
点击下方卡片,关注「集智书童」公众号

最近主流的Masked知识蒸馏方法通过从其教师网络的特征映射中选择性地重建学生网络的Masked区域来实现。在这些方法中,Masked区域需要被正确选择,以便重建的特征能够编码足够的区分性和代表性,就像教师特征一样。然而,先前的Masked知识蒸馏方法只关注了空间Masked,导致重建的Masked区域偏向于空间重要性,而没有编码有信息量的通道线索。
在这项研究中,作者设计了一个双重Masked知识蒸馏(DMKD)框架,可以捕获全面的Masked特征重建的空间重要性和通道信息提示。具体来说,作者采用双重注意力机制来引导各自的Masked分支,从而导致重建的特征编码双重重要性。
此外,通过自适应权重策略来融合重建特征,以实现有效的特征蒸馏。作者在目标检测任务上的实验证明,在使用RetinaNet和级联Mask R-CNN分别作为教师网络时,借助DMKD,学生网络的性能提升了4.1%和4.3%,同时优于其他最先进的蒸馏方法。
众所周知,知识蒸馏能够将复杂教师网络中学到的深层知识传递给轻量级的学生网络。早期的知识蒸馏算法主要关注网络的输出Head,代表性的方案包括基于logit的分类蒸馏和基于Head的检测蒸馏。最近,基于特征的蒸馏策略受到越来越多的关注,因为它具有良好的任务不可知的灵活性。特别是,特征蒸馏帮助学生网络模仿教师特征,增强了表征能力。
在目标检测中,已经开发了各种先进的特征蒸馏方法。具体来说,经典的FitNet在全局特征级别上执行了蒸馏。FGD被开发出来在统一框架内区分前景和背景的蒸馏。CWD简单地最小化了两个网络的通道概率图之间的Kullback-Leibler散度,蒸馏过程倾向于每个通道的最重要的区域。
在特征蒸馏方法中,最近的研究表明,学生模型最好首先从教师模型中重建重要特征,而不是跟随教师生成具有竞争力的表示。例如,MGD被提出来随机Masked学生网络特征图中的像素,通过一个简单的块生成教师模型的重建特征。AMD在学生网络的特征图上执行基于注意力的特征Masked,使得可以通过空间自适应特征Masked来识别特定区域的重要特征,而不是像以前的方法中的随机Masked。
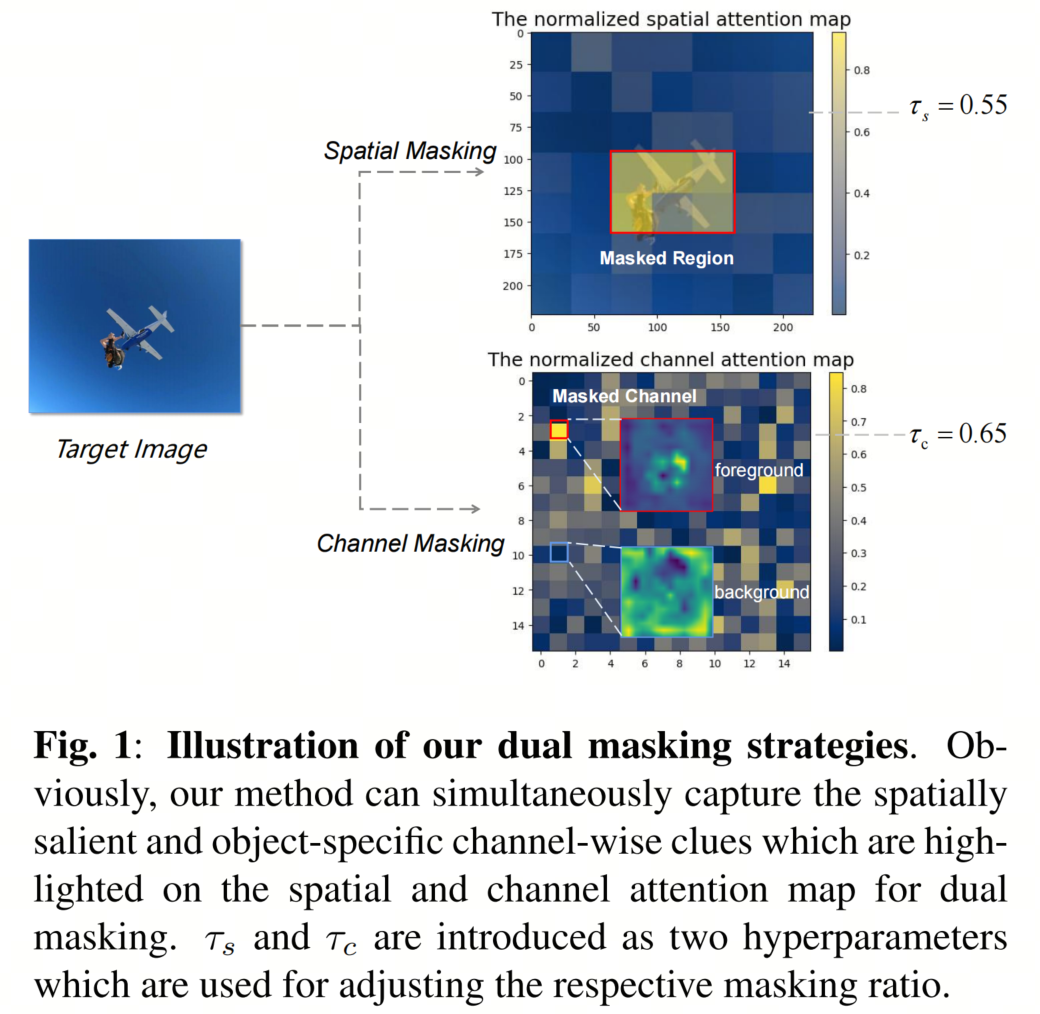
尽管当前的Masked特征蒸馏方法有助于提高学生模型的性能,但上述方法中的选择性Masked区域仅考虑了空间重要性。例如,MGD执行随机特征Masked,不考虑位置,导致被重建的区域是无信息和语义不相关的。AMD在识别空间显著区域时使用了空间Masked,这在一定程度上减轻了这一限制,但仍然无法识别对于密集预测任务至关重要的信息通道。
而在这项研究中,作者尝试捕获空间重要区域和物体感知的通道信息,这两者都可以通过双重注意力机制获得。具体来说,图1中显示的双重Mask策略用于Masked特征重建,以全面描述重要的物体感知特征。

如图2所示,与仅捕获有辨别能力的局部特征(鸟的Head和身体)的MGD和AMD相比,作者的DMKD为改进的表示能力提供了更全面的物体特定编码。
在详细介绍作者提出的方法之前,作者简要回顾基本的基于特征的蒸馏框架,其公式如下:
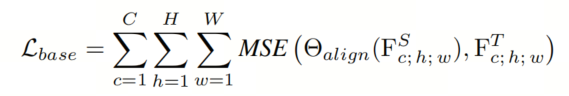
其中, 是从学生或教师网络生成的特征图。表示学生特征与可学习函数对齐的拟合误差和教师特征之间的拟合误差。
从上述公式可以看出,基本特征蒸馏模型要求学生原始特征尽可能接近教师的对应特征。从这个意义上说,教师充当要直接模仿的模板,特征蒸馏可以被认为是一个直接且简单的算法,因为学生和教师网络的特征直接用于表示匹配。
为了全面编码物体感知语义到学生网络中,作者开发了一个双重Mask知识蒸馏(DMKD)框架,其中既揭示了空间显著区域,又揭示了信息丰富的通道,以进行更好的Masked特征重建。
值得注意的是,作者的模型可以被视为一个即插即用的增强模块,适用于基本的基于特征的蒸馏方法。
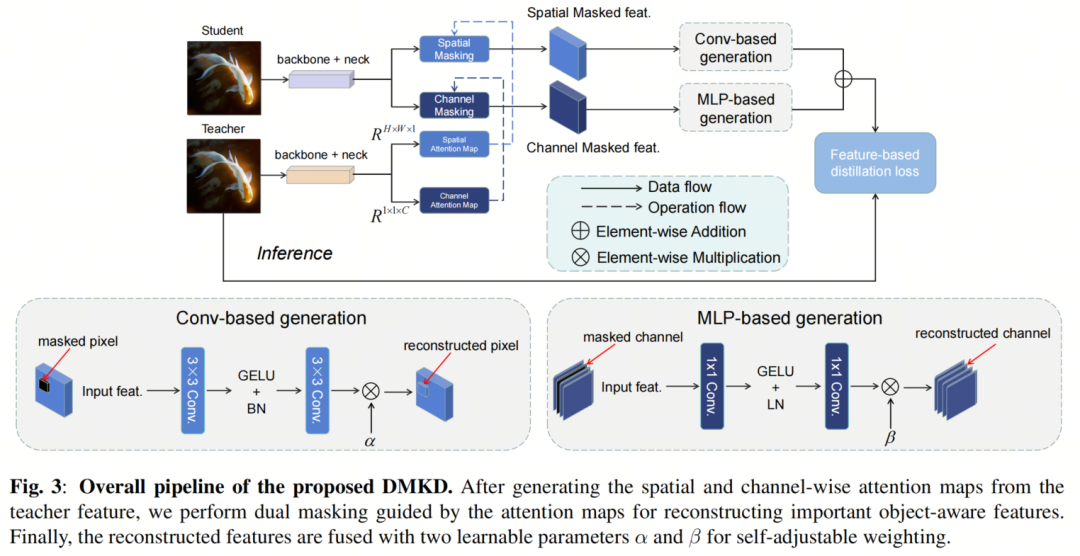
如图3所示,作者的DMKD包括三个关键步骤:双重注意力图生成,注意力引导的Masked和自适应权重融合。首先,从教师特征中产生空间和通道注意力图,如下所示:
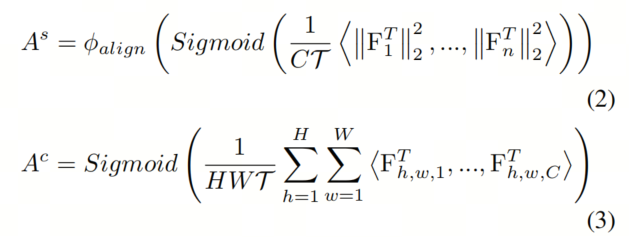
其中, 和 分别是空间和通道注意力图。公式(2)中的是教师特征图的第个向量,而公式(3)中的是第通道的特征图。引入以调整分布。
接下来,生成的双重注意力图和用于根据阈值和导出相应的Mask图和:
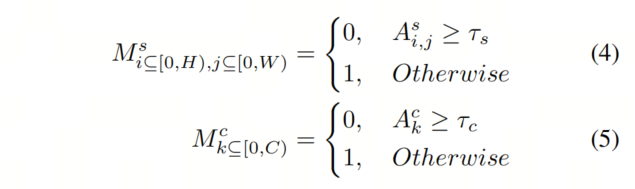
其中,和与和具有相同的形状。然后,作者利用它们对学生特征进行空间和通道Masked,生成两个Masked特征和:
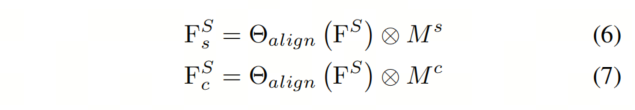
其中,表示逐元素相乘。
最后,分别采用卷积和多层感知器(MLP)的两个不同的生成块来重建空间和通道Masked特征。值得注意的是,通道重建是通过MLP完成的,与MGD和AMD中的空间重建不同,因为通道特征在空间上是相互独立的。
换句话说,这个生成层应该只关注通道间的交互,这将在消融研究中进行演示。此外,引入了成对的自适应权重因子和来融合双重重建特征,得到最终的学生特征,其公式如下:
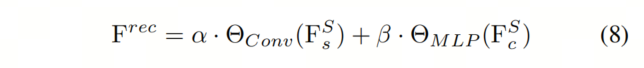
因此,蒸馏损失可以建立在重建的学生特征 和教师对应特征上,如下所示:
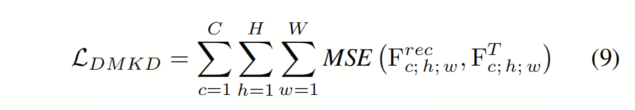
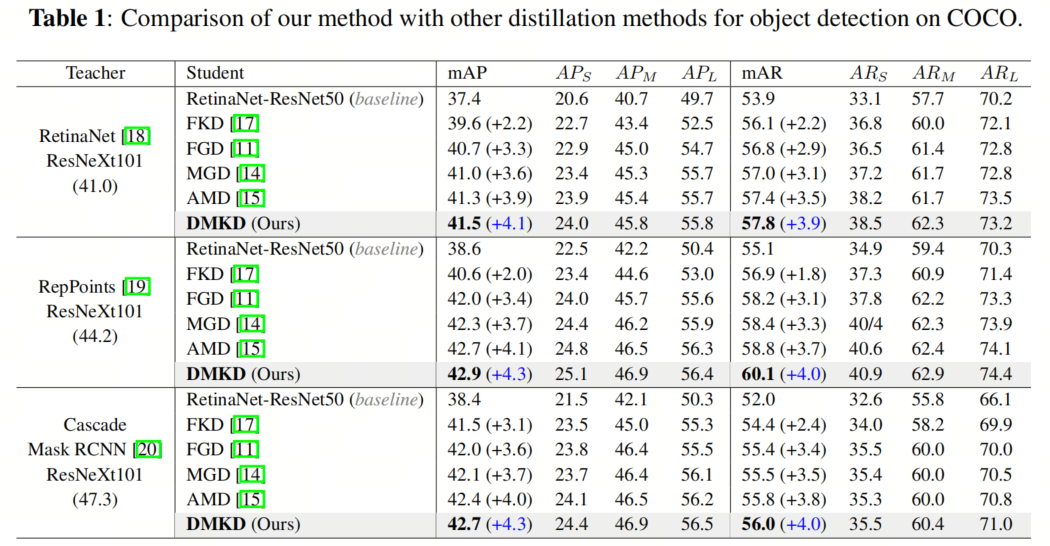
如表1所示,在第一组实验中,结果表明作者的DMKD不仅将Baseline学生模型的mAP提高了4.1%,还超过了教师网络0.5%的mAP。
与最先进的MGD和AMD相比,DMKD的优势体现在进一步提高了0.5%和0.2%的性能。在mAR指标方面,DMKD也表现出类似的性能优越性。当将RetinaNet网络替换为其他检测器时,也呈现了类似的结果。
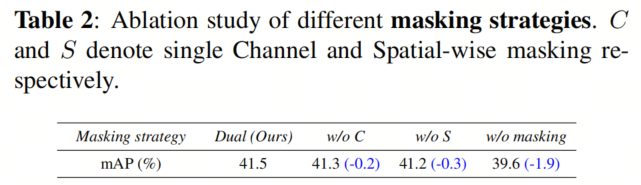
首先,作者探讨了特征Masked对蒸馏性能的影响,并比较了不同的Masked策略。如表2所示,当没有任何Masked策略参与时,可以观察到性能显著下降,超过1.5%,表明Masked策略在特征蒸馏中起到了有益的作用,以增强特征重构。
此外,当将作者的双重Masked方案与两种单一Masked策略进行比较时,都呈现了一致的性能提升,表明双重Masked在捕获空间显着区域和信息丰富的通道线索方面具有优势,以编码全面的面向对象的表示。
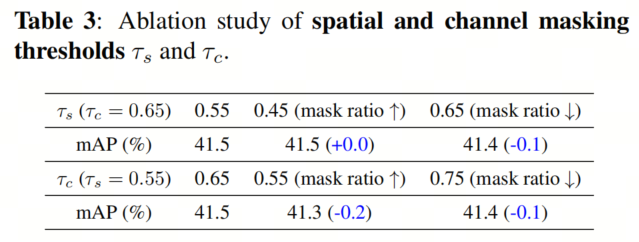
表3展示了DMKD在不同Masked比例下的性能。可以清楚地看到,当减小空间Masked比例并增加时,模型性能略微下降,这与MAE中的发现一致。这意味着一些空间重要的区域可能被排除在空间Masked之外。
另一方面,当增加通道Masked比例时,也可以观察到类似的性能下降,表明模型过于关注冗余和非信息性的通道。在作者的实验中,双重阈值τs和τc的经验设定为0.55和0.65。

作者还讨论了特征生成块设计对通道特征重构的影响。如表4所示,作者的DMKD中的基于MLP的模块比基于Conv的模块表现更好。这可以解释为MLP操作符的属性,即与ConvNets中的空间交互相反,它独立于空间维度,并且仅对通道间关系进行建模。
具体来说,作者在实践中使用了两个连续的线性投影 和,然后是GELU和Layer Normalization。
[1]. DMKD: IMPROVING FEATURE-BASED KNOWLEDGE DISTILLATION FOR OBJECT DETECTION VIA DUAL MASKING AUGMENTATION.
DualToken-ViT | 超越LightViT和MobileNet v2,实现更强更快更轻量化的Backbone
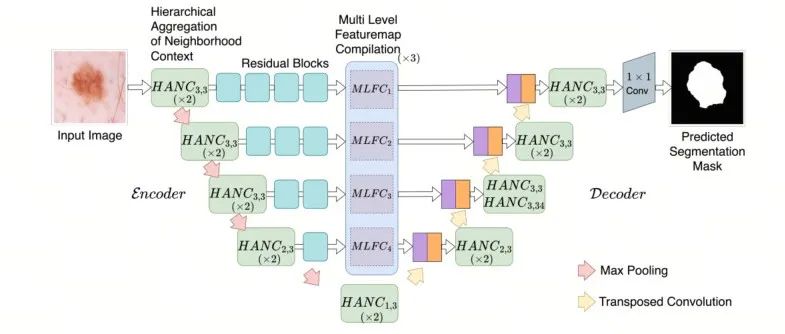
ACC-UNet | 致敬ConvNeXt,全卷积结构UNet设计,超越SWin-UNet!
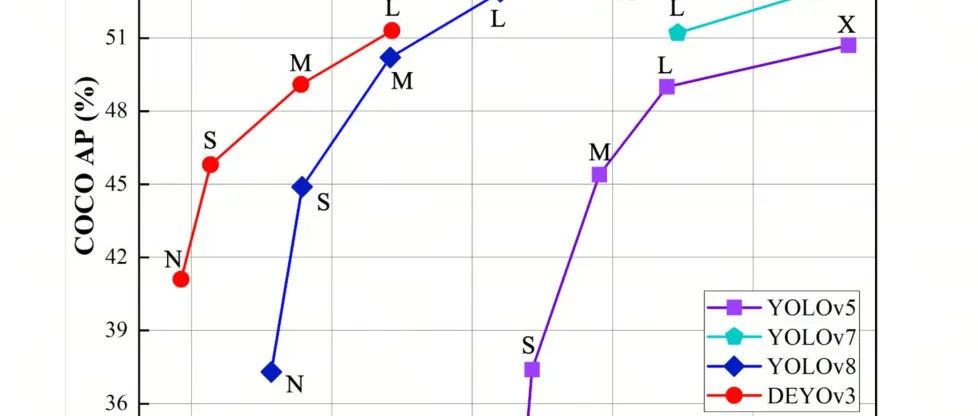
DEYOv3来袭 | YOLOv8+DETR造就实时端到端目标检测,无需NMS(主打吸引不开源)

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢