
Datawhale干货
分享:马毅教授团队,来源:新智元
【导读】马毅教授团队最新研究表明,微调多模态大语言模型(MLLM)将会导致灾难性遗忘。
模型灾难性遗忘,成为当前一个关键热门话题,甚至连GPT-4也无法避免。
近日,来自UC伯克利、NYU等机构研究人员发现,微调后的多模态大模型,会产生灾难性遗忘。

论文地址:https://arxiv.org/abs/2309.10313
论文中,研究团队引入了首个研究MLLM灾难性遗忘的评估框架——EMT(Evaluating MulTimodality)。(老二次元的基因动了)
在多个基准上评估4个模型后,发现多数模型无法保持与其基础视觉编码器(CLIP)相似的分类性能。
同时,在一个数据集上对LLaVA进行微调会导致在其他数据集上出现灾难性遗忘。
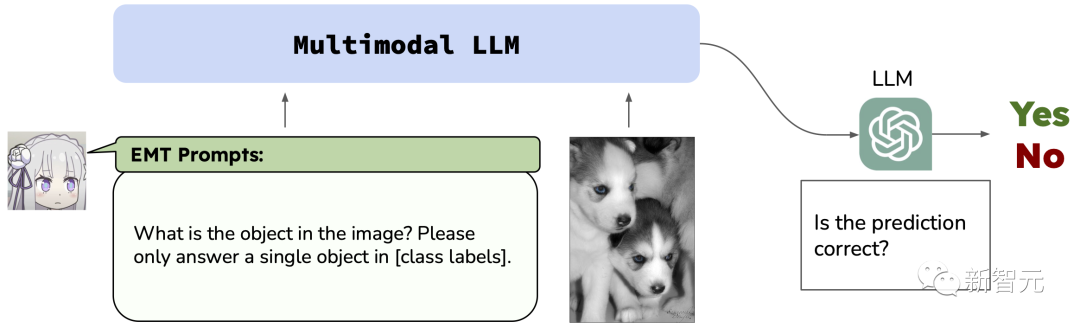
MLLM的EMT评估流程如下:
通过 (1) 提示每个MLLM作为图像分类器输入来自分类任务的图像;(2) 要求MLLM明确回答分类任务中的单个标签。并使用另一个LLM评估每个输出的正确性。
马毅教授对这项研究也做了推荐,在一些新任务上通过微调得到的性能提升,是以以前能力大幅下降为代价。

一起来看看究竟怎么回事?
微调后,大模型忘性更严重了
GPT-4之后,一系列多模态大语言模型(MLLM)的研究喷涌而出。
业界常用的做法是将预训练的视觉编码器与开源LLM集成,以及对生成视觉语言模型进行指令调优。
虽然许多经过微调的MLLM在通用视觉语言理解方面,展现出卓越的能力,但这些模型仍然遭受灾难性遗忘。
也就是说,模型往往会过度拟合微调数据集,从而导致预训练任务的性能下降。
图像分类中的灾难性遗忘,已在CV和ML领域中有着广泛的研究。
然而,MLLM的最新发展主要集中在,创建用于视觉问答多模态聊天机器人,而没有评估其基本图像分类能力,更不用说探索MLLM中的灾难性遗忘了。
话虽如此,先前的MLLM评估框架主要侧重于评估「认知推理能力」或「幻觉」,而忽略了研究如何在MLLM中灾难性遗忘的必要性。
总而言之,最新研究做出了2个关键贡献:
- 提出了EMT,一个专门设计用于评估MLLM中灾难性遗忘现象的评估框架。
据研究人员所知,它是第一个通过分类研究MLLM灾难性遗忘的评估框架。通过EMT,研究团队发现几乎所有测试的模型都无法保留其视觉编码器的分类性能。
- 对LLaVA进行了微调实验。
实验结果表明,适度的微调对于非微调任务是有利的,但过度的微调最终会导致这些任务中的灾难性遗忘。
EMT:评估开源多模态大模型
具体来讲,EMT的工作原理如下:
(1) 首先输入来自分类任务的图像;
(2) 然后,根据每个数据集,要求测试MLLM对输入图像进行分类,并通过提供的提示收集其输出;
(3) 接下来,由于MLLM的输出可能不遵循特定格式,因此研究人员用GPT-3.5来评估分类精度;
(4) 最后,输出测试MLLM在不同数据集上的预测精度
开源MLLM灾难性遗忘
研究人员首先用EMT来评估四个模型:LLaVA、Otter、LENS和InstructBLIP。
它们在MNIST、CIFAR10、CIFAR100和miniImageNet上的分类准确率介绍如下。研究团队按基本ViTCLIP模型对所展示的径向图进行了区分。
尽管大多数测试的MLLM无法获得与其基础视觉编码器相似的性能,但仍有几处值得注意:
- InstructBLIP-7b是唯一的例外,其性能优于视觉编码器
- 在所有测试模型中,LENS的整体分类性能最差
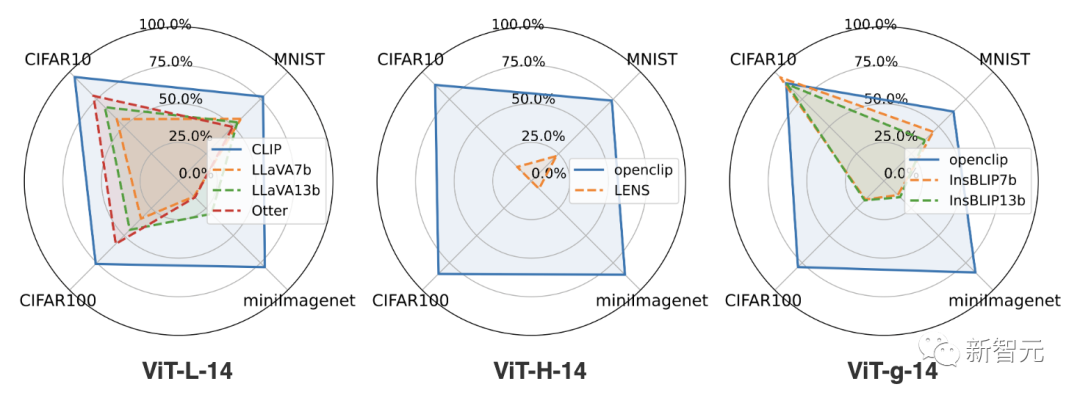
不同MLLM在MNIST、CIFAR-10、CIFAR-100和miniImagenet上的EMT评估精度
检验预测结果
研究人员对不同模型在不同数据集上的输出结果进行了分析,并找出了影响分类准确性的三大因素:

- 错误预测:与其他分类任务一样,MLLM有时也会做出错误的预测。
在如下示例中,LLaVA-7B在MNIST分类中错误地将0看做成8。

- 内在幻觉:经过测试的MLLM有时会生成看似相关,但不正确或无法验证的内容,简之,生成的输出与源内容直接矛盾。
其中一个例子是,要求LENS对CIFAR-10进行分类。
值得注意的是,EMT提示明确指示,测试MLLM仅识别所有类标签中的单个对象。
尽管有这些明确的说明,LENS仍然会产生本质上幻觉的输出——飞机、汽车、鸟、猫、鹿、狗、青蛙、马,一个包含多个标签的答案。

- 外在幻觉:输出与原始源内容没有可验证的联系。
如下示例中,虽然生成的输出文本部分包含标签「观赏鱼」,但它还显示了附加描述符,这些描述符不仅难以验证,而且与提示概述的原始请求无关。

微调LLaVA
接下来,研究人员使用EMT来评估LLaVA微调过程中的精度变化。
在此,他们使用LLaVA-7b和LLaVA-13b作为基础MLLM进行微调,并且分别在MNIST、CIFAR-10、CIFAR-100和 miniImagenet上进行微调实验。
具体方法是微调(1)线性适配器层(表示为线性);(2)线性适配器层和使用Lora的LLM(表示为lora)。
下图展示了3个epoch微调结果。虽然LLaVA的性能确实在微调数据集上有所提高,但图中揭示了MLLM微调的一个关键问题:
在一个数据集上微调MLLM会降低另一非微调数据集上的性能。
这种现象虽然并不出人意料,但却值得注意。由于该模型除了经过微调的数据集之外没有接触过其他数据集,因此理所当然会观察到与灾难性遗忘类似的影响。
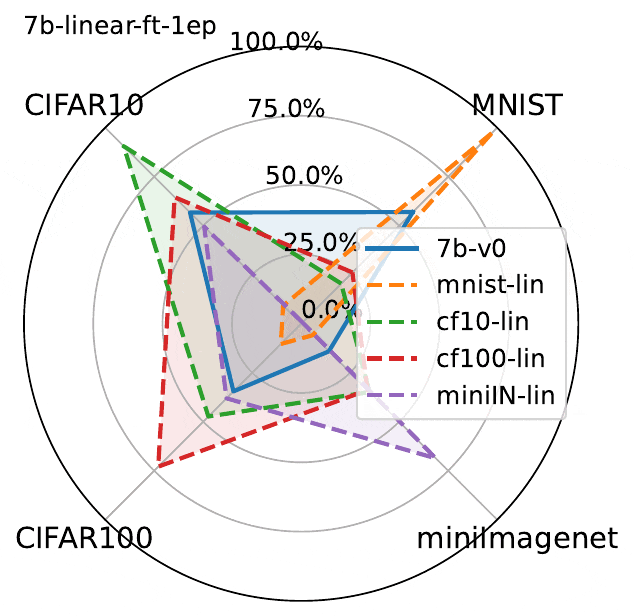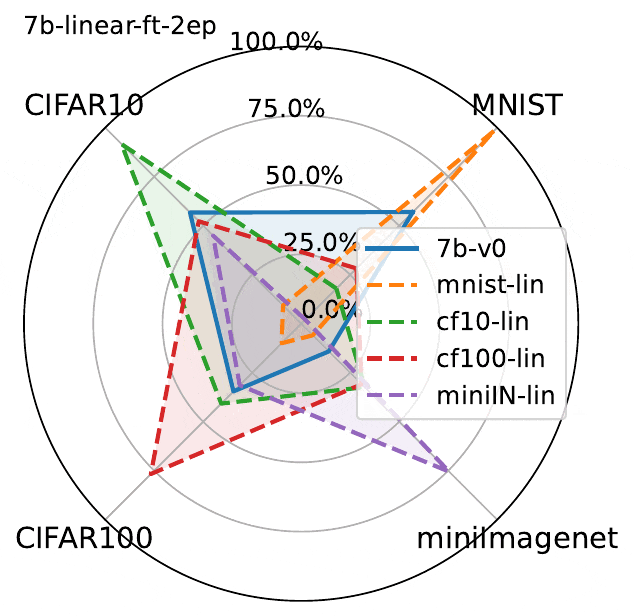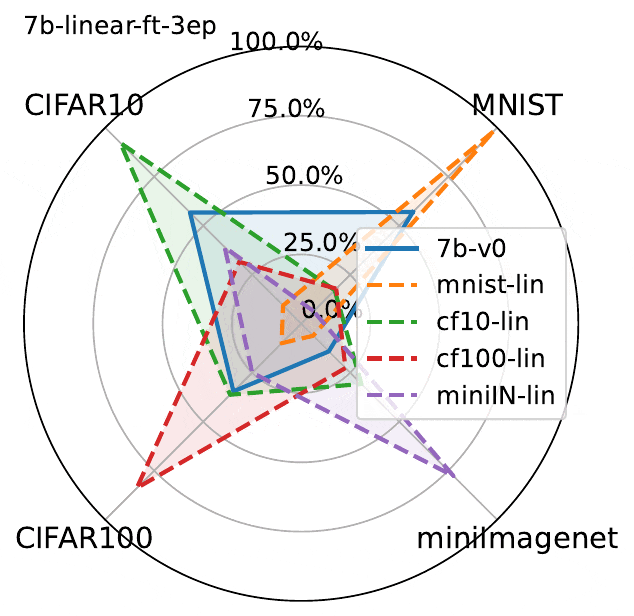
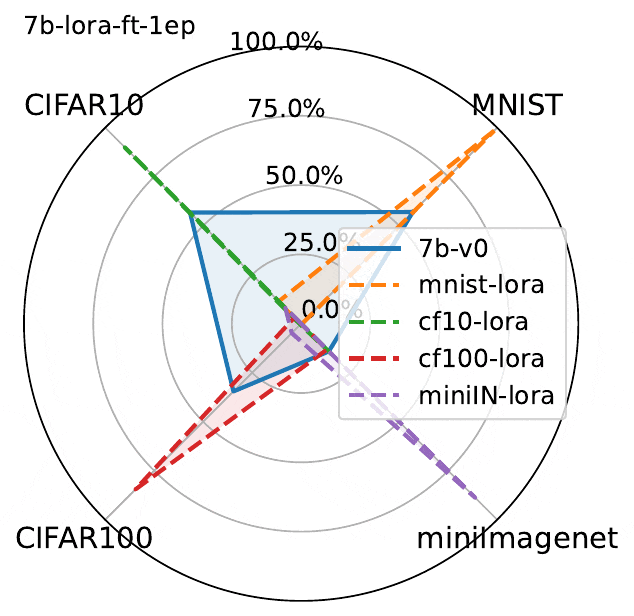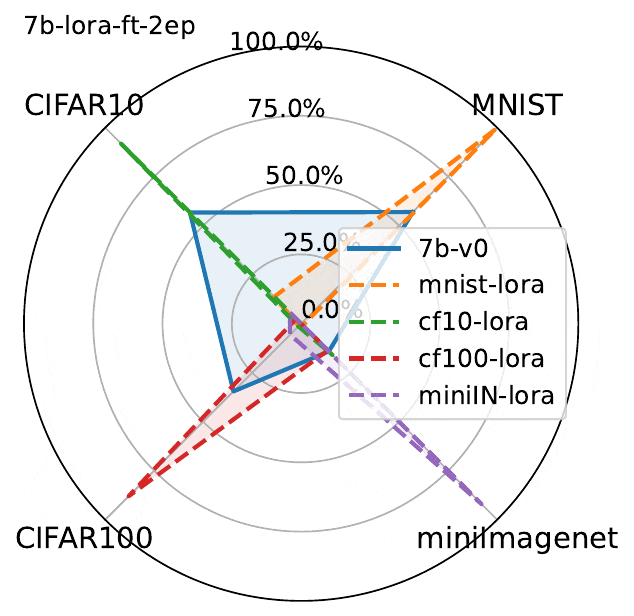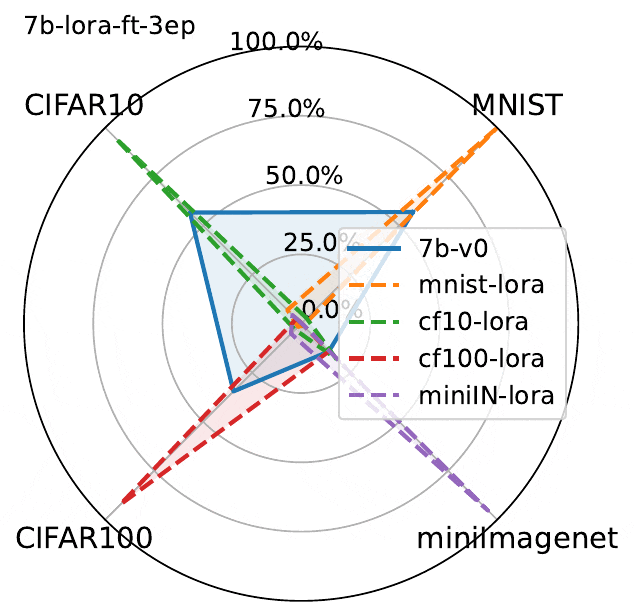
经过微调实验表明:
- 在一个数据集上进行微调会导致其他数据集上的灾难性遗忘,这种现象在线性微调和Lora微调中都会发生
- Lora微调比线性微调导致更多遗忘
接下来,研究人员将通过提供精确度曲线,来更详细地研究微调过程。
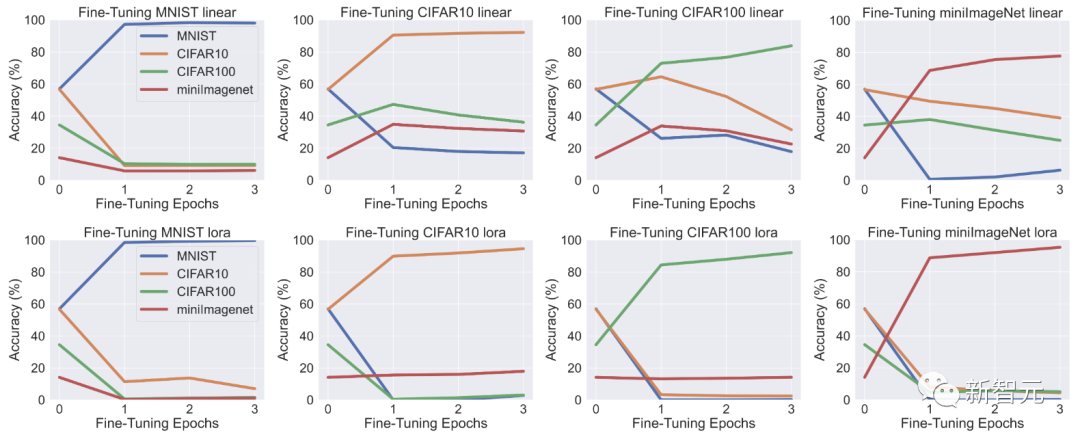
从分类曲线中可以看出:
- 线性微调具有普适性,因为使用RGB数据集(CIFAR10、CIFAR100、miniImageNet)进行线性微调也能在第一个epoch提高其他RGB数据集的准确率
- Lora微调不具备线性微调的通用性
检验预测结果
当研究人员检查微调LLaVA的输出时发现:
它会输出与其微调数据集相关的文本,同时忽略与其原始提示相关的问题,从而产生幻觉。
为了进一步说明这一现象,研究团队提供了对LLaVA-7b和LLaVA-13b进行分类的明确示例,这些示例已使用EMT提示在不同数据集上进行了微调。

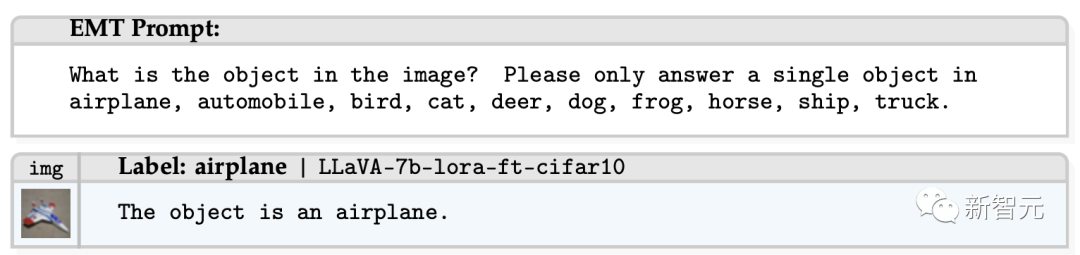
如下的演示说明,当CIFAR-10微调模型在CIFAR10上进行测试时,LLaVA确实能成功识别物体。
然而,在其他数据集上进行微调后,LLaVA模型在CIFAR-10分类中开始出现幻觉。
在这个例子中,通过MNIST微调模型对CIFAR-10进行分类时,模型不仅部分生成了关键词「飞机」,而且同时产生了数字「8」的幻觉输出。

另外,研究人员在CIFAR-100和miniImagenet微调模型中也观察到了类似的现象。
具体来说,这些微调模型开始产生幻觉,将「飞机」预测为与「飞机」相似或相关的类别,如CIFAR-100模型中的「蝴蝶」和miniImagenet模型中的「航空母舰」。
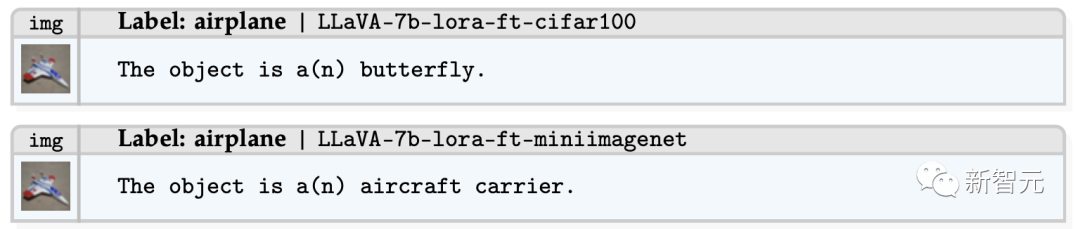
上述例子表明:
- 微调MLLM确实提高了微调数据集的分类性能
- 微调MLLM在其他数据集上会导致灾难性遗忘,因为微调MLLM会记忆微调数据集,从而产生幻觉文本
作者介绍
Yuexiang Zhai

Yuexiang Zhai是加州大学伯克利分校的博士生,由马毅教授和Sergey Levine教授指导。
Shengbang Tong(童晟邦)

Xiao Li

Mu Cai

Qing Qu

Yi Ma

https://yx-s-z.github.io/emt/

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢