

以下文章来源于知乎:Kevin吴嘉文
作者:Kevin吴嘉文
编辑:极市平台
链接:https://zhuanlan.zhihu.com/p/641641929
本文仅用于学术分享,如有侵权,请联系后台作删文处理

LM.int8()
.from_pretrain() 时候传递 load_in_8bit 来实现,针对几乎所有的 HF Transformers 模型都有效。大致方法是,在矩阵点积计算过程中, 将其中的 outliers 参数找出来(以行或列为单位),然后用类似 absolute maximum (absmax) quantization 的方法,根据行/列对 Regular 参数做量化处理,outlier 参数仍然做 fp16 计算,最后相加。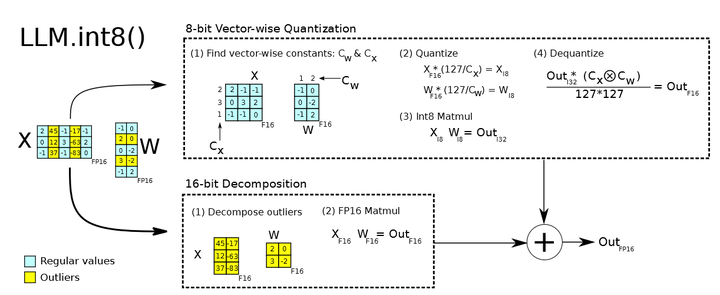
GPTQ
GPTQ-for-LLaMa
CUDA_VISIBLE_DEVICES=0 python llama.py /models/vicuna-7b c4 \
--wbits 4 \
--true-sequential \
--groupsize 128 \
--save_safetensors vicuna7b-gptq-4bit-128g.safetensors
CUDA_VISIBLE_DEVICES=0 python llama.py /models/vicuna-7b c4 \
--wbits 4 \
--groupsize 128 \
--load vicuna7b-gptq-4bit-128g.safetensors \
--benchmark 2048 --check
模型加载问题:使用 gptq-for-llama 时,因 transformer 版本不同,可能出现模型加载不上问题。如加载 TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ(https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/discussions/5) 时,用最新版的 GPTQ-for-LLaMa 就会出现权重于模型 registry 名称不匹配的情况。
left-padding 问题:目前 GPTQ-for-LLaMa 的所有分支(triton, old-cuda 或 fastest-inference-int4)都存在该问题。如果模型对存在 left-padding 的输入进行预测时候,输出结果是混乱的。这导致了 GPTQ-for-LLaMa 目前无法支持正确的 batch inference。
经过测试,问题存在于 llama.py中的quant.make_quant_attn(model)。使用quant_attn能够极大提升模型推理速度。参考这个历史 ISSUE,估计是position_id的推理 cache 在 Attention layer 中的配置存在了问题。left-padding issue(https://github.com/qwopqwop200/GPTQ-for-LLaMa/issues/89)GPTQ-for-LLaMa 版本变动大,如果其他仓库有使用 GPTQ-for-LLaMa 依赖的话,需要认真检查以下版本。如 obbabooga fork 了一个单独的 GPTQ-for-LLaMa 为 oobabooga/text-generation-webui 做支持。最新版的 GPTQ-for-LLaMa 在 text-generation-webui 中使用会有 BUG。
AutoGPTQ
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized(
model_dir, # 存放模型的文件路径,里面包含 config.json, tokenizer.json 等模型配置文件
model_basename="vicuna7b-gptq-4bit-128g.safetensors",
use_safetensors=True,
device="cuda:0",
use_triton=True, # Batch inference 时候开启 triton 更快
max_memory = {0: "20GIB", "cpu": "20GIB"} #
)
fused_attention,配置 CPU offload 等。用 AutoGPTQ 加载权重会省去很多不必要的麻烦,如 AutoGPTQ 并没有 GPTQ-for-LLaMa 类似的 left-padding bug,对 Huggingface 其他 LLM 模型的兼容性更好。因此如果做 GPTQ-INT4 batch inference 的话,AutoGPTQ 会是首选。exllama
gptq
GGML
.devops/full-cuda.Dockerfile 中的 EntryPoint。而后构建镜像:docker build -t local/llama.cpp:full-cuda -f .devops/full-cuda.Dockerfile .
docker run -it --name ggml --gpus all -p 8080:8080 -v /home/kevin/models:/models local/llama.cpp:full-cuda bash
# 转换 ggml 权重
python3 convert.py /models/Llama-2-13b-chat-hf/
# 量化
./quantize /models/Llama-2-13b-chat-hf/ggml-model-f16.bin /models/Llama-2-13b-chat-GGML_q4_0/ggml-model-q4_0.bin q4_0
./server -m /models/Llama-2-13b-chat-GGML_q4_0/ggml-model-q4_0.bin --host 0.0.0.0 --ctx-size 2048 --n-gpu-layers 128
curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "Once a upon time,","n_predict": 200}'
--ctx-size: 上下文长度。--n-gpu-layers:在 GPU 上放多少模型 layer,我们选择将整个模型放在 GPU 上。--batch-size:处理 prompt 时候的 batch size。
Once a upon time, 并返回 200 个字符,两者完成时间都在 2400 ms 左右(约 80 tokens/秒)。推理部署
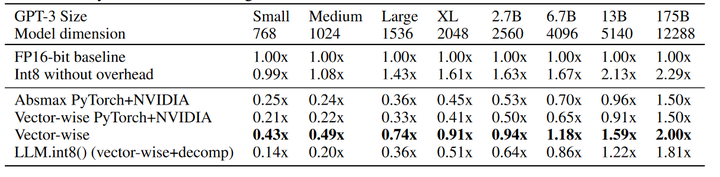
| Model_name | tool | tokens/s |
|---|---|---|
| vicuna 7b | float16 | 43.27 |
| vicuna 7b | load-in-8bit (HF) | 19.21 |
| vicuna 7b | load-in-4bit (HF) | 28.25 |
| vicuna7b-gptq-4bit-128g | AUTOGPTQ | 79.8 |
| vicuna7b-gptq-4bit-128g | GPTQ-for-LLaMa | 80.0 |
| vicuna7b-gptq-4bit-128g | exllama | 143.0 |
| Llama-2-7B-Chat-GGML (q4_0) | llama.cpp | 111.25 |
| Llama-2-13B-Chat-GGML (q4_0) | llama.cpp | 72.69 |
| Wizard-Vicuna-13B-GPTQ | exllama | 90 |
| Wizard-Vicuna-30B-uncensored-GPTQ | exllama | 43.1 |
| Wizard-Vicuna-30B-uncensored-GGML (q4_0) | llama.cpp | 34.03 |
| Wizard-Vicuna-30B-uncensored-GPTQ | AUTOGPTQ | 31 |
一些备注
模型推理的速度受 GPU 即 CPU 的影响最大。有网友指出 link,同样对于 4090,在 CPU 不同的情况下,7B LLaMa fp16 快的时候有 50 tokens/s,慢的时候能达到 23 tokens/s。 对于 stable diffusion,torch cuda118 能比 torch cuda 117 速度快上1倍。但对于 LLaMa 来说,cuda 117 和 118 差别不大。 量化 batch inference 首选 AUTOGPTQ (TRITON),尽管 AutoGPTQ 速度慢点,但目前版本的 GPTQ-for-LLaMa 存在 left-padding 问题,无法使用 batch inference;batch size = 1 时,首选 exllama 或者 GPTQ-for-LLaMa。 vllm 部署 fp16 的模型速度也不错(80+ tokens/s),同时也做了内存优化;如果设备资源够的话,可以考虑下 vllm,毕竟采用 GPTQ 还是有一点精度偏差的。 TheBloke 早期发布的一些模型可能无法加载到 exllama 当中,可以使用最新版本的 GPTQ-for-LLaMa 训练一个新模型。 当显卡容量无法加载整个模型时(比如在单卡 4090 上加载 llama-2-70B-chat),llama.cpp 比 GPTQ 速度更快(参考:https://www.reddit.com/r/LocalLLaMA/comments/147z6as/llamacpp_just_got_full_cuda_acceleration_and_now/?rdt=56220)。
推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢