
书生·浦语 InternLM-20B 于 9 月 20 日发布,现已正式登陆 Hugging Face!
你可以在 Hugging Face Hub 中查阅模型以及 Space 应用~
Base 模型:
https://huggingface.co/internlm/internlm-20b
Chat 模型:
https://huggingface.co/internlm/internlm-chat-20b
Space 应用地址:
https://huggingface.co/spaces/BridgeEight/internlm-20B-chat-w4-turbomind
(应用由社区用户 BridgeEight 上传)
在 Hugging Face 最新公布的 Open LLM Leaderboard 评测榜单上,InternLM-20B 在参数量 60B 以下基模型中平均成绩领先,也超过了Llama-65B。
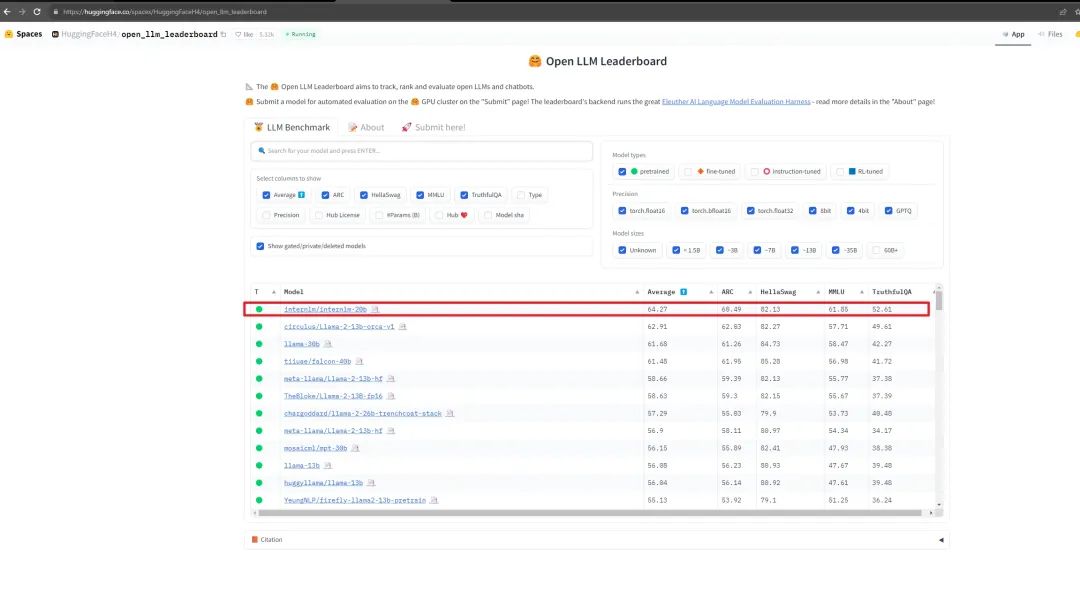
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
本文我们将重点教大家如何在 Hugging Face 使用 InternLM-20B。
InternLM-20B 是什么?
InternLM-20B 是基于 2.3T token 预训练语料从头训练的中量级语言大模型。相较于 InternLM-7B,训练语料经过了更高水平的多层次清洗,补充了高知识密度和用于强化理解及推理能力的训练数据。因此,在理解能力、推理能力、数学能力、编程能力等考验语言模型技术水平等方面,InternLM-20B 都有显著提升。
InternLM-20B 的优势是什么?
相比于此前的开源模型,InternLM-20B 的能力优势主要体现在:
优异的综合性能: InternLM-20B 具备优异的综合性能,不仅全面领先相近量级的开源模型(包括 Llama-33B、Llama2-13B 以及国内主流的 7B、13B 开源模型),并且以不足三分之一的参数量,测评成绩达到了 Llama2-70B的水平。
强大的工具调用能力: InternLM-20B 拓展了模型的能力边界,实现了大模型与现实场景的有效连接。InternLM-20B 支持数十类插件,上万个 API 功能,在 ToolBench 评测集上获得了最佳结果,在与 ChatGPT 的竞赛中,胜率达到 63.5%。InternLM-20B 还具备代码解释和反思修正能力,为智能体(Agent)的构建提供了良好的技术基础。
更长的语境: InternLM-20B 支持 16K 语境长度,从而更有效地支撑长文理解、长文生成和超长对话。
更安全的价值对齐: 相比于之前版本,InternLM-20B 在价值对齐上更加安全可靠。在研发训练的过程中,研究团队进行了基于 SFT(监督微调)和 RLHF(基于人类反馈的强化学习方式)两阶段价值对齐,并通过专家红队的对抗训练,大幅提高其安全性。当用户带着偏见向它提问时,它能够给出正面引导。
全线升级的开源工具、数据体系: 书生·浦语开源工具链全线升级,形成了更为完善的工具体系,其中包括预训练框架 InternLM-Train、低成本微调框架 XTuner、部署推理框架 LMDeploy、评测框架 OpenCompass 以及面向场景应用的智能体框架 Lagent。书生·浦语工具链将和开源数据平台 OpenDataLab 构成强大的开源工具及数据体系,共同为学术界和产业界提供一条龙的研发与应用支持。
如何使用 InternLM-20B
使用 LMDeploy 部署 InternLM-20B
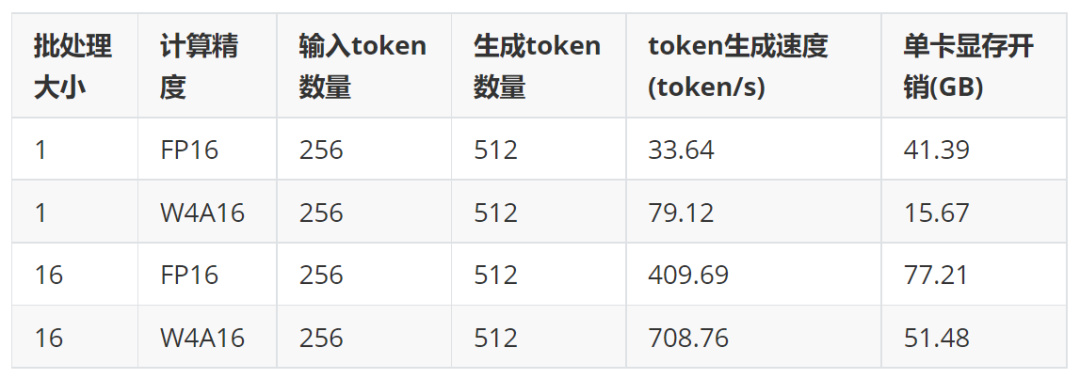
我们推荐使用 LMDeploy 4bit 量化和推理能力来部署 InternLM-20B 模型。与 FP16 计算精度相比,LMDeploy 4bit 量化推理不仅把模型的显存降低 60% 以上,更重要的是,经过 kernel 层面的极致优化,推理速度并未损失,反而是 FP16 推理速度的两倍以上。
第一步:安装 lmdeploy
pip install 'lmdeploy>=0.0.9'第二步:下载 InternLM-20B-4bit 模型
git-lfs installgit clone https://huggingface.co/internlm/internlm-chat-20b-4bit
第三步:转换模型权重格式
python3 -m lmdeploy.serve.turbomind.deploy internlm-chat \--model-path ./internlm-chat-20b-4bit \--model-format awq \--group-size 128
第四步:启动 gradio 服务
python3 -m lmdeploy.serve.gradio.app ./workspace --server_name {ip_addr} --server_port {port}了解 LMDeploy 的更多内容,请关注 https://github.com/InternLM/lmdeploy
使用 XTuner 24G 显卡
低成本微调 InternLM-20B
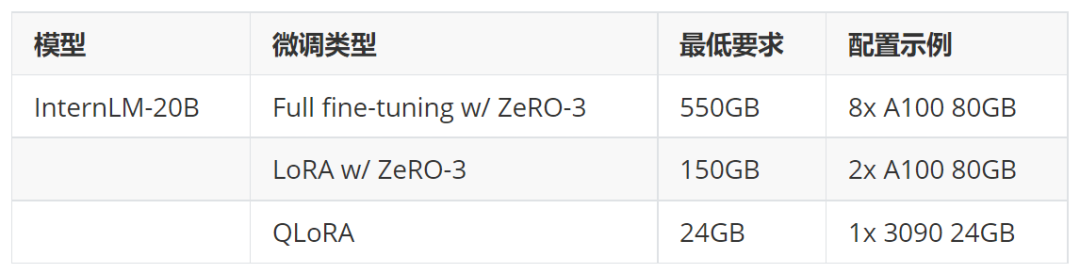
XTuner 是上海人工智能实验室开发的低成本大模型训练、微调工具箱,通过 XTuner,仅需 24GB 显存,就可以微调 InternLM-20B 系列模型。
目前,XTuner 已支持 InternLM-20B 模型的全参数、LoRA、QLoRA 微调,集成 DeepSpeed ZeRO 2/3 训练优化技巧,并支持诸如 Alpaca、OpenAssistant 等热门开源数据集,用户可以“开箱即用”!
硬件要求
快速上手
只需两行命令,外加 24GB 显存,即可实现 InternLM-20B 的 QLoRA 微调(以 oasst1 数据集为例):
pip install xtunerxtuner train internlm_20b_qlora_oasst1_512_e3
同时,XTuner 已内嵌了众多 InternLM-20B 微调配置文件,用户可以通过下列命令查看:
xtuner list-cfg -p internlm_20b面向专业级用户,如果有自定义训练流程、自定义训练数据等深度需求,则可以导出示例配置文件,并进行自定义修改,实现灵活配置:
xtuner copy-cfg internlm_20b_qlora_oasst1_512_e3 ${SAVE_PATH}探索 XTuner 的更多内容,请关注 https://github.com/InternLM/xtuner
本文转载自社区供稿内容,不代表官方立场。了解更多,请关注微信公众号"InternLM":
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢