

【论文标题】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
【作者团队】Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
【发表时间】2020/10/22
【论文链接】https://arxiv.org/pdf/2010.11929v1.pdf
【论文代码】https://github.com/google-research/vision_transformer
【推荐理由】
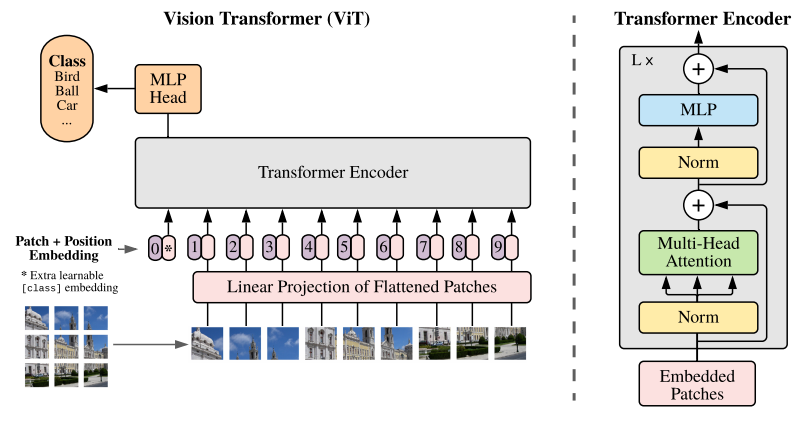
本文来自Google Brain团队,将NLP领域的transformer不作修改地搬到CV领域中。
Transformer 架构早已在自然语言处理任务中得到广泛应用,但在计算机视觉领域中仍然受到限制。在计算机视觉领域,注意力要么与卷积网络结合使用,要么用来代替卷积网络的某些组件,同时保持其整体架构不变。本文不同于以往工作的地方,就是尽可能地将NLP领域的transformer不作修改地搬到计算机视觉领域来。本文研究表明,对 CNN 的依赖不是必需的,当直接应用于图像块序列时,transformer 也能很好地执行图像分类任务。在实验中,本文作者发现,在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢