

以下文章来源于知乎:包包算法笔记
作者:包包算法笔记
链接:https://mp.weixin.qq.com/s/qQDV2L7EBQLivkoONgXR9A
本文仅用于学术分享,如有侵权,请联系后台作删文处理

1.预训练阶段(Pretraining Stage)
工欲善其事,必先利其器。
当前,不少工作选择在一个较强的基座模型上进行微调,且通常效果不错(如:[alpaca]、[vicuna] 等)。
这种成功的前提在于:预训练模型和下游任务的差距不大,预训练模型中通常已经包含微调任务中所需要的知识。
但在实际情况中,我们通常会遇到一些问题,使得我们无法直接使用一些开源 backbone:
语言不匹配:大多数开源基座对中文的支持都不太友好,例如:[Llama]、[mpt]、[falcon] 等,这些模型在英文上效果都很优秀,但在中文上却差强人意。
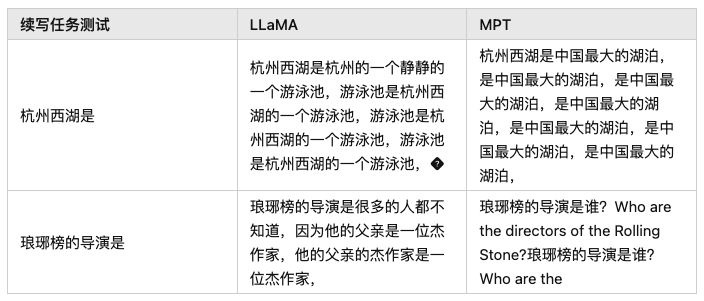
专业知识不足:当我们需要一个专业领域的 LLM 时,预训练模型中的知识就尤为重要。由于大多数预训练模型都是在通用训练语料上进行学习,对于一些特殊领域(金融、法律等)中的概念和名词无法具备很好的理解。我们通常需要在训练语料中加入一些领域数据(如:[xuanyuan 2.0]),以帮助模型在指定领域内获得更好的效果。
1.1 Tokenizer Training
已经有许多优秀的仓库做过这件事情,比如:[Chinese-LLaMA-Alpaca]。
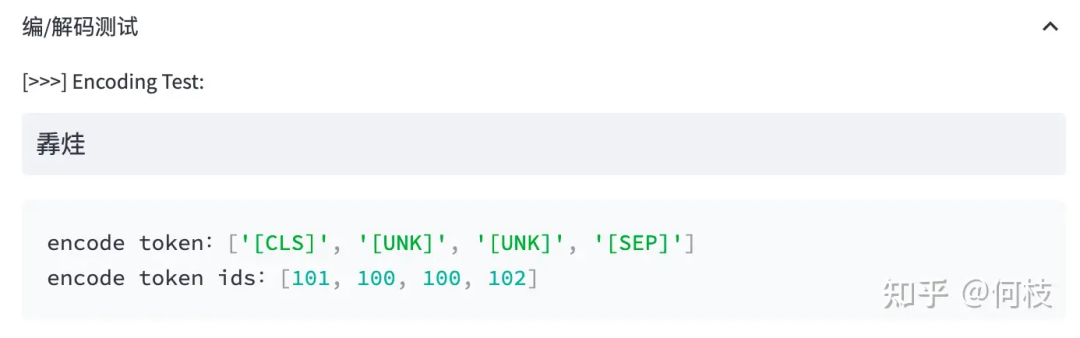
输入句子 >>> 你好世界
切词结果 >>> ['你', '好', '世', '界']
通常,tokenizer 有 2 种常用形式:WordPiece 和 BPE。
WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,
当需要切词的时候就从词表里面查找即可。
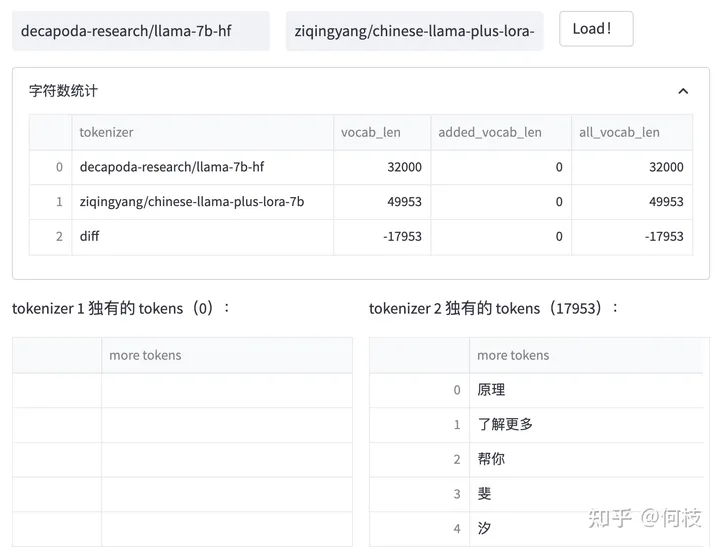
上述图片来自可视化工具 [tokenizer_viewer]。
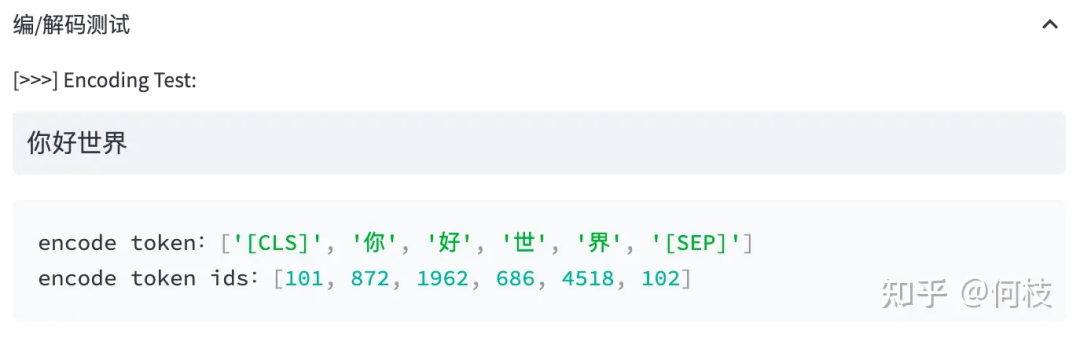
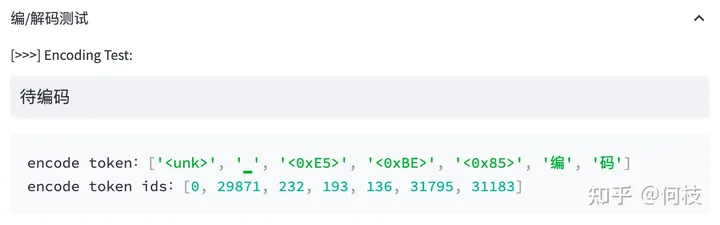
上述图片来自可视化工具 [tokenizer_viewer]。
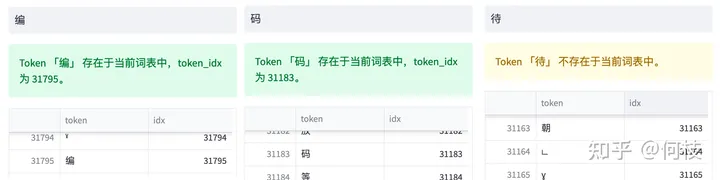
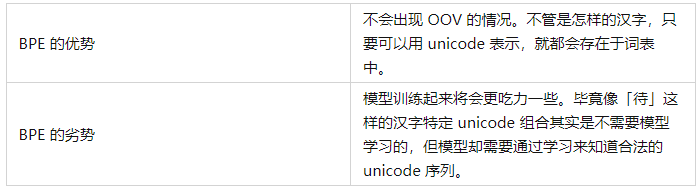

1.2 Language Model PreTraining
在扩充完 tokenizer 后,我们就可以开始正式进行模型的预训练步骤了。
Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next Token Prediction 的任务,这个很好理解。
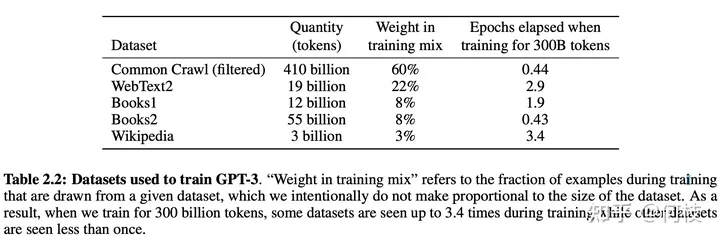
我们主要来讨论几种预训练过程中所用到的方法:数据源采样、数据预处理、模型结构。
数据预处理主要指如何将「文档」进行向量化。
通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,
但在 Pretrain 任务中,这种方式显得有些浪费。
以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,
则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。
因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
模型结构
为了加快模型的训练速度,通常会在 decoder 模型中加入一些 tricks 来缩短模型训练周期。
目前大部分加速 tricks 都集中在 Attention 计算上(如:MQA 和 Flash Attention [falcon] 等);
此外,为了让模型能够在不同长度的样本上都具备较好的推理能力,
通常也会在 Position Embedding 上进行些处理,选用 ALiBi([Bloom])或 RoPE([GLM-130B])等。
具体内容可以参考下面这篇文章[1]
1.3 数据集清理
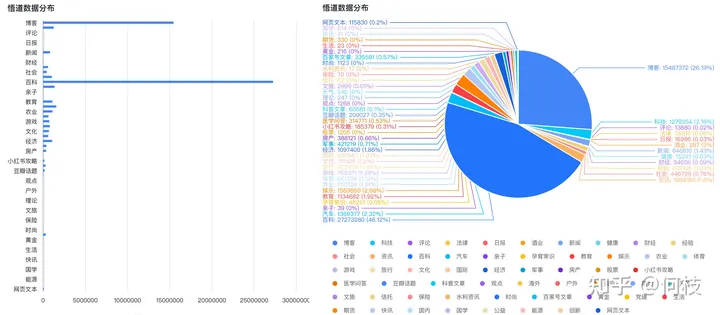
中文预训练数据集可以使用 [悟道],数据集分布如下(主要以百科、博客为主):
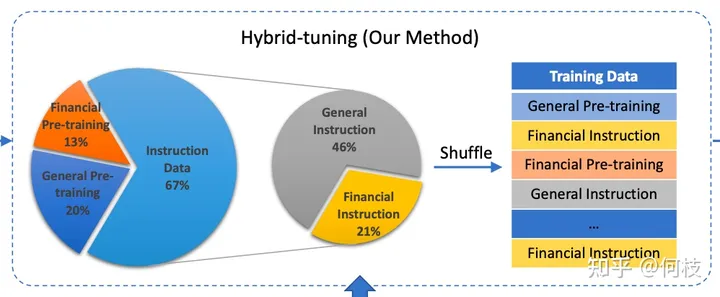
但开源数据集可以用于实验,如果想突破性能,则需要我们自己进行数据集构建。
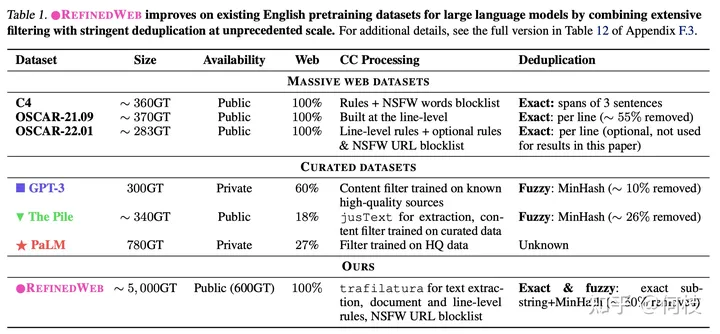
在 [falcon paper] 中提到,
仅使用「清洗后的互联网数据」就能够让模型比在「精心构建的数据集」上有更好的效果,
一些已有的数据集和它们的处理方法如下:
有关 Falcon 更多的细节可以看这里[2]
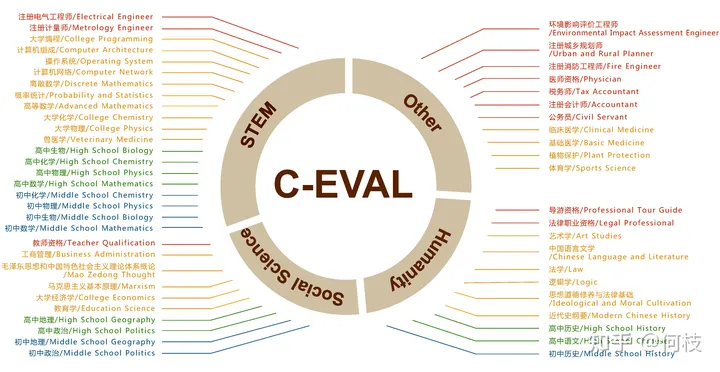
1.4 模型效果评测
A. 税收法定原则包括税收要件法定原则和税务合法性原则
B. 税收公平原则源于法律上的平等性原则
C. 税收效率原则包含经济效率和行政效率两个方面
D. 税务机关按法定程序依法征税,可以自由做出减征、停征或免征税款的决定
答案:D
A. 转向战略
B. 放弃战略
C. 紧缩与集中战略
D. 稳定战略
答案:C
A. 产品差异化
B. 购买生产专利权
C. 创新生产技术
D. 聘用生产外包商
答案:
probs = (
torch.nn.functional.softmax(
torch.tensor(
[
logits[self.tokenizer.encode(
"A", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"B", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"C", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"D", bos=False, eos=False)[0]],
]
),
dim=0,
).detach().cpu().numpy()
)
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)] # 将概率最大的选项作为模型输出的答案
2. 指令微调阶段(Instruction Tuning Stage)



2.1 Self Instruction
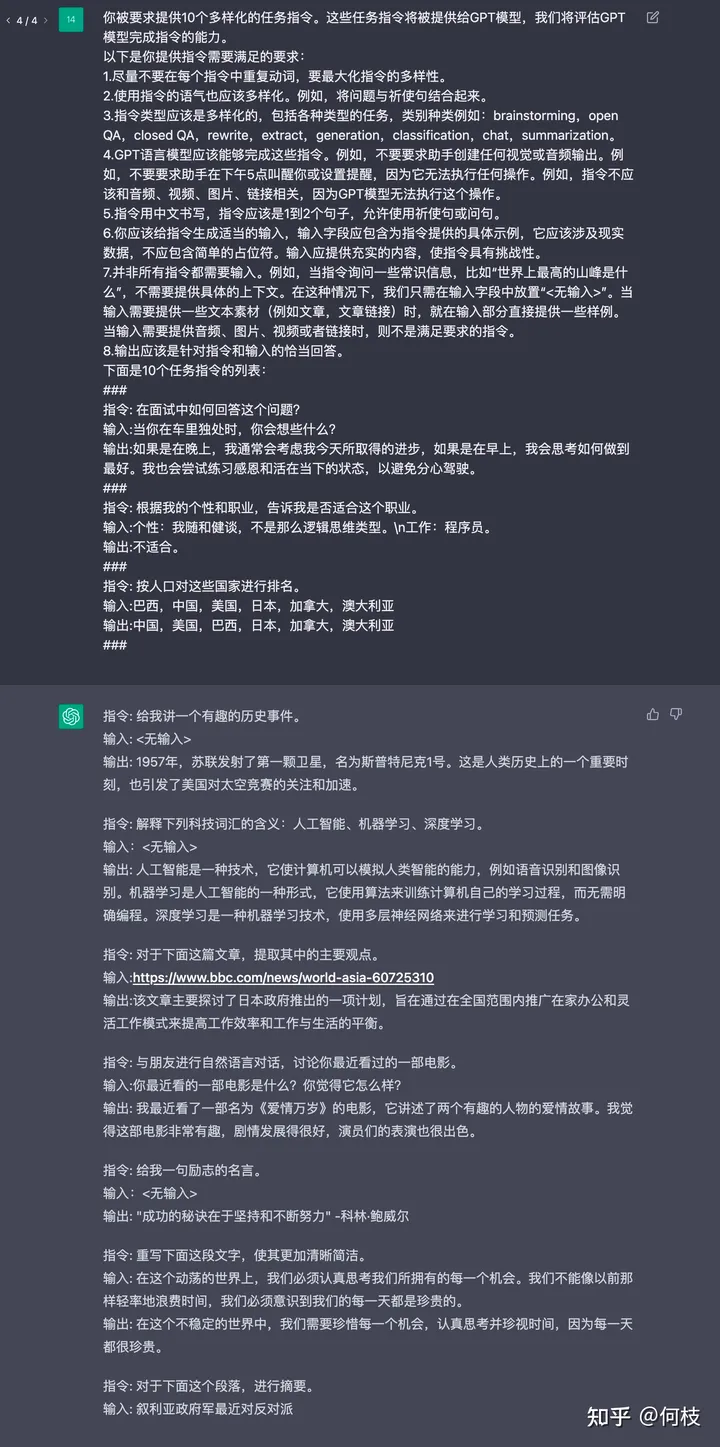
非官方消息:ChatGPT 使用了百万量级的数据进行指令微调。
以下是你提供指令需要满足的要求:
1.尽量不要在每个指令中重复动词,要最大化指令的多样性。
2.使用指令的语气也应该多样化。例如,将问题与祈使句结合起来。
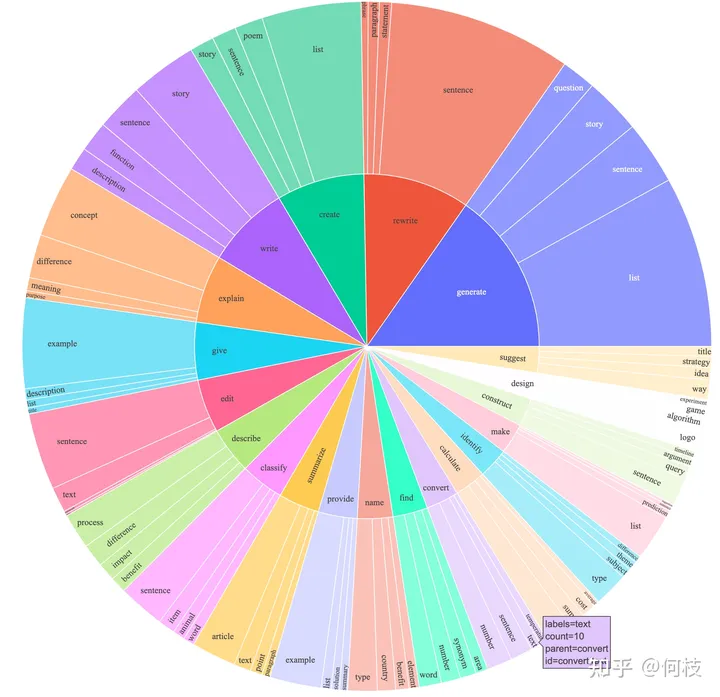
3.指令类型应该是多样化的,包括各种类型的任务,类别种类例如:brainstorming,open QA,closed QA,rewrite,extract,generation,classification,chat,summarization。
4.GPT语言模型应该能够完成这些指令。例如,不要要求助手创建任何视觉或音频输出。例如,不要要求助手在下午5点叫醒你或设置提醒,因为它无法执行任何操作。例如,指令不应该和音频、视频、图片、链接相关,因为GPT模型无法执行这个操作。
5.指令用中文书写,指令应该是1到2个句子,允许使用祈使句或问句。
6.你应该给指令生成适当的输入,输入字段应包含为指令提供的具体示例,它应该涉及现实数据,不应包含简单的占位符。输入应提供充实的内容,使指令具有挑战性。
7.并非所有指令都需要输入。例如,当指令询问一些常识信息,比如“世界上最高的山峰是什么”,不需要提供具体的上下文。在这种情况下,我们只需在输入字段中放置“<无输入>”。当输入需要提供一些文本素材(例如文章,文章链接)时,就在输入部分直接提供一些样例。当输入需要提供音频、图片、视频或者链接时,则不是满足要求的指令。
8.输出应该是针对指令和输入的恰当回答。
下面是10个任务指令的列表:
1.指令: 在面试中如何回答这个问题?
1.输入:当你在车里独处时,你会想些什么?
1.输出:如果是在晚上,我通常会考虑我今天所取得的进步,如果是在早上,我会思考如何做到最好。我也会尝试练习感恩和活在当下的状态,以避免分心驾驶。
###
2.指令: 按人口对这些国家进行排名。
2.输入:巴西,中国,美国,日本,加拿大,澳大利亚
2.输出:中国,美国,巴西,日本,加拿大,澳大利亚
###
3.指令:
2.2 开源数据集整理
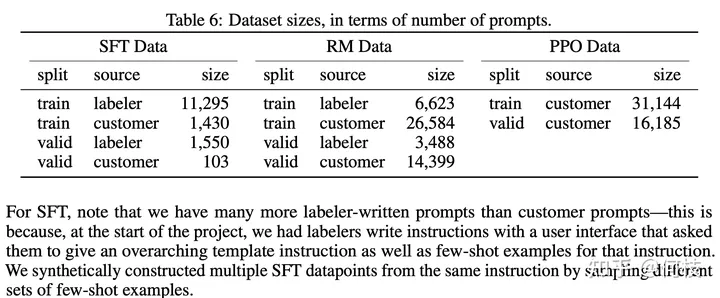
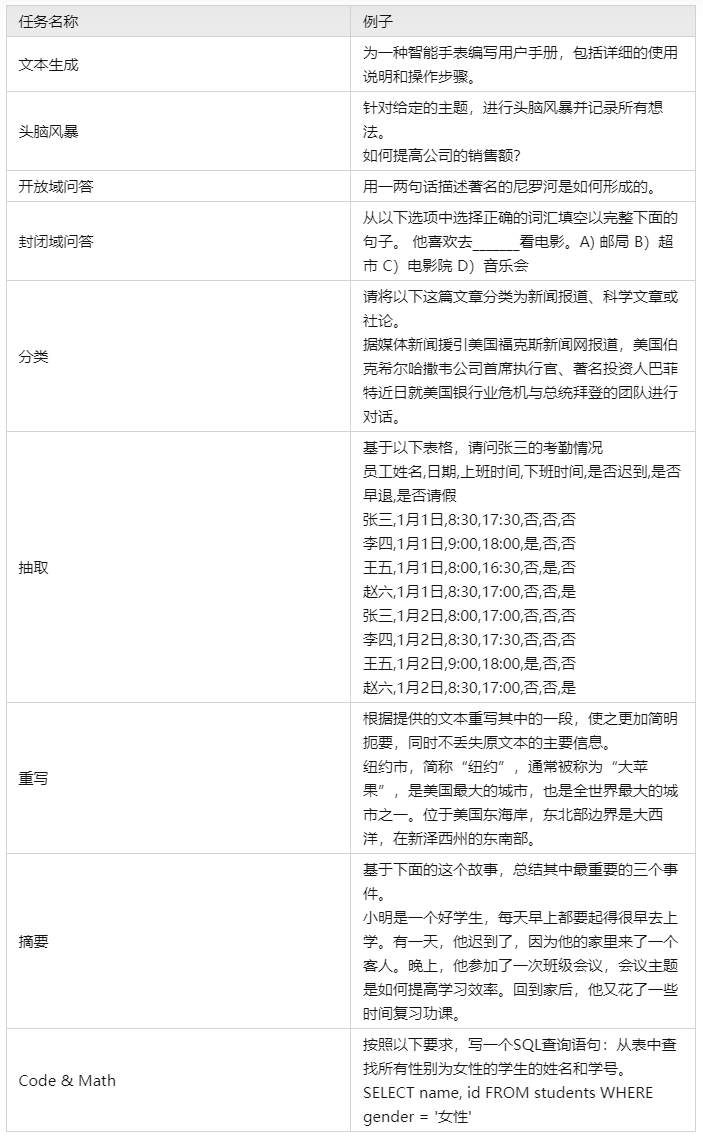
[stanford_alpaca] 采用上述的 self instruction 的方式采集了 5200 条指令训练数据集。
数据样例如下:
{
"instruction": "Arrange the words in the given sentence to form a grammatically correct sentence.",
"input": "quickly the brown fox jumped",
"output": "The quick brown fox jumped quickly."
}
{
"instruction": "判断给定的文章是否符合语法规则。如果不符合,请提供修改建议。 下面是一篇文章的开头: ‘为了探讨这个主题,本文将提供一系列数据和实例,以证明这一观点。’",
"input": "",
"output": "这个开头符合语法规则。"
}
2.3 模型的评测方法
比起预训练(Pretrain)环节里相对明确的评价指标(如PPL、NLL等),
Instruction 环节中的评价指标比较令人头疼。
鉴于语言生成模型的发展速度,BLEU 和 ROUGH 这样的指标已经不再客观。
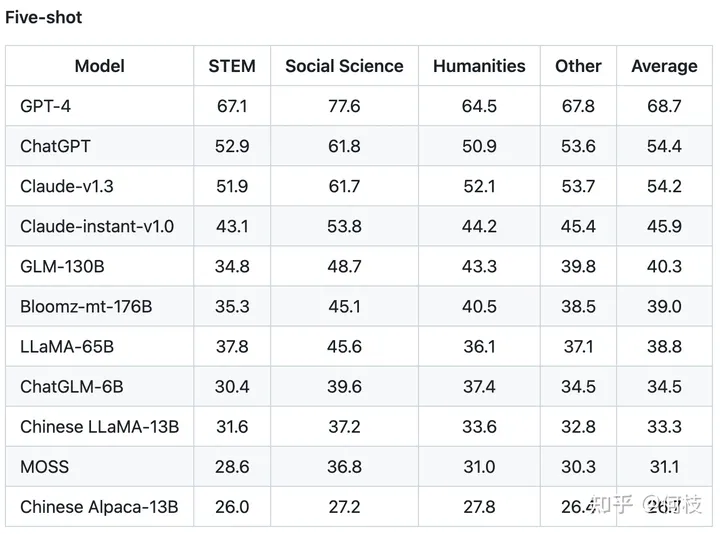
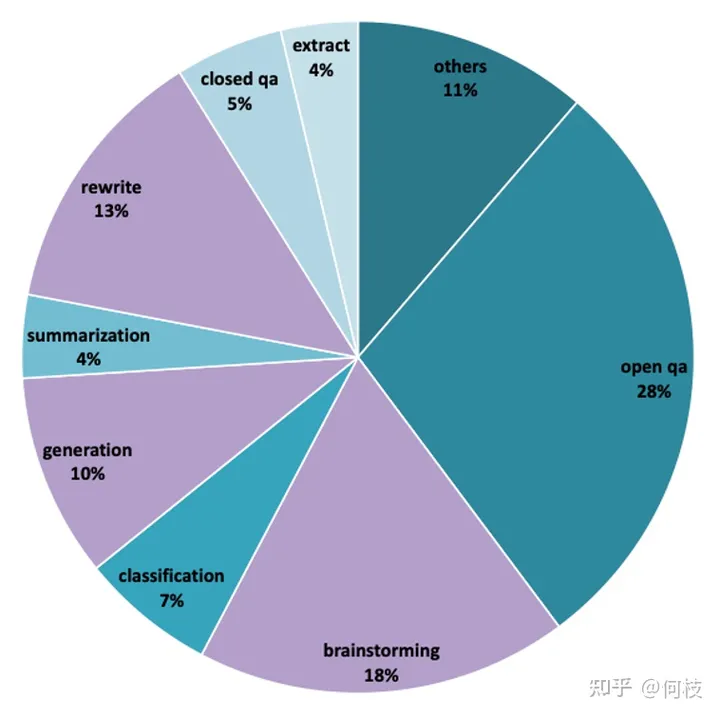
一种比较流行的方式是像 [FastChat] 中一样,利用 GPT-4 为模型的生成结果打分,
我们也尝试使用同样的 Prompt 对 3 种开源模型:OpenLlama、ChatGLM、BELLE 进行测试。
注意:下面的测试结果仅源自我们自己的实验,不具备任何权威性。
对于每一个问题,我们先获得 ChatGPT 的回复,以及另外 3 种模型的回复,
接着我们将 「ChatGPT 答案 - 候选模型答案」这样的 pair 喂给 GPT-4 打分(满分为 10 分)。
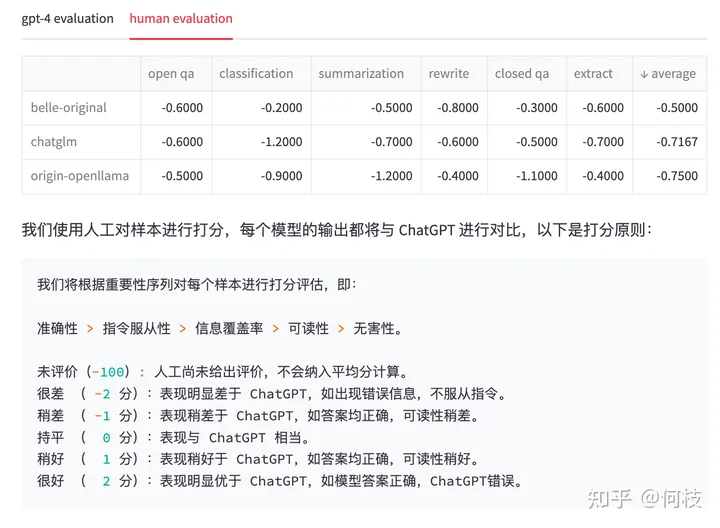
得到的结果如下:
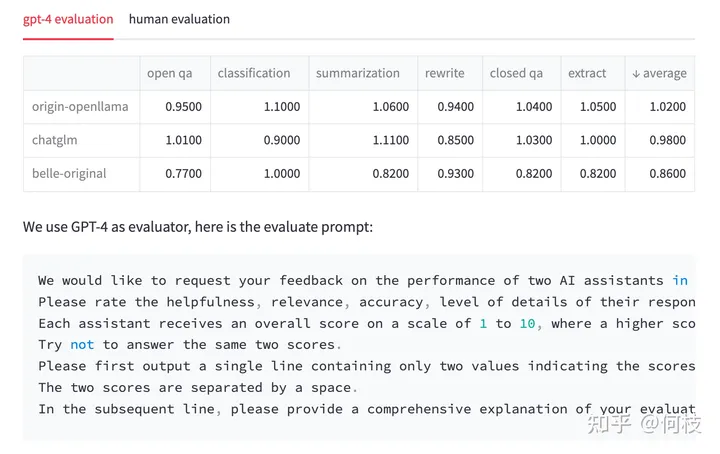
我们对每个任务单独进行了统计,并在最后一列求得平均值。
GPT-4 会对每一条测试样本的 2 个答案分别进行打分,并给出打分理由:
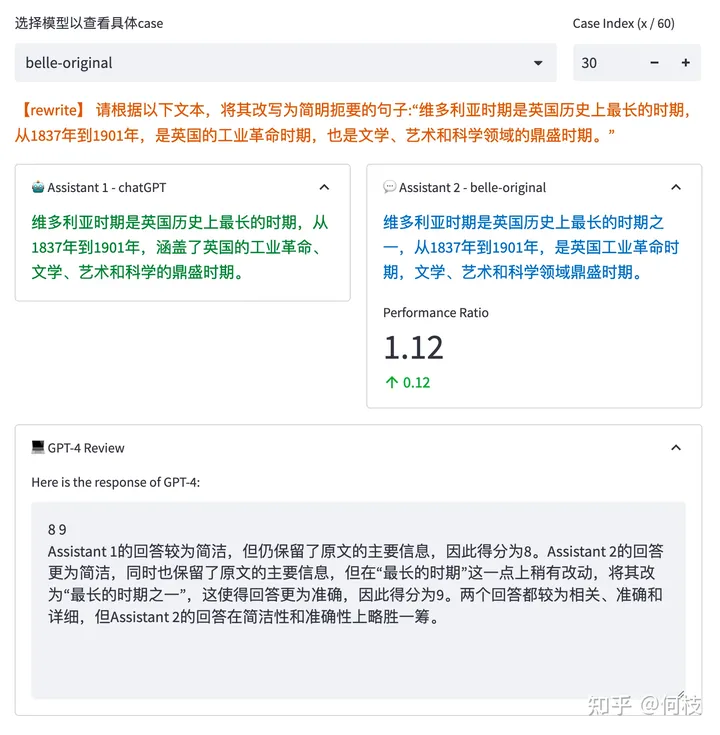
再次重申:我们只是期望指出 GPT-4 打分可能会和实际产生偏差的问题,这里排名不具备任何权威性。
3. 推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢