
今天是2023年9月4日,星期一,北京,阴天,新的一周开始了。
天已经入秋,早上骑车已经有露水降下来,北方的朋友注意早晚别着凉。
周末看到几个篇文章,地址https://twitter.com/FinanceYF5/status/1697735239160959455,https://mp.weixin.qq.com/s/-uCVv5SOLoZUATvqiTsdoA,https://mp.weixin.qq.com/s/x6rfj1zZYFeg5RVrvAkLdQ其中有些观点很有趣,引用其中的五点给大家一起看看:
1、Infra(硬件底层)团队必须比 Modelling(模型)团队还要强大。做过大模型 Infra 的人比做大模型的人还要贵、更稀缺;而会做 Scaling Law(扩展定律,模型能力随着训练计算量增加而提升)的人比会做大模型 Infra 的人更稀缺。【归根结底,大模型的基建比算法更为重要,本质就是数据+工程】9
2、读通论文也会少走很多弯路,因为有些论文是故意把不奏效的东西写出来,不会读很容易被带偏。 【所以这也是我们读论文时需要注意的点】,此外,尽管在跟 GPT-3、GPT3.5 等 SOTA(state of the art,先进)模型的各种评比中,Llama2 的差距不大。但实际上用起来,今天 Llama2 的能力跟 GPT-4,以及 Bard(谷歌的大语言模型)的下一个版本,差别巨大。【这其实是片面性评估带来的问题】
3、当技术换代或者更强的开源模型出来,过去的投入可能完全「打水漂」。【但我们需要follow住,常抬头看看】
4、很多原先想做「最好大模型」的企业,其实需要重新思考创业的生态位,选择拥抱开源,在开源的底座上做「为我所用」的东西。 基于开源模型做,后续的投入门槛并不低,能力要求也不低,用开源只是有效降低了冷启动的成本,对创业者这并不丢人。 【这是一门经济学,现在大模型纠结的就是ROI】
5、真正去跟 B 端客户谈,客户只需要语言理解、多轮对话和一定的推理能力,其他的 AGI(通用人工智能)能力一概不要。甚至其他能力反而给客户带来了麻烦。一个通用的大模型,并不意味着可以解决所有问题。B 端客户的很多场景,通用大模型放上去并不奏效。AI Agent 这个方向还需要探索。Agent 怎么样比 ChatGPT 解决了更多问题,很难被讲清楚。【这是B端落地的一个痛点】
这些都值得我们去思考,而回到正题,我们再看看看大模型技术层面以及模型榜单上的一些事。
本文主要介绍基于知识图谱进行大模型问答以及任务编排、CEVAL榜单评测中能够得到一些启示,供大家一起参考。
一、基于知识图谱进行大模型问答以及任务编排
1、基于知识图谱增强大模型的文档问答
基于知识图谱增强大模型的文档问答路线如下:
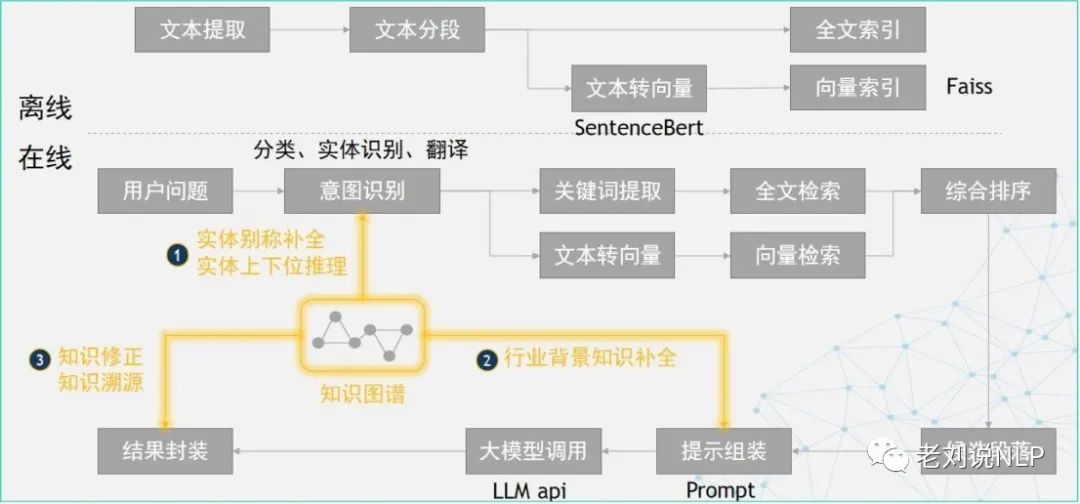
首先,离线部分,对文档进行预处理,构建段落级索引,包括全文索引和向量索引;
其次,在线部分,在意图识别阶段,用知识图谱进行实体别称补全和上下位推理;在Prompt组装阶段,从知识图谱中查询背景知识放入上下文;在结果封装阶段,用知识图谱进行知识修正和知识溯源。
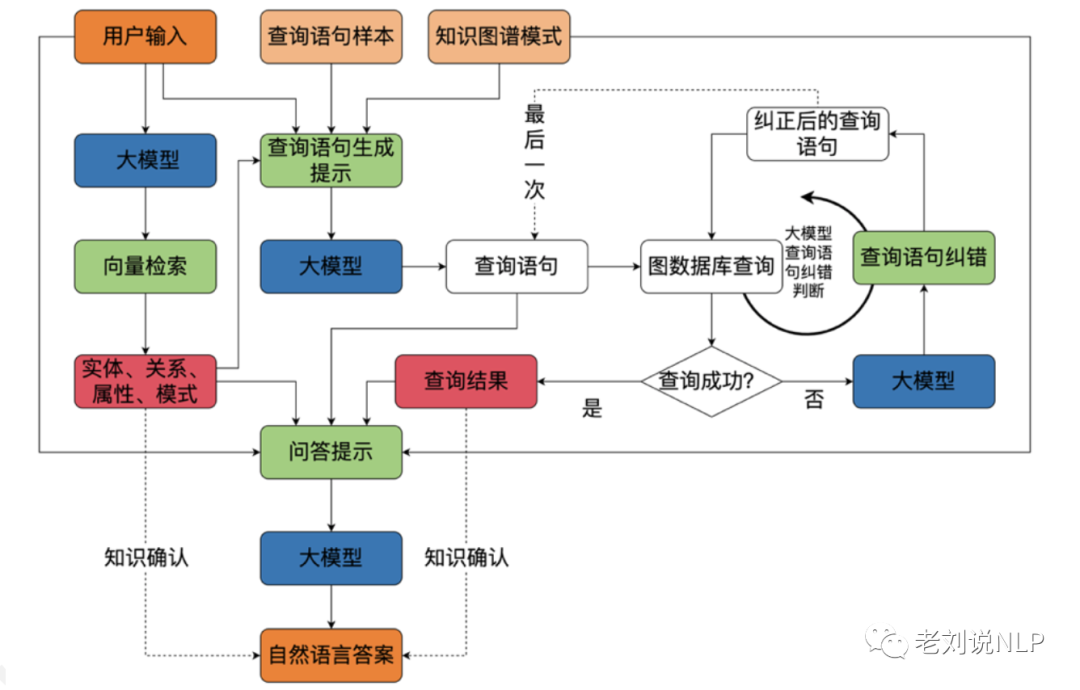
2、大模型+知识图谱实现可控可信可靠问答的架构
如下图所示,结合大语言模和向量检索的外挂能力,将自然语言交互和知识图谱结合,形成可控、可信、 可靠的问答。
值得注意的是,其中关于知识确认的环节,用来对查询、生成后两个阶段进行约束。
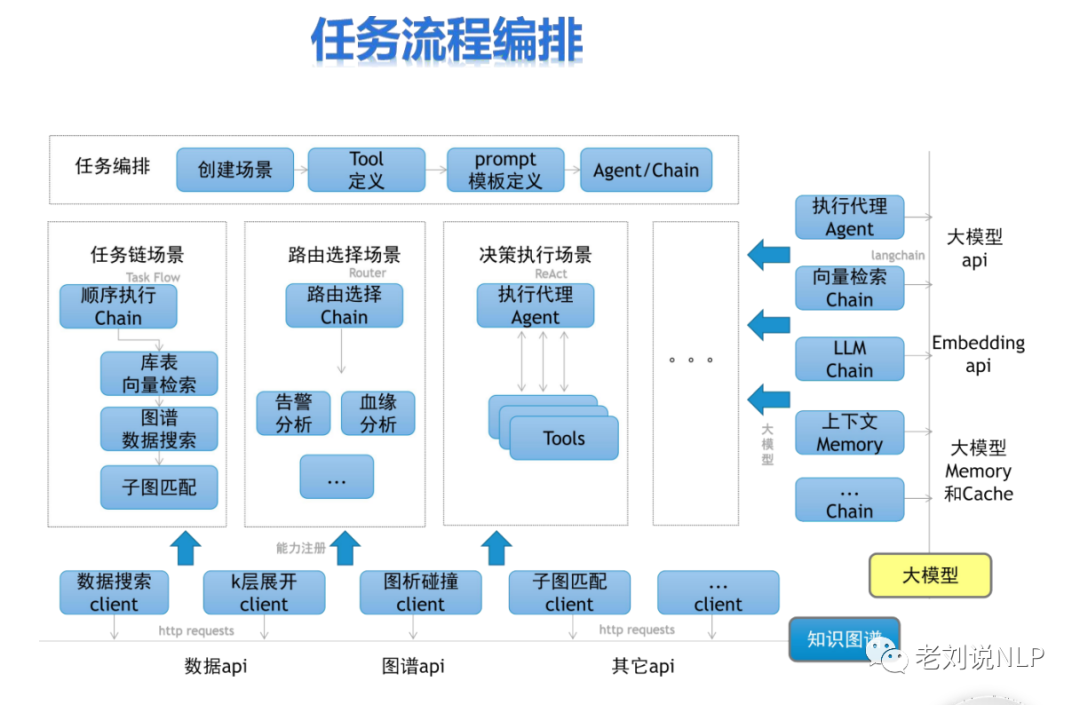
3、利用知识图谱进行大模型执行逻辑编排
利用知识图谱进行任务流程编排,尤其是针对任务链场景。其核心在于,可以事先利用图谱地结构将各个部分之间的逻辑依存关系进行存储,例如顺序执行Chain,关于这块,也有人会扯上事理图谱地概念。
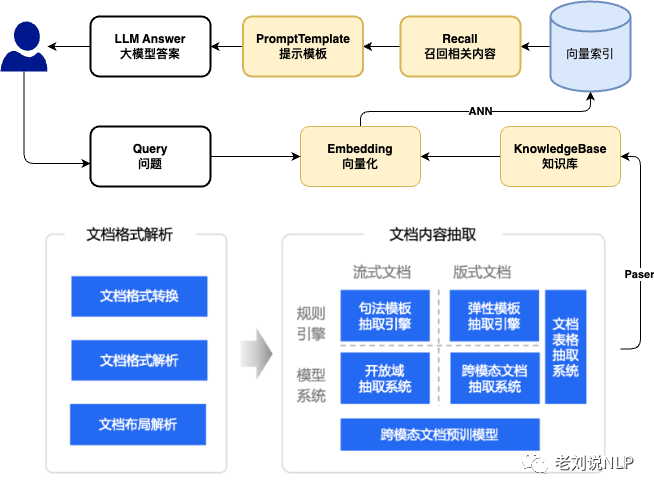
4、加入文档智能的问答闭环方案
加入文档智能的问答闭环方案,将文档智能提升到一个较高的位置,可以先通过文档智能进行处理,将表格、图表等进行处理。

二、CEVAL榜单评测中能够得到一些启示
最近在跟进大模型榜单打榜的工作,而周末一过,在ceval榜单上,GPT4也即将跌出前十。
这个榜单似乎已经彻底玩坏,在某种程度上,似乎没有了参考价值?但这并不重要,理解其背后一些有意思的结论更有趣。
Ceval官方github地址:https://github.com/SJTU-LIT/ceval/blob/main/resources/tutorial.md针对该评测有一些很有趣的点,本文引用写出来,与大家一起分享:
首先,在评测prompt构造方面,存在如下四种不同的格式:
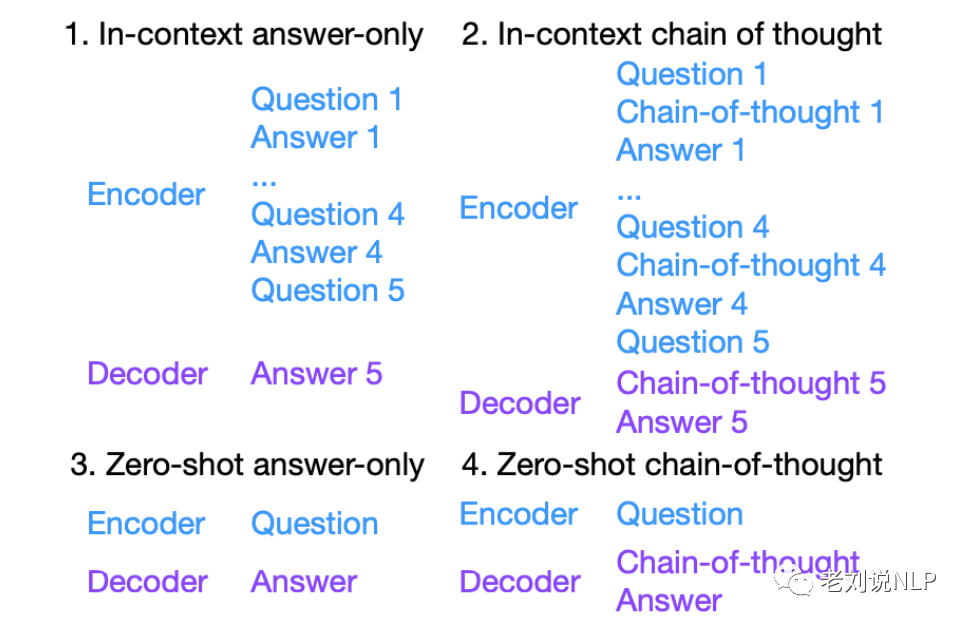
其中,few-shot chain-of-thought上,一般 CoT 在模型超过 65B 之后才会显著有效。除此之外,在Decoding策略,fewshot好还是zeroshot好等也给出了一些参考的结论,如下:
1、Decoding的方法
测试的时候一般temperature设置为0做greedydecoding,因为这种variance低; 大模型一般不用beamsearch,贵且作用不大; 上线一般用sampling,因为用户友好,说错了可以再说一遍。
2、以few-shot为准还是以zero-shot为准?
一般来说,pretraining阶段的模型few-shot的效果总是会比zero-shot好一些,但是经过instruction tuning之后的模型,且instruction tuning没有few-shotdata的话,很可能zero-shot会更好; Few-shot是面向开发者的,因为在构造基于LLM的应用的时候,开发者总是希望用prompt engineering的方法进一步提升模型的效果, 在这种情况下,模型相当于一个操作系统;Zero-shot是面向用户的,因为用户没工夫写prompt, 在这种情况下,模型相当于一个Chatbot;建议开发两个版本,一个面向开发者,把in-context learning的能力拉满,另一个面向用户,把zero-shot的能力拉满。
3、是否需要做prompt engineering
对于pretrained checkpoint(没有经过instruction tuning)
prompt的不同会得到很不同的效果; 给定了default prompt,这个prompt不一定是最优的; 在实际操作的过程中,需要区分分数的提高是来自于模型的提升还是来自于prompt的提升; 如果目标是开发模型,则推荐不要做太多的prompt优化。
对于instruction-tuned checkpoint
prompt的差异导致模型效果的variance会减小,但是也无法忽略; 经过了instruction tuning之后,模型对prompt engineering的需求会减小,但是仍然存在
所以推荐报两份结果,一份是使用dev文件夹里的数据作为defaultprompt报一次结果,此结果看作baseline;另一份是根据自己的模型做prompt engineering然后报一次结果,此结果看作upperbound;
4、理解[推理]和[知识]
大模型测测试题目一般分推理和知识两种类型:
有些题目天生不需要reasoning,比如中国语言文学里面一个是“《茶馆》的作者是谁”,这种不需要CoT,直接AO即可,CoT反而增加了distractor; 有些题目天生需要reasoning,比如求定积分,这种直接给答案基本上都是随着直觉瞎猜,还是得一步一步推; 一般而言,知识性的问题不大需要CoT,推理型的问题需要CoT; MMLU是一个典型的知识型数据集,所以PaLM在这上面AO比CoT好; BBH是一个典型的推理型数据集,这上面CoT显著好于AO; 在Ceval中,文科科目比较偏知识,理科科目比较偏推理; 在Ceval上理科CoT和AO效果差不多,但这并不意味着CoT没有用,而是因为模型在CoT的时候需要能推公式,但现在很多模型做不到这件事情。因此,如果能够增加公式推导中间过程的准确性,例如OpenAI:https://arxiv.org/abs/2305.20050,预测CoT的效果会比AO好很多;
[知识]和[推理]是两项可以显著区分大小模型的能力,其中
[推理]能力的区分度是最高的,比如说gsm8k这个数据集,GPT492分,LLaMA7b只有七分,模型每大一点基本上都是十几二十分的差距; [知识]的区分度没有[推理]这么高,但也很高;这里面模型每大一个台阶基本上是五六分的差距; [推理]能力小的模型基本没有,很多时候acc只有个位数; [知识]能力小模型也会有一点,比如MMLU上11Bflant5也有40+;
关于英文推理能力的benchmark,可以参见https://github.com/FranxYao/chain-of-thought-hub)
5、解读模型的分数
四选一,所以baseline是25分, 但是模型没训练好的话可能低于25分;CoT不一定能显著提升模型分数,因为只有在推理数据类任务上,模型强到一定程度之后,CoT才会有效,这也是为什么CoT是一个典型的涌现能力 CoT的模式下,目前只评价最终答案对不对,不评价中间过程对不对,这是因为中间过程和最终答案在大部分时候显著正相关,最终答案对了,中间不会错到哪里去;中间错的多了,最终答案不会对;这种做法可以绕开中间过程难以评价的问题; 单个科目平均只有200-300道题,所以在这上面效果超过5个点才能算显著;总的科目有15k的题目,这上面效果超过2个点可以认为显著; 具体的分数的显著性还跟模型天生的variance相关,因此推荐多跑实验观察。
总结
本文主要介绍了基于知识图谱进行大模型问答以及任务编排、CEVAL榜单评测中能够得到一些启示,供大家一起参考。
文首说到的一些观点其实很耐人寻味,大家可以再加以体会。
参考文献
1、https://github.com/SJTU-LIT/ceval/blob/main/resources/tutorial.md
2、《语义增强可编程知识图谱SPG》白皮书 v1.0
3、知识图谱与大模型融合实践研究报告
4、https://www.breezedeus.com/article/vie-nougat
5、https://twitter.com/FinanceYF5/status/1697735239160959455
6、https://mp.weixin.qq.com/s/-uCVv5SOLoZUATvqiTsdoA
7、https://mp.weixin.qq.com/s/x6rfj1zZYFeg5RVrvAkLdQ
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢