
点击下方卡片,关注「AI视界引擎」公众号

面部特征点检测是驾驶员状态跟踪的基本技术,在实时估计方面一直备受需求。作为一个Landmark坐标预测,基于Heatmap的方法以其高准确性而闻名,而LiteHRNet可以实现快速估计。然而,使用LiteHRNet时,连接不同分辨率特征图的融合块的高计算成本问题尚未解决。
此外,Lite-HRNet没有采用HRNetV2中使用的强输出模块。鉴于这些问题,作者提出了一种称为Lite-HRNet Plus的新型架构。
Lite-HRNet Plus实现了两项改进:
基于通道注意力的新型融合块
使用多分辨率特征图的计算强度较低的新型输出模块
通过在两个面部特征点数据集上进行的实验,作者确认Lite-HRNet Plus相对于传统方法进一步提高了准确性,并在计算复杂度在10M FLOP范围内实现了最先进的准确性。
面部特征点检测是面部处理流程的关键要素之一,例如驾驶员状态跟踪。自动面部特征点检测极大地促进了这种基于代理的界面的发展。近年来,卷积神经网络(CNN)在面部特征点检测方面取得了高准确性,有两种类型的方法:
基于回归的方法
基于Heatmap的方法
特别是,使用高分辨率表示的基于Heatmap的方法取得了高性能。然而,在现实世界的环境中,使用有限的计算资源实时进行快速估计的Landmark检测也是必要的,因为作者必须在汽车SoCs上同时实时运行面部检测、头部姿态估计和凝视估计等多个进程。
对于作者的研究,作者将模型的目标计算复杂度设置在10M FLOP的范围内,这是每张图像处理10毫秒的标准,因为作者必须在汽车SoCs上实时运行面部特征点检测和其他进程,包括面部检测、头部姿态估计和凝视估计。然而,在以前的研究中,没有在这个FLOP范围内保持高准确性的方法。
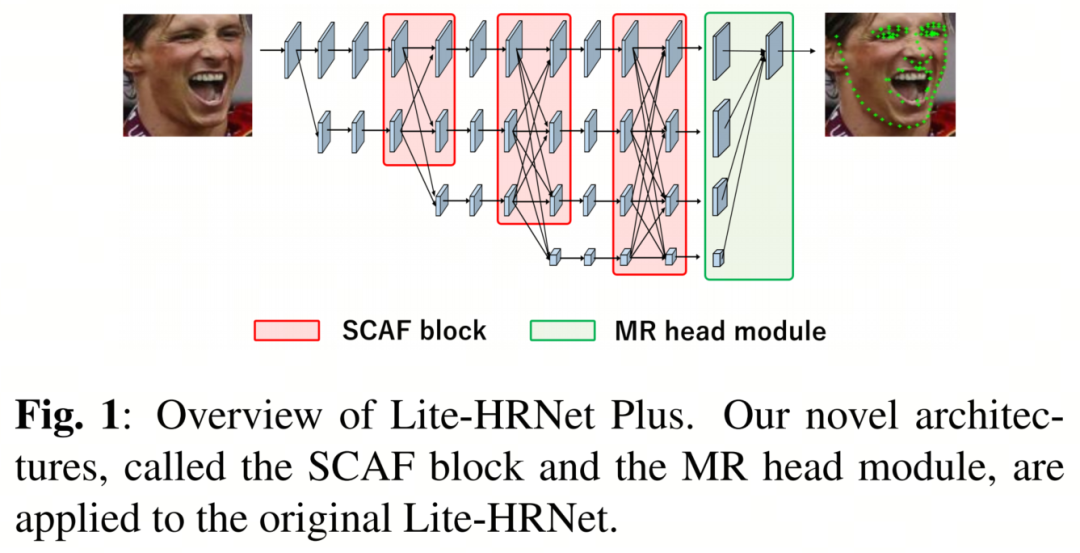
受上述问题的启发,作者研究了一种称为Lite-HRNet Plus的新型网络架构。图1显示了Lite-HRNet Plus的概述。Lite-HRNet Plus基于Lite-HRNet,该网络应用了Shuffle块到HRNet并引入了有效的条件通道权重。
作者为Lite-HRNet Plus提出了2种新型架构。首先,作者提出了一种分阶段通道注意力融合(SCAF)块,它在明显降低计算复杂性的同时防止了准确性下降。尽管Lite-HRNet具有连接不同分辨率子网络之间特征图的融合块,但作者确认,在融合块中广泛使用的逐点卷积层是计算瓶颈。作者提出的SCAF块不使用逐点卷积层,而是使用通道注意力权重连接不同分辨率的特征图。通过应用SCAF块,作者可以将融合块的整体计算复杂性减少约80%。
其次,作者提出了一个多分辨率(MR)输出模块,该模块使用各种分辨率的特征图进行较低计算复杂性的预测。Lite-HRNet采用基于HRNetV1的输出模块,该模块仅输出从高分辨率流计算得到的高分辨率表示。相比之下,HRNetV2采用了一个输出模块,该模块结合了所有高到低分辨率并行流的表示。
尽管HRNetV2的输出模块对于特征点检测是有效的,但其计算复杂性大于HRNetV1的计算复杂性。MR输出模块以与HRNetV2不同的方式组合高到低分辨率的特征图,并且可以实现比传统输出模块更高的准确性和更低的计算复杂性。
作者在面部特征点检测数据集上对Lite-HRNet Plus进行了实验评估。根据实验结果,作者确认即使计算复杂性在10M FLOP范围内,Lite-HRNet Plus仍然比传统方法实现了显著更高的准确性。
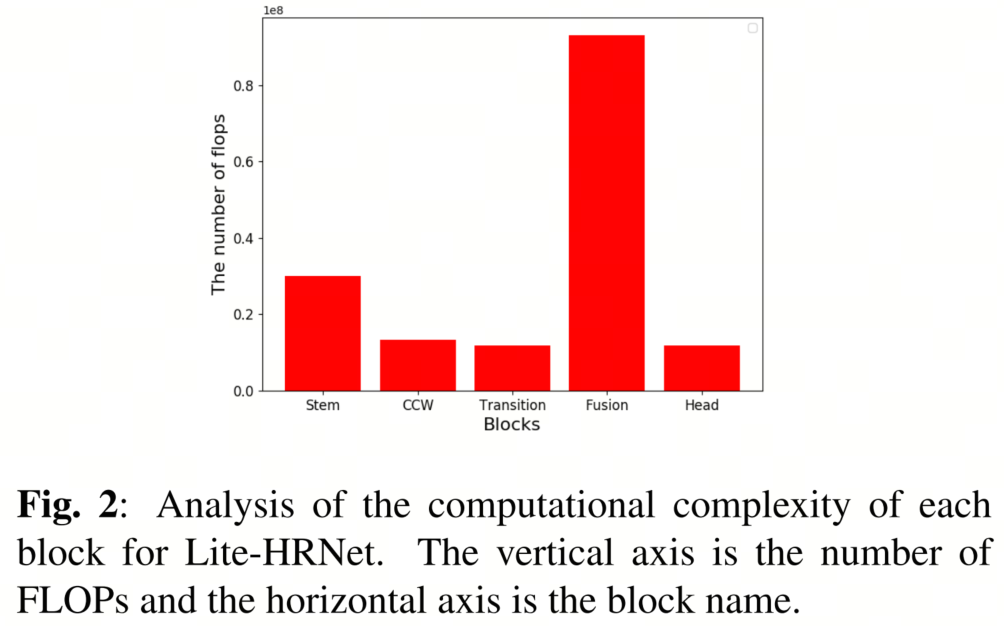
图2显示了Lite-HRNet每个块的计算复杂性分析。Lite-HRNet由5个块组成,分别称为Stem、条件通道加权(ccw)、Transition Block、Fusion和Head。如图2所示,作者确认将不同分辨率子网络之间的特征图连接起来的融合块具有最高的计算复杂性。
作者认为融合块中包含的逐点卷积层(PW Conv)具有很大的计算复杂性,因为它处理了大量通道。PW Conv是一种只考虑通道方向的卷积操作。PW Conv的计算复杂性取决于通道数,表示为NMHW,其中N和M分别是输入和输出特征图的通道数,H和W分别是特征图的高度和宽度。由于不同分辨率的特征图具有不同数量的通道,因此需要使用PW conv将它们对齐到相同数量的通道,这预计会导致较大的计算复杂性。
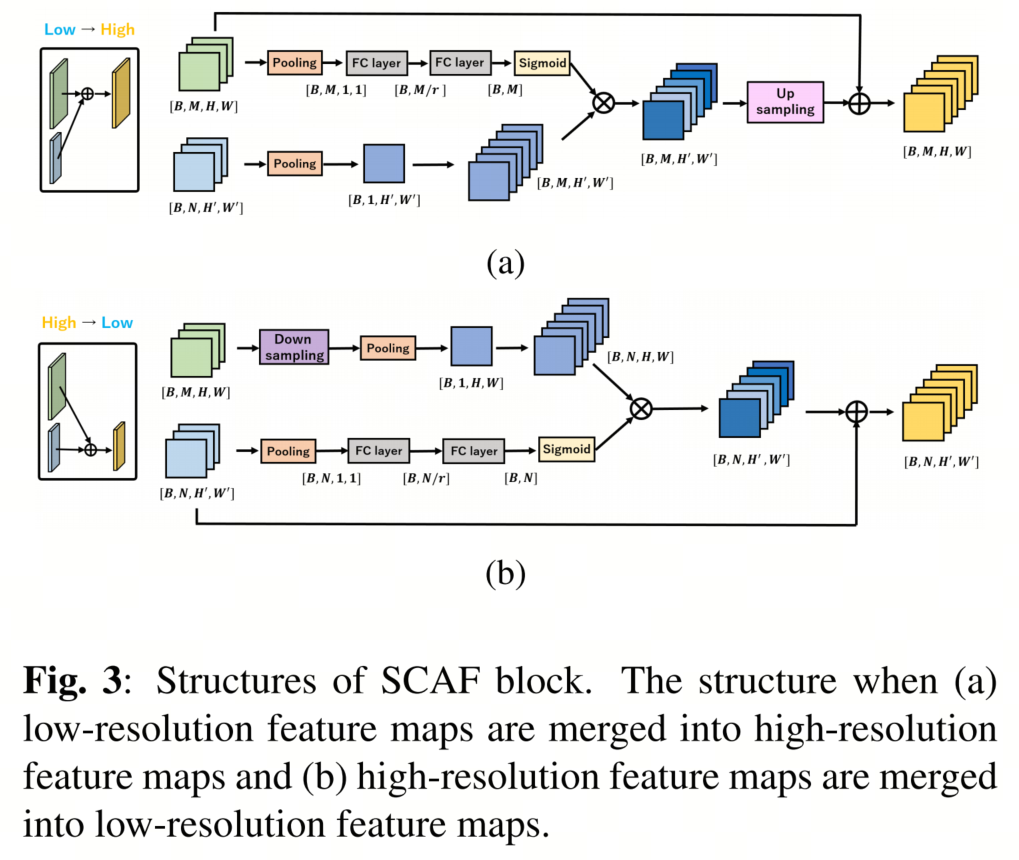
因此,作者提出用不使用PW Conv的分阶段通道注意力融合(SCAF)块替换原始融合块。如图3(a)所示,当将低分辨率特征图合并到高分辨率特征图时,沿通道方向执行低分辨率特征图的全局平均池化,并生成平均特征图。在高分辨率特征图中,沿空间方向执行全局平均池化,只保留通道信息,因此使用全连接层和Sigmoid函数生成范围在[0,1]之间的标准化注意权重。
然后,将从高分辨率特征图生成的注意权重与平均低分辨率特征图相乘,生成新的特征图。最后,通过上采样对齐融合块和高分辨率特征图的空间大小,并将这些特征图相加以生成融合块的输出特征图。当将高分辨率特征图合并到低分辨率特征图时,如图3(b)所示,以相同方式生成新的特征图;
此外,从低分辨率特征图生成注意权重,并将其与从高分辨率特征图生成的平均特征图相乘。然后将新的特征图添加到低分辨率特征图中。
在SCAF块中,仅计算通道方向上的加权,因此理论计算复杂性可以表示为,其中是缩减比率,使用与上面相同的符号。由于SCAF块的计算复杂性仅由和决定,而不是PW Conv的计算复杂性NMHW,因此SCAF块可以有效地减少计算复杂性。
在HRNetV2的输出模块中,低分辨率特征图被上采样并与高分辨率特征图串联起来,最终的预测Heatmap,其通道数量等于特征点数量,是通过PW Conv生成的。由于这个输出模块在面部特征点检测中非常有效,作者期望它对Lite-HRNet也会有效。然而,这个模块显著增加了生成最终预测Heatmap的计算复杂性,因为它将不同分辨率的特征图结合在一起,并使用PW Conv输出Heatmap。
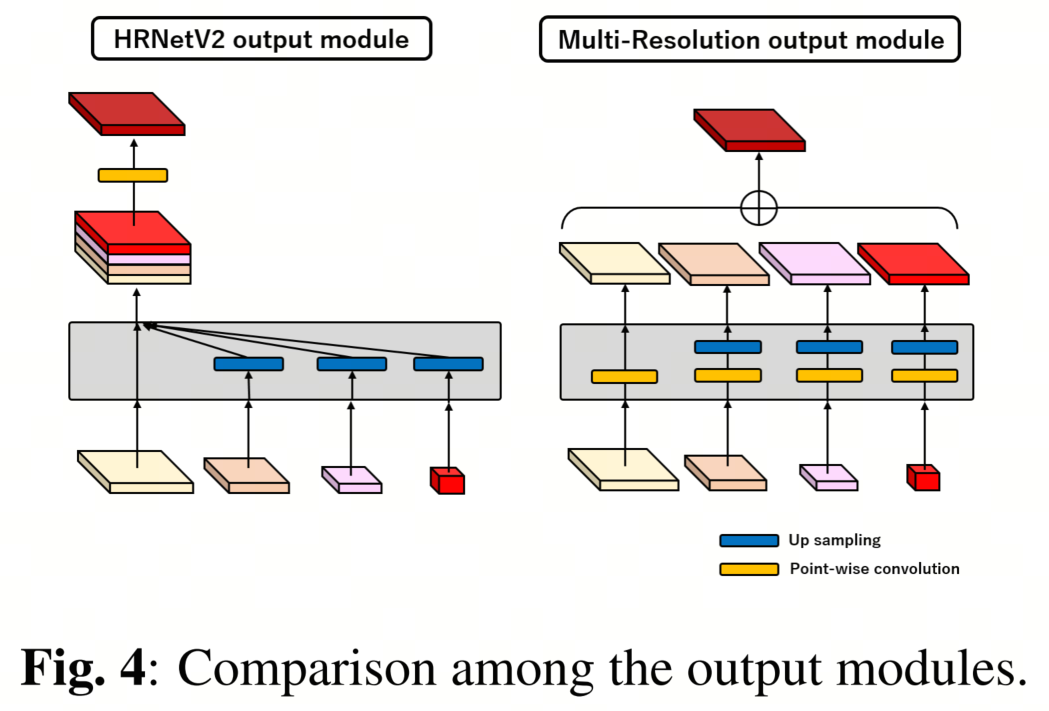
因此,作者提出了一个多分辨率(MR)输出模块。图4显示了HRNetV2和MR输出模块结构的比较。在MR输出模块中,PW Conv应用于不同分辨率的每个特征图以输出预测Heatmap,然后将每个Heatmap相加以生成最终的预测。作者不需要串联特征图,MR输出模块的计算复杂性可以减少到仅为HRNetV2输出模块的约十五分之一左右,并且适应于Lite-HRNet输出模块的计算复杂性的约1.87倍。
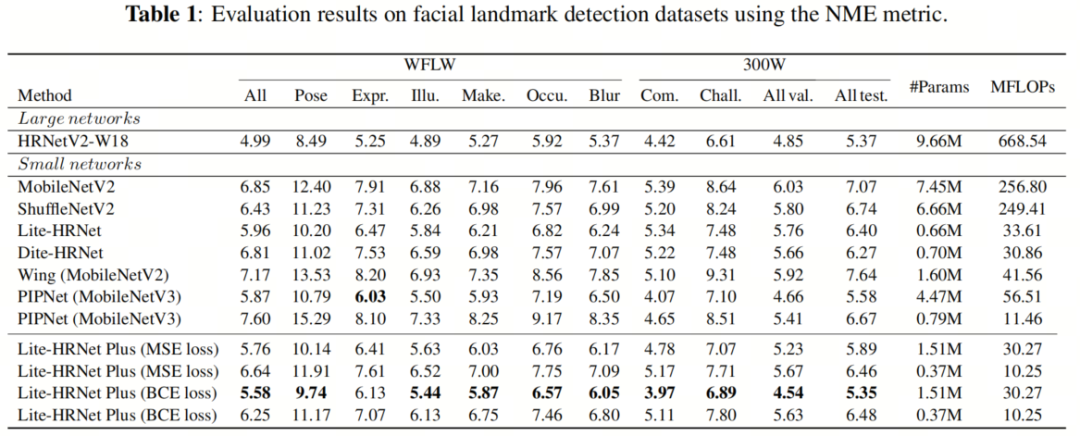
表1显示了在WFLW和300W数据集上进行的评估结果。作者将作者的方法与传统的轻量级方法进行了比较。此外,尽管均方误差(MSE)损失在传统的面部特征点检测中被用作损失函数,但作者还评估了二元交叉熵(BCE)损失,因为它对小错误更敏感。
如表1所示,尽管Lite-HRNet Plus具有最低的计算复杂性,但性能更好。将Lite-HRNet Plus与在10.25M FLOPs时使用BCE损失的PIPNet在11.46M FLOPs时进行比较,在WFLW数据集上,NME提高了1.35%,在300W数据集上,测试集的NME提高了0.19%。这些结果表明,Lite-HRNet Plus优于传统的轻量级方法。
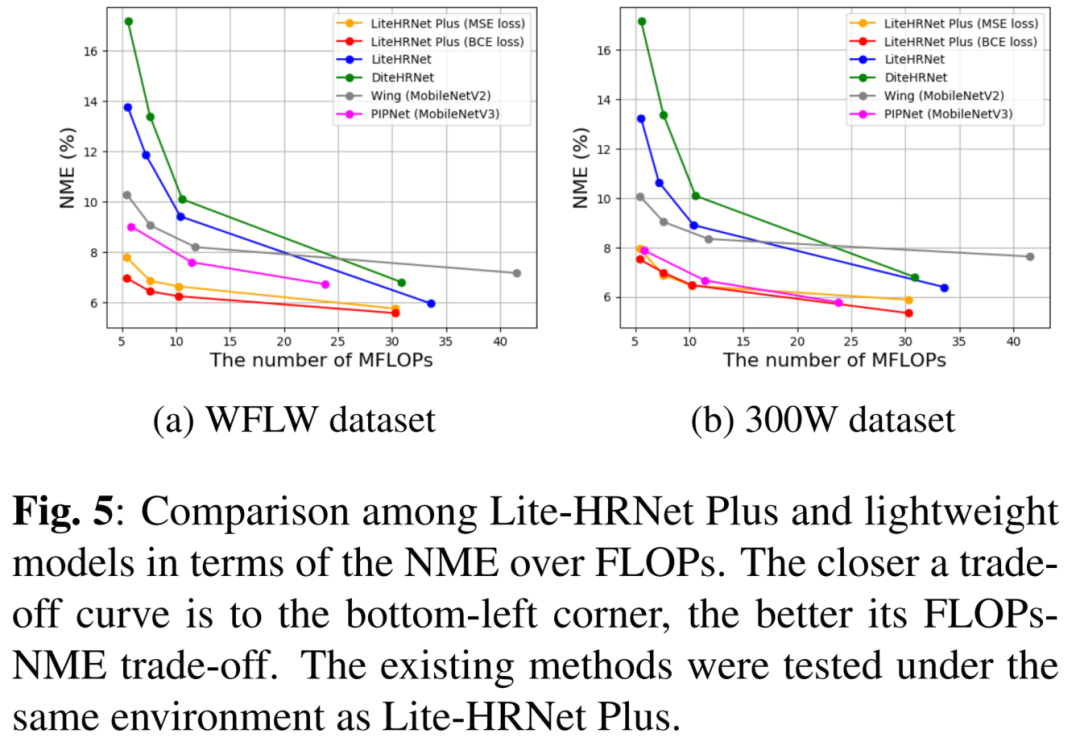
图5显示了在WFLW和300W数据集上的速度和准确性权衡方面的现有方法和作者方法的图形比较。权衡曲线越接近左下角,FLOPs-NME权衡越好。在使用各种轻量级方法进行验证后,作者确认Lite-HRNet Plus在FLOPs-NME权衡方面表现最佳。
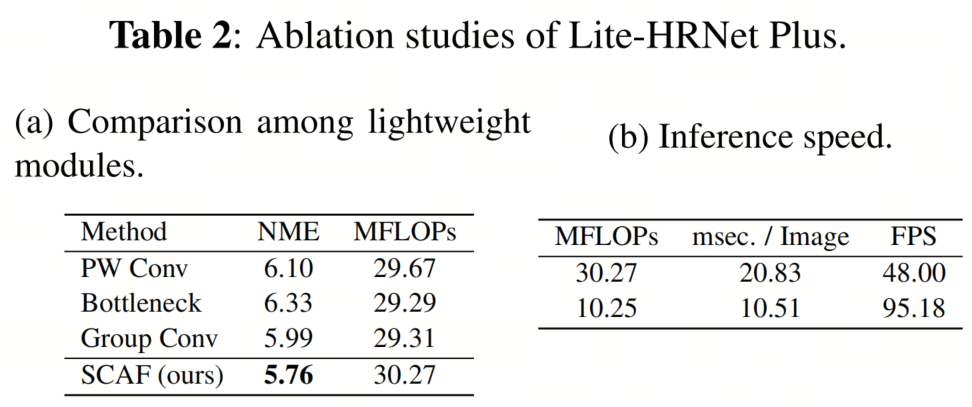
表2(a)显示了用于融合块的轻量级技术之间的比较。作者将SCAF块与其他降低计算复杂性的方法进行了比较:PW Conv、带Bottleneck的PW Conv(Bottleneck)和分组卷积(Group Conv)。如表2(a)所示,如果准确性相同,SCAF块可以实现最小的计算复杂性,并且与传统的轻量级技术相比,可以进一步减少计算复杂性。
表2(b)显示了Lite-HRNet Plus对96×96像素人脸图像的推理时间。作者在具有ONNX Runtime框架的Intel Core i9-7960X CPU上测量了每个人脸图像的推理时间。如表2(b)所示,Lite-HRNet Plus在30.27M FLOPs模型上实现了48.00 fps的速度,在10.25M FLOPs模型上实现了95.18 fps的速度。结合表1的结果,Lite-HRNet Plus可以在实时速度下实现高准确性。
[1].LITE-HRNET PLUS: FAST AND ACCURATE FACIAL LANDMARK DETECTION.
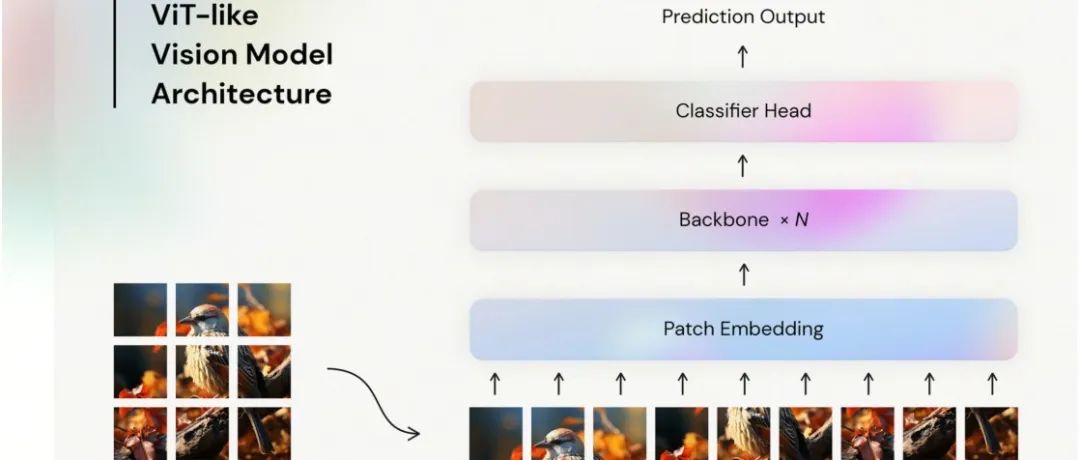
ViT Backbone大演习 | 哪个Vision Transformer 性价比最高?哪个才是你的最爱?
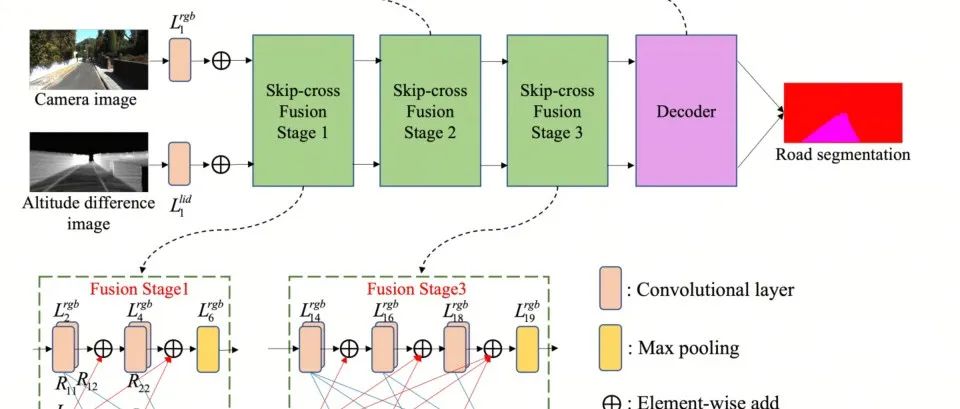
清华联合北航提出全新多模态融合方法SkipcrossNets,更快更强!!
CS-Mixer | MLP-Like 中的王者,让MLP Token也有跨尺度交互

点击上方卡片,关注「AI视界引擎」公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢