
7月28日,清华大学计图团队和南开大学程明明教授团队合作,在CVMJ上在线发表一篇关于视觉骨干网络的论文Visual Attention Network,介绍了一种新型的注意力机制大核注意力机制(LKA)和新的骨干网络 VAN。该网络在图像分类、目标检测、语义分割和姿态估计等任务上均取得了优异的效果。该论文已2022年2月在ArXiv上发布,目前该文章的Google scholar的引用次数已达215次。
Part1
早期发明阶段(2012年之前),这个阶段以LeNet为代表,研究人员正式开始提出使用卷积神经网络进行特征提取。
第二阶段(2012年-2020年),这个阶段出现了大量杰出的卷积神经网络工作,如AlexNet和ResNet等,卷积神经网络的层数得到突破,并不断加深,骨干网络正式进入深度时代。
第三阶段(2020-至今),各种基于注意力机制的视觉模型层出不穷,并迅速应用在了计算机视觉的各种任务中,骨干网络也开始变成基于注意力机制的深度神经网络。
2021年 11 月,清华大学的计图团队和南开大学程明明教授团队合作发布了一篇计算机视觉中的注意力机制的综述[1],分析了目前已有的各种注意力机制。通过完成这篇综述,作者意识到,如果从Transformer 的角度去看自注意力机制,那么自注意力机制是Transformer 中不可或缺的一部分,但是从注意力机制的角度去看自注意力机制,那么自注意力机制就是一种特殊的注意力机制,完全可能被替代。
在这篇文章中,计图团队提出了一种全新的针对于视觉任务的注意力机制 —大核注意力(Large-Kernel Attention, LKA),其机理和self-attention不同。基于这种大核注意力机制,作者提出了一种简单且有效的视觉骨干网络 Visual Attention Network(VAN), 该网络在图像分类、目标检测和语义分割任务上均取得了优异的效果[2]。
自注意力擅长处理一维的序列结构,如果直接用于处理图像,会忽略图像自身的二维结构信息,而数据自身的结构信息是重要的。
由于自注意力自身复杂度的问题,难以用于处理高分辨率图像。
自注意力机制仅仅考虑了空间维度上的自适应性,而忽略了通道维度上的自适应性,而通道自适应性已经在 SENet[3] 等工作中证明了在视觉任务中的重要性。
自注意力机制可以捕获长距离依赖。
自注意力具有空间自适应性。
卷积可以高效地利用图像的局部信息。
卷积可以利用图像的二维结构信息。
经过了上述的分析,作者希望为计算机视觉专门设计一种新的注意力机制,而不是简单沿用自然语言处理中的自注意力机制。于是,作者在该论文中提出了一种专门针对计算机视觉任务的大核注意力(LKA)机制,基于该注意力,作者进一步提出了一种全新的视觉骨干网络VAN。
Part3
下面介绍大核注意力的机理和VAN的设计。
注意力机制
注意力机制可以理解为:计算机视觉系统在模拟人类视觉系统中可以迅速高效地关注到重点区域的特性。注意力过程是一个自适应(动态)过程,根据输入去调节输出的过程。
注意力机制大概可以分成两个步骤: 1)得到注意力图(attention map),2)根据注意力图对输入进行处理。
如何判断一个点的重要程度呢?
由于缺乏语义信息,根据单个点的信息,你难以判断这个点重要还是不重要,你需要知道它周围点的信息你才可以进行判断。所以我们需要得到周围点的信息,并且点越多(long-range dependence),可能判断的就越准确。如图1所示,attention map表示表示每个点的重要程度,你需要知道周围点的信息,才能判断一个黄色点的重要性。
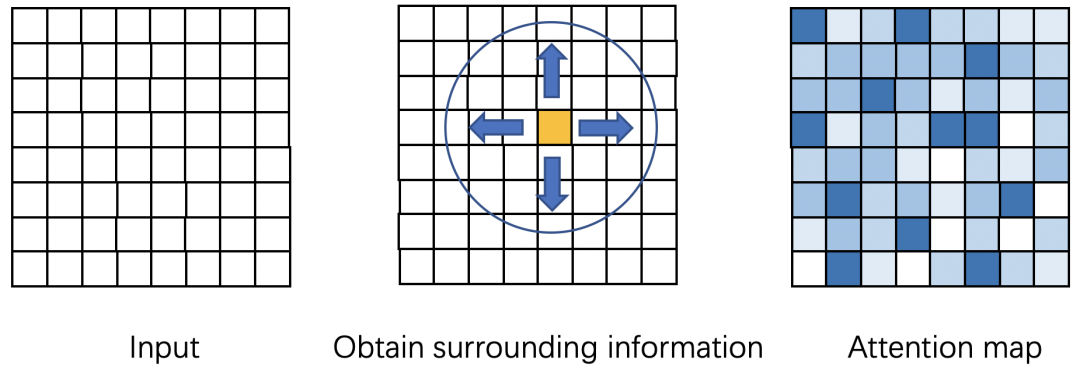
图1 Attention map的计算原理
捕捉长距离的依赖有两种常见的方法:
1) 使用自注意力机制。在研究动机中已经讲述了在视觉中使用自注意力机制的不足。
2) 使用大核卷积来捕捉长距离依赖。使用该方法的不足在于,大卷积核的参数量和计算量太大,难以接受。
本文针对 2) 进行了改进,提出了一种新的分解方式,用于减少大卷积的计算量和参数量。
如图2所示:我们可以将一个Kx K 的大卷积分解成三部分:
a) 一个(K/d) x (K/d) 的depth-wise dilation convolution,其中dilation的大小为d;
b) 一个(2d-1)x (2d-1) 的 depth-wise convolution;
c) 一个 1x1 卷积。
这种分解可以理解为如何选择三种基本的构件来布满整个卷积空间。图2展示了将一个 13 x 13 的卷积分解成一个 5 x 5 的 depth-wise convolution 、一个 5 x 5 的depth-wise dilation convolution,和一个 1 x 1 的卷积,其中 d = 3 。
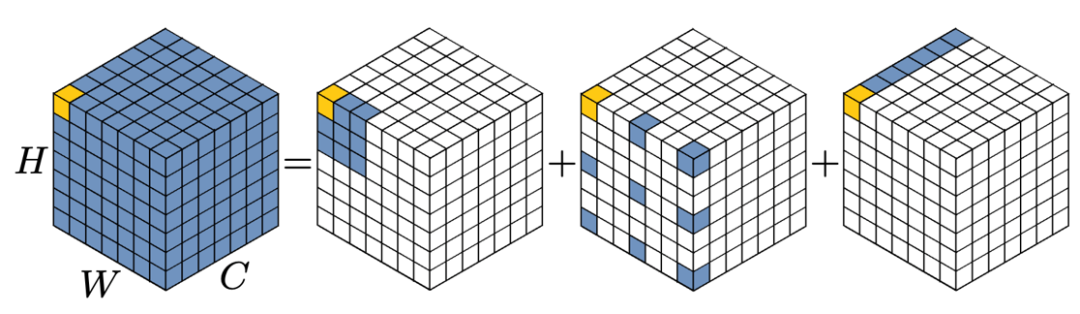
图2 13 x 13 卷积的分解
如上这种分解与 mobilenet[4] 中的分解相比,不同之处在于,作者对空间进行了二次分解,这使得该方法更加适用于大卷积核的分解。
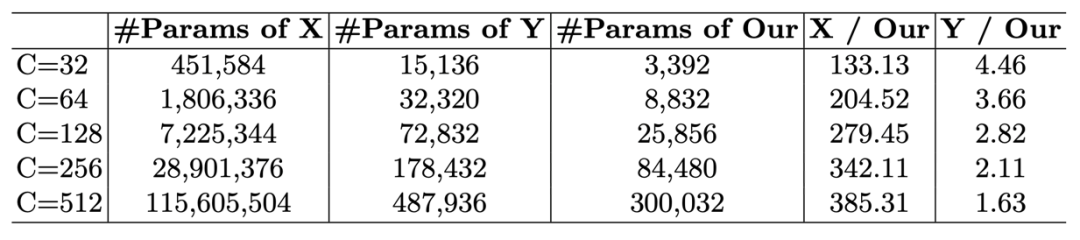
文中选用了 21 x 21 的卷积,通过求导可以发现,按照这种分解方式,分解一个 21 x 21 的卷积时候,d = 3 可以使得参数量和计算量最小。通过该分解方式与原始卷积、mobilenet[3]分解的参数量的对比,发现该分解在大卷积核时,有着明显的优势。如表1所示,X 表示标准 21 x 21 的卷积,Y 表示使用mobilenet分解方式的卷积,Our表示文中的分解方式。
大核注意力 (LKA)
下面给出大核注意力的实现方式,
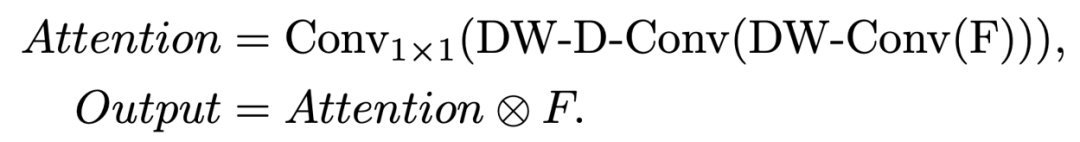
其中DW-Conv 表示 depth-wise convolution, DW-D-Conv 表示 depth-wise dilation convolution, Conv1x1 表示1 x 1 卷积。⊗ 表示逐元素相乘。
我们可以用图来表示神经网络模块:(a) 即为本文提出的大核注意力 (Large Kernel Attention);(b)是传统的卷积网络模块;(c)是自注意力模块;(d)是 VAN 的一个Stage,CFF 表示卷积前馈网络。
可以看到,(a) 和(b) 之间的区别是元素乘法。值得注意的是,(c)最初是为一维序列设计的。
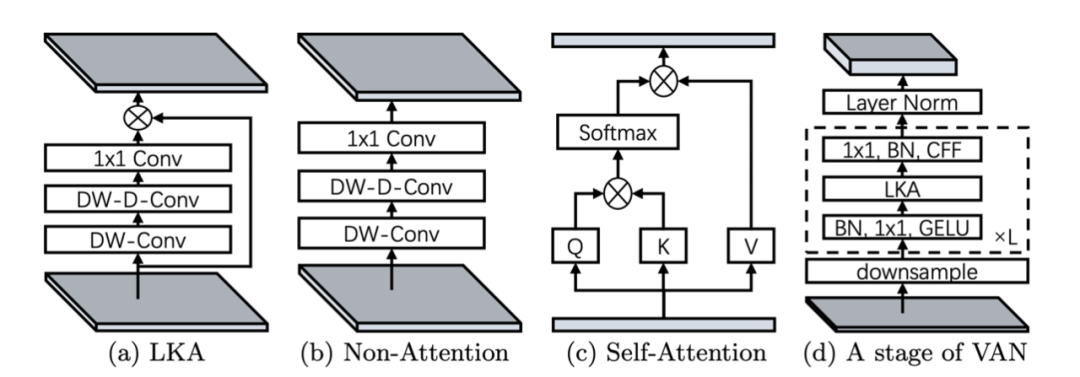
视觉注意力网络VAN
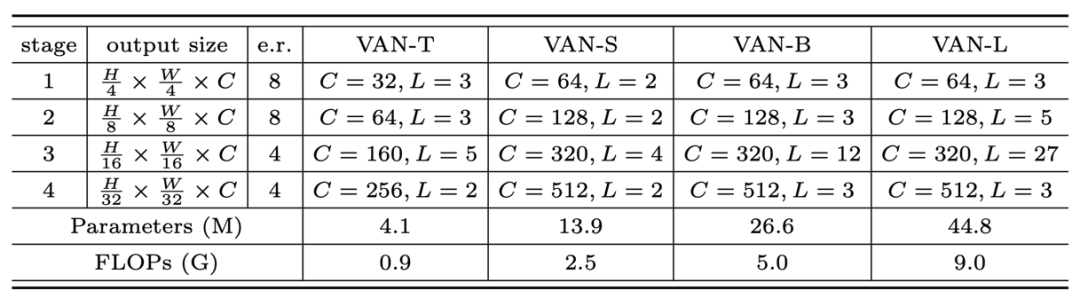
基于LKA,本文搭建了一个新的视觉骨干网络VAN。文中使用了类似层次化transformer 的结构,即 Attention-FFN 结构,具体如表2所示。作者给出了四种不同大小的VAN网络 (Tiny, Small, Base, Large),具体配置如下。
表2 不同大小的网络设置
Part4
作者针对图像分类、检测和分割等任务做了实验,并和 Swin Transformer[5] 以及 ConvNeXt[6]进行了详尽的对比和分析,具体详见论文的实验章节。这里仅展示部分实验结果和可视化结果。
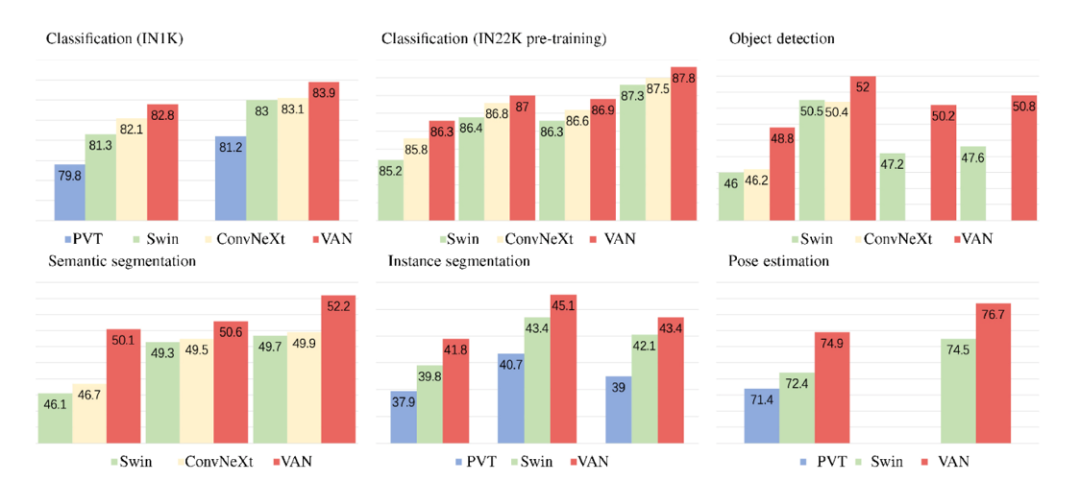
图4 与 ConvNeXt、Swin transformer以及 PVT 的比较
通过 Grad-CAM方法[7],进行可视化的结果如下。

Part5
参考文献
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R. Martin, Ming-Ming Cheng, Shi-Min Hu, Attention Mechanisms in Computer Vision: A Survey, Computational Visual Media, 2022, Vol. 8, No. 3, 331-368.
Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng and Shi-Min Hu, Visual attention network, Computational Visual Media, Vol. 9, No. 4, 733–752.
Jie Hu, Shen Li, Samuel Albanie, Sun Sun, Enhua Wu, Squeeze-and-excitation networks, IEEE T-PAMI, 2020, Vol. 42, No. 8, 2011-2023.
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Heng Zhang, Stephen Lin, Baining Guo, Swin transformer: Hierarchical vision transformer using shifted windows, IEEE ICCV 2021, 10012-10022.
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, A convnet for the 2020s, arXiv:2201.03545, 2022.
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. IEEE ICCV, 2017, 618-626.
Guo, M. H., Lu, C. Z., Hou, Q., Liu, Z., Cheng, M. M., & Hu, S. M. (2022). Segnext: Rethinking convolutional attention design for semantic segmentation. Advances in Neural Information Processing Systems, 35, 1140-1156.
Li, X. L., Guo, M. H., Mu, T. J., Martin, R. R., & Hu, S. M. (2023). Long Range Pooling for 3D Large-Scale Scene Understanding. In Proceedings of the IEEE/CVF CVPR, 2023, 10300-10311.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢