

《Can LLMs Really Reason and Plan? | blog @ CACM | Communications of the ACM》
原文地址:
https://cacm.acm.org/blogs/blog-cacm/276268-can-llms-really-reason-and-plan/fulltext
相关视频演讲:
https://www.youtube.com/watch?v=BmyB-4S9QuY
相关论文:
https://arxiv.org/abs/2305.15771
https://arxiv.org/abs/2206.10498
https://arxiv.org/abs/2202.02886
作者主页:
https://rakaposhi.eas.asu.edu/
描述了文章中提及的我们自己工作的细节,从以下几方面阐释了LLM模型并不真正具有推理和规划能力:
LLM模型的训练和使用过程中没有任何迹象表明其可以进行原则性的推理,这通常需要计算上十分困难的推断/搜索。一些文章声称LLM有零样本推理能力,但这些结论值得怀疑。
对GPT-3、GPT-3.5和GPT-4在规划任务上的测试表明,尽管性能有所提升,但GPT-4的规划准确率只有30%左右,在其他领域更低们进一步通过打乱动作和对象名称来测试,GPT-4的性能大幅下降,表明其并不能真正进行规划。
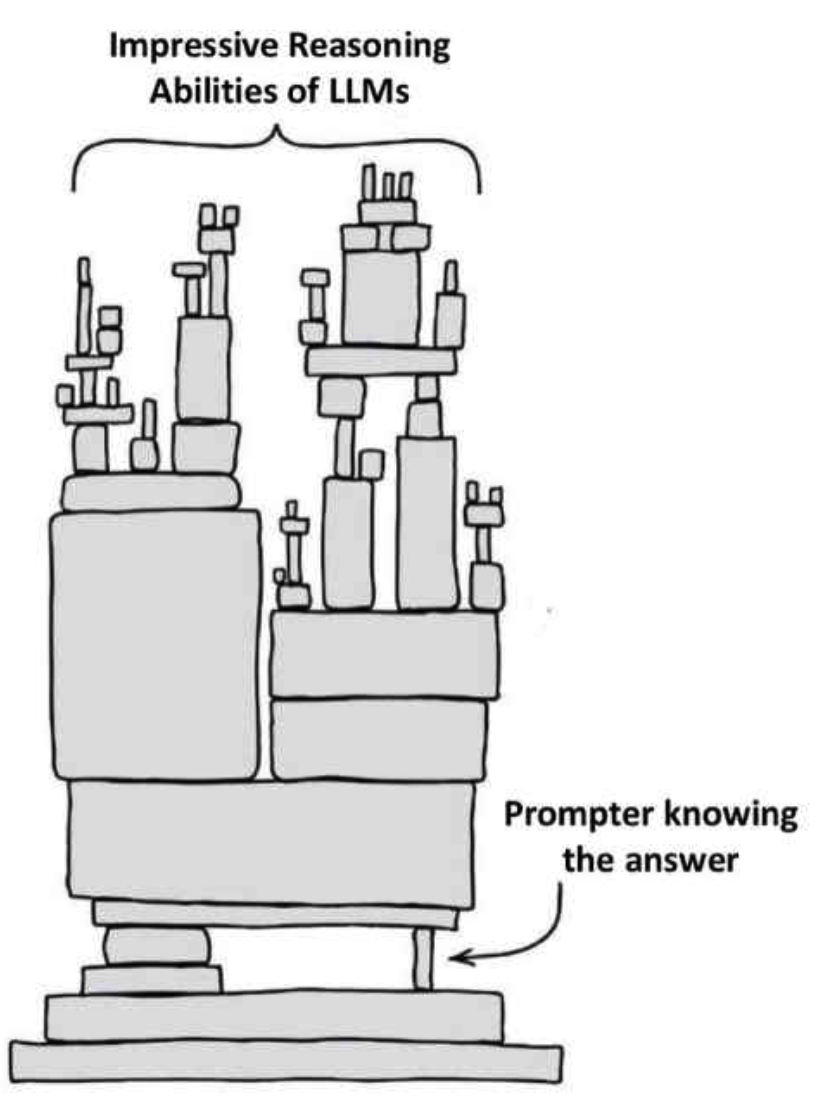
通过巧妙提示或自训练来提升LLM的规划能力的做法也存在问题。人工提示会产生Clever Hans效应,模型自训练也需要假设模型的解验证比解生成更加容易,这些假设都无法证明。
一些文章声称LLM有规划能力,但在仔细检验下,这些所谓的规划往往只是提取了规划知识,而非真正可执行的规划。执行时的子目标交互往往被忽略或者转由人工完成。
LLM的价值在于可以提取规划知识,生成规划思路,但需要人工或专门的程序来验证和完善这些知识和思路,最后交给基于模型的规划器来保证正确性。这与过去的知识工程方法有相似之处。
总之,没有任何证据表明LLM真正具备推理和规划能力。它们通过大规模训练进行的是一种普适的近似检索,有时会被误认为是推理能力。不应当过于夸大LLM的能力,但可以充分利用其生成思路的优势来辅助推理和规划。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢