
引言
本月学术进展主要是还是围绕大模型的应用,比如:斯坦福大学提出的多模态医疗模型Med-Flamingo、清华大学提出的ToolLLM来学习API调用、阿里提出的文生图多概念定制生成方法Cones2、国内AI初创公司LinkSoul.Al推出的中文版开源Llama2等;
除此之外,也不乏对基础模型的研究,比如:Meta发布SeamlessM4T多语言识别翻译模型、Meta发布代码生成的基础模型Code Llama、上海交通大学清源研究院等提出来的一个稳健有效的数据选择器,旨在实现用更少的数据微调模型并达到预期效果、清华提出了Prompt2Model平台架构用于专用模型的训练部署等。----所有论文下载可回复:8月论文
多模态医疗模型
最新!斯坦福 多模态医疗模型:Med-Flamingo,支持Few-shot问答,模型开源!
就医学而言,它涉及各个方面知识,需要整合各种信息。医学生成视觉语言模型(VLM)朝这个方向迈出了第一步,并有望带来更多的临床应用。然而,现有模型通常需要基于大量的下游数据集进行微调,这对于医学领域来说是一个相当大的限制。因为在许多医疗应用中数据稀缺,所以需要模型能够从Few-shot进行学习。
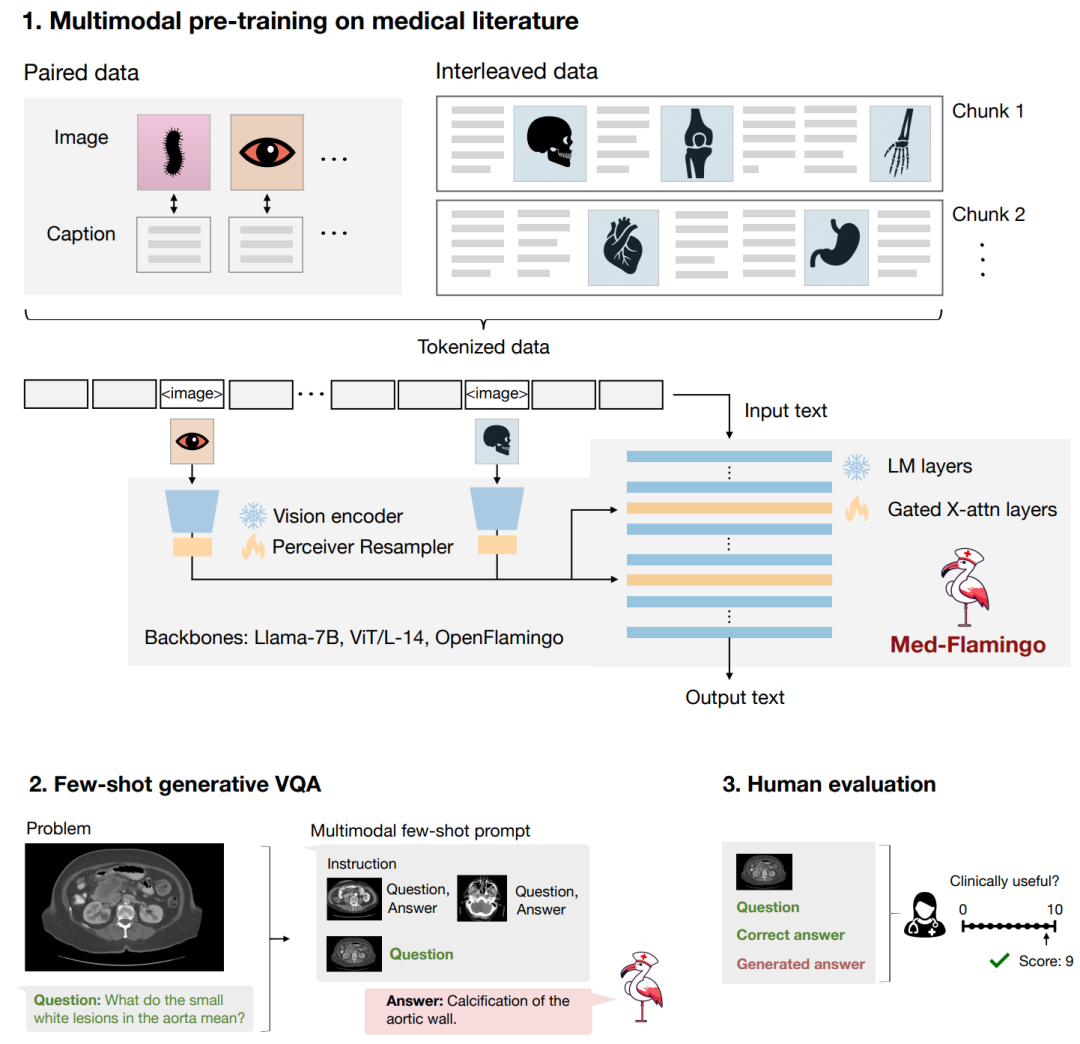
为此,「斯坦福」提出了Med-Flamingo,一种适用于医学领域的多模态少样本学习器。该学习器基于OpenFlamingo-9B,对出版物和教科书中成对和交错的医学图像-文本数据进行预训练,解锁了Med-Flamingo小样本生成医学视觉问答(VQA)能力,实验结果显示Med-Flamingo在临床医生的评分中将生成医学VQA的性能提高了20%。本文工作也代表了多模态医学基础模型的开发及其在医学领域,执行多模态上下文学习的能力方面向前迈出了重要一步。
清华ToolLLM
清华等提出新框架:ToolLLM,增强大模型API调用能力,性能堪比ChatGPT!
为了让开源 LLM 更好的使用外部工具,来自清华、人大、耶鲁、腾讯、知乎等多家机构的研究者联合撰写了论文,他们引入了一个通用工具使用框架 ToolLLM,该框架包括数据构建、模型训练和评估多项功能。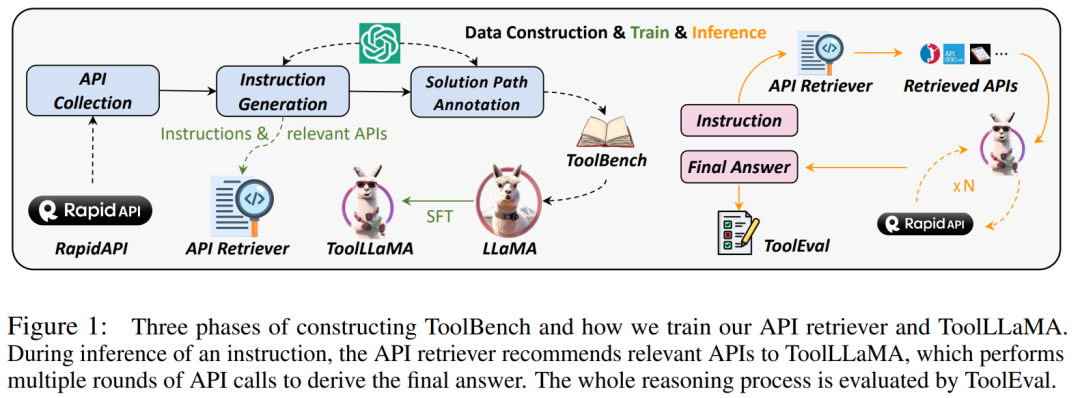 研究团队从 RapidAPI 收集了 16464 个 REST(representational state transfer)API。这些 API 涵盖 49 个不同类别,如社交媒体、电子商务和天气。对于每个 API,研究团队都会从 RapidAPI 抓取详细的 API 文档,包括功能描述、所需参数、API 调用的代码片段等。他们希望 LLM 能够通过理解这些文档来学习使用 API,从而使模型能够泛化到训练过程中未见过的 API。
研究团队从 RapidAPI 收集了 16464 个 REST(representational state transfer)API。这些 API 涵盖 49 个不同类别,如社交媒体、电子商务和天气。对于每个 API,研究团队都会从 RapidAPI 抓取详细的 API 文档,包括功能描述、所需参数、API 调用的代码片段等。他们希望 LLM 能够通过理解这些文档来学习使用 API,从而使模型能够泛化到训练过程中未见过的 API。
该研究在 ToolBench(指令调优数据集)上对 LLaMA 进行微调,得到了 ToolLLaMA。ToolEval(自动评估器)评估显示,ToolLLaMA 展现出了出色的执行复杂指令和泛化到未知 API 的能力,并且在工具使用方面性能与 ChatGPT 相媲美。
阿里&蚂蚁:Cones2
阿里 & 蚂蚁| 提出组合式的多概念定制生成方法,图片质量飞升!
文生图在最近一年取得了显著的进步,DreamBooth定制化生成工作,进一步证明了文生图的潜力,并且广泛引起了社区关注,相比于单概念生成,在一张图内定制多个概念是更加有趣且具有广泛应用场景(AI 影楼,AI 漫画生成....)。 阿里巴巴和蚂蚁集团的研究团队提出了组合式的多概念定制生成方法:Cones 2,能同时定制更多物体,且生成图片质量显著提升。Cones 2 优势主要体现在 3 个方面。(1)使用简单而有效的方法来表示概念,可以任意组合,复用各种训练好单概念,从而进行多定制概念生成,而无需为多概念进行任何重新训练。(2)使用空间布局作为指导,这在实践中非常容易获得,用户只需要提供一个 bounding box,即可以控制每个概念的特定位置,并同时减轻概念之间的属性混淆。(3)在一些具有挑战性的场景下也能取得令人满意的性能:进行语义相似的多定制概念的生成,如定制两只狗,并且可以交换眼镜;在概念数量上,也可以合成六个概念。
阿里巴巴和蚂蚁集团的研究团队提出了组合式的多概念定制生成方法:Cones 2,能同时定制更多物体,且生成图片质量显著提升。Cones 2 优势主要体现在 3 个方面。(1)使用简单而有效的方法来表示概念,可以任意组合,复用各种训练好单概念,从而进行多定制概念生成,而无需为多概念进行任何重新训练。(2)使用空间布局作为指导,这在实践中非常容易获得,用户只需要提供一个 bounding box,即可以控制每个概念的特定位置,并同时减轻概念之间的属性混淆。(3)在一些具有挑战性的场景下也能取得令人满意的性能:进行语义相似的多定制概念的生成,如定制两只狗,并且可以交换眼镜;在概念数量上,也可以合成六个概念。
中文版开源Llama2
主打一个中英文自由切换!中文版 开源Llama2 多模态大模型,完全可商用!
7月19日,Meta终于发布了免费可商用版本Llama2,让开源大模型领域的格局发生了巨大变化。Llama2模型系列包含70亿、130亿和700亿三种参数变体,相比上一代的训练数据增加了40%,在包括推理、编码、精通性和知识测试等许多外部基准测试中展示出了优越的表现,且支持多个语种。美中不足的是,Llama2语料库仍以英文(89.7%)为主,而中文仅占据了其中的0.13%。这导致Llama2很难完成流畅、有深度的中文对话。 在MetaAl开源Llama2 模型的次日,开源社区首个能下载、能运行的开源中文LLaMA2模型就出现了。该模型名为「Chinese Llama2 7B」,由国内AI初创公司LinkSoul.Al推出。Chinese-Llama-2-7b开源的内容包括完全可商用的中文版Llama2模型及中英文 SFT 数据集,输入格式严格遵循llama-2-chat格式,兼容适配所有针对原版llama-2-chat模型的优化。
在MetaAl开源Llama2 模型的次日,开源社区首个能下载、能运行的开源中文LLaMA2模型就出现了。该模型名为「Chinese Llama2 7B」,由国内AI初创公司LinkSoul.Al推出。Chinese-Llama-2-7b开源的内容包括完全可商用的中文版Llama2模型及中英文 SFT 数据集,输入格式严格遵循llama-2-chat格式,兼容适配所有针对原版llama-2-chat模型的优化。
Dynalang多模态模型
UC 伯克利 | Dynalang多模态模型:利用语言预测未来
当前,人与智能体(比如机器人)的交互是非常直接的,你告诉它「拿一块蓝色的积木」,它就会帮你拿过来。但现实世界的很多信息并非那么直接,比如「扳手可以用来拧紧螺母」、「我们的牛奶喝完了」。这些信息不能直接拿来当成指令,但却蕴含着丰富的世界信息。智能体很难了解这些语言在世界上的含义。
 UC伯克利Dynalang研究的关键思想是,我们可以将语言看作是帮助我们更好地对世界进行预测的工具,比如「我们的牛奶喝完了」→打开冰箱时没有牛奶;「扳手可以用来拧紧螺母」→使用工具时螺母会旋转。Dynalang 在一个模型中结合了语言模型(LM)和世界模型(WM),使得这种范式变成多模态。研究者认为,将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。
UC伯克利Dynalang研究的关键思想是,我们可以将语言看作是帮助我们更好地对世界进行预测的工具,比如「我们的牛奶喝完了」→打开冰箱时没有牛奶;「扳手可以用来拧紧螺母」→使用工具时螺母会旋转。Dynalang 在一个模型中结合了语言模型(LM)和世界模型(WM),使得这种范式变成多模态。研究者认为,将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。
OpenAI GPTBot 爬虫
OpenAI公布「官方爬虫」:GPT-5靠它训练,有需要可以屏蔽
训练 GPT-4 需要海量的数据,这可不是付费购买能解决的问题。大概率,OpenAI 用了网络爬虫。很多用户指控 OpenAI,理由就是这种手段会侵犯用户的版权和隐私权。为此,OpenAI直接公布从整个互联网爬取数据的网络爬虫 ——GPTBot。这些数据将被用来训练 GPT-4、GPT-5 等 AI 模型。不过GPTBot保证了,爬取内容绝对不包括违反隐私来源和需要付费的内容。
OpenAI表示:使用GPTBot爬取网络数据是为了改进AI模型的准确性、功能性和安全性。网站所有者可以根据需要允许和限制 GPTBot 爬取网站数据。
SeamlessM4T
All In One!Meta发布SeamlessM4T,支持100种语言,35种语音、开源、在线体验!
多语言识别翻译的研究一直都是学术界研究的重点。目前全球有几千种语言,在全球化背景下不同语言人群之间的交流越来越密切,然而学习一门外语的成本是非常大的。前两年的研究主要集中在一对一、一对多的研究,然而当面对这么多的语言时,既需要「考虑模型准确率,还需要考虑语种的识别」。最近,随着人工智能大型自然语言模型的发展,利用统一模型实现多语种识别翻译来实现不同语种之间交流逐渐的变成了可能。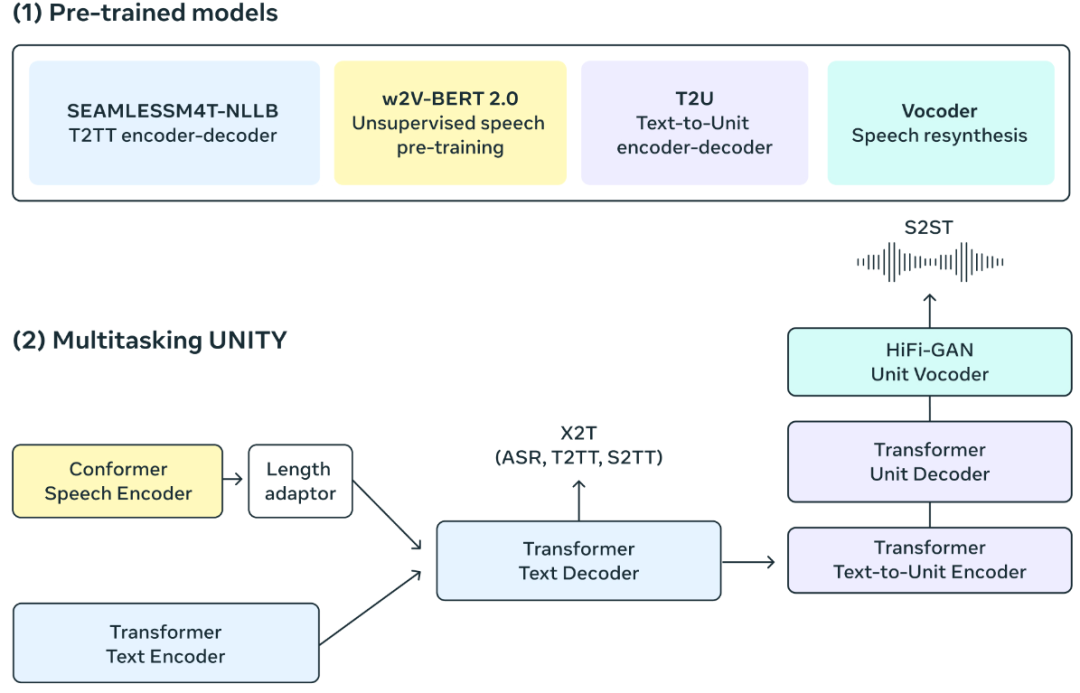 最近Meta刚刚发布的SeamlessM4T,它在近100种语言中实现了最先进的结果,并在自动语音识别、语音转文本、语音转语音、文本转语音和文本转语音等方面实现了多任务支持——全部集中在一个模型中!
最近Meta刚刚发布的SeamlessM4T,它在近100种语言中实现了最先进的结果,并在自动语音识别、语音转文本、语音转语音、文本转语音和文本转语音等方面实现了多任务支持——全部集中在一个模型中!
Code Llama
重磅!Meta官方发布:Code Llama,3个版本,支持10万Token,接近GPT-4,可商用!
Meta的开源Llama模型家族迎来了一位新成员——专攻代码生成的基础模型Code Llama。作为Llama2的代码专用版本,Code Llama基于特定的代码数据集在其上进一步微调训练而成。Meta 表示,Code Llama的开源协议与Llama2一样,免费用于研究以及商用目的。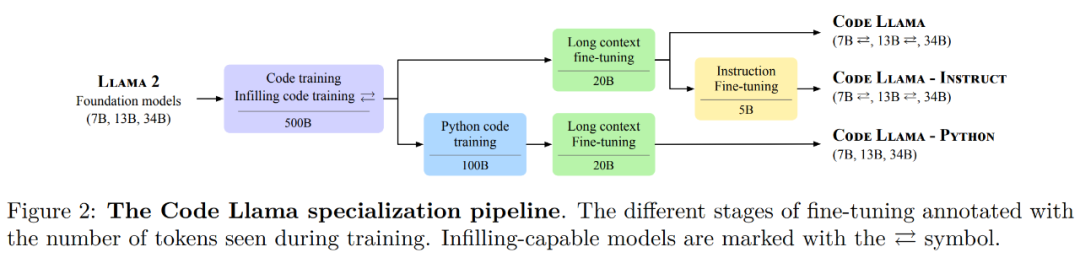 Code Llama 系列模型有三个版本,参数量分别为7B、13B 和 34B。并且支持多种编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C#和Bash。Code Llama 稳定支持了最高10万token的上下文生成。
Code Llama 系列模型有三个版本,参数量分别为7B、13B 和 34B。并且支持多种编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C#和Bash。Code Llama 稳定支持了最高10万token的上下文生成。
WizardCoder
远超GPT-4!微调Code Llama,WizardCoder 代码能力达到 惊人的73.2%!
WizardLM 团队的编程专用大模型 WizardCoder。该团队推出了基于 Code Llama 的最新版本模型 WizardCoder 34B,它利用 Evol-Instruct 进行微调而成。结果显示,它在 HumanEval 上的 pass@1 达到了惊人的 73.2%,超越了原始 GPT-4、ChatGPT-3.5 以及 Claude 2、Bard。此外,WizardCoder 13B 和 7B 版本也将很快到来。
Prompt2Model
卡内基梅隆 && 清华 | Prompt2Model:利用大模型Prompt,实现专有NLP模型生成!
随着大型语言模型 (LLM) 的应用,只需使用自然语言描述任务并提供一些示例,人们就能够方便的通过Prompt创建NLP系统。然而,相比传统的专用NLP模型,大型语言模型仍然存在计算资源紧张等问题。
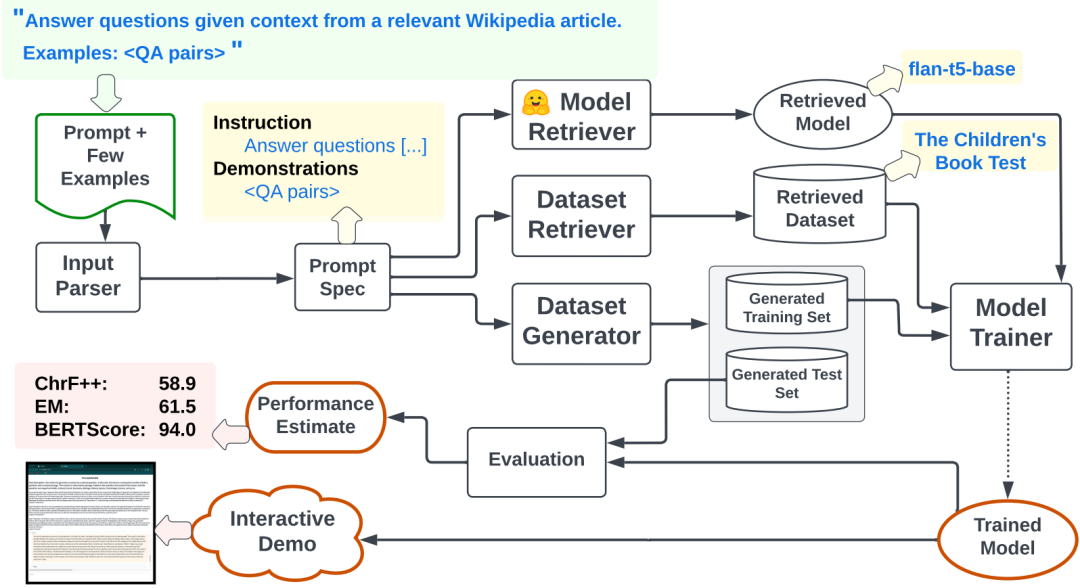 为此,本文提出了Prompt2Model平台架构,采用自然语言描述任务,并用它来训练有利于部署的专用模型。实验结果显示:Prompt2Model训练的模型的「性能比ChatGPT的结果平均高出20%,同时尺寸最多缩小700倍」。
为此,本文提出了Prompt2Model平台架构,采用自然语言描述任务,并用它来训练有利于部署的专用模型。实验结果显示:Prompt2Model训练的模型的「性能比ChatGPT的结果平均高出20%,同时尺寸最多缩小700倍」。
InstructionGPT-4
Less is More! 上交清源 && 里海 | 利用200条数据微调模型,怒超MiniGPT-4!
对于大型语言模型的微调对齐,并不是说微调数据越多越好。这一结论在Zhou等人发表的关于LIMA的论文中指出,他们选择750条数据集对LLaMA-65B进行微调得到LIMA模型,其性能非常好,甚至接近 GPT-4 和 Claude2 等最先进的专有模型的性能。但是,Zhou等人的数据集都是通过人工严格删选的,并没有给出如何选择高质量数据集的指导方针。
 「上海交通大学清源研究院和里海大学」的一个联合研究团队基于对MiniGPT-4模型的研究填补了这一空白,提出了一个稳健有效的数据选择器。这个数据选择器能够自动识别并过滤低质量视觉 - 语言数据,从而确保模型训练所使用的都是最相关和信息最丰富的样本。
「上海交通大学清源研究院和里海大学」的一个联合研究团队基于对MiniGPT-4模型的研究填补了这一空白,提出了一个稳健有效的数据选择器。这个数据选择器能够自动识别并过滤低质量视觉 - 语言数据,从而确保模型训练所使用的都是最相关和信息最丰富的样本。
NLP 的四个时代
斯坦福 | 曼宁教授长文梳理:NLP的四个时代,横跨70年,指出模型发展前景!
给大家分享的这篇文章,斯坦福曼宁教授于2021年10月份完稿的(比ChatGPT还要早上一年),最近才发布到期刊上的。由于原文比较长,所以作者结合自己的理解做了一些整理,感兴趣的可以阅读一下原文。「本篇文章主要概述了整个自然语言处理的发展过程,介绍近年NLP的发展以及相关神经网络模型技术,最后给出了未来语言模型的发展方向」。文章是2021年底完稿的,结合目前的语言模型的发展趋势,可以发现曼宁教授的预测太准了,和他两年前的预测基本一致!他的预测今天照样适用。
2023-09-05

2023-09-04
2023-09-01



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢