
我们人类依靠五种感官来解释我们周围的世界。我们利用视觉、听觉、触觉、味觉和嗅觉来收集有关环境的信息并理解它。同样,多模态是人工智能的一个令人兴奋的新领域,它试图通过组合来自多个模型的信息来复制这种能力。通过集成文本、图像、音频和视频等不同来源的信息,对底层数据建立更丰富、更完整的理解,解锁新的见解,并实现广泛的应用。
多模态中使用的技术包括基于融合的方法、基于对齐的方法和后期融合。在本文中,我们将探讨多模态学习的基础知识,包括用于融合不同来源信息的不同技术,以及它的许多令人兴奋的应用,从语音识别到自动驾驶汽车等。
多模态是人工智能的一个子领域,旨在有效地处理和分析来自多种模态的数据。简单来说,这意味着结合来自文本、图像、音频和视频等不同来源的信息,以建立对底层数据更完整、更准确的理解。
一、组合模型技术
组合模型是机器学习中的一项技术,涉及使用多个模型来提高单个模型的性能。组合模型背后的想法是,一个模型的优点可以弥补另一个模型的缺点,从而产生更准确、更稳健的预测。集成模型、堆叠和Bagging是组合模型时使用的技术。

在组合模型中,模型是独立训练的,并通过使用集成模型、堆叠或装袋等技术组合这些模型的输出来做出最终预测。当各个模型具有互补的优点和缺点时,组合模型特别有用,因为组合可以带来更准确、更稳健的预测。
组合模型和多模态学习之间的主要区别在于,组合模型涉及使用多个模型来提高单个模型的性能。相比之下,多模态学习涉及学习并组合来自图像、文本和音频等多种模态的信息来执行预测。现在,让我们看看多模态技术。
二、多模态技术
1.融合的方法
基于融合的方法涉及将不同模态输入编码到公共表示空间中,以创建单一模态不变的表示。该表示捕获来自所有模态的语义信息。根据融合发生的时间,这种方法可以进一步分为早期融合和中期融合技术。
基于融合的方法的典型示例是图像和文本字幕。这是基于融合的方法,因为图像的视觉特征和文本的语义信息被编码到公共表示空间中,然后融合以生成单个模态不变表示,该表示从两种模态捕获语义信息。

2.对齐的方法
这种方法涉及调整不同的模式,以便可以直接比较它们。目标是创建可以跨模态进行比较的模态不变表示。

基于对齐的方法的一个例子是手语识别任务。这种使用涉及基于对齐的方法,因为它需要模型对齐视觉(视频帧)和音频(音频波形)模态的时间信息。模型的任务是识别手语手势并将其翻译成文本。使用摄像机捕获手势,并且必须对齐相应的音频和两种模态才能准确识别手势。这涉及识别视频帧和音频波形之间的时间对齐,以识别手势和相应的口头单词。
3.后期融合的方法
这种方法涉及结合分别在每种模态上训练的模型的预测。然后将各个预测组合起来以创建最终预测。当模式不直接相关或者各个模式提供补充信息时,这种方法特别有用。

现实生活中晚期融合的一个例子是音乐中的情感识别。在此任务中,模型必须使用音频特征和歌词来识别一首音乐的情感内容。本示例中应用了后期融合方法,因为它结合了在不同模式(音频特征和歌词)上训练的模型的预测来创建最终预测。各个模型在每种模态上分别进行训练,并在稍后阶段组合预测。因此,后期融合。

例如,您可以训练一个单独的机器学习模型,以使用音频特征(例如 MFCC 和频谱对比度)来预测每首歌曲的情感内容。可以训练另一个模型来使用歌词来预测每首歌曲的情感内容,并使用词袋或词嵌入等技术来表示。训练各个模型后,可以使用后期融合方法组合每个模型的预测以生成最终预测。
三、多模态的优势
多模态技术有几个优点,其中包括:
1. 提高准确性:通过利用来自多种模态的信息,与单模态人工智能相比,多模态人工智能可以实现更高的准确性和鲁棒性。例如,在分析客户对产品的反馈的系统中,结合文本、图像和音频模式可以更全面地了解客户情况。
2.增强用户体验:多模态技术可以通过为用户与系统交互提供多种方式来增强用户体验。例如,在虚拟助理系统中,用户可以使用语音、文本或手势与系统交互,从而提供更大的便利性和可访问性。
3. 抗噪声鲁棒性:通过结合多种模态的信息,多模态人工智能可以对输入数据中的噪声和变异性具有更强的鲁棒性。例如,在结合音频和视觉信息的语音识别系统中,即使音频信号降级或说话者的嘴被部分遮挡,系统也可以继续识别语音。
4. 资源的有效利用:多模态人工智能可以使系统专注于每种模态中最相关的信息,从而帮助更有效地利用计算和数据资源。例如,在评估社交媒体帖子进行情感分析的系统中,结合文本、图像和元数据可以帮助减少需要处理的不相关数据量。
5.更好的可解释性:多模态人工智能可以通过提供可用于解释系统输出的多个信息源来帮助提高可解释性。例如,在分析医学图像进行诊断的系统中,将图像与文本描述和其他模式相结合可以帮助解释系统诊断背后的推理,并提供更多的透明度和问责制。
四、典型应用
1.电影分级

多模态融合的一个现实例子是电影推荐系统。在这种情况下,系统可能使用文本数据(电影描述、评论或用户配置文件)、音频数据(音轨、对话)和视觉数据(电影海报、视频剪辑)来为用户生成个性化推荐。融合过程结合了这些不同的信息源,以更准确、更有意义地了解用户的偏好和兴趣,从而产生更好的电影建议。MovieLens 数据集是一个适合开发融合电影推荐系统的现实数据集。
2.医学诊断
在医学诊断中,不同的医学成像模式(例如 CT 扫描和 MRI 扫描)为诊断提供补充信息。多模态协同学习可用于组合这些模态以提高诊断的准确性。
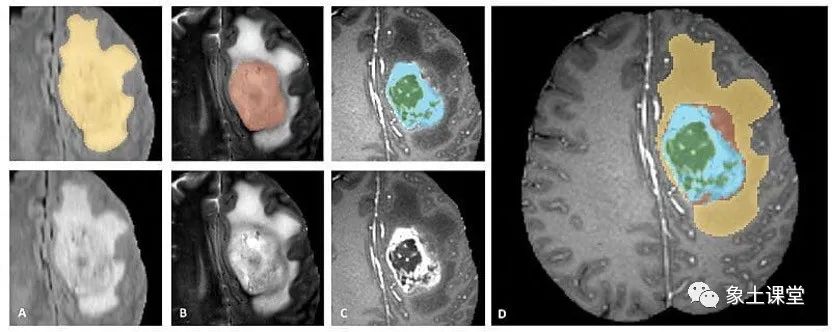
例如,对于脑肿瘤,MRI 扫描可提供软组织的高分辨率图像,而 CT 扫描可提供骨骼结构的详细图像。结合这些方法可以全面了解患者的病情并为治疗决策提供信息。多模态脑肿瘤分割 (BraTS) 数据集包含用于多模态协同学习的脑肿瘤 MRI 和 CT 扫描数据。
3.语音识别

多模态学习可以通过结合音频和视觉数据来提高语音识别的准确性。例如,多模态模型可以分析语音的音频信号和相应的嘴唇运动,以提高语音识别的准确性。通过结合音频和视觉模态,多模态模型可以减少噪声和语音信号变化的影响,从而提高语音识别性能。

可用于语音识别的多模态数据集的一个示例是CMU-MOSEI 数据集。
4.自动驾驶
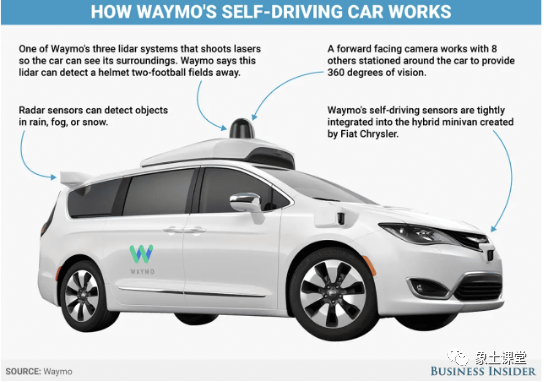
多模态学习可通过集成多个传感器的信息来增强机器人的能力。
例如,它对于开发自动驾驶汽车至关重要,自动驾驶汽车依赖来自摄像头、激光雷达和雷达等多个传感器的信息来导航和做出决策。多模态学习有助于整合来自这些传感器的信息,使汽车能够更准确、更有效地感知环境并做出反应。自动驾驶汽车数据集的一个例子是Waymo 开放数据集,其中包括来自 Waymo 自动驾驶汽车的高分辨率传感器数据,以及车辆、行人和骑自行车者等物体的标签。
五、总结
从医疗保健到金融、从娱乐业到农业,各行各业逐步发现使用多模态人工智能的好处,新的落地场景也在不断的涌现。多模态通过结合不同模式的优势,使他们能够做出更好的决策并改善结果。随着技术不断发展并变得更加先进,我们可以预测多模态技术会在未来几年内带来更大的创新和影响。你做好准备了吗?!
欢迎关注我们的课程
《多模态大模型核心理论与微调技术》
掌握多模态核心理论及微调技术!抢占职业先机!
课程亮点
多模态大模型的关键技术;
多模态模型微调技巧(VisualGLM-6B);
多模态表示、多源理解和生成技术;
深入剖析多模态模型架构设计思路;
详解图像及语言模型(ViT、Conformer、LLM)融合;
知名多模态大模型排名。
适合人群
课程需要具备NLP知识基础和相关从业经验。
算法工程师、NLP领域从业者、应届毕业生、往届生、转型的开发工程师、AI爱好者。
购课&了解更多
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢