
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
国产新标杆:免费可商用的200亿参数大模型,来了!
书生·浦语大模型(InternLM)20B版本正式发布,一举刷新国内新一代大模型开源纪录。
它由上海人工智能实验室(上海AI实验室)与商汤科技联合香港中文大学和复旦大学共同推出。
在综合性能上全面领先相近量级开源模型,包括Llama2-33B、Llama2-12B等。评测成绩达到Llama2-70B水平——要知道后者参数量是InternLM-20B的3倍多。

此外它还具备以下几方面亮点:
支持数十类插件、上万个API功能,在ToolBench上获得最佳结果
支持16K语境长度。
采用深结构,模型层数达60层
推理与编程能力显著提升
另一边,书生·浦语开源工具也做了全线升级,支持大模型从头打造到落地应用。
如上所有成果发布即开源,支持向企业和开发者提供免费商业授权。最新模型也已在阿里云魔塔社区(ModelScope)上首发。
这也是书生·浦语系列大模型,再一次升级和开源。
自今年6月首发以来,书生·浦语大模型在短短三个月时间里先后开源7B版本、推出123B版本,并率先在业内开源全链条工具体系。
属实是在开源这个方向上“卷”起来了~

而在这一系列紧锣密鼓动作背后,其实是由趋势、市场及自身使命共同推动。
上海AI实验室领军科学家林达华在解释最新进展时表示,技术浪潮最终要带来科技革命,科技革命如何向前发展,能沉淀下来什么非常关键。
上海AI实验室想做的,就是带来更多沉淀,更进一步引领国产力量在新一轮技术革命中抢占优势身位。
作为实验室,我们能提供基础模型以及将各行业的Know-how融汇成数据、模型能力的一系列工具,并且将它们做的非常易用、教会更多人用,让它们能在各个行业里开花结果。
那么,具体该怎么做?已经做到了什么?
来看看最新发布的InternLM-20B,就能找到答案。
同量级开源模型的“国货之光”
目前大模型领域的开源工作,上海AI实验室主要关注了两部分:
大模型,以及生产大模型的工具。
先来看最新开源的200亿参数规模大模型。
InternLM-20B是基于2.3T Tokens预训练语料从头训练的语言大模型。
相较于此前推出的InternLM-7B,训练语料经过了更高水平的多层次清洗,补充了高知识密度和用于强化理解及推理能力的训练数据。
所以,模型在理解、推理、数学、编程等方面能力更为突出。同时也兼具了工具调用能力,在安全和语境长度上也做了进一步加强。
多个测评性能领先
直观对比可以参考OpenCompass大模型测评平台结果。
研究人员在涵盖语言、知识、理解、推理和学科能力等武大维度的50个主流评测集上,对InternLM-20B进行全面比较。
结果显示,InternLM-20B在全维度上领先于开源13B量级模型,平均成绩不仅明显超越了Llama-33B,甚至优于被称为开源模型的标杆Llama2-70B。
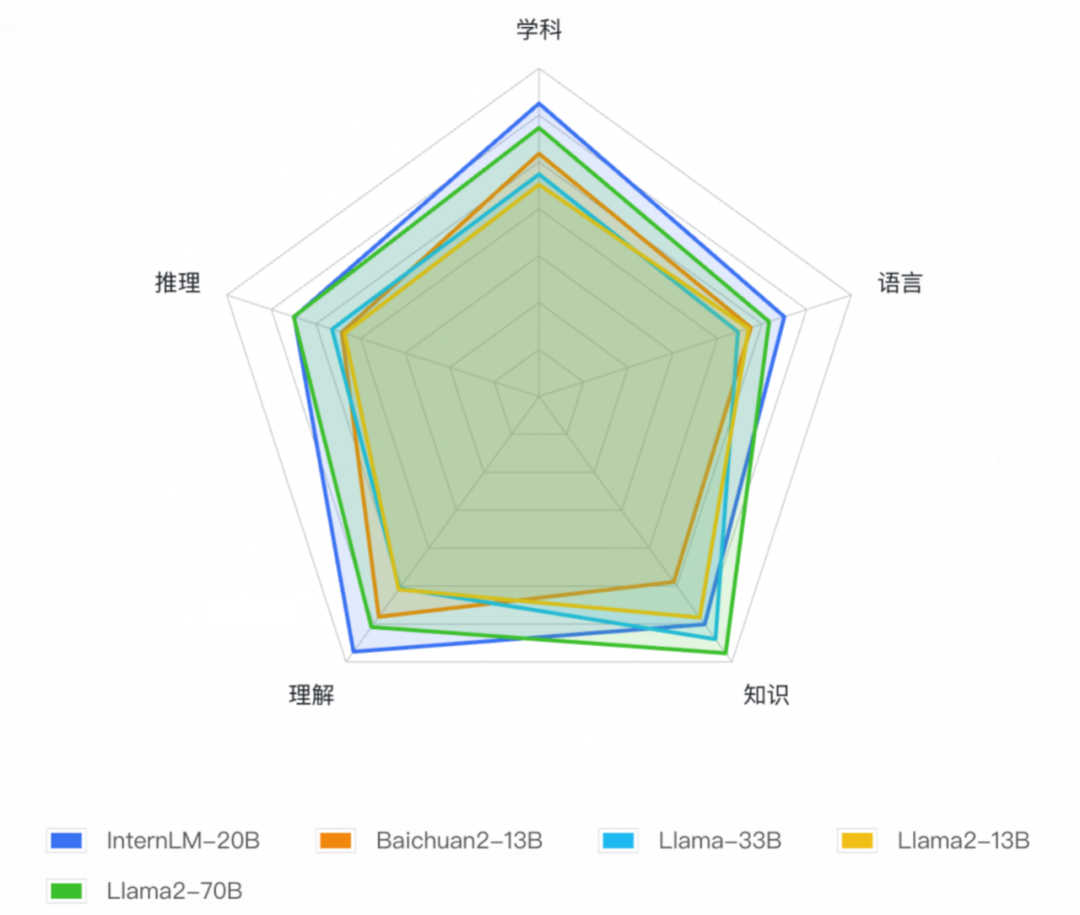
△基于OpenCompass的InternLM-20B及相近量级开源模型测评结果
具体数据结果如下:
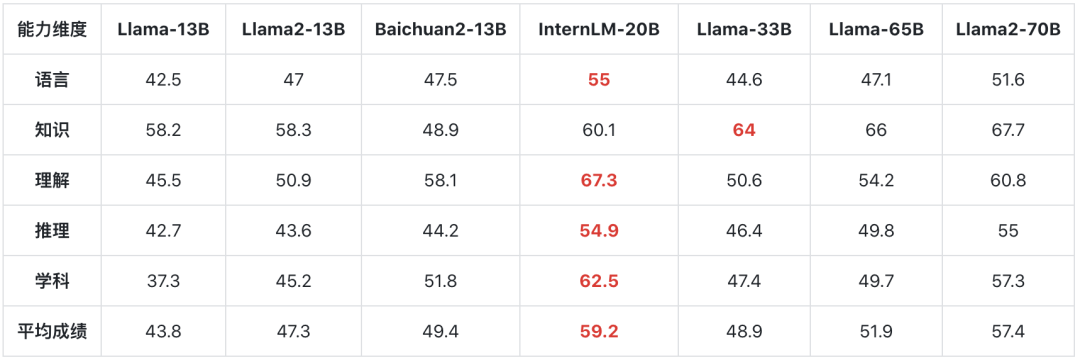
可以看出,InternLM-20B在语言、学科综合评测上都超越Llama2-70B。
在推理能力评测上和Llama2-70B持平,而知识方面则仍有一定差距。
同时,InternLM-20B也在其他多个主流数据集上进行了对比。
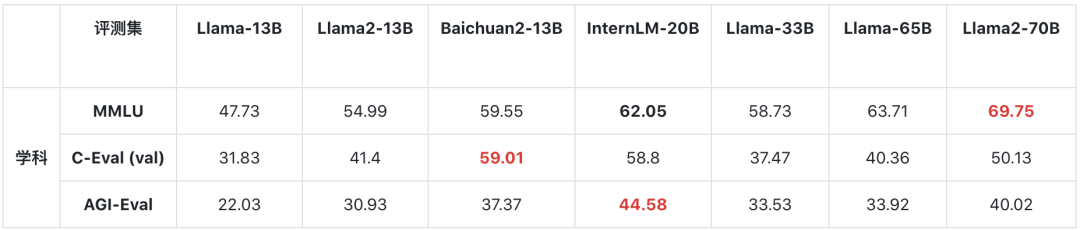
首先来看综合能力。
在MMLU上,InternLM-20B取得62.05的成绩,接近Llama-65B的水平。
在包含中文学科考试的C-Eval和AGIEval上,InternLM-20B的表现超过了Llama2-70B。
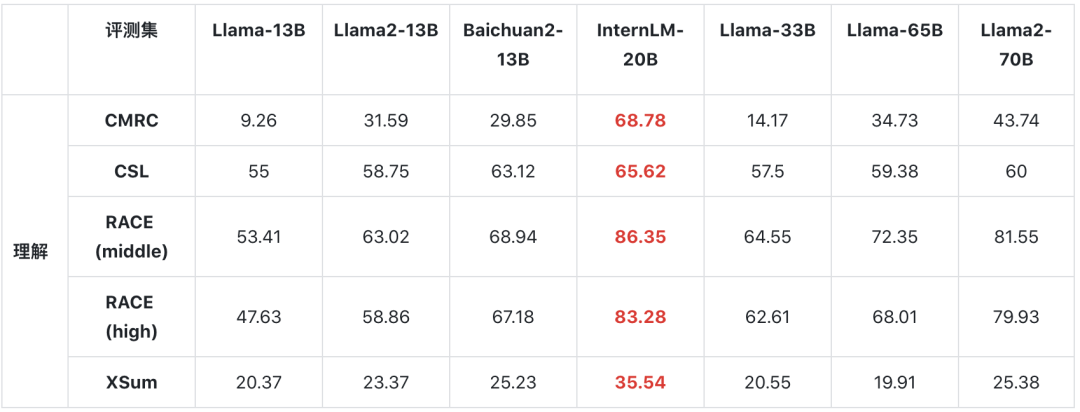
其次是理解能力考察,这里使用了CMRC、CSL、RACE和XSum几个数据集,它们分别面向百科知识、科技文献、学生阅读理解以及文献摘要评测。
在这一维度,InternLM-20B表现突出,全面超越包括Llama2-70B在内的各个量级的开源模型。
然后是推理方面,这也是大模型能否支撑实际应用的关键能力。
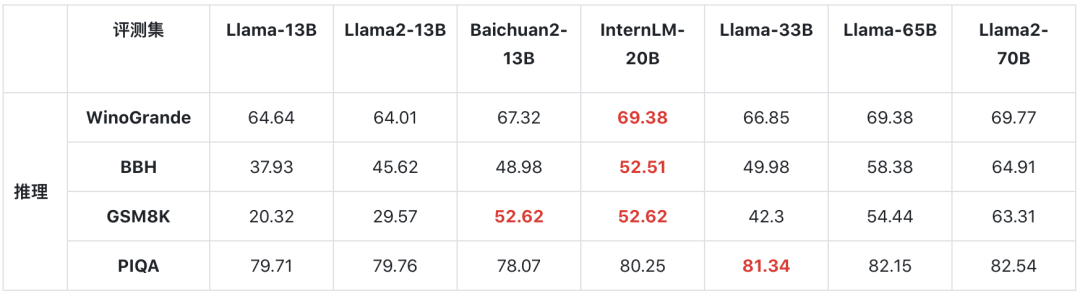
WinoGrande、GSM-8K、PIQA、BigBench-Hard(BBH)分别考察模型在常识推理、数学推理、物理相关推理、以及有挑战性的综合推理方面的能力。
InternLM-20B均获得明显超越主流的13B开源模型的成绩,在 WinoGrande、GSM8K和PIQA已经非常接近Llama-65B此类重量级模型的推理能力水平。
最后在编程方面,InternLM-20B也有明显提升。
在HumanEval和MBPP两个典型评测集上,全面超越了主流13B开源模型、Llama-33B和Llama-65B,接近Llama2-70B。

调用工具可“无师自通”
更进一步来看实际应用方面。
InternLM-20B对话模型支持了日期、天气、旅行、体育等数十个方向的内容输出及上万个不同的 API。
在清华大学等机构联合发布的大模型工具调用评测集ToolBench 中,InternLM-20B和 ChatGPT 相比,达到了63.5%的胜率,在该榜单上取得了最优结果。
值得一提的是,InternLM-20B模型还展现出一定的零样本泛化能力。
即便是没有学习过的工具,也能根据描述和提问作为引导,实现调用。
给它一个任务,同时提供AI工具,模型就能自己选择好对应插件,进行规划和推理,完成任务。
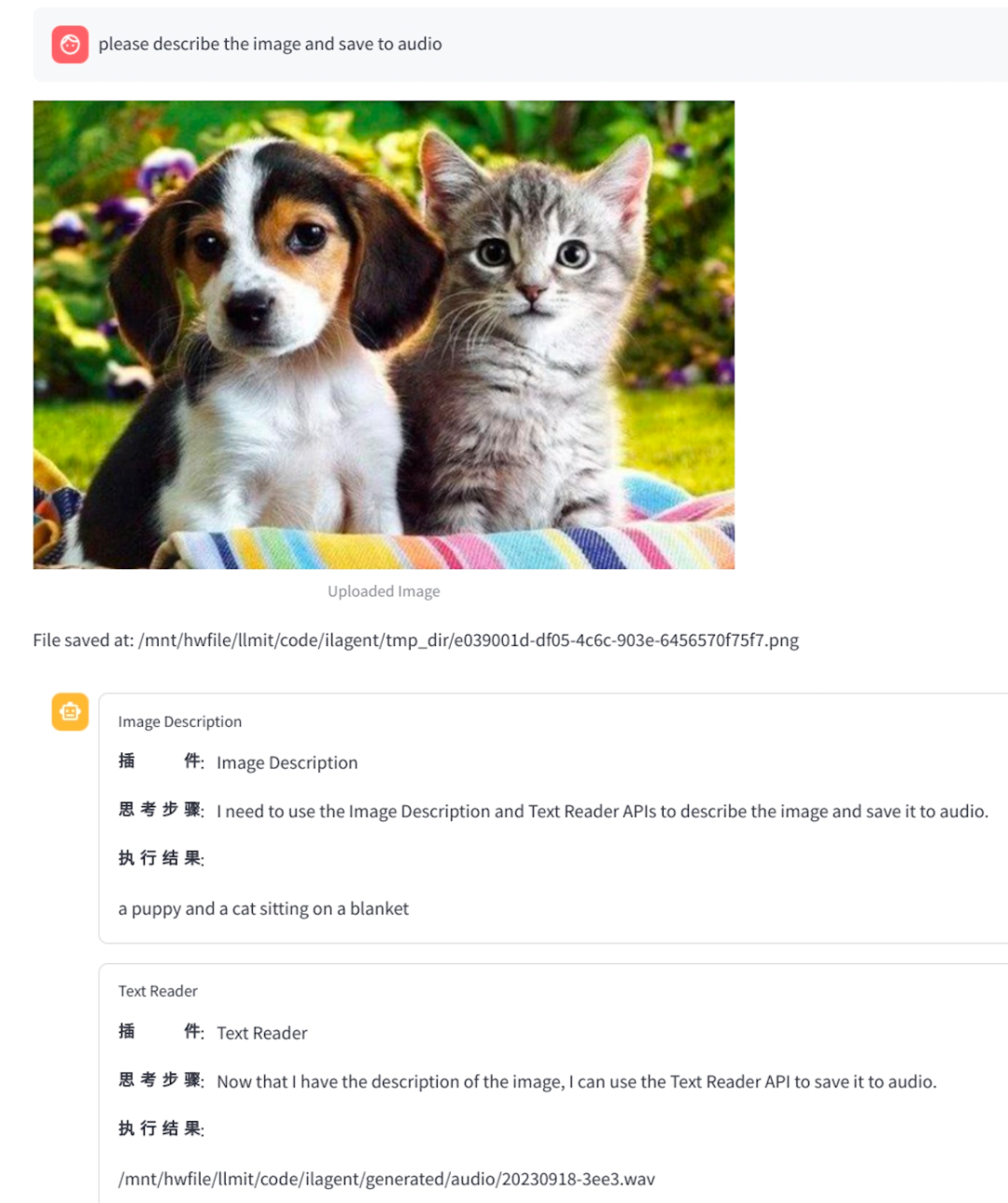
比如让它描述图片内容并且转成语音。
模型能自己从链接里找到需要的工具:图像描述和文字转语音,并且给出了“思考步骤”,然后解决了问题。
另外,InternLM-20B在安全性和语境长度上也做了增强。
面对疑似带有偏见的问题,模型不仅会拒绝回答,并且能给出不安全因素、正确价值观引导。

语境长度上从原来的8K提升到了16K。
现在InternLM-20B能有效支持长文理解、长文生成和超长对话。
比如看一整篇酱香拿铁的文章都没问题,还能正确回答提问。

同时也提升了总结摘要能力。
全链条工具体系大升级
而对于开发者来说,仅有开源模型还不够,好用的工具也也尤为关键。
由此,在今年7月InternLM-7B开源时,上海AI实验室等就率先开源了覆盖数据、预训练、微调、部署和评测的全链条工具体系。
如今随着更大规模模型的开源,这一工具体系也进行升级,并面向全社会提供免费商用。

数据方面,书生·万卷是上海AI实验室开源的多模态语料库,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。
预训练部分,本次还开源了InternLM-Train。
它深度整合Transformer模型算子,提升训练效率;同时提出Hybrid Zero技术,实现了计算和通信的高效重叠,训练过程中的跨节点通信流量大大降低。能实现千卡并行计算,训练性能达到了行业领先水平。
微调方面,低成本大模型微调工具箱XTuner也在近期开源,支持多种大模型和LoRA、QLoRA等微调算法。
通过XTuner,最低只需 8GB 显存,就可以对7B模型进行低成本微调,20B模型的微调也能在24G显存的消费级显卡上完成。
部署方面提供了LMDeploy,它涵盖大模型的全套轻量化、推理部署和服务解决方案,支持了从十亿到千亿参数的高效模型推理,在吞吐量等性能上超过了社区主流开源项目 FasterTransformer,vLLM,Deepspeed等。
评测部分则是上面提到过的OpenCompass平台,它构建了包含学科、语言、知识、理解、推理五大维度的评测体系,支持了超过50个评测数据集和30万道评测题目,支持零样本、小样本及思维链评测,是目前最全面的开源评测平台。
发布后被阿里巴巴、腾讯、清华大学等数十所企业与科研机构广泛应用于大语言模型和多模态模型研发。
最后,团队还关注到了大模型领域的热门应用智能体,开源了智能体框架Lagent,支持用户快速地将一个大语言模型转变为多种类型的智能体。
这套开源框架集合了多种类型的智能体能力,包括ReAct、AutoGPT 和 ReWoo 等,支持包括InternLM,Llama,ChatGPT在内的多个大语言模型。在Lagent加持下,这些智能体能够调用大语言模型进行规划推理和工具调用,并在执行过程中及时进行反思和自我修正。
△爆火的斯坦福“AI小镇”
总之,无论是从大模型本身,还是全链条工具体系出发,研究团队都非常关注大模型的实际应用问题,并将这些思考体现在了实际开源工作里。
比如开源模型规模选择了相对适中的200亿参数级别;推出了低成本大模型微调工具箱XTuner,降低模型微调显存要求。
甚至是模型的底层架构设计上,也有来自实际应用方面的思考。
InternLM-20B的模型层数设定为60,远超过常见7B、13B模型采用的32层或者40层设计,同时内部维度保持在5120,处于适中水平。
这是因为研究人员发现,目前大模型在适配下游任务时,对准确性和推理能力提出更高要求,但同时大家运行太大规模的模型都相对吃力,所以希望出现一个规模适中、性能又好的大模型。
他们通过广泛的对照实验发现,提高模型深度更有利于提升复杂推理能力,由此提出了这一深结构的模型架构。
那么问题来了——
为什么要如此关注模型的开源、降门槛问题?
做开源是使命
背后原因,有趋势方面的直接影响,也有内在因素驱动。
直接原因来自市场需求。
上海AI实验室领军科学家林达华介绍,今年上半年出现了多个70亿参数级别的大模型,在一定程度上展现了不错的能力。
但随着趋势演进,如今行业内外更加关注大模型的应用落地问题,70亿参数大模型在满足实际商业应用方面遇到了很多问题。
也就是说,当下需要更大规模的开源大模型。
而200亿参数规模,刚好能兼顾高性能和低门槛。
林达华表示这是取了一个中间值。
7B规模属于轻量级模型,70B属于重量级,这之间差了十倍。而20B刚好是7B的三倍左右,同时也是65B-70B的三分之一左右。
同时20B规模给硬件层面提出的要求也不高。一台服务器可完成训练、微调,单卡即可搞定推理。

更大范围还有来自趋势的影响。
今年,大模型热潮走入下半场,推理应用的需求不断增长。
业内普遍认为,大模型的最终应用不会局限在几家头部公司,而是全社会、各个行业、不同企业都能深入其中。
同时大模型趋势也需要非常多的开发者、企业、机构加入,带来更多创造力,把大模型价值落地,才能让这一波技术浪潮的影响更为广泛。
林达华也透露,在他们日常接触到的开发者/群体中,不乏中小企业、研究组,甚至是一个学生或者研究员。
他们有想法、有创新力,唯一缺的就是资源。
所以需要开源出来更为强大的基础模型、更好用的开发工具,推动广大开发者能在低成本情况下落地大模型,从而产生更多领域内价值。
最后,坚持开源是上海AI实验室一直以来的使命,也是他们擅长的事。
在此之前,上海AI实验室搭建了开源平台体系OpenXLab,其中包括浦视视觉智能开源平台OpenMMLab、浦策决策智能开源平台OpenDILab、书生通用视觉开源开放平台OpenGVLab等十余个开放平台。
今年6月,InternLM千亿参数语言大模型(104B)首次对外发布。
仅一个月后便推出开源的7B版本,供免费商用,并率先在业内开源了全链条工具体系。
8月,实验室联合多个大模型语料数据联盟成员,共同发布“书生·万卷1.0”多模态预训练语料库,开源了涵盖文本、图文和视频在内总量超过2TB的大模型训练数据。

由此,也就不难理解为什么InternLM-20B会在此时被推出。
而InternLM-20B的开源,不仅给开发者们带来了实用的模型,同时也为开源社区本身提供了一些经验参考。
具体来看可以体现在三方面:
内部验证再开源
密切关注社区反馈
结合自身技术趋势思考
林达华介绍,上海AI实验室做开源的逻辑其实非常简单,就是内部怎么做,便把这样的技术体系分享出来。
这就是全链条工具体系开源的起点。
在开发书生·浦语大模型时,团队内部沉淀出了一套研发体系,它由数据、预训练、应用等团队构成,模型训练出来后也需要有专门团队来做评测。
每个团队在推进这些工作时,自然会沉淀下来一整套工具。他们就将自己研发过程中使用的东西,直接开源出来。
而且,这种开源是格外有底气且有效率的——因为经过内部验证后,可以确保工具好用,最终也一定会被更多人利用起来。
另一方面,开源模型、工具好不好用,还一个主要评判维度就体现在了细节上。
开发者们来自学术界、工业界,大家需求存在差异,开源团队需要能及时关注到这些需求。
在这方面,上海AI实验室已经构建了活跃的开源社区,有专门团队看社区反馈,然后对模型进行迭代升级。同时也会对大家提出的各种问题进行解答。
以及团队的开源步骤如何推进,也是最大限度从社区需求出发。

而除此之外,更为底层的开源逻辑在于,团队本身是否对趋势洞察足够敏感,并能带来原始性创新。
比如在InternLM-20B的开源工作中,林达华反复提及了团队对于推理部分的重视。
在这背后其实是大模型趋势再更进一步向实际应用倾斜。而对于这一点的洞察,团队在今年3、4月就已意识到了。
并且团队能够在洞察趋势后,给出提高应用能力的解决路线——提升数理、代码、工具能力。
在数理方面,团队不仅用常规数学数据训练模型,更进一步将语料构建成了知识体系,形成一个知识密度、逻辑密度非常高的数据库。某种程度上,在这里1个token相当于普通数据10个、甚至更多token的效力。由此能更进一步催生大模型能力。
代码方面,InternLM-Chat-7B v1.1是首个具备代码解释能力的开源对话模型,支持Python解释器、搜索引擎等外部工具来拓展能力边界。
工具方面,林达华认为当下大模型的核心应用早已不局限在聊天这个范畴,更大的需求体现在如何让大模型成为一个聪明的中央大脑。
所以在最新的开源工作中,我们看到了模型在工具调用方面的加强,并且具备反思修正能力。
总之,在开源方面,上海AI实验室已经沉淀出了一套自己的方法论。
用最简要的一句话来概括,那就是——
坚持完整、持续的开源
不可否认,年初的ChatGPT热潮正在逐渐消散。
而热浪褪去后的沉淀,才是推动技术革命向前发展的关键。
在这样的背景下,上海AI实验室想做的,就是带来更多沉淀。
作为实验室,我们能提供基础模型以及将各行业的Know-how融汇成数据、模型能力的一系列工具,并且将它们做的非常易用、教会更多人用,让它们能在各个行业里开花结果。

提出这样宏大的愿景,底气是什么?
当然有人才、算力、数据作为底层支柱,但更为关键的还是上海AI实验室,已经形成了非常高效的研究闭环。
从头开发大模型是一个相当复杂的系统工程,OpenAI、Google都没有公布过具体研发细节,这意味着每一个发起攻坚的团队都要自己摸索路线。
上海AI实验室的做法是,把大模型需要突破的维度再细分成若干个不同维度,比如具体到语言、推理、编程、数理等方面,然后由不同小组团队负责。
每个小组都会在解决一个问题后,沉淀出很多Know-how,实验室在最后会将这些Know-how汇总,形成下一版模型训练的配方。
换言之,在上海AI实验室内部形成了一套异常严谨、高效、紧密合作的研发模式。
这便使得他们能以更快速度、进行更极致创新。
如今,上海AI实验室的开源工作还在紧锣密鼓进行中。据透露,他们下一步将逐步开源和应用结合更紧密的模型;同时也正在考虑开源一些产品级应用。
总之,从愿景落到实处,上海AI实验室希望通过开源,不断降低大模型门槛。
正如林达华所说:
大模型的最终价值和任何技术都一样,都要在应用中产生价值。
而这或许才是当下大模型趋势里,大家最应该“卷”的方向。
你觉得呢?
— 完 —
点这里👇关注我,记得标星哦~

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢