
新智元报道
新智元报道
【新智元导读】陶哲轩早就预言,2026年GPT能帮数学家合著论文。今天,GPT-4就帮他写出一段代码,直接节省了半小时的工作量。
刚刚,陶哲轩大赞:用ChatGPT写Python代码,效果真是太好了,它直接为我节省了数学研究中半小时的工作量!
作为实验,他要求ChatGPT写一段Python代码,为每个自然数n计算1,...,n的最长子序列的长度𝑀(𝑛) ,其中欧拉全能函数ϕ不递减。
例如,𝑀(6)=5,因为ϕ在1,2,3,4,5(或 1,2,3,4,6)上是非递减的,但在 1,2,3,4,5,6 上不是。
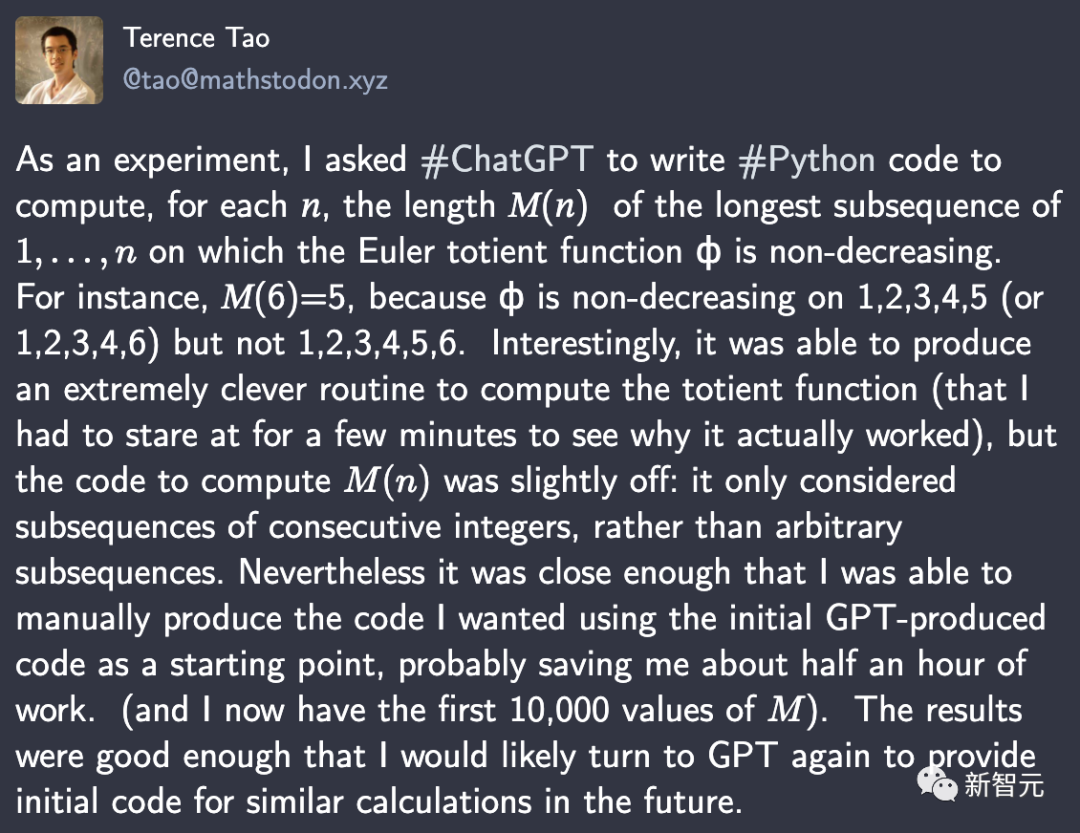
有趣的是,它生成了一段极其巧妙的代码来计算全能函数,这段代码如此之巧妙,以至于陶哲轩不得不盯着它看了几分钟,才明白代码背后的原理究竟是什么。
当然,这段代码也存在偏差——它只考虑了连续整数的子序列,而不是任意子序列。
不过,这已经足够接近了,用ChatGPT生成的这段初始代码作为起点,陶哲轩最终手动生成了自己想要的代码,这大概节省了他半个小时的工作量。
现在,他已经得到了M的前10,000个值。
因为ChatGPT给出的结果非常好,陶哲轩表示,自己以后还会经常使用它,为类似的计算提供初始代码。
ChatGPT的惊人表现
「理想情况下,我想要一个这样一个程序,它可以快速计算出n的中等值(比如大到100),我建议可以是一种动态编程方法,但如果只是一个适用于较小n值的暴力破解法,对我来说应该也够了。」

ChatGPT立马给出了如下回答——
欧拉函数(通常表示为 φ(n) )是指小于n的正整数中,与n互质的数的数目。
对于暴力破解方法,您可以按照以下步骤操作:
1.对于从1到n的每个i,计算φ(i)
2.对于 {1,...,n} 的每个子序列,检查该子序列上的序列φ是否是不递减的
3.找到满足φ 不递减的最长子序列

接着,ChatGPT就给出了一段Python代码。
import mathdef phi(n):"""Compute the Euler totient function for n."""result = nfor i in range(2, int(math.sqrt(n)) + 1):if n % i == 0:while n % i == 0:n //= iresult -= result // iif n > 1:result -= result // nreturn resultdef is_non_decreasing(seq):"""Check if a sequence is non-decreasing."""for i in range(1, len(seq)):if seq[i] < seq[i-1]:return Falsereturn Truedef longest_non_decreasing_phi_subsequence(n):"""Find the length of the longest subsequence of {1,...,n} on which phi is non-decreasing."""phi_values = [phi(i) for i in range(1, n+1)]max_length = 0for i in range(n):for j in range(i, n):if is_non_decreasing(phi_values[i:j+1]):max_length = max(max_length, j-i+1)return max_lengthn = 6print(longest_non_decreasing_phi_subsequence(n)) # Output: 5
并在最后给出总结:这段代码适用于较小的n值,但由于其时间复杂度,对于较大的值会很慢。
对于较大的n值,需要更有效的算法或动态规划方法。

陶哲轩和网友的讨论
「这段代码肯定不是GPT-4自己写的,它应该是从哪个程序员po到网上的代码那里扒的。或许我们永远都找不到。」

对此,陶哲轩表示,他问了GPT-4是怎么想出这段代码的,它竟然能对代码给出清晰正确的解释。
因此他判断,这段代码并不是GPT-4简单地从某个来源抄来的。
并且,他也在网上搜了一下,不过并没有搜到类似代码。
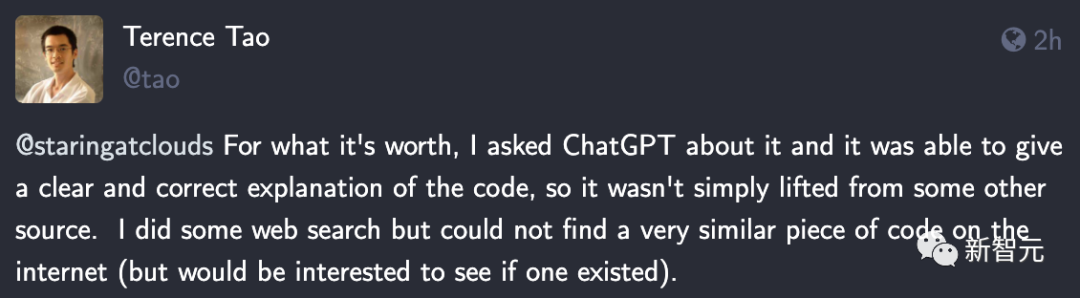
在下图中,我们可以看到,GPT-4对于自己如何想到这套算法的解释对答如流,毫无破绽。

很快,有网友表示自己挖出了这个算法的最早示例,是2008年的某个俄语个人网页上。
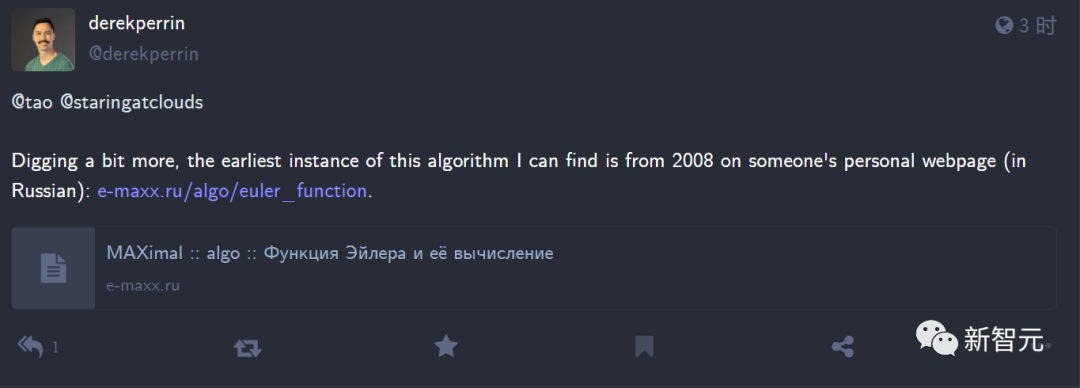
陶哲轩对此表示,有趣的是,GPT生成的Python代码与该网友挖掘的C/C++算法非常相似(例如使用相同的变量名称「result」),但与现有的的Python欧拉函数代码完全不同,后者可以从谷歌搜索中找到。
就好像GPT锁定了这段C代码(也许是因为它似乎出现在网络上的多处,并且对背后原理的解释非常优秀),并且更喜欢将其转换为Python,而不是使用表面上更相关的「命中」,这与搜索引擎的运行方式相反。

另外还有网友留言表示,一个有趣的现象是,你觉得修补一段代码比从头写代码快。但对我来说完全相反,或许每个人的感受都会有差异吧。
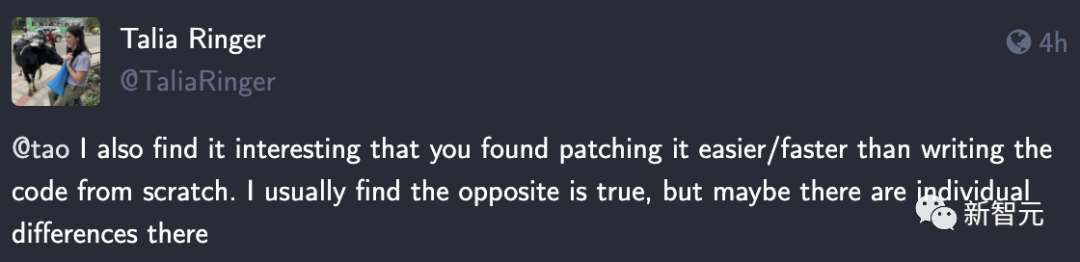
陶哲轩回复道:我不常用Python,所以我并没有可以直接调用的基本语法(比如for循环)。
并且逐个引用传递和按值传递之间有一些微妙之处,我每次都会出错,最终我因此错误地初始化二维数组时,不得不通过手动检查动态更新来调试。
能得到语法正确、功能也基本正确的代码,对我的帮助很大,否则我不得不谷歌一下每一行代码,才能弄清楚如何准确表达。
而对于编写数学证明,我同意你的观点,GPT提供的不正确的结论,不会对我有多大帮助,这种情况下还是从头开始会更有效率。

有网友向他建议说:GitHub Copilot + VSCode或许对您很有用。我几乎不需要查找标准的表层句法结构了。
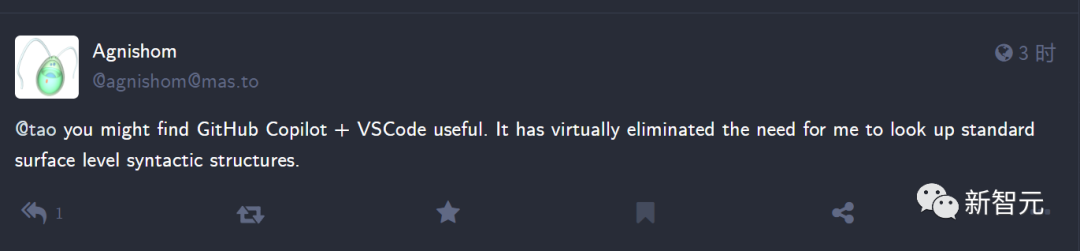
陶哲轩表示感谢,如果自己需要定期大量写代码,就一定会采用的。
不过目前只是每月一次偶尔需要这样的计算,为特定任务找到最快的解决方案而已。
2026年GPT就能帮我合著数学论文
今年3月GPT-4正式发布时,他曾获邀提前试用。
试用完,他的感受是——2026年,GPT应该就能帮数学家们合著数学论文了!

在过去几十年里,人类一直在被信息技术规训,慢慢习惯了一些情况。比如:
- 硬件和软件将以摩尔定律的速度不断改进(如性能、用户体验和可靠性),然后过渡到更渐进的改进。
- 单个软件工具能够可靠地产生高质量的输出,但输入数据必须是最高质量的,并且必须以特定的方式进行精心格式化,以满足工具的要求。
- 工具越先进,规范和特殊情况就越复杂。除非有精心设计的标准,否则工具之间(特别是不同供应商之间)的可交互性就会成为巨大的技术挑战。
- 人类将做出所有关键的执行决策;软件工具则通过它执行人类指令的成功或失败的结果来影响人类的决策过程。
随着GPT-4等生成式AI工具的出现,所有这些习惯即使不能被完全放弃,也需要重新调整。
这些工具在处理措辞模糊(且略有错误)的自然语言提示,或处理从网页或 PDF 中抓取的嘈杂数据时表现非常出色。
比如,向GPT-4提供一份数学论文的前几页PDF,它就可以生成几个质量还不错的学术问题。而使用类似提示词的变体,就可以准备今后的演讲或阅读技术层面比较复杂的论文。
起初,陶哲轩基于编程或脚本语言的经验,努力使自己写的提示词尽可能准确。然而,最好的结果却是在他放弃了那种谨慎,直接将大量的原始文本扔给AI时得到的。
如此高的容错性,让AI工具可以与传统软件工具配合工作,或者让AI工具相互集成协同工作,或者与没有处理过的个人数据和个人偏好结合起来工作。
而这种方式,将彻底改变人们的工作流程,而不仅仅是像现在一样孤立地给人类行为提供一些建议。
现在,陶哲轩经常会使用GPT-4来回答随意和措辞含糊的问题。甚至,让它来帮忙起草一些复杂文件的初稿。
对于这些问题,以前则需要花很多精力去搜索引擎里寻找答案。
当前的大语言模型(LLM)通常可以令人信服地模仿某个知识领域中专家的回答,但幻觉问题还是无法避免。
对此,不管是人类还是AI,都需要培养分析这种「新型文本」的技能。
陶哲轩也表示,自己用来「探测」某些离谱的错误数学论证的文体信号,对LLM生成的数学文本没有多大用处。只有逐行认真地阅读才能辨别出是否有任何实质内容。


不过,即使是LLM生成的无意义的数学内容,也经常引用相关概念。只要花些功夫,人类专家可以将不可行的想法修改为正确而且是原创的观点。
2023年的AI已经可以生成对于数学家有用的提示和线索,从而在数学家的决策和思考过程中发挥作用。
当与形式证明验证器、互联网搜索和符号数学包等工具集成到一起配合工作时,陶哲轩预测,只要使用得当,2026 年的人工智能将成为数学研究中值得信赖的合著者,在许多其他领域也应该如此。
如今,在AI指导下,研究生已经可以在不到一天的时间内生成一篇入门级的数学论文,而未来AI工具的准确性显然还要高得多。
甚至,我们都不用等到那个时候。
今年6月,陶哲轩在解决一道数学难题时,GPT-4就提出了一种可行的解决思路。
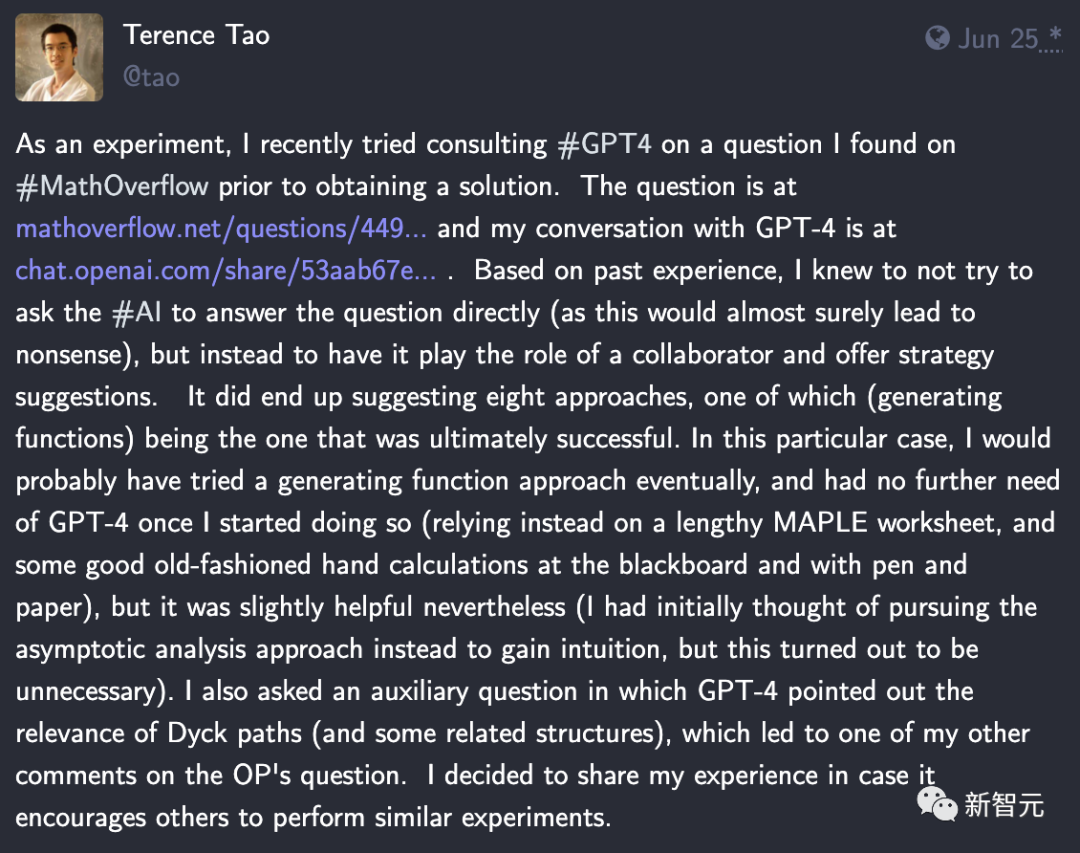
随后,陶哲轩还完整地分享了他与GPT-4的聊天记录。



GPT-4无法攻克数学问题,但对工作有帮助

在接下来一段时间中,他经常分享了一些自己使用ChatGPT等工具的体验。
许多ChatGPT隐藏功能都被他挖掘了出来,比如寻找公式、解析代码格式的文档、改写论文语句等等。
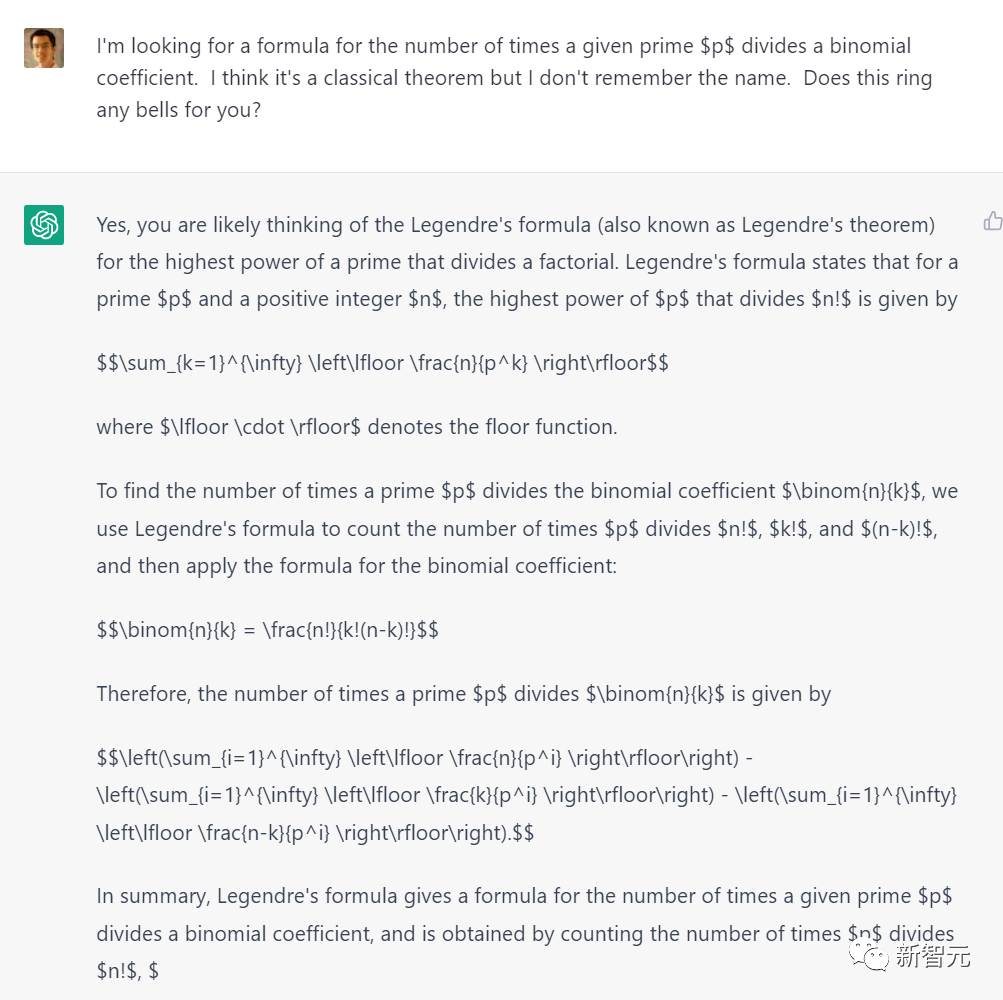
比如,陶哲轩让ChatGPT从描述中识别库默尔定理,它没能给出正确答案,但根据它给出的近似答案(Legendre公式)。
对此,陶哲轩称,AI在数学中的作用是提供一个初步的近似答案,然后可以结合传统搜索引擎轻松找到正确答案。

陶哲轩还发现了ChatGPT在处理数学问题时的亮点,能够识别不同语言的数学概念音译版。

另外,可以要求ChatGPT转换从MathSciNet获得的一堆参考文献,并在LaTeX书目环境下将其格式化为\bibitems。
虽然,ChatGPT等AI工具虽然不能帮陶哲轩攻克一个未解决的数学问题,但对其他工作相关的问题很有用,尽管事后经常需要进行一些手动调整。
一方面,它很擅长解析代码格式的文档(在这种情况下是#arXiv搜索的API),然后返回一个正确格式的代码查询(后来它还提供了一些工作的python代码,以我要求的方式调用这个API,尽管我不得不手动安装一个包来使它运行)。
另一方面,可以让它想出一些,聪明的学生在本科线性代数课上可能会问的问题(为此我提供了一些样本题目),它给出了一些很好的例子,让他对课程的可能方向,以及潜在的作业问题有所启发。

总的来说,陶哲轩对于生成式AI工具的看法分为四类。
首先,对于每天执行的任务,陶哲轩已经开发了足够的技术来优化工作流程,AI工具对他来说并没有太多的增值。最明显的是在研究数学方面。
其次,对于那些我们有一些专业知识,但很少实践的任务,AI工具是有帮助的:通常可以用它们来创建输出的初稿,然后进行验证和修改,或至少作为灵感来源使用。这一类的例子包括数据处理,翻译成外语,或以自己很少使用的格式写文本(比如公开演讲,规则文件等)。
再次,对于那些没有什么专业知识,也不需要极高的质量和可靠的输出的任务,可以简单地询问AI工具,并或多或少地听从其建议。在这里,AI的功能是作为传统搜索引擎的一个稍微方便的版本。
最后,对于那些自己不具备专业知识,但又需要质量和可靠性的任务,AI和陶哲轩本人都无法解决,必须咨询去人类专家。比如修理一个复杂、昂贵、精致的设备。
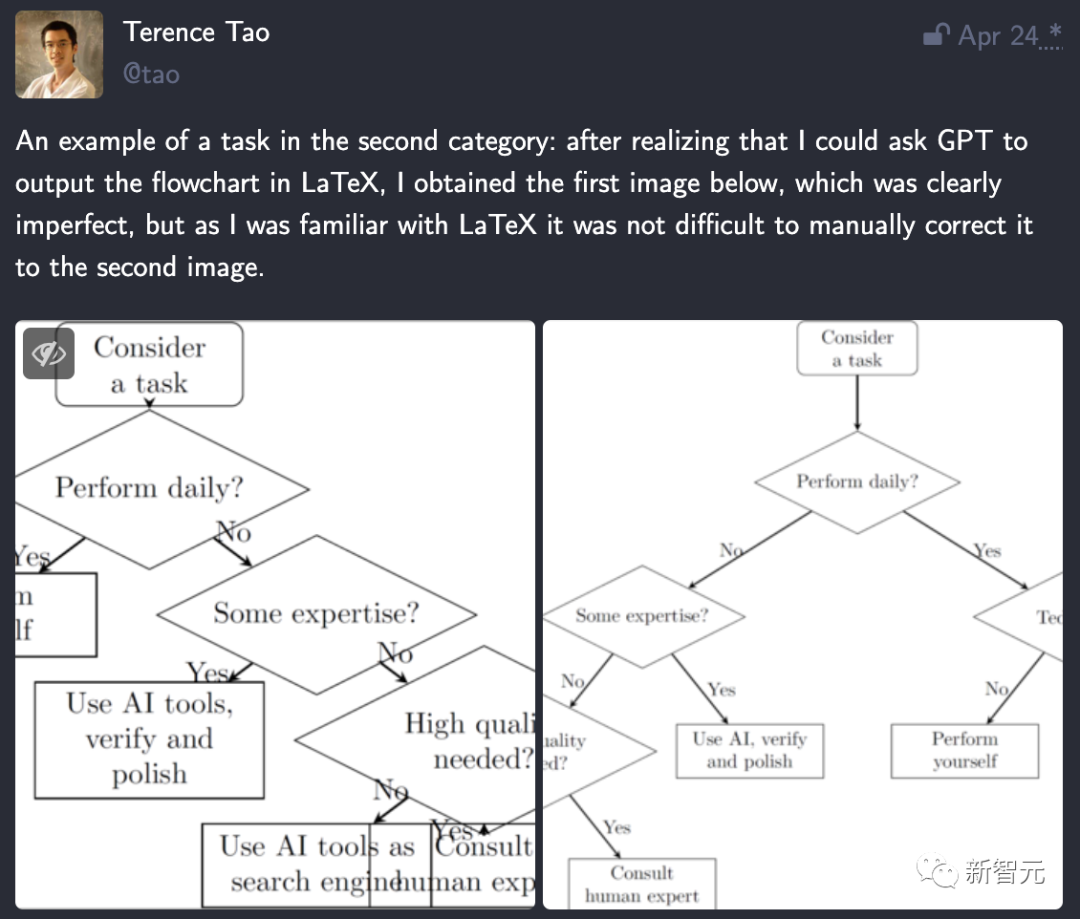
对于第二类任务,陶哲轩表示,当自己意识到可以要求GPT以LaTeX格式输出流程图后,得到了下面的第一张图片,这显然是不完美的。
当然,由于他非常熟悉LaTeX,手动将其修正为第二张图片并不困难。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢