

新智元报道
新智元报道
【新智元导读】继各类输入端多模态大语言模型之后,新加坡国立大学华人团队近期开源了一种支持任意模态输入和任意模态输出的「大一统」多模态大模型,火爆AI社区。
「大一统」通用多模态大模型来了
正当大家都在期待OpenAI未来要发布的GPT-5是否实现了任意模态大一统功能时,来自于新加坡国立大学NExT++实验室的华人团队出手了! 就在最近,团队正式开源了一款「大一统」通用多模态大模型——NExT-GPT,可以支持任意模态输入到任意模态输出。 目前,NExT-GPT的代码已经开源,并且还上线了Demo系统。

项目地址:https://next-gpt.github.io
代码地址:https://github.com/NExT-GPT/NExT-GPT


话不多说,直接上效果
接下来,咱就来看看NExT-GPT到底可以实现哪些功能! - 文本 → 文本 + 图像 + 音频 - 文本 + 图像 → 文本 + 图像 + 视频 + 图像 - 文本 + 视频 → 文本 + 图像 - 文本 + 视频 → 文本 + 音频 - 文本 + 音频 → 文本 + 图像 + 视频 - 文本 → 文本 + 图像 + 音频 + 视频 - 文本 → 文本 + 图像 - 文本 + 视频 → 文本 + 图像 + 音频 - 文本 → 文本 + 图像 + 音频 + 视频 - 文本 → 文本 + 图像 可看到,NExT-GPT能够准确理解用户所输入的各类组合模态下的内容,并准确灵活地返回用户所要求的甚至隐含的多模态内容,从而输出图像、视频以及声音。 其中,常见的图生文、图生视频、看图像/声音/视频说话、图像/声音/视频问答等问题统统不在话下,统一了跨模态领域的大部分常见任务,做到了真正意义上的任意到任意模态的通用理解能力。 此外,作者还给出一些定量的实验结果验证,感兴趣的同学可以在论文中阅读详细内容。 技术点解析
技术点解析
众所周知,人类的认知和沟通必须无缝地在任何信息模态之间进行转换——我们不仅仅可以理解多模态内容,还能够以多模态的方式灵活输出信息。 但现有的大语言模型,一方面是局限于某种单一模态信息的处理,而缺乏真正「任意模态」的理解;另一方面是只关注于多模态内容在输入端的理解,而不能以任意多种模态的灵活形式输出内容。 那么,NExT-GPT又是如何实现任意模态输入到任意模态输出的呢? 原理其实非常简单,作者甚至表示在技术层面上「没有显著的创新点」—— 通过有机连接现有的开源1)LLM,2)多模态编码器和3)各种模态扩散解码器,便构成了NExT-GPT的整体框架,实现任意模态的输入和输出,可谓大道至简。 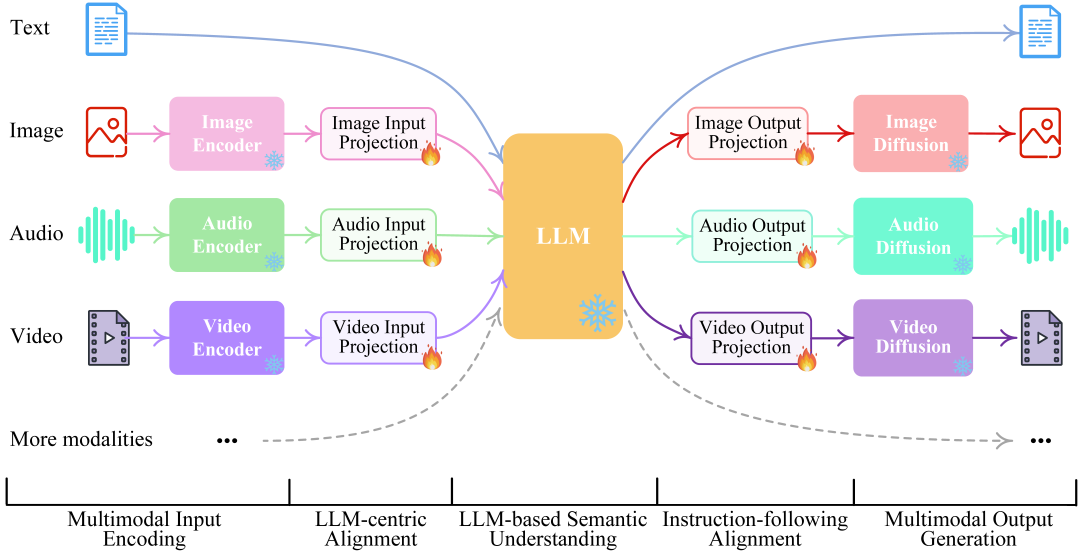
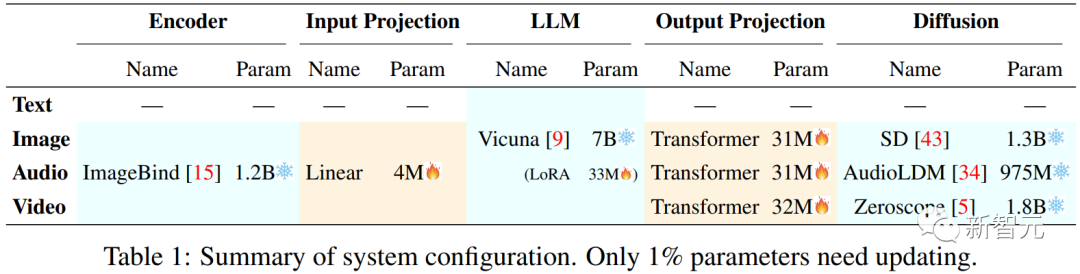
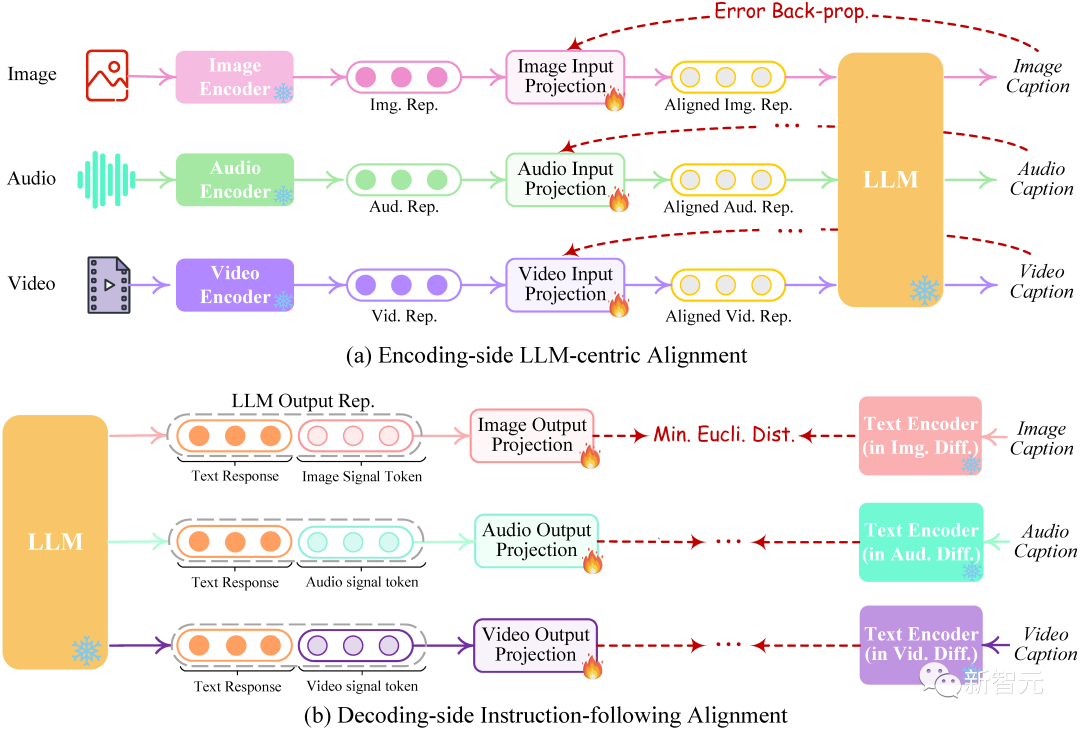
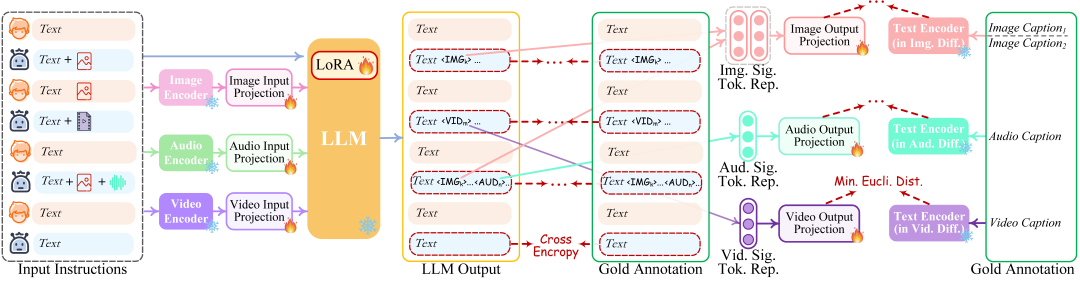
整体来说,模型呈现为一个「编码端-推理中枢-解码器」三层架构: - 多模编码阶段: 利用已开源的编码器对各种输入模态进行编码,然后通过一个投影层将这些特征投影为LLM所能够理解的「类似语言的」表征。中文作者采用了MetaAI的ImageBind统一多模态编码器。 - 推理中枢阶段: 利用开源LLM作为核心大脑来处理输入信息,进行语义理解和推理。LLM可以直接输出文本,同时其还将输出一种「模态信号」token,作为传递给后层解码端的指令,通知他们是否输出相应的模态信息,以及输出什么内容。作者目前采用了Vicuna作为其LLM。 - 多模生成阶段: 利用各类开源的图像扩散模型、声音扩散模型以及视频扩散模型,接收来自LLM的特定指令信号,并输出所对应的模型内容(如果需要生成的指令)。 在推理时,给定任意组合模态的用户输入,通过模态编码器编码后,投影器会将其转换为特征传递给LLM(文本部分的输入将会直接出入到LLM)。 然后LLM将决定所生成内容,一方面直接输出文本,另一方面输出模态信号token。 如果LLM确定要生成某种模态内容(除语言外),则会输出对应的模态信号token,表示该模态被激活。
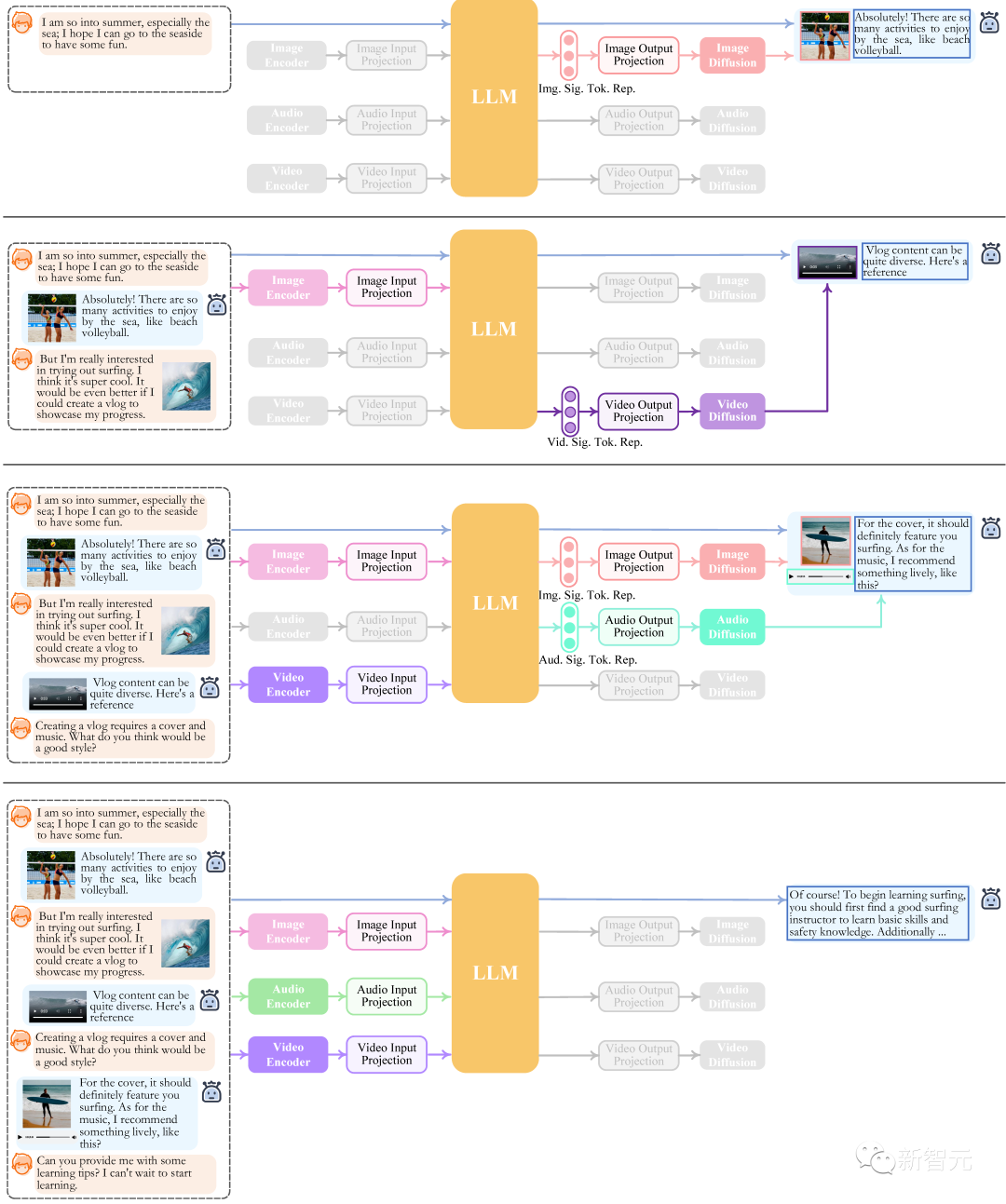
关键技术
研究亮点
结论与展望
基于NExT-GPT,后续的研究工作可以考虑以下几个方面: 1. 模态与任务扩展: 受限于现有资源,目前作者所开源的NExT-GPT系统仅支持四种模态:语言、图像、视频和音频。 作者表示,后续会逐步扩展到更多的模态(例如,网页、3D视觉、热图、表格和图表)和任务(例如,对象检测、分割、定位和跟踪),以扩大系统的普遍适用性。 2. 考虑更多基座LLM: 目前作者实现了基于7B版本的 Vicuna LLM,其表示下一步将整合不同大小的LLM,以及其他LLM类型。 3. 多模态生成策略: 目前版本的NExT-GPT系统仅考虑了基于扩散模型的纯输出方式的多模态输出。 然而生成模式容易输出错误幻想内容(Hallucination),并且输出内容的质量往往容易受到扩散模型能力的限制。 因此,进一步提升扩散模型的性能很关键,这能直接帮助提高多模态内容的输出质量。 另外,实际上可以整合基于检索的方法来补充基于生成的过程的弊端,从而提升整体系统的输出可靠性。 4. 降低多模态支持成本: NExT-GPT考虑了ImageBind来统一多种模态的编码,从而节省了在编码端的代价。而对于多模态输出端,作者简单地集成了多个不同模态的扩散模型。 在之后的研究中,可以考虑进一步降低对更多模态的支持的成本。尤其是,如何防止随着模态的增加而动态增加解码器。 比如,可以考虑将一些支持不同模态生成(但具有模态共性)的扩散模型进行复用。 5. MosIT数据集扩展: 目前NExT-GPT所使用的MosIT数据集规模受限,这也会限制其与用户的交互表现。后续研究可以进一步提升模态切换指令微调学习策略以及数据集。 总体上,NExT-GPT系统展示了构建一个通用大一统多模态的AI模型的可能性,这将为AI社区中后续的更「人类水平」的人工智能研究提供宝贵的借鉴。 参考资料: https://github.com/NExT-GPT/NExT-GPT



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢