
深度学习自然语言处理 原创
作者:Winnie
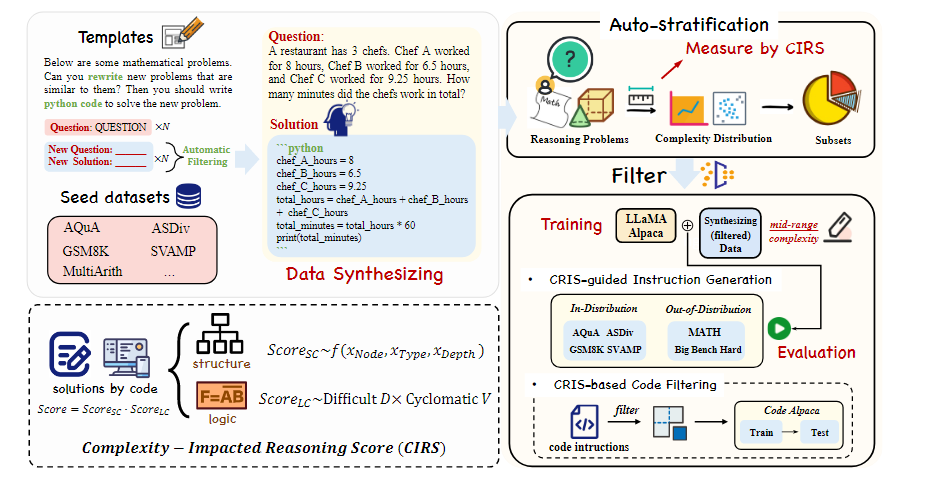
代码数据对提升LLM的推理能力有效吗?为了解答这个问题,最近的一篇工作提出了CIRS(复杂度影响推理分数)这一新的指标,用来衡量代码数据的复杂性,进而验证不同复杂度的代码数据与LLM推理能力的关系。让我们一起来看看有什么有趣的发现吧。
Paper:
When Do Program-of-Thought Works for Reasoning?Link:
https://arxiv.org/abs/2308.15452

在介绍这篇论文之前,先让我们回顾一下PoT(Program-of-Thought)。它是一种解决数值推理任务的方法,将计算和推理两个任务分离开来。具体来说,PoT将问题简化成编程逻辑,并用额外的语言解释器,例如用Python进行编译,得出结果。这种方法能够在几个数学数据集上显著提高了性能,超过了CoT的表现。
下图是CoT与PoT方法的对比。
PoT虽然有所表现,但在什么条件下,它最能提升推理能力?为了解答这个问题,研究者提出了CIRS这一新指标。CIRS的目标是通过量化代码的结构和逻辑复杂度,来探讨它们如何影响LLM的推理能力。
我们假定代码数据可以提升LLM推理能力,是由于下面两个原因:
结构上,与自然语言相比,代码具有复杂结构建模能力; 逻辑上,代码面向过程的逻辑有助于解决多步推理问题。
因此,CIRS计算代码复杂度从结构和逻辑两个方面衡量。
结构上:用一种叫做“抽象语法树”(AST)的技术来编码代码的结构信息。 逻辑上:通过计算代码中操作数和运算符的数量来衡量代码逻辑的复杂度。
最后,CIRS指标就是结构复杂度和逻辑复杂度的乘积。CIRS给了我们一个全面但直观的量化方式,来观察代码复杂度对LLM推理能力的影响。
研究进行了以下实验:
首先进行数据合成,并用CIRS计算代码数据的复杂度,根据计算结果,将数据分成三个不同的子集; 基于LLAMA1.0版本训练了三个不同参数大小的模型,从每个子集中随机选择1,700个实例来构建训练和验证数据集,验证不同复杂度的代码数据对模型性能的影响; 最后利用自动合成和分层算法,并以最有效的复杂度评估其在过滤数据上的性能,从源数据集过滤掉更多数据来训练增强的推理模型。
实验结果有几个关键发现:
1️⃣ 适度复杂度最佳:如果代码数据过于简单或复杂,LLM的推理能力反而会受到限制。
2️⃣ 参数越多越好:大型LLM(比如有750亿参数)在推理任务上表现得更出色。
3️⃣ 局限:当代码过于复杂,即使是大型LLM也难以理解和推理。
尽管PoT在一些数据集上取得了比CoT更好的结果,但我们依然不清楚这种方法是如何促进推理的。这一研究是一个初步的尝试,不仅探索了代码数据对LLM推理能力的影响,还为如何设计更有效的推理模型提供了新的思路。

一起在人工智能时代旋转跳跃眨巴眼
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢