
【导读】大家好,我是泳鱼。一个乐于探索和分享AI知识的码农!今天的这篇文章带大家轻松get机器学习建模方法~
算法工程师是伴随着人工智能火起来的一个领域。听着名字似乎门槛很高。但是,得益于Python生态下的包共享机制,机器学习模型构建的过程其实已经变得非常简单了,很多听起来牛逼的算法,其实根本不需要自己实现,甚至都不需要知道这些算法的具体原理。扩展阅读:一文全览机器学习建模流程(Python代码)
1、加载数据集
因为原始的数据集中包含很多空值,而且类别特征用英文名表示各个花的名字,也需要我们转换成数字。
from sklearn.datasets import load_iris
data = load_iris()
x = data.data
y = data.target
x值如下,可以看到scikit-learn把数据集经过去除空值处理放在了array里,所以x是一个(150,4)的数组,保存了150个数据的4个特征:
array([[5.1, 3.5, 1.4, 0.2], [4.9, 3. , 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2], [5. , 3.6, 1.4, 0.2], [5.4, 3.9, 1.7, 0.4], [4.6, 3.4, 1.4, 0.3], [5. , 3.4, 1.5, 0.2], [4.4, 2.9, 1.4, 0.2], [4.9, 3.1, 1.5, 0.1], [5.4, 3.7, 1.5, 0.2], [4.8, 3.4, 1.6, 0.2], [4.8, 3. , 1.4, 0.1], [4.3, 3. , 1.1, 0.1], …………
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
2、数据集拆分
数据集拆分是为了验证模型在训练集和测试集是否过拟合,使用train_test_split的目的是保证从数据集中均匀拆分出测试集。这里,简单把10%的数据集拿出来用作测试集。
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.1,random_state=0)
万能模板V1.0版
助你快速构建一个基本的算法模型

而且在scikit-learn中,每个包的位置都是有规律的,比如:随机森林就是在集成学习文件夹下。
模板1.0应用案例
1、构建SVM分类模型
通过查阅资料,我们知道svm算法在scikit-learn.svm.SVC下,所以:
# svm分类器
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
svm_model = SVC()
svm_model.fit(train_x,train_y)
pred1 = svm_model.predict(train_x)
accuracy1 = accuracy_score(train_y,pred1)
print('在训练集上的精确度: %.4f'%accuracy1)
pred2 = svm_model.predict(test_x)
accuracy2 = accuracy_score(test_y,pred2)
print('在测试集上的精确度: %.4f'%accuracy2)
在训练集上的精确度: 0.9810
在测试集上的精确度: 0.9778
2、构建LR分类模型
同理,找到LR算法在sklearn.linear_model.LogisticRegression下,所以:
# LogisticRegression分类器
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score #评分函数用精确度评估
lr_model = LogisticRegression()
lr_model.fit(train_x,train_y)
pred1 = lr_model.predict(train_x)
accuracy1 = accuracy_score(train_y,pred1)
print('在训练集上的精确度: %.4f'%accuracy1)
pred2 = lr_model.predict(test_x)
accuracy2 = accuracy_score(test_y,pred2)
print('在测试集上的精确度: %.4f'%accuracy2)
在训练集上的精确度: 0.9429 在测试集上的精确度: 0.8889
3、构建随机森林分类模型
随机森林算法在sklearn.ensemble.RandomForestClassifier 下,好了,现在你应该可以自己写了,这个作为本文的一个小测试,欢迎在评论区写下你的答案。
万能模板V2.0版
加入交叉验证,让算法模型评估更加科学
更糟糕的是,有些情况下,在训练集上,通过调整参数设置使模型的性能达到了最佳状态,但在测试集上却可能出现过拟合的情况。这个时候,我们在训练集上得到的评分不能有效反映出模型的泛化性能。
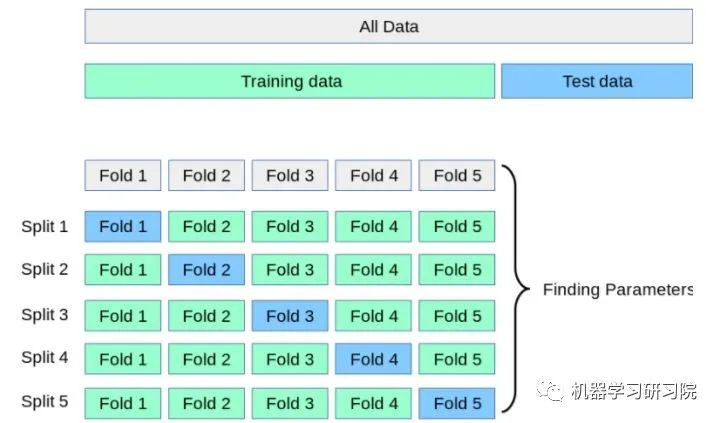
这样一方面可以让训练集的所有数据都参与训练,另一方面也通过多次计算得到了一个比较有代表性的得分。唯一的缺点就是计算代价很高,增加了k倍的计算量。
原理就是这样,但理想很丰满,现实很骨干。在自己实现的时候却有一个很大的难题摆在面前:怎么能够把训练集均匀地划分为K份?

把模型、数据、划分验证集的个数一股脑输入函数,函数会自动执行上边所说的过程。
# 输出精确度的平均值
# print("训练集上的精确度: %0.2f " % scores1.mean())
但是既然我们进行了交叉验证,做了这么多计算量,单求一个平均值还是有点浪费了,可以利用下边代码捎带求出精确度的置信度:
# 输出精确度的平均值和置信度区间
print("训练集上的平均精确度: %0.2f (+/- %0.2f)" % (scores2.mean(), scores2.std() * 2))
模板2.0应用案例:
1、构建SVM分类模型
### svm分类器
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
svm_model = SVC()
svm_model.fit(train_x,train_y)
scores1 = cross_val_score(svm_model,train_x,train_y,cv=5, scoring='accuracy')
# 输出精确度的平均值和置信度区间
print("训练集上的精确度: %0.2f (+/- %0.2f)" % (scores1.mean(), scores1.std() * 2))
scores2 = cross_val_score(svm_model,test_x,test_y,cv=5, scoring='accuracy')
# 输出精确度的平均值和置信度区间
print("测试集上的平均精确度: %0.2f (+/- %0.2f)" % (scores2.mean(), scores2.std() * 2))
print(scores1)
print(scores2)
训练集上的精确度: 0.97 (+/- 0.08)
测试集上的平均精确度: 0.91 (+/- 0.10)
[1. 1. 1. 0.9047619 0.94736842]
[1. 0.88888889 0.88888889 0.875 0.875 ]
2、构建LR分类模型
# LogisticRegression分类器
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(train_x,train_y)
scores1 = cross_val_score(lr_model,train_x,train_y,cv=5, scoring='accuracy')
# 输出精确度的平均值和置信度区间
print("训练集上的精确度: %0.2f (+/- %0.2f)" % (scores1.mean(), scores1.std() * 2))
scores2 = cross_val_score(lr_model,test_x,test_y,cv=5, scoring='accuracy')
# 输出精确度的平均值和置信度区间
print("测试集上的平均精确度: %0.2f (+/- %0.2f)" % (scores2.mean(), scores2.std() * 2))
print(scores1)
print(scores2)
训练集上的精确度: 0.94 (+/- 0.07)
测试集上的平均精确度: 0.84 (+/- 0.14)
[0.90909091 1. 0.95238095 0.9047619 0.94736842]
[0.90909091 0.88888889 0.88888889 0.75 0.75 ]
注: 如果想要一次性评估多个指标,也可以使用可以一次性输入多个评估指标的 cross_validate()函数。
万能模板V3.0版
调参让算法表现更上一层楼
首先要明确的是,scikit-learn提供了算法().get_params()方法来查看每个算法可以调整的参数,比如说,我们想查看SVM分类器算法可以调整的参数,可以:
SVC().get_params()
输出的就是SVM算法可以调节的参数以及系统默认的参数值。每个参数的具体含义会在以后的文章中介绍。
{'C': 1.0,
'cache_size': 200,
'class_weight': None,
'coef0': 0.0,
'decision_function_shape': 'ovr',
'degree': 3,
'gamma': 'auto',
'kernel': 'rbf',
'max_iter': -1,
'probability': False,
'random_state': None,
'shrinking': True,
'tol': 0.001,
'verbose': False}
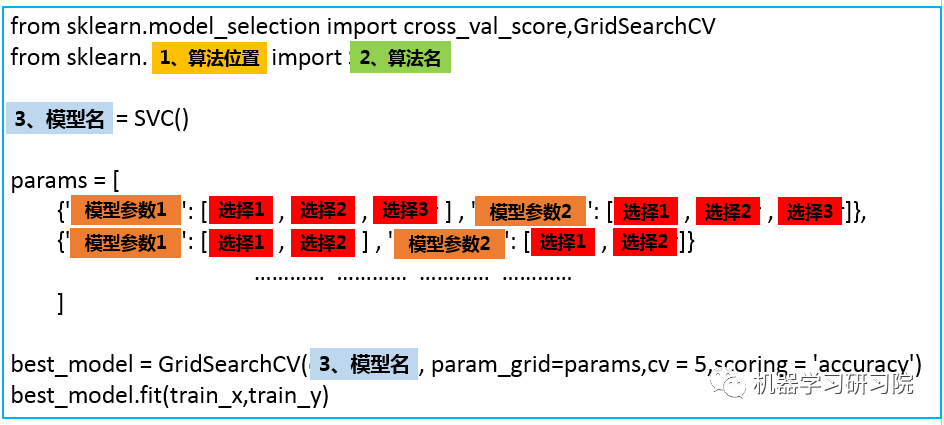

看到这里,可能有人会有疑惑:为什么要采用列表、字典、列表三层嵌套的方式呢?params直接是字典的形式不行吗?答案是:行,但是不好。
best_model.cv_results_:可以查看不同参数情况下的评价结果。 best_model.param_ :得到该模型的最优参数 best_model.best_score_: 得到该模型的最后评分结果
模板3.0应用案例
实现SVM分类器
###1、svm分类器
from sklearn.model_selection import cross_val_score,GridSearchCV
from sklearn.svm import SVC
svm_model = SVC()
params = [
{'kernel': ['linear'], 'C': [1, 10, 100, 100]},
{'kernel': ['poly'], 'C': [1], 'degree': [2, 3]},
{'kernel': ['rbf'], 'C': [1, 10, 100, 100], 'gamma':[1, 0.1, 0.01, 0.001]}
]
best_model = GridSearchCV(svm_model, param_grid=params,cv = 5,scoring = 'accuracy')
best_model.fit(train_x,train_y)
from sklearn.model_selection import cross_val_score,GridSearchCV
from sklearn.svm import SVC
svm_model = SVC()
params = [
{'kernel': ['linear'], 'C': [1, 10, 100, 100]},
{'kernel': ['poly'], 'C': [1], 'degree': [2, 3]},
{'kernel': ['rbf'], 'C': [1, 10, 100, 100], 'gamma':[1, 0.1, 0.01, 0.001]}
]
best_model = GridSearchCV(svm_model, param_grid=params,cv = 5,scoring = 'accuracy')
best_model.fit(train_x,train_y)
best_model.best_score_
0.9714285714285714
best_model.best_params_
{'C': 1, 'kernel': 'linear'}
best_model.best_estimator_
best_model.cv_results_
注:
1、以前版本是best_model.grid_scores_,现在已经移除
2、这个函数输出很多数据,不方便查看,一般不用
在实际使用中,如果计算资源够用,一般采用第三种万能公式。如果,为了节约计算资源尽快算出结果,也会采用以后介绍的手动调参方式。
文章来源:https://zhuanlan.zhihu.com/p/88729124

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢