
近日,全球规模最大的大模型开发工具与社区Colossal-AI,发布了全套Llama 2训练、微调、推理方案,可以为700亿参数模型的训练加速195%。
ChatGPT引发的大模型热潮愈演愈烈,全球科技巨头和明星初创争相入局,打造以AI大模型为核心的竞争力和多样化商业使用需求。
其中LLaMA系列模型,因良好的基础能力和开放生态,已积累了海量的用户和实际应用案例,成为无数开源模型后来者的模仿和竞争的标杆对象。
但如何降低类Llama 2大模型预训练成本,如何基于Llama 2通过继续预训练和微调,低成本构建AI大模型实际应用,仍是AIGC相关企业面临的关键瓶颈。
作为全球规模最大、最活跃的大模型开发工具与社区,Colossal-AI再次迭代,提供开箱即用的8到512卡Llama 2训练、微调、推理方案,对700亿参数训练加速195%,并提供一站式云平台解决方案,极大降低大模型开发和落地应用成本。
开源地址:https://github.com/hpcaitech/ColossalAI
Llama 2训练加速195%
Meta开源的LLaMA系列大模型进一步激发了打造类ChatGPT的热情,并由此衍生出了诸多项目和应用。
最新的7B~70B Llama 2大模型,则进一步提高了语言模型的基础能力。但由于Llama 2的预训练预料大部分来自英文通用知识,而仅用微调能够提升和注入的领域知识和多语言能力也相对有限。
此外,高质量的专业知识和数据集通常被视为各个行业和公司的核心资产,仅能以私有化形式保存。因此,以低成本预训练/继续预训练/微调Llama 2系列大模型,结合高质量私有化业务数据积累,帮助业务降本增效是众多行业与企业的迫切需求与瓶颈。
但Llama 2大模型仅发布了原始模型权重与推理脚本,不支持训练/微调,也未提供数据集。
针对上述空白与需求,Colossal-AI开源了针对Llama 2的全流程方案,并具备高可扩展性,支持从70亿到700亿参数的模型,从8卡到512卡都可保持良好的性能。
在使用8卡训练/微调Llama 2 7B时,Colossal-AI能达到约54%的硬件利用率(MFU),处于业界领先水平。
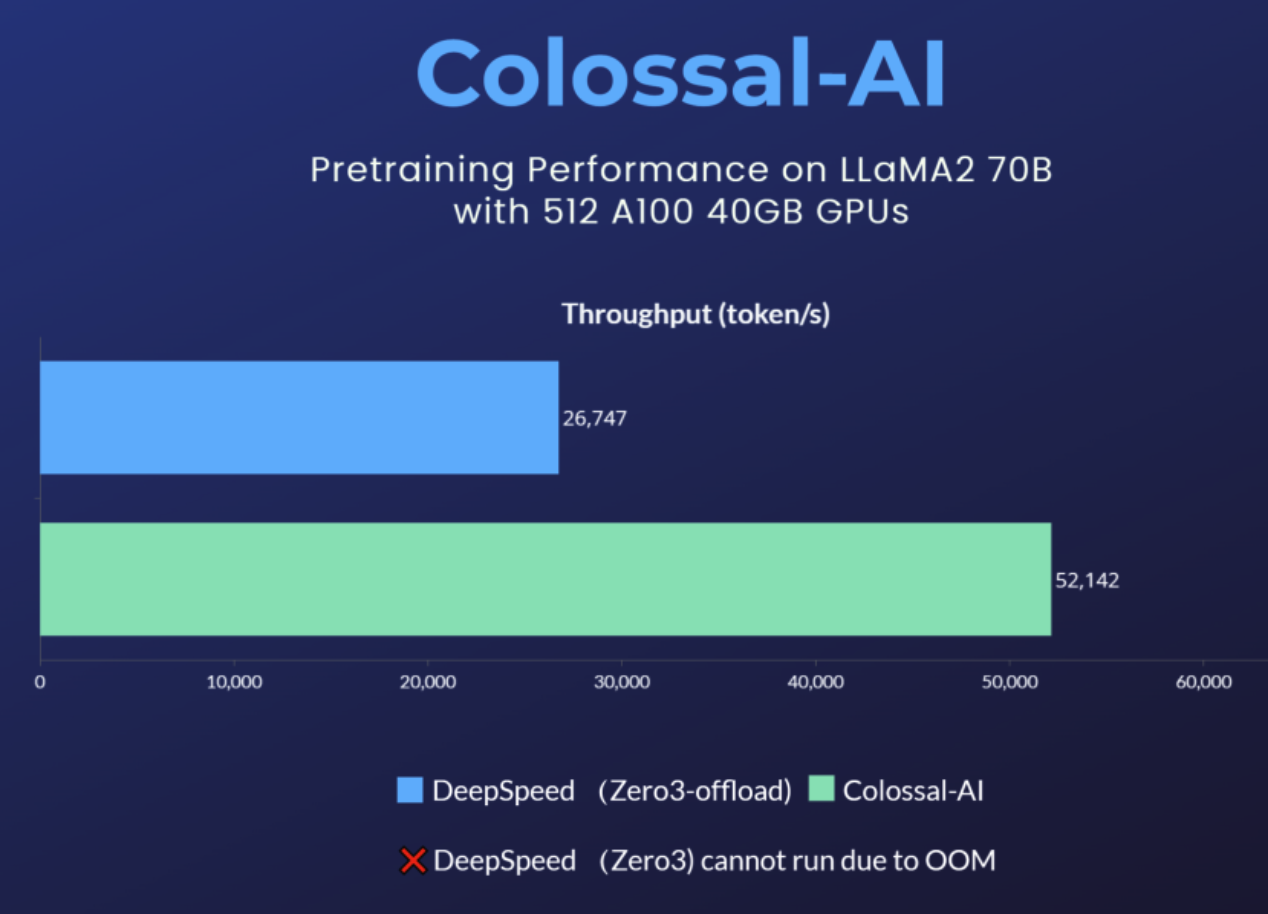
对于预训练任务,以使用512张A100 40GB预训练Llama 2 70B为例,DeepSpeed ZeRO3策略因显存不足而无法启动,仅能通过速度衰减较大的ZeRO3-offload策略启动。
相比之下,Colossal-AI则因卓越的系统优化和扩展性,仍能保持良好性能,训练提速195%。
Colossal-AI云平台:platform.luchentech.com
Colossal-AI开源地址:https://github.com/hpcaitech/ColossalAI
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢