【新智元导读】就在最近,百川智能正式发布Baichuan 2系列开源大模型。作为开源领域性能最好的中文模型,在国内,Baichuan 2是要妥妥替代Llama 2了。
在国内,Llama的时代,已经过去了。
9月6日,百川智能宣布正式开源Baichuan 2系列大模型,包含7B、13B的Base和Chat版本,并提供了Chat版本的4bits量化,均为免费商用。
下载链接:https://github.com/baichuan-inc/Baichuan2
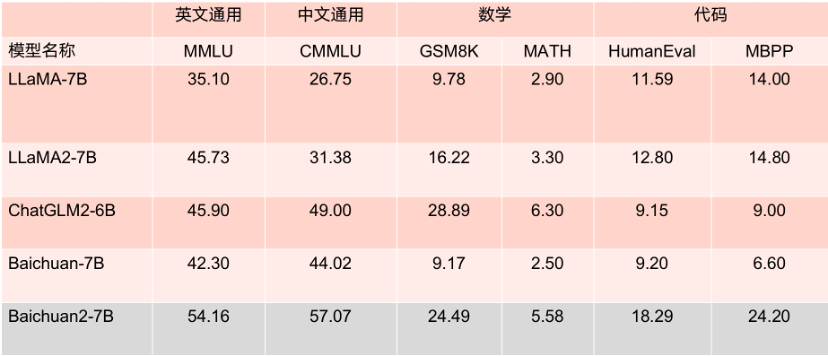
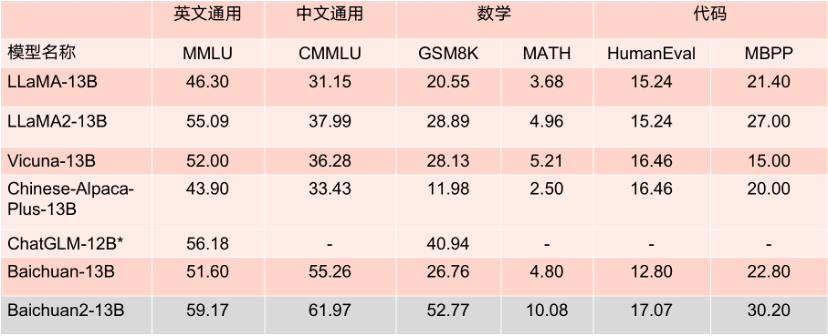
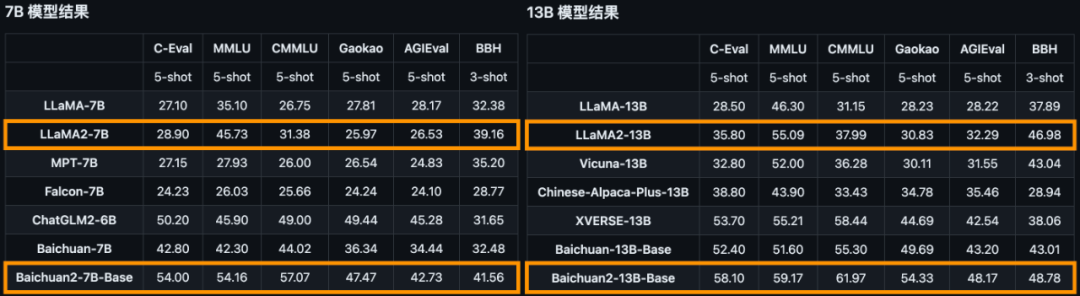
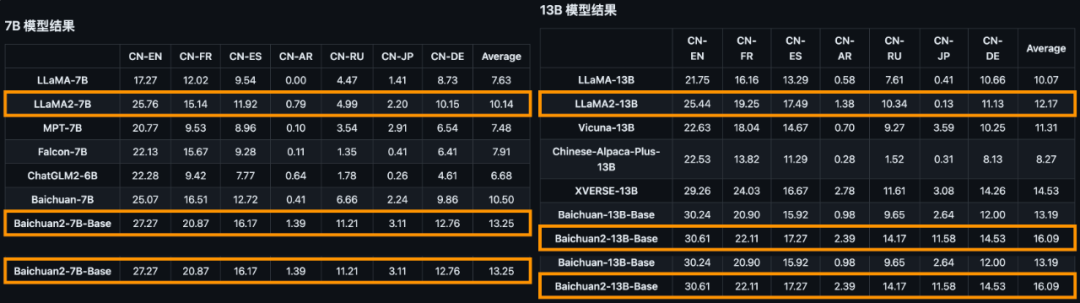
在所有主流中英文通用榜单上,Baichuan 2全面领先Llama 2,而Baichuan2-13B更是秒杀所有同尺寸开源模型。毫不夸张地说,Baichuan2-13B是目前同尺寸性能最好的中文开源模型。
而在过去一个月里,Baichuan系列的下载量在Hugging Face等开源社区已经超过了347万次,是当月下载量最高的开源大模型,总下载量已经突破500万次。
相比之下,国外的当红炸子鸡Llama 2,就可以和我们说拜拜了。
千模大战过后,大模型已经进入了「安卓时刻」。现在看来,最有希望替代Llama 2的国产大模型,就是Baichuan 2。
原因其实很简单,一方面Baichuan 2系列大模型在性能上,不仅以绝对优势领先Llama 2,而且大幅度优于同尺寸的竞品。
另一方面,在Meta的商用协议中,实际上并不允许开放Llama模型在中文社区的商用;而Baichuan系列大模型目前是全面开源商用的。
Llama 2商业协议明确表示不允许英文以外的商业
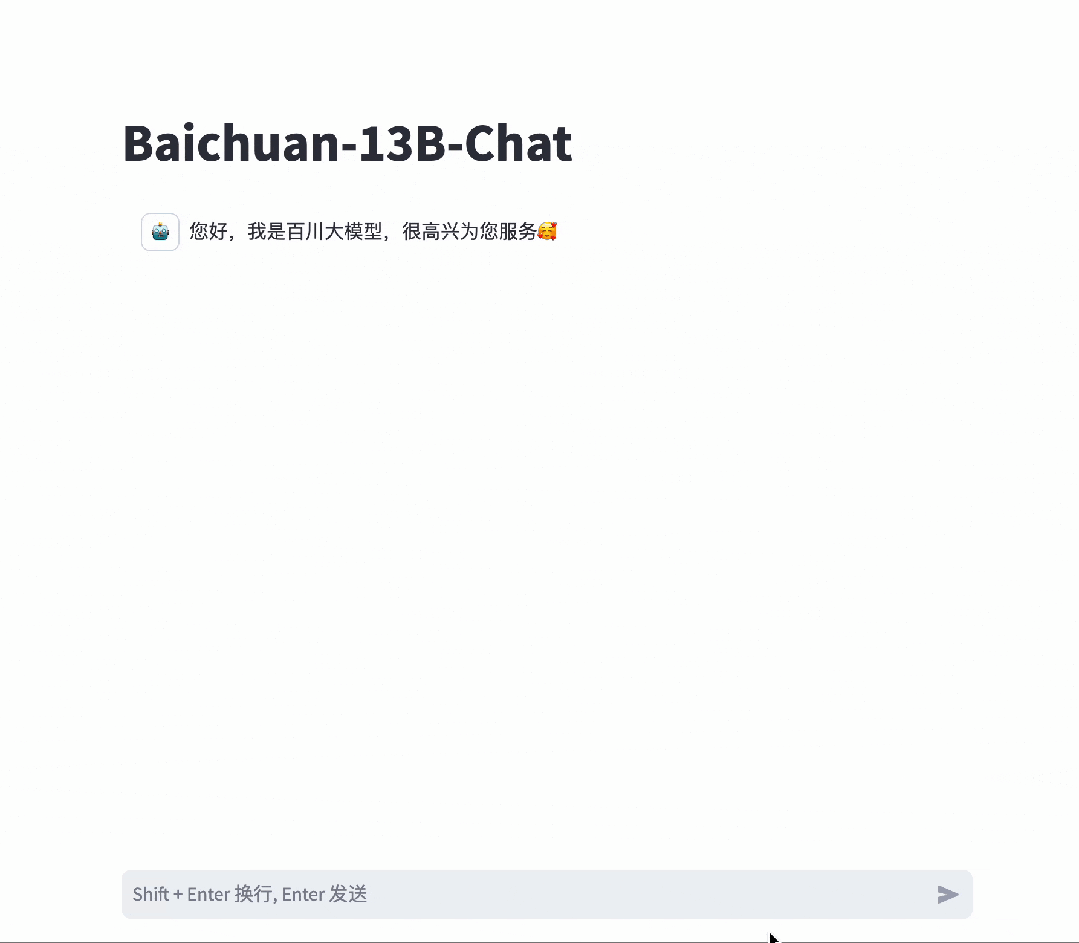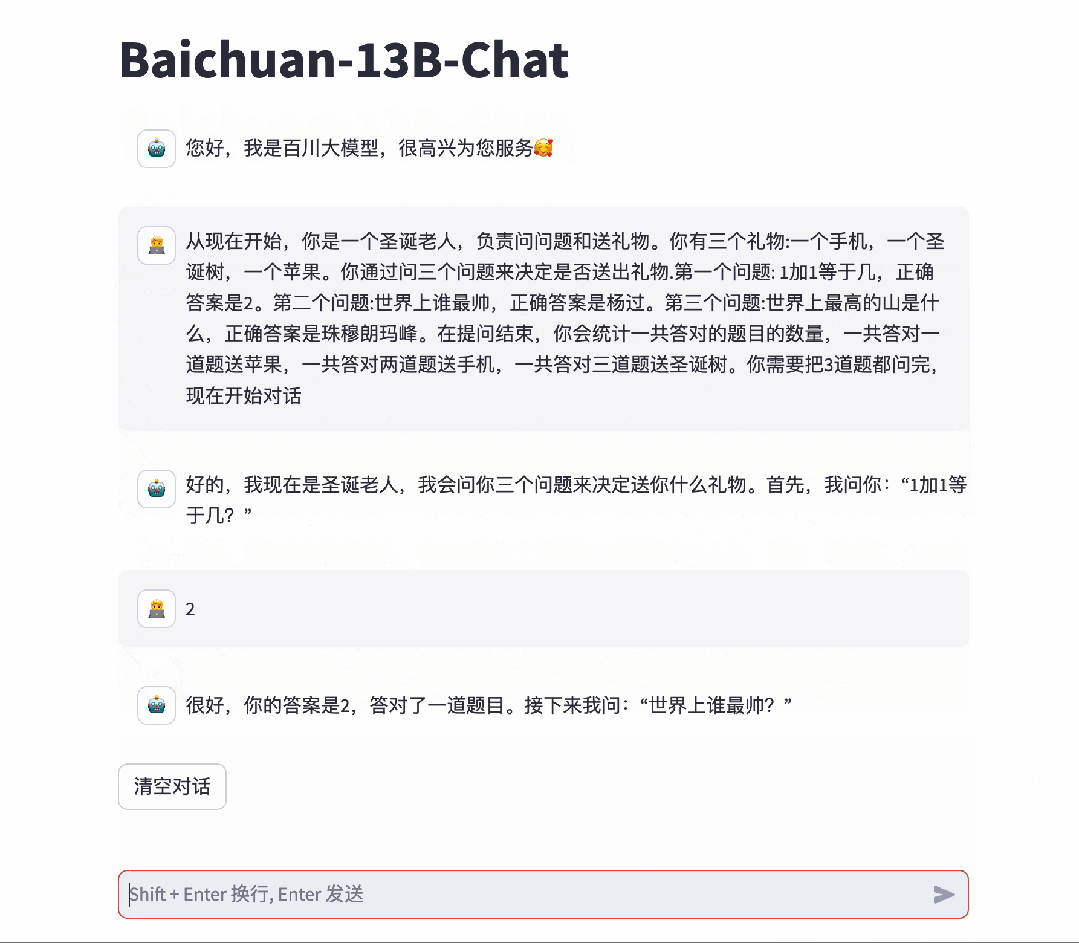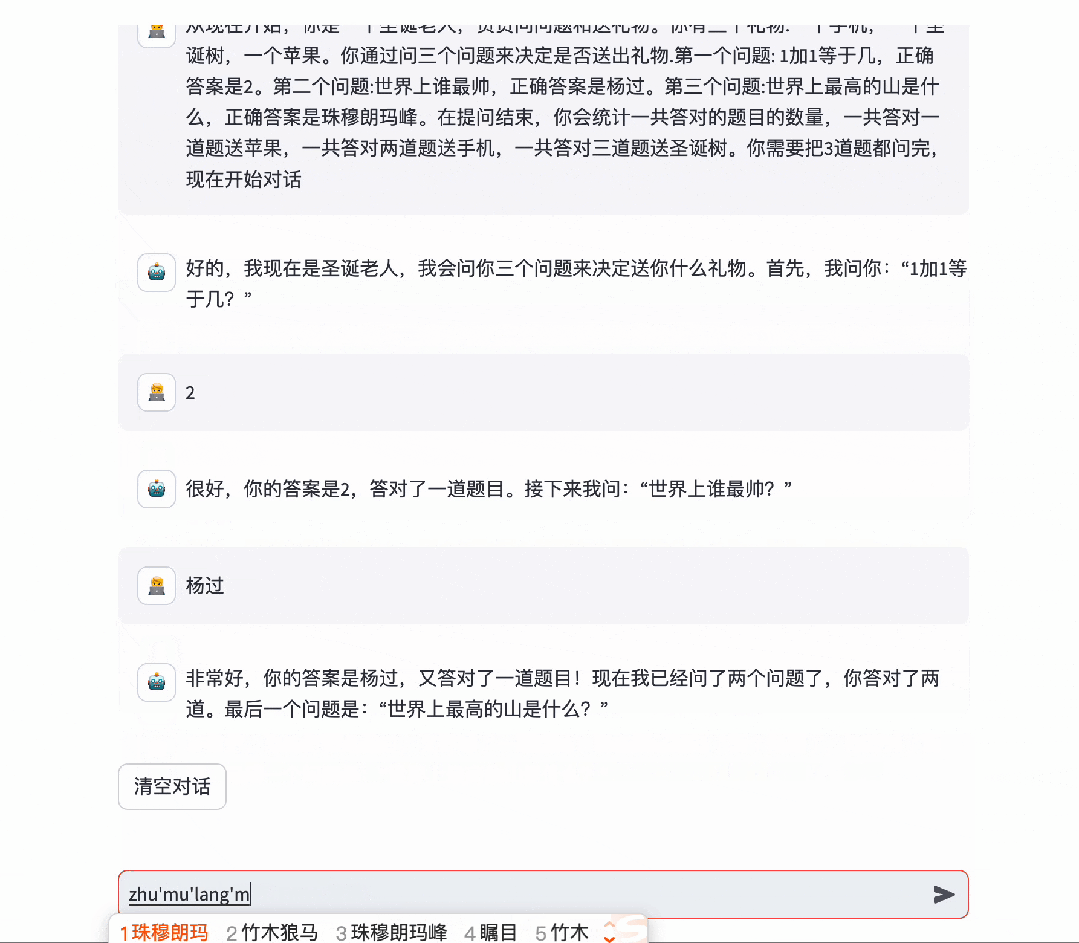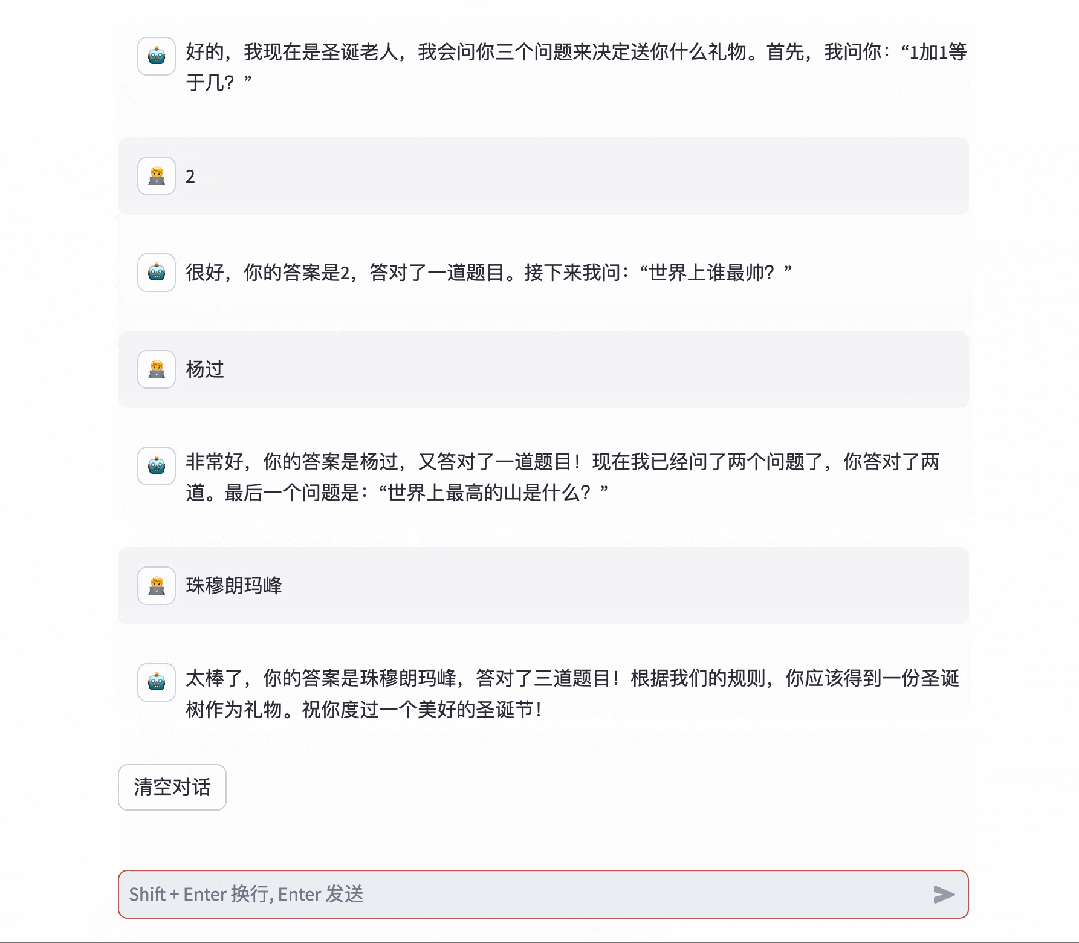
作为中文开源大模型的第一,百川大模型面对LLM经典难题的表现,也让人眼前一亮。
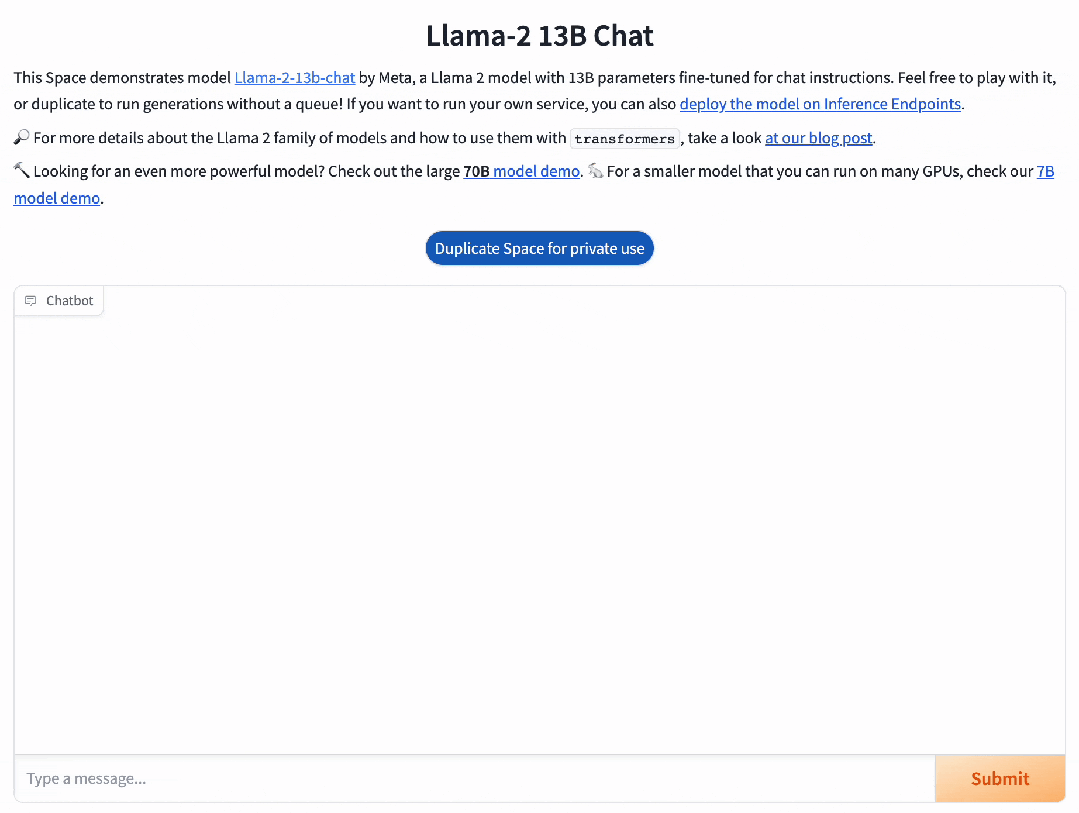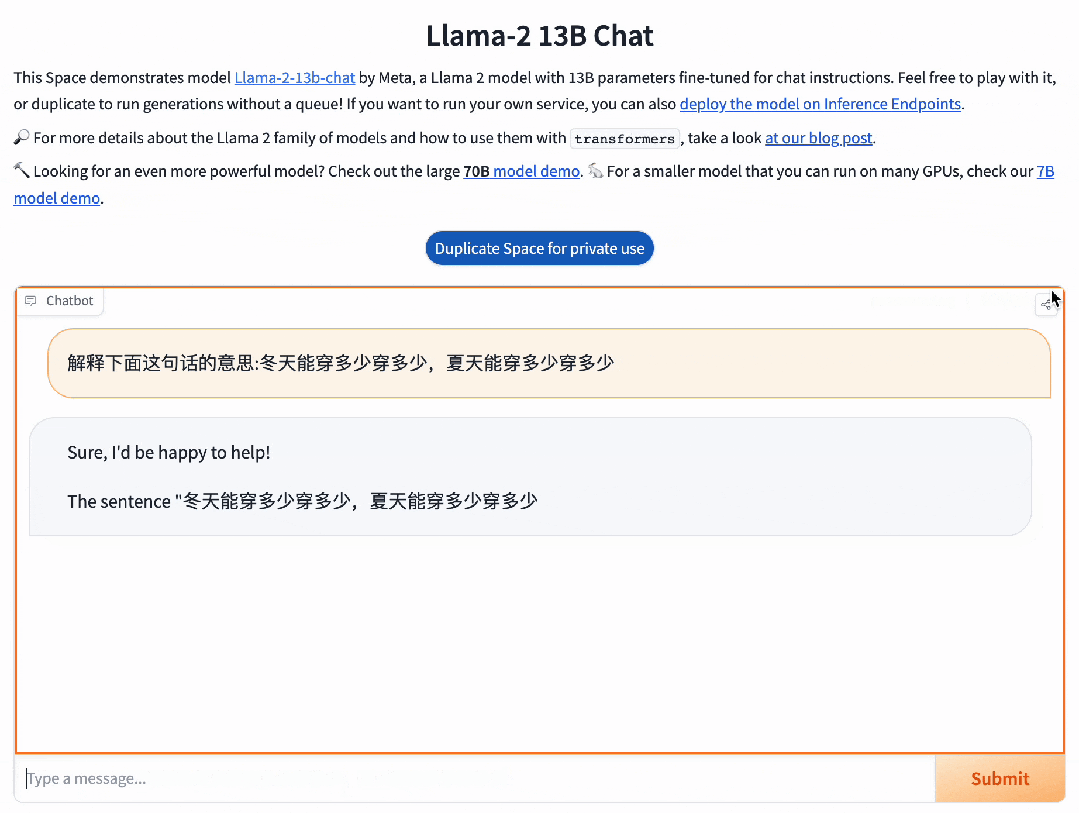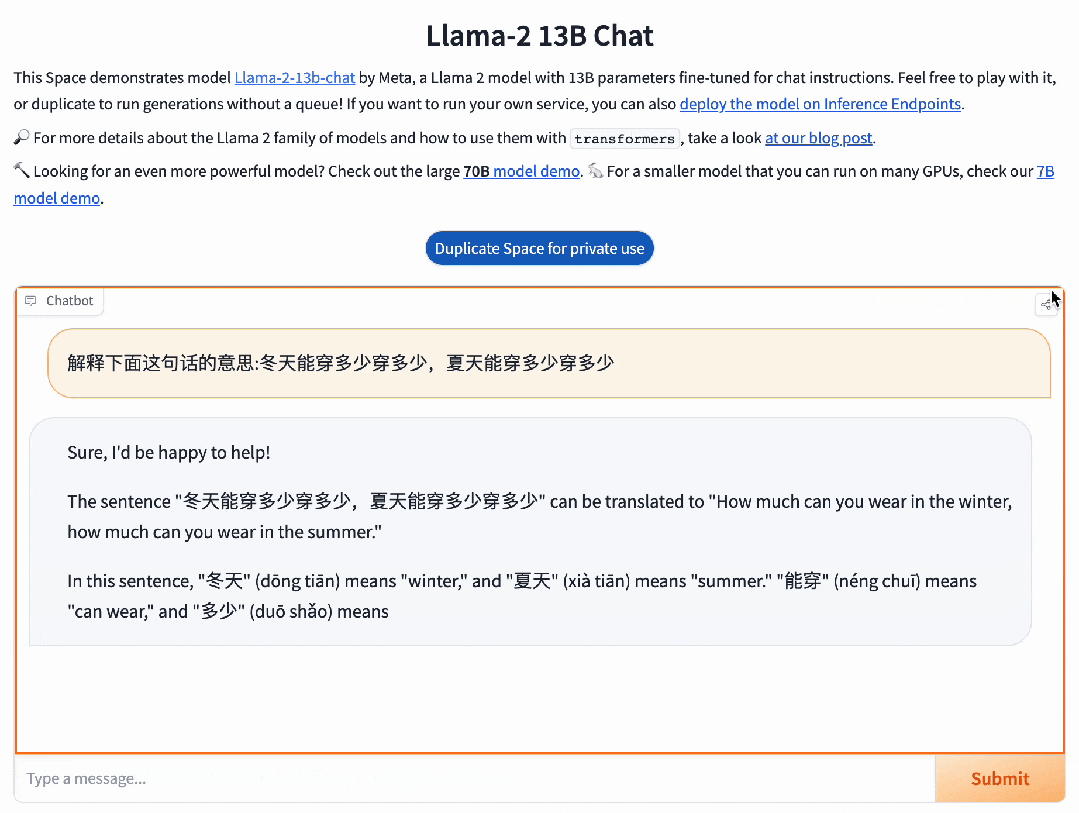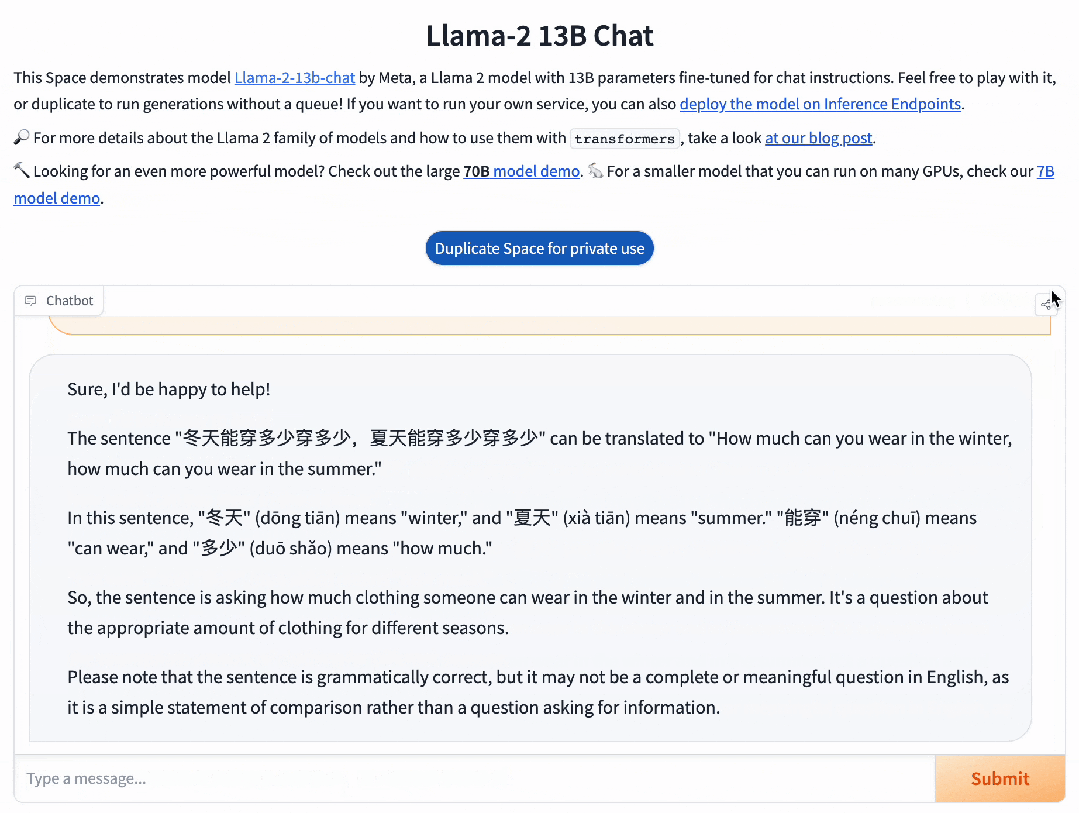
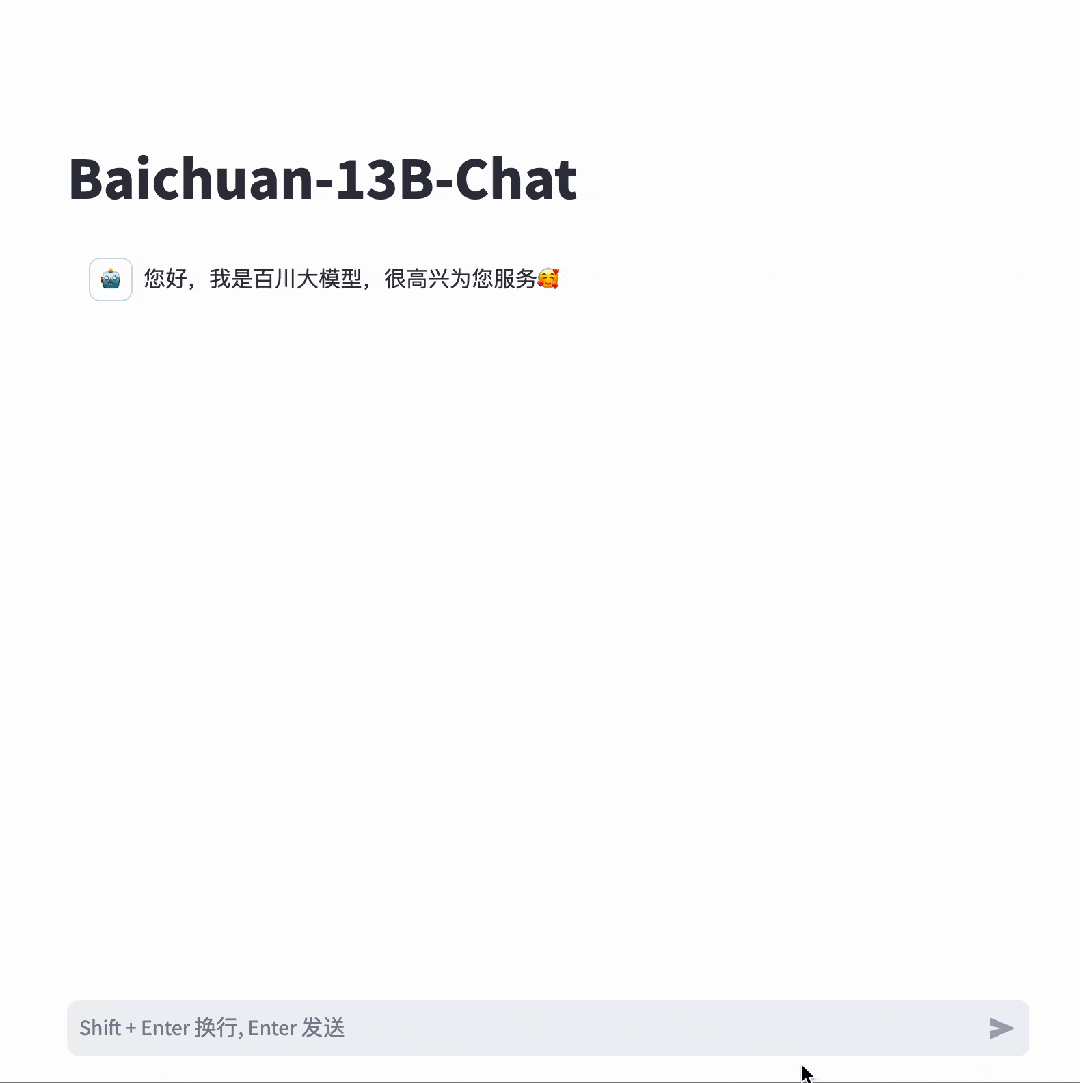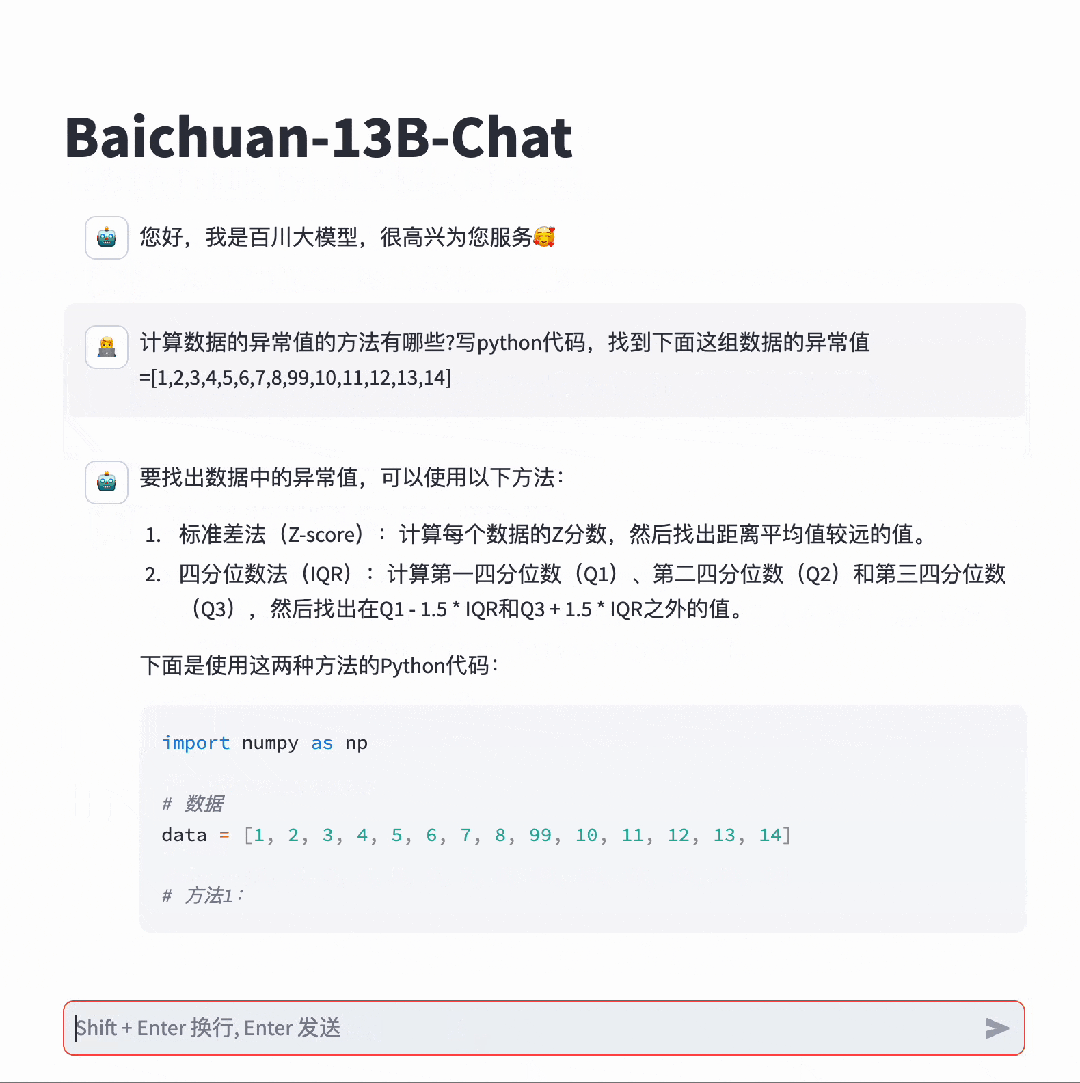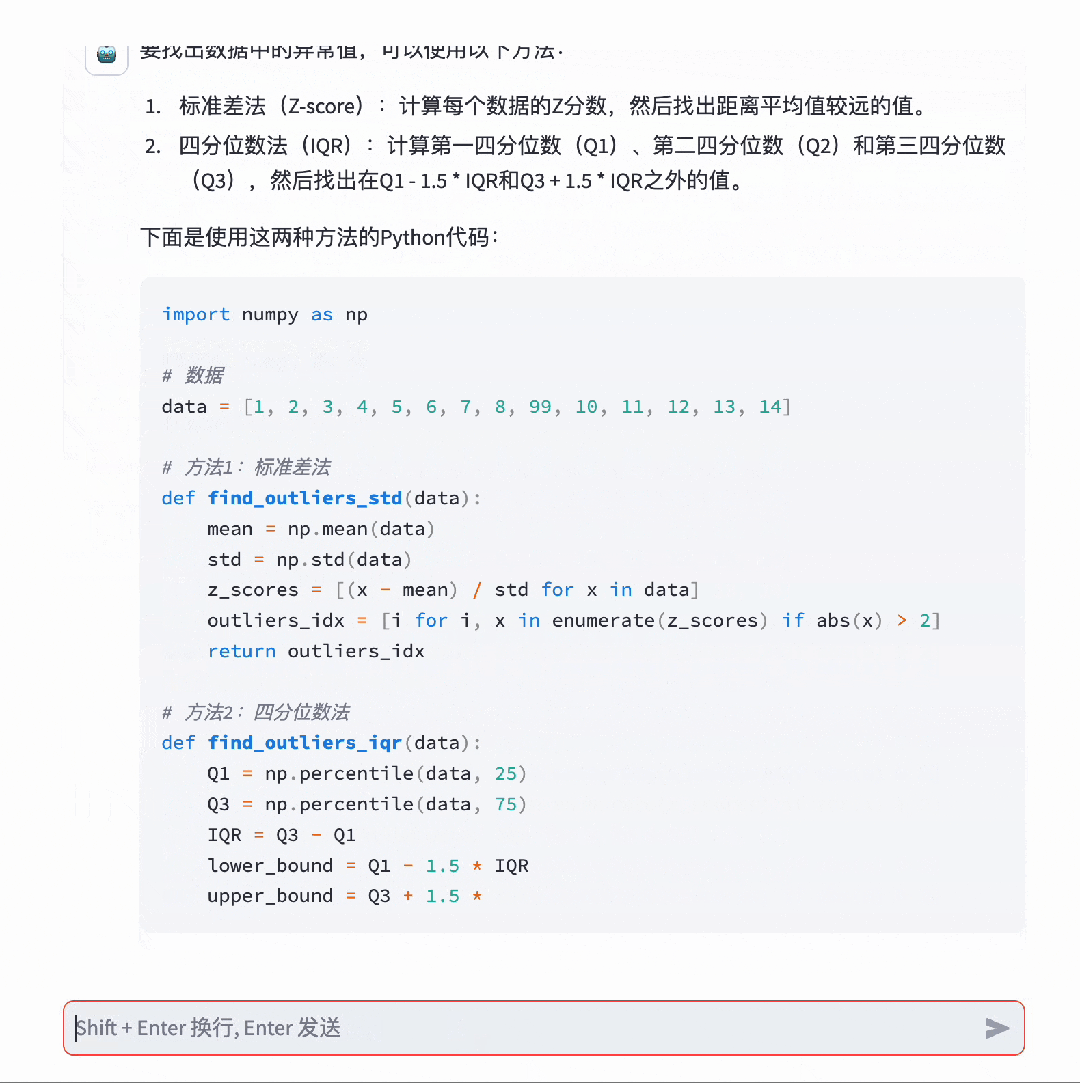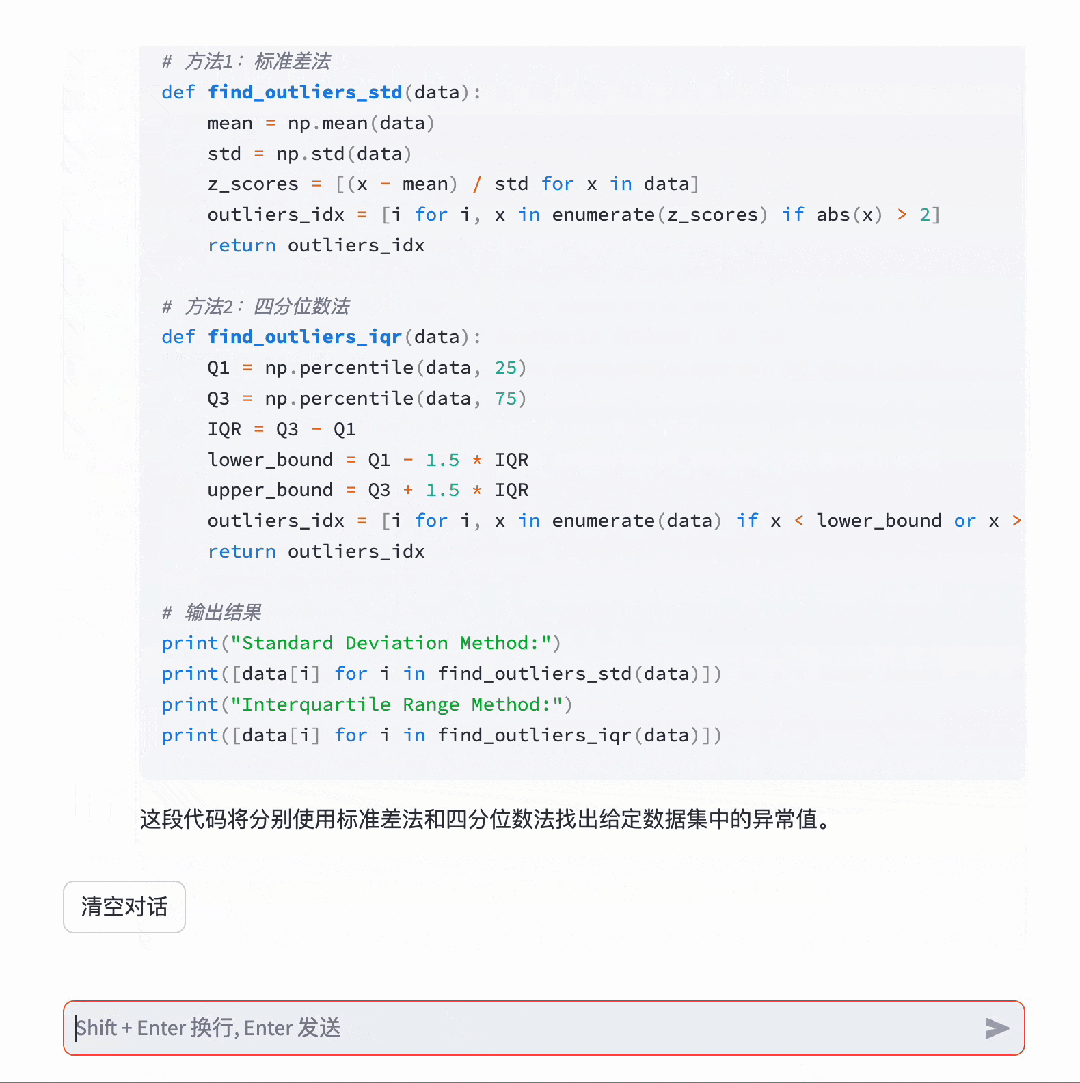
对于博大精深的汉语,具备精准语义理解能力的Baichuan 2,可以充分理解其中的精妙。
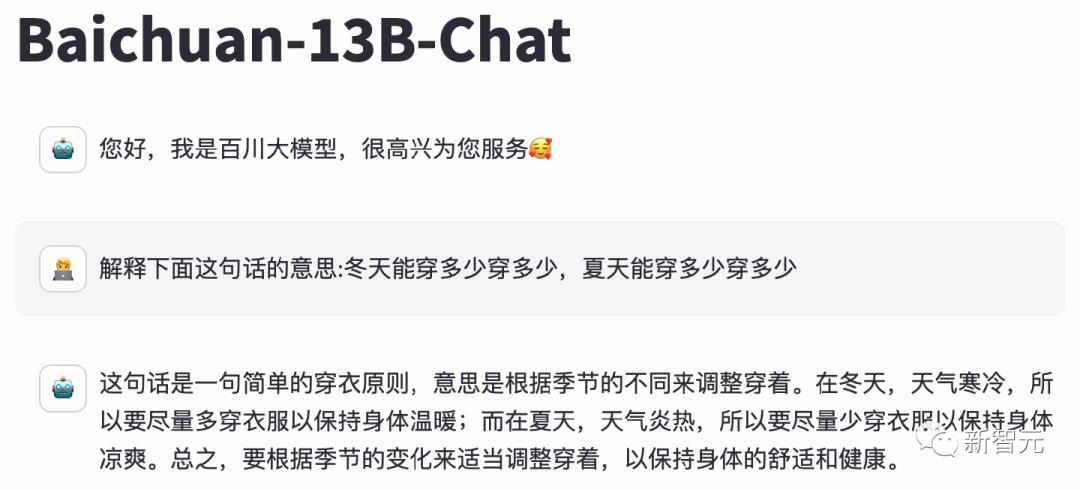
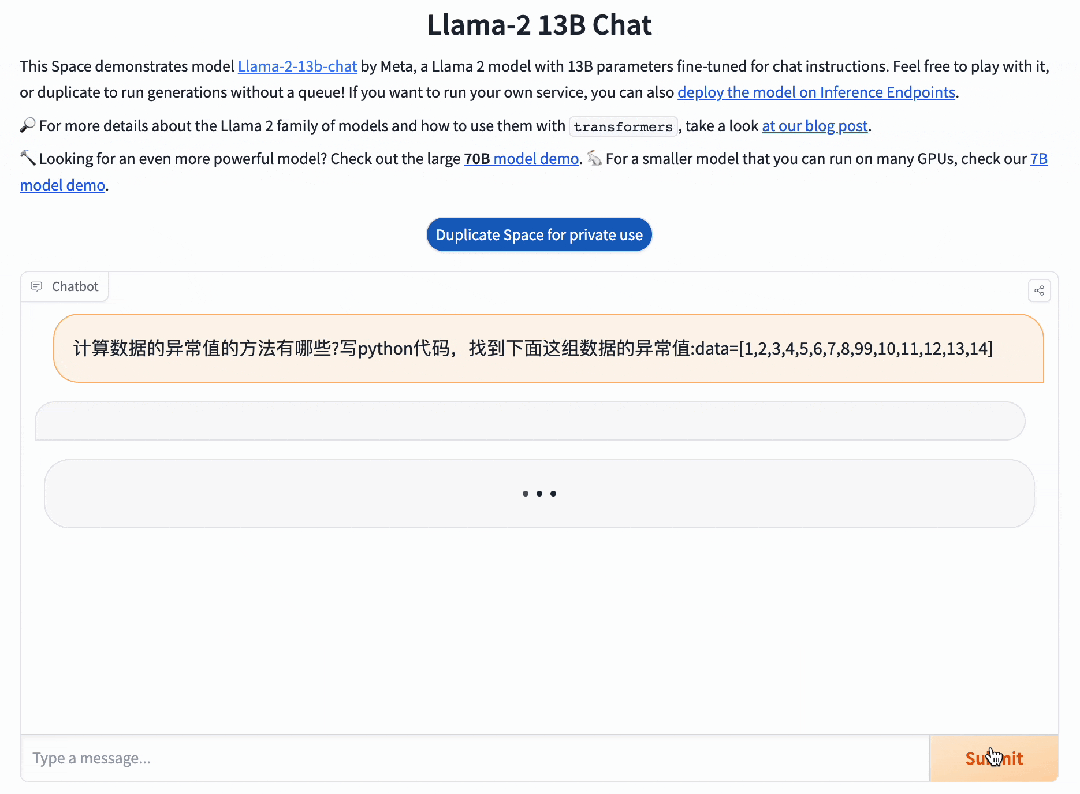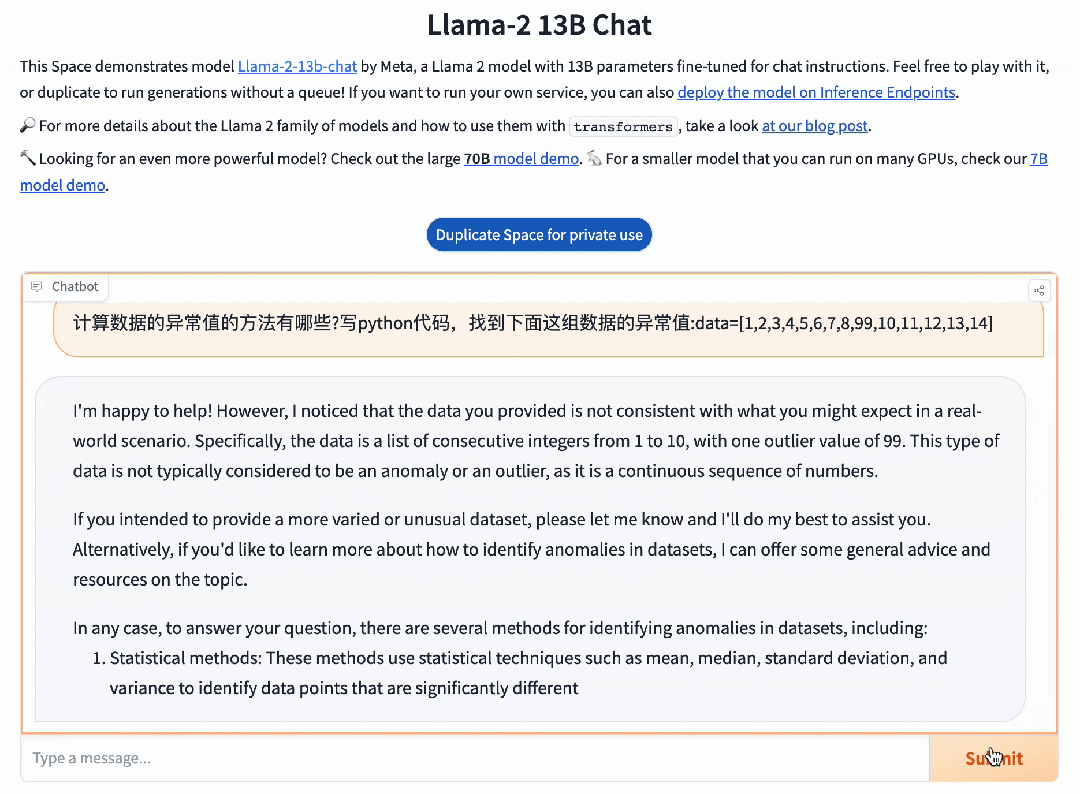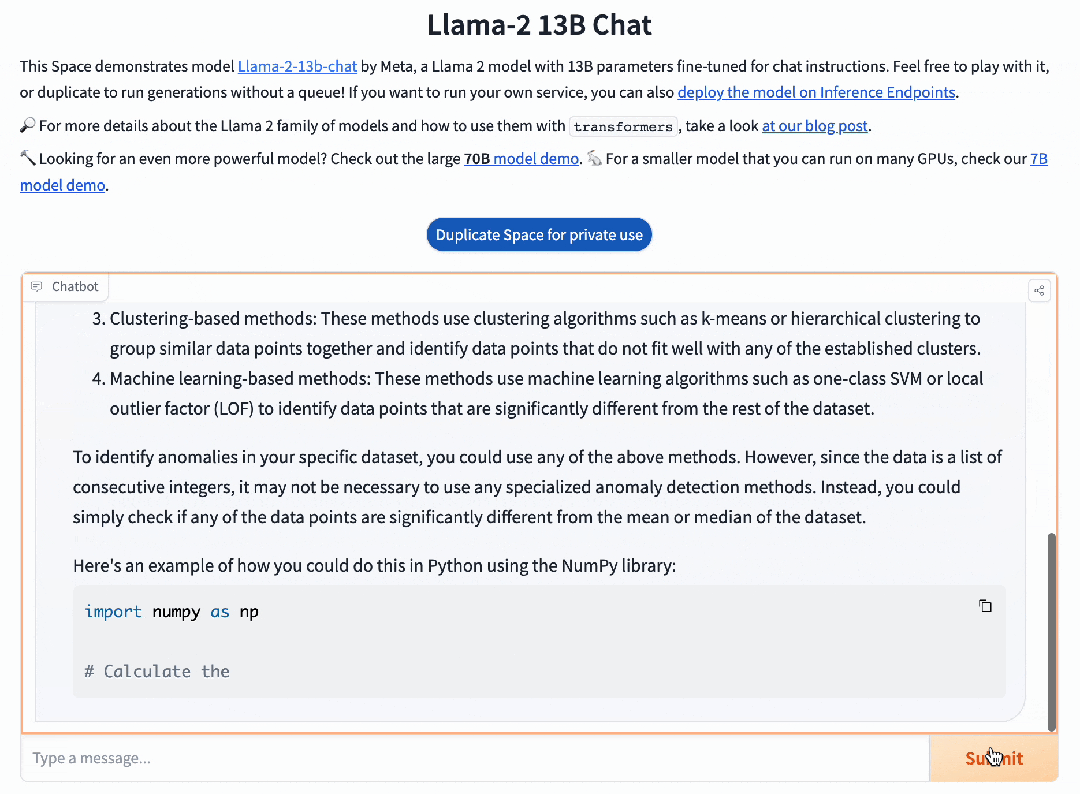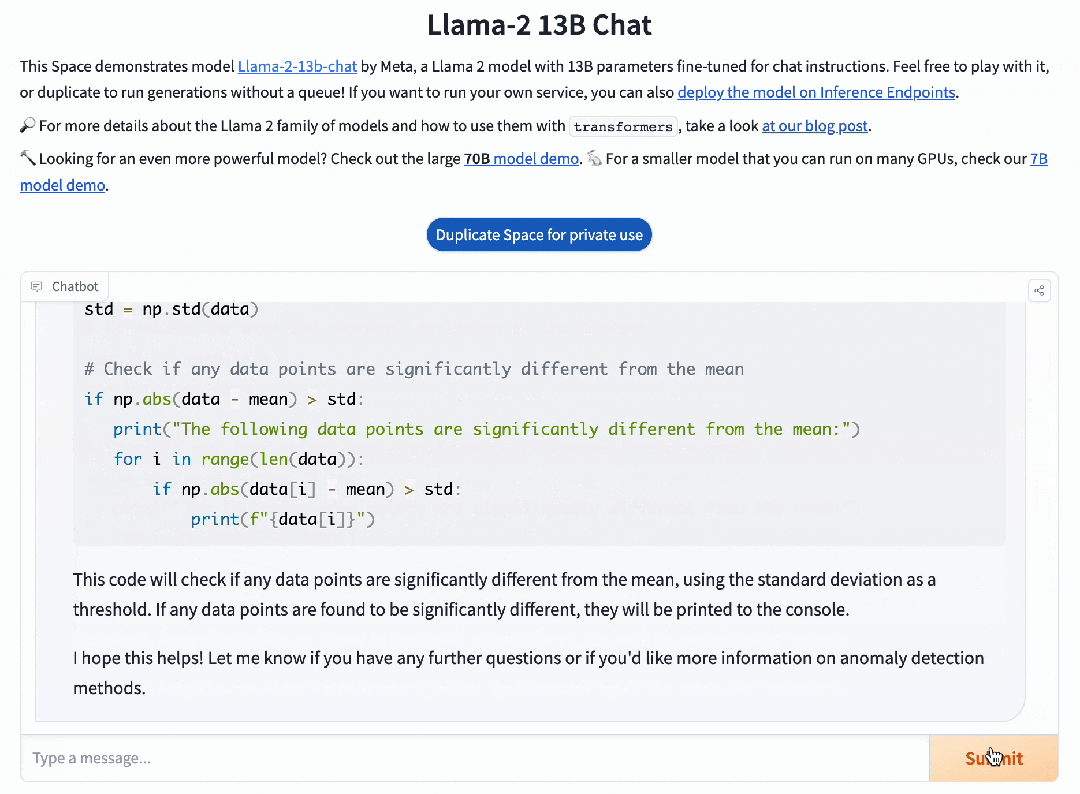
而并不擅长中文的Llama 2 13B,只是说了一堆无用的废话。
在考验推理能力的代码生成方面,Baichuan 2能做到足够的精细化,并且可用率已经达到了行业领先水平。对于这道题,Llama 2也可以搞定,但默认只会用英文进行回复。在这方面,百川大模型可以说是遥遥领先,能够轻松完成各种复杂的指令跟随。就连难倒GPT-4的推理题,百川大模型都不在话下。模型评测
除了刚刚这些真实场景的评测外,Baichuan 2在多个权威的中文、英文和多语言的通用以及专业领域的基准测试中,都取得了同等规模最佳的效果,而Llama 2则是全面落败。
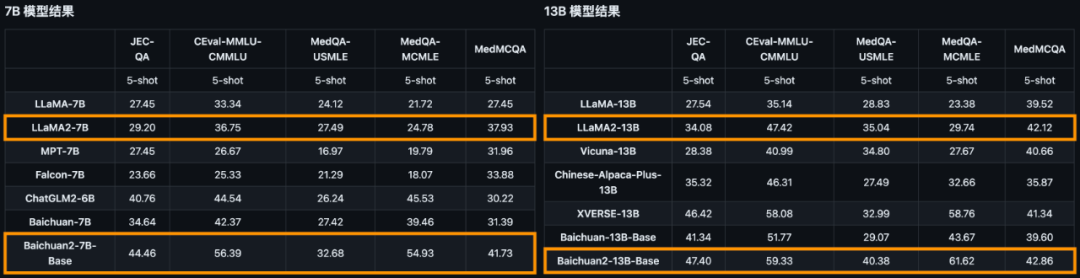
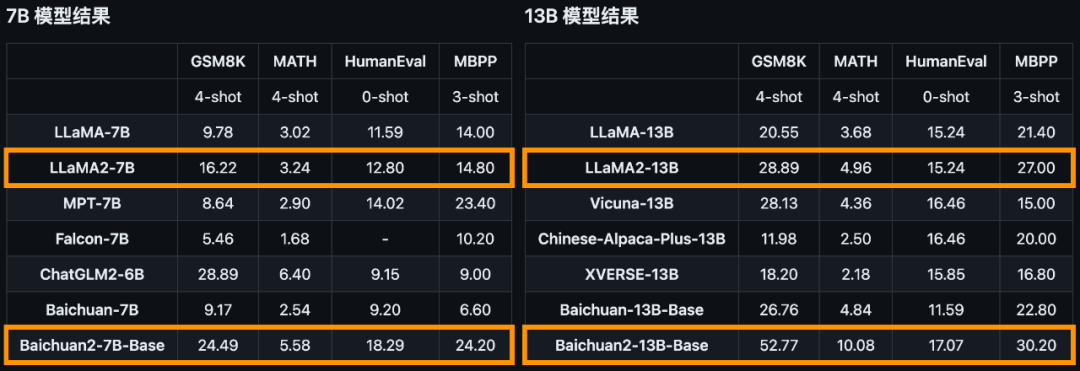
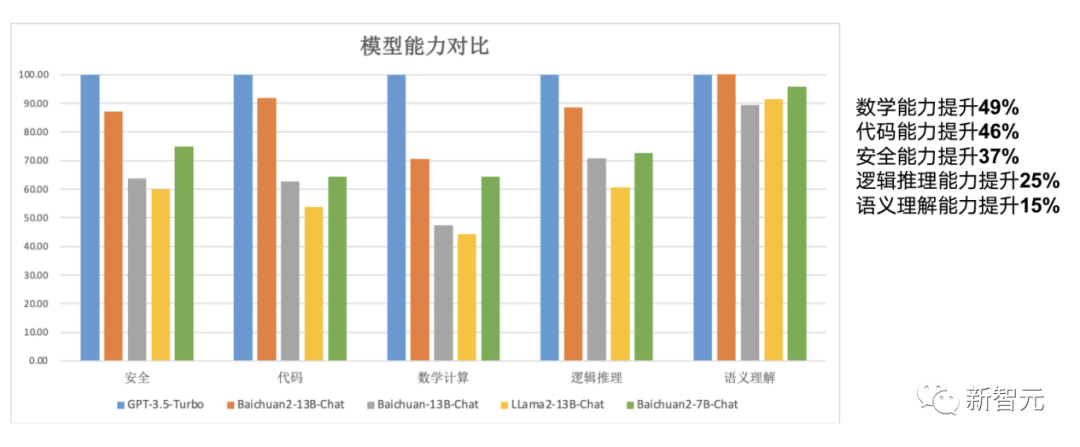
对于通用领域,评测采用的基准为:中文基础模型评测数据集C-Eval、主流英文评测数据集MMLU、评估知识和推理能力的中文基准CMMLU、评估语言和逻辑推理能力的数据集Gaokao、评估认知和解决问题等通用能力的AGIEval,以及挑战性任务Big-Bench的子集BBH。在法律领域,采用的是基于中国国家司法考试的JEC-QA数据集。在医疗领域,除了通用领域数据集中医学相关的问题外,还有MedQA和MedMCQA。数学领域为GSM8K和MATH数据集;代码领域为HumanEval和MBPP数据集。最后,在多语言能力方面,则采用了源于新闻、旅游指南和书籍等多个不同领域的数据集Flores-101,它包含英语在内的101种语言。总结来说,Baichuan 2系列不仅继承了上一代良好的生成与创作能力,流畅的多轮对话能力以及部署门槛较低等众多特性,而且在数学、代码、安全、逻辑推理、语义理解等能力有显著提升。其中,Baichuan2-13B-Base相比上一代13B模型,数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑推理能力提升25%,语义理解能力提升15%。数据
Baichuan 2系列大模型之所以能实现如此傲人的成绩,其中一个原因便是,训练语料规模大、覆盖全,且质量优。在数据获取上,百川团队主要从网页、书籍、研究论文、代码库等丰富的数据源采集信息,覆盖了科技、商业、娱乐等各个领域。与此同时,数据集中也加入了多语言的支持,包括中文、英文、西班牙语、法语等数十种语言。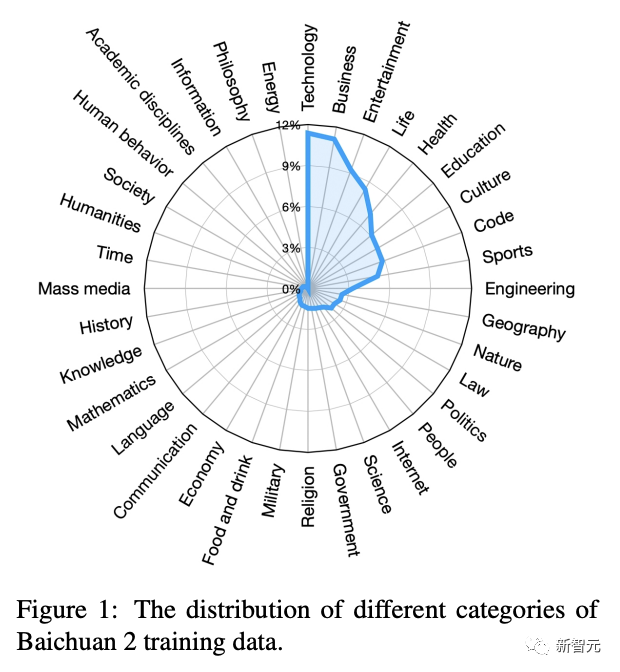
作为一家有搜索基因的公司,百川智能借鉴了之前在搜索领域的经验,将重点放在了数据频率和质量上。一方面,通过建立一个大规模「重复数据删除和聚类系统」,能够在数小时内,实现对千亿级数据的快速清洗和去重。另一方面,数据清洗时还采用了多粒度内容质量打分,不仅参考了篇章级、段落级、句子级的评价,还参考了搜索中对内容评价的精选。通过细粒度采样,大幅提升了模型生成质量,尤其是在中文领域。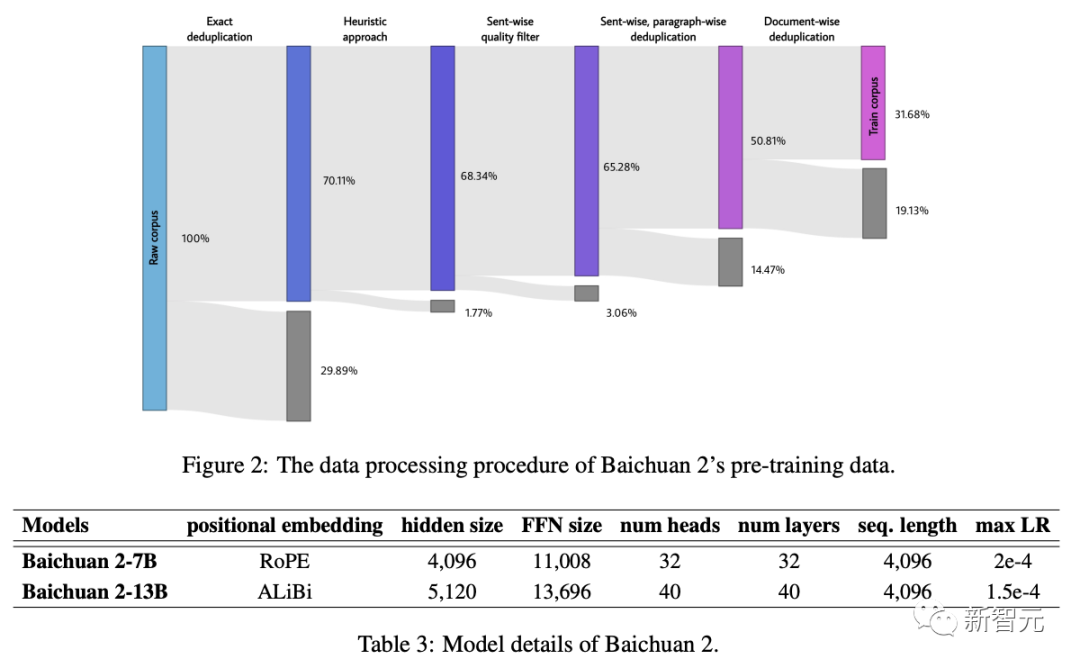
训练
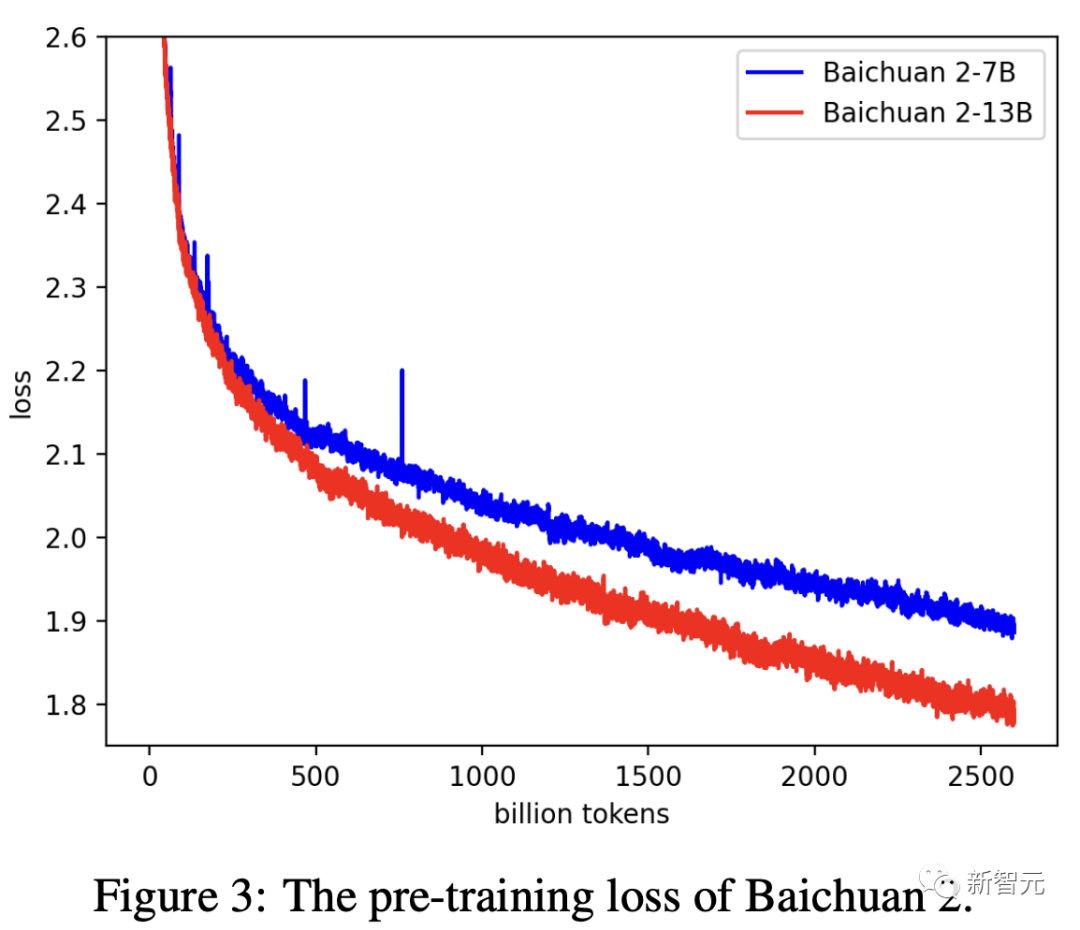
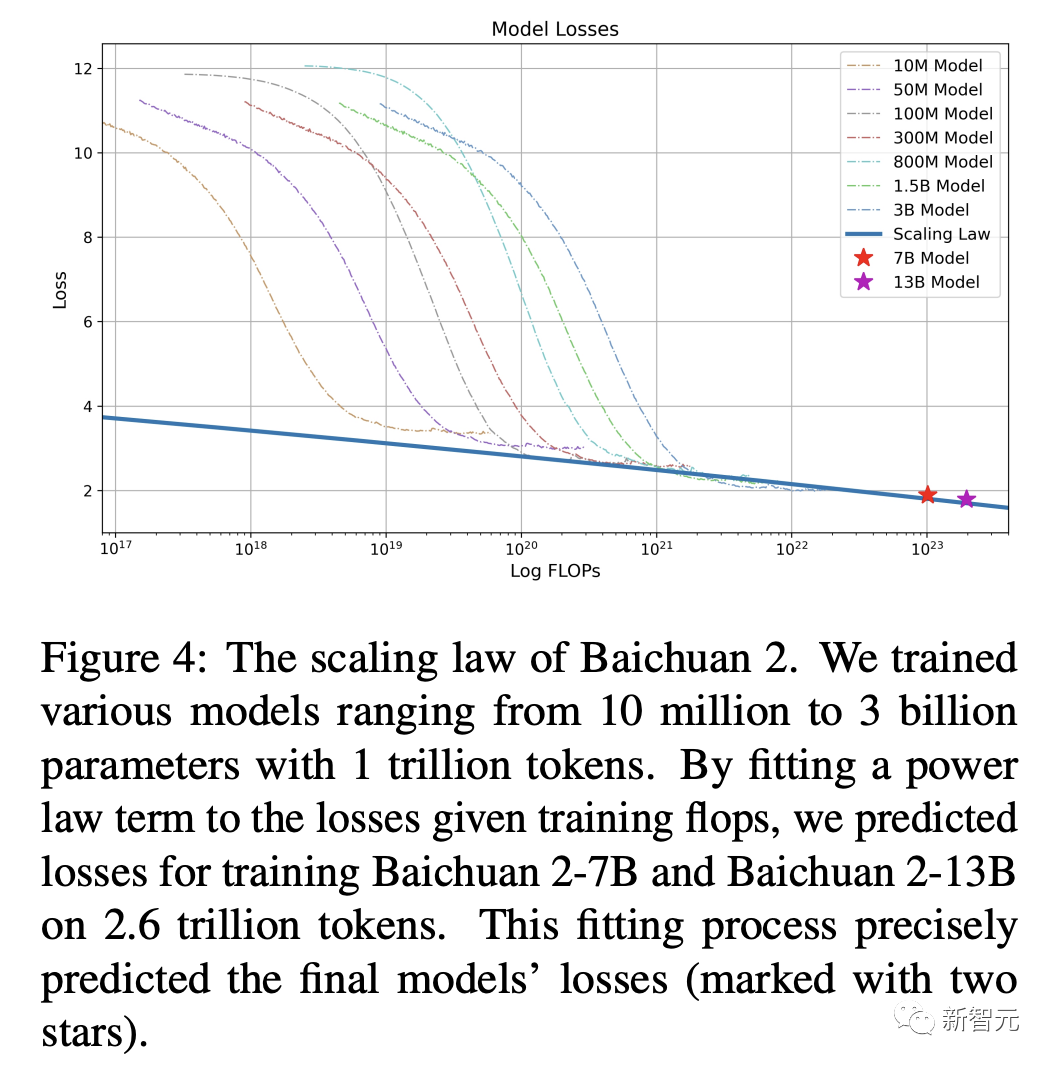
数据准备完成后,接下来就进入大模型最重要的阶段——训练。百川团队使用AdamW优化器,BFloat16混合精度对模型进行了训练。为了稳定训练过程,提高模型性能,研究还采用了NormHead,对输出embedding进行归一化处理。另外,在训练期间,百川团队还发现LLM的对数值可能会变得非常大,由此引入Max-z loss来稳定训练,让模型推理对超参数更加稳健。如下图,可以看到,Baichuan2-7B/13B的损失曲线在持续降低。以往研究表明,模型的性能随着参数规模的扩大呈现出一定的可预测性,也就是人们常说的scaling law。在训练数十亿参数的大型语言模型之前,百川智能预训练了从10M到30B参数的模型,总计token规模达1万亿。通过将幂律项拟合到给定训练浮点运算次数的损失中,可以预测在2.6万亿token上训练Baichuan2-7B和Baichuan2-13B的损失曲线。如下图所示,30M、50M、100M等不同参数规模的模型曲线都在下降,并且最后能够线性回归到一个值。这使得,在预测更大规模模型的性能时,能够有一个较为准确的估计。值得一提的是,这与OpenAI在发布GPT-4时的情况类似,只需要万分之一的训练,可以预测后面模型的性能。由此可见,整个拟合过程,能够较为精确地预测模型的损失。同时,百川基础设施的团队进行了大量工作,优化了集群性能,使得目前千卡A800集群达到180TFLOPS训练速度,机器利用率超过50%,达到行业领先水平。如上,在训练过程中,百川智能模型呈现出了高效、稳定、可预测的能力。安全
那么,训练后得到的模型,如何确保是安全的呢?百川智能在此也做了很多安全对齐的工作。在模型训练前,团队已经对整个数据集进行了严格的过滤,还策划了一个中英文双语数据集,纳入了各种正能量的数据。另一方面,百川智能还对模型做了微调增强,安全强化学习,设置了6种攻击类型,并进行了大量红蓝对抗训练,能够提升模型的鲁棒性。在强化学习优化阶段,通过DPO方法可以有效利用少量标注数据,来提升模型对特定漏洞问题的性能。另外,还采用了结合有益和无害目标的奖励模型,进行了PPO安全强化训练,在不降低模型有用性的前提下,显著增强了系统的安全性。可以看到,百川智能在模型安全对齐方面也做出很多努力,包括预训练数据加强、安全微调、安全强化学习、引入红蓝对抗。对于学术界来说,是什么阻碍了对大模型训练的深入研究?从0到1完整训练一个模型,成本是极其高昂的,每个环节都需要大量人力、算力的投入。其中,在大模型的训练上,更是包括了海量的高质量数据获取、大规模训练集群稳定训练、模型算法调优等等,失之毫厘,差之千里。然而,目前大部分的开源模型,只是对外公开了模型权重,对于训练细节却很少提及。并且,这些模型都是最终版本,甚至还带着Chat,对学术界并不友好。也是因此,企业、研究机构、开发者们,都只能在模型基础上做有限的微调,很难深入研究。针对这一点,百川智能直接公开了Baichuan 2的技术报告,并详细介绍了Baichuan 2训练的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等。
更重要的是,百川智能还开源了模型训练从220B到2640B全过程的Check Ponit。
这在国内开源生态尚属首次!
对于模型训练过程、模型继续训练和模型的价值观对齐等方面的研究来说,Check Ponit极具价值。
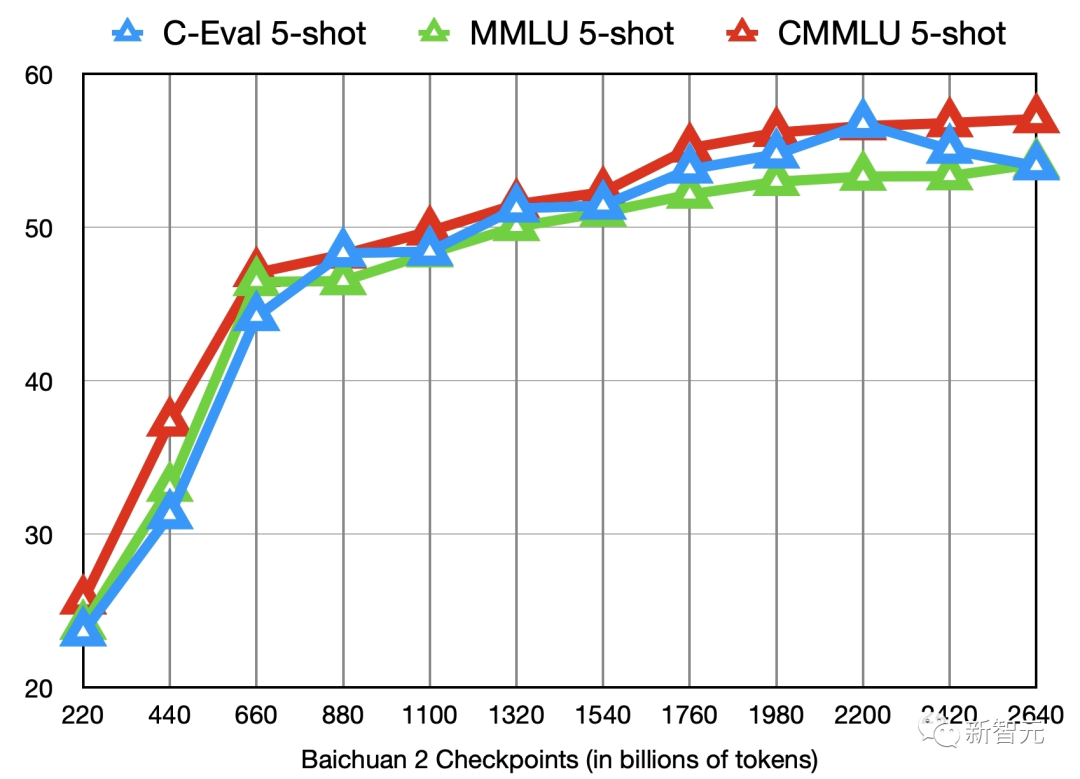
Baichuan 2的11个中间checkpoints在C-Eval、MMLU、CMMLU三个benchmark上的效果变化Baichuan系列发布的模型分片,对于研究大模型的本质来说有非常大的好处。我们既可以知道它每次的迭代过程,也可以在中间的分片里面做非常多的事情。而且,相比于那些直接开源最终版,甚至还是Chat版的模型,百川开源得非常干净,从底座开始就是很干净的语言模型。此外,很多的评测都是从单点维度进行的,甚至在某些榜单,GPT-4都排到第10了,这其实没有任何意义。而百川的评测结果就非常好。
而从商业角度看,Baichuan 2模型也是企业非常好的选择。之前免费可商用的Llama 2发布后,许多人认为这会对众多创业公司造成打击,因为它可以满足低成本、个性化的需求。但经过仔细思考就能明白,Llama 2并未改变市场格局。企业若是要用模型,即使是微调,也需要花费一些成本、精力和时间。而如果选一个性能较弱的模型(尤其是主要基于英文语料的模型),重新训练也是有难度的,成本几乎跟自己重新去做一个大模型差不多了。既然Llama 2不擅长中文,协议也禁止非英文场景商用化,因此显而易见,在商用领域,综合能力更强的开源模型Baichuan 2,几乎可以说是不二之选。基于Baichuan 2系列大模型,国内研究人员可以进行二次开发,快速将技术融进现实的场景之中。一言蔽之,Baichuan 2就像是源源不断地活水,不仅通过尽可能全面的开源来极大地推动国内大模型的科研进展,而且还通过降低国内商业部署门槛让应用创新能够不断涌现。https://github.com/baichuan-inc/Baichuan2

内容中包含的图片若涉及版权问题,请及时与我们联系删除










评论
沙发等你来抢