
Anima大语言模型更新发布了基于LLama2的可商用开源的7B模型,支持100K的输入窗口长度!
专门针对100K输入长度精选了长文本问答训练数据,并且做了很多内存优化使得LLama2模型能scale到100K的输入长度。
01
优化输入窗口长度是AI的未来
大语言模型智能程度越来越高。但是能处理的数据量输入长度都很有限,大部分只有4k,有一些支持到32K。
模型空有很强的推理分析能力,并没有办法把这个能力应用到处理大量的数据上。
真正的智能 = 大数据 x 推理分析能力
仅有LLM强大的推理能力,没有能力处理足够大量的有效信息,并不能真的提供足够解决现实世界问题的智能。
常见的Retrieval Augmented Generation (RAG)的方法,将文本切段,做向量化索引,推理时通过向量召回选择一部分信息输入大语言模型。RAG可以一定程度上解决输入长度不足的问题。但是常常碰到召回不足,或者召回过量的问题。对于数据的切分方式也常常很难找到最合理的方式。
对于很多实际的数据处理问题,最有价值的部分其实是怎么从海量的信息中发现和选择最有价值的部分。很多时候如果真的准确的选择了对需要的信息,其实不需要多大的智能就可以解决问题了。
RAG的方法本质上并没有把今天AI的最高智能的大语言模型用到这个最关键的信息选择的问题上。而是一个没有交叉注意力(cross attention)机制的Embedding模型,能力很弱鸡。
更重要的是,RAG的假设是信息的分布是稀疏的。关键的信息只存在局部,真实世界很多情况这不成立。很多时候最宝贵的信息是需要全文综合才能提炼的,缺了哪个局部都不够。
提升LLM的输入窗口长度才能真的让最高的AI智能应用到最多的数据上。
简单的说,大模型,只大不够,又大又长才是王道!

02
100K难在哪?
100K的训练和推理,最大的难点是内存消耗。Transformer训练过程的很多内存的大小很多是正比于输入序列长度的二次方的,当输入长度达到100K的时候,就是
比如,原始HF中Llama2的实现代码中的330行的代码:
attn_weights = torch.matmul( \query_states, key_states.transpose(2, 3)) \/ math.sqrt(self.head_dim)
运行这一行代码时,需要分配的内存量为:
这一行代码就需要分配600GB的显存。一行代码干出8块A100😓😓。


03
Anima 100K的内存优化技术
为了优化模型训练100K序列长度时的内存消耗,我们组合使用了各种最新的科技与狠活:

XEntropy可以把
Paged 8bit Adamw, 可以通过用8 bit block-wise quantization把adam optimizer中的states, Momentum的内存占用从32 bit降到8 bit,降低4倍。
LORA, 让我们不需要优化全部的参数,只需要用一个LORA的稀疏矩阵的乘积代替。
100k的输入会碰到各种OOM的问题,我们对transformer的代码做了一些修改优化,解决了各种内存问题。
04
100k训练数据
05
100k评测
| 模型 | Accuracy |
| Claude2 | 0.9 |
| together llama2 32k | 0.15 |
| longchat 32k 1.5 | 0.05 |
| Anima 100k | 0.5 |
| 模型 | Accuracy |
| Claude2 | 1.0 |
| together llama2 32k | 0.2 |
| longchat 32k 1.5 | 0.05 |
| Anima 100k | 0.45 |
| 模型 | F1 |
| Claude2 | 0.6187 |
| together llama2 32k | 0.3833 |
| longchat 32k 1.5 | 0.2416 |
| Anima 100k | 0.4919 |
06
模型开源
开源模型可以在huggingface中找到(lyogavin/Anima-7B-100K)。
训练、评测、推理的代码欢迎访问我们的github repo(https://github.com/lyogavin/Anima/anima_100k)。
这一次仅开源了英文版的模型。中文模型暂未公开开放,现在接受申请,可以添加"AI统治世界计划"的公众号,后台输入“100K”申请访问。
07
谁是凶手?
有了100k的处理能力,我们可以做很多有趣的事情。
比如,我们可以把一整本小说输入给模型,让他回答一些问题。
我们把著名硬汉侦探小说劳伦斯布洛克的《八百万种死法》整本输入给模型,让他回答几个问题:
谁是真正的杀死Kim的凶手?
文中Kim的男友到底是谁?
为了构造悬念,侦探小说常常需要给出各种错误的讯息误导读者,然后结尾再上演好几次的大反转。模型必须能完整的理解整本书的内容,才能不被误导。找到真正的答案。
这本书的长度略超过了100k,我们随机切掉了中间的一部分内容。然后剩下接近100k的内容全部输入给Anima 100K。

看看Anima 100K能否看懂这本书找到谁是凶手:
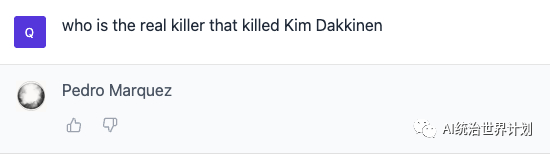
答对了!👍
再看看另一个问题:
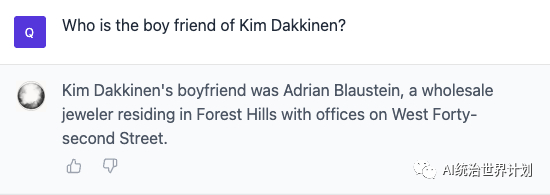
这个问题也准确答对了。
看来Anima 100k已经具备了理解和分析超长输入内容的能力。
再来看看RAG + GPT4怎么样:
因为输入窗口不能超过8K,我们基于RAG将文本切分索引,然后基于问题选择top 3输入,分别prompt给GPT4,答案如下:
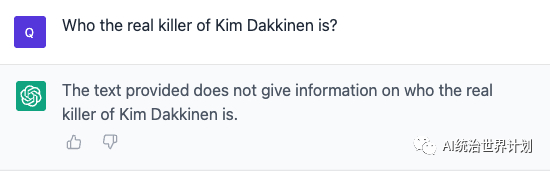
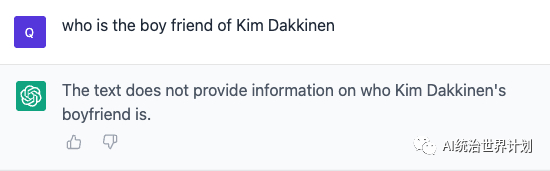
我们会持续开源更多最新的最有效的paper和算法,为开源社区贡献。请关注我们,获取最新后续进展。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢