
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
神经网络的不可解释性,一直是AI领域的“老大难”问题。
但现在,我们似乎取得了一丝进展——
ChatGPT最强竞对Claude背后的公司Anthropic,利用字典学习成功将大约500个神经元分解成了约4000个可解释特征。

具体而言,神经元具有不可解释性,但经过这一分解,Anthropic发现每一个特征都代表了不同的含义,比如有的分管DNA序列,有的则表示HTTP请求、法律文本等等,也就是具备了可解释性。
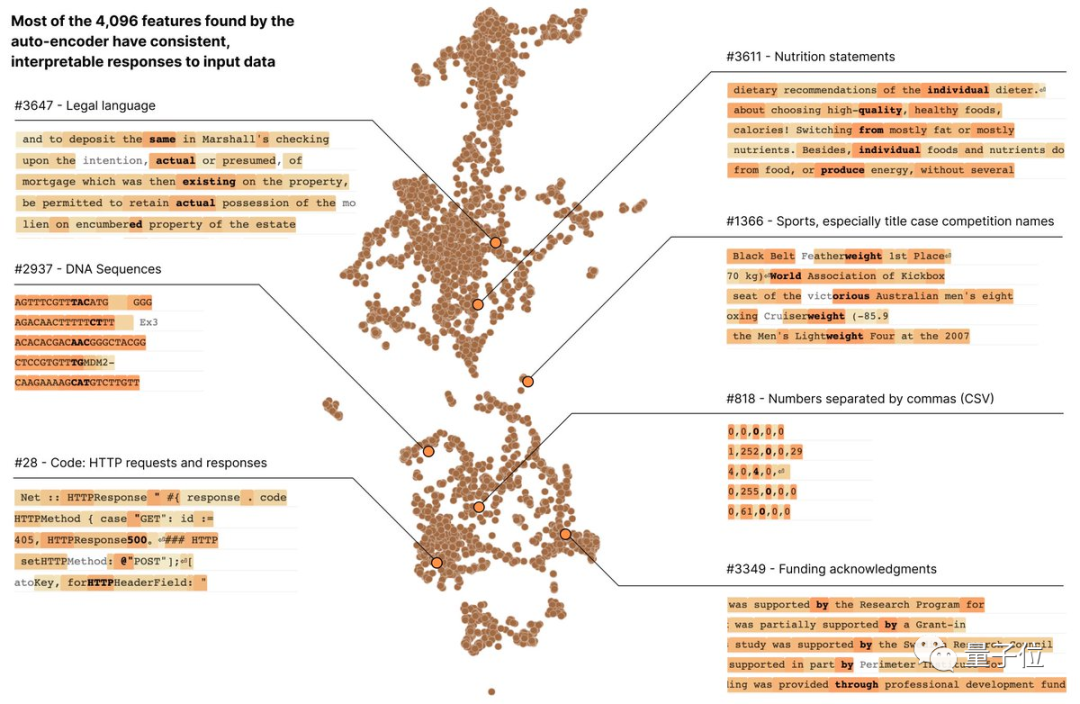
而通过人为地刺激其中任一特征,就能引导模型给出我们预期之内的输出。
比如开启DNA特征就能使模型输出DNA,开启阿拉伯文字特征就让模型输出阿拉伯文字。
Anthropic激动地表示:
他们这一方法很可能克服AI不可解释性这一巨大障碍。
而一旦我们能够了解语言模型的工作原理,就能很容易地判断一个模型是否安全,从而决定它是否应该被社会和企业所采用。

具体来看。
用字典学习分解语言模型
首先,光针对语言模型来说,它的不可解释性主要体现在网络中的大多数神经元都是“多语义的”。
即它们可以对多个不相关的事物进行响应。
例如,一个小型语言模型中的某个神经元会同时对学术引文、英语对话、HTTP请求、韩语文字等不同内容表现出强烈的激活状态。

而这会阻碍我们了解神经网络每一小部分的具体功能和交互过程,从而无法对整个网络的行为进行推断。
那么,是什么原因造成了多语义性这一特征?
早在去年,Anthropic就推测其中一个潜在的因素是“叠加”(superposition)。
这指的是模型将许多不相关的概念全部压缩到一个少量神经元中的操作。

同时,Anthropic也指出,字典学习——就是提取事物最本质的特征,最终让我们像查字典一样获取新知识,是解决这一问题的办法。
在此之前,他们已提出了一个叠加玩具模型,并证明:
如果一个对模型有用的特征集在训练数据中是稀疏的,那么该神经网络在训练过程中可以自然地产生叠加。
基于该玩具模型,他们提出了三种策略来找到一组稀疏且可解释的特征:一是创建没有叠加的模型,然后通过鼓励激活稀疏性;
二是使用字典学习在表现出叠加的模型中找到超完备的特征基础;
三是将前两种方法混合使用。
经过实验证明,方法一不足以杜绝多语义性,方法二则存在严重的过拟合问题。
于是在此,团队又采用了一种称为稀疏自动编码器的弱字典学习算法。
它能够从经过训练的模型生成学习特征,提供比模型神经元本身更单一语义的分析单元。
总的来说,该算法建立在大量先前的成果之上,尤其是在神经网络激活上使用字典学习的相关方法,以及解耦(disentanglement)相关的内容。
最终所得编码器在从叠加中提取可解释性特征方面取得了“令人信服的成功”。
具体来说,Anthropic采用一个具有512个神经元的MLP单层transformer,通过在具有80亿个数据点的MLP激活上训练稀疏自动编码器,最终将MLP激活分解为相对可解释的特征,扩展因子范围可以从1x(512个特征)增长到256x(131072个特征)。
Anthropic团队将他们得到的可解释性分析全部集中在一个称为A/1的运行中,共包含4096个特征,每个特征都注明了含义,它们可以按照预期被人工激活。
下面是它们的可视化图表:
集成长篇报告发布,7个关键结论
现在,Anthropic将以上全部成果以报告的形式发布。
报告题目为《迈向单义性:通过字典学习分解语言模型》(Towards Monosemanticity: Decomposing Language Models With Dictionary Learning)。
篇幅非常长,共分为四部分,分别为:
问题设置,阐述研究动机,以及他们训练的transformer和稀疏自动编码器。
特征详细调查,即“存在性证明”,证明他们发现的特征确实是功能上特定的因果单元。
全局分析,表明所得特征是可解释的,并且它们能够解释MLP层的重要部分。
现象分析,描述特征的几个属性,包括特征分割性、普遍性等,以及它们如何形成一个有趣的、类似“有限状态自动机”的系统。
总的来看,关键结论一共有7个:
1、我们能够用稀疏自动编码器提取相对单一语义的特征,但大多数学习到的特征都是相对可解释的。
2、稀疏自动编码器产生可解释的特征,在神经元基础中基本是不可见的。
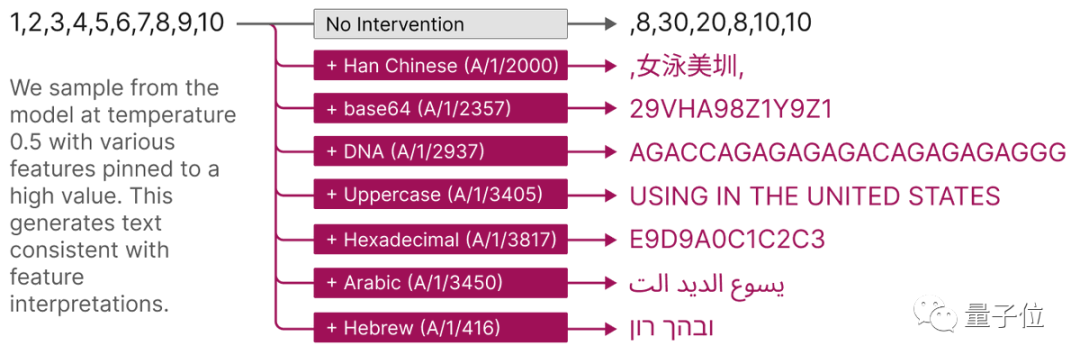
3、稀疏自动编码器功能可用于干预和引导transformer的生成。
例如,激活Base64特征会导致模型生成Base64文本,激活阿拉伯文字特征会生成阿拉伯文本。
4、稀疏自动编码器产生相对通用的特征。特征彼此之间的相似性比它们与自己模型神经元之间的相似度更高(对应“普遍性”一节)。
5、当我们增加自动编码器的大小时,特征似乎会“分裂”。比如一个小型字典中的Base64特征在较大的字典中会分成三个,每个都具有更微妙但仍可解释的含义(对应“特征分割性”一节)。
6、仅512个神经元就可以代表数万个特征。
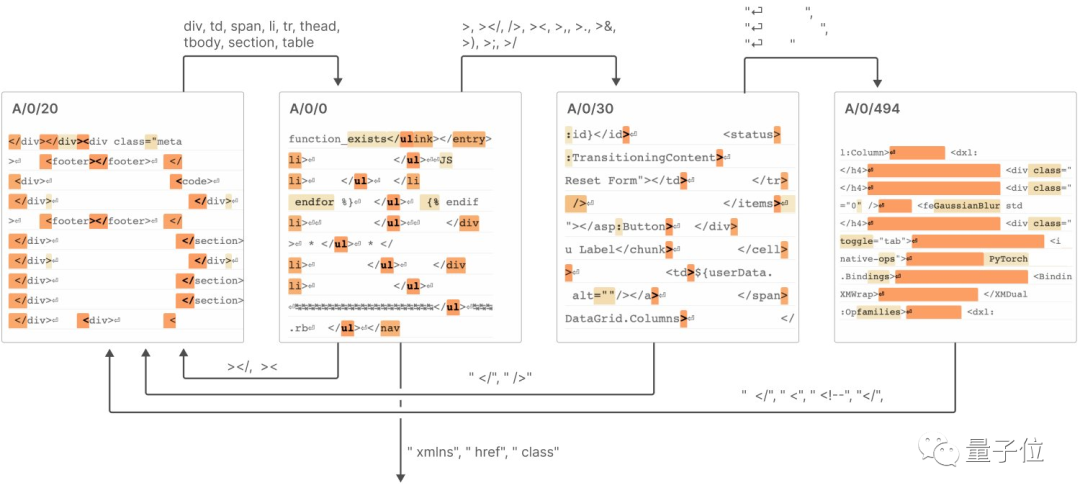
7、特征可以在类似“有限状态自动机”的系统中实现连接,从而完成复杂的行为(比如生成HTML功能)。
One More Thing
在评论区,有网友评价:
神经元就像一个神秘的盒子,Anthropic这项工作就相当于研究如何偷看盒子中的内容。
显然,这项工作还只是一个开头——
Anthropic同时还在加紧招聘可解释性相关的研究员和工程师。

点开来看,薪资在25万美元(约180万元)-52万美元之间,研究内容跟如上报告息息相关。
报告链接:
https://transformer-circuits.pub/2023/monosemantic-features/index.html
参考链接:
https://twitter.com/anthropicai/status/1709986949711200722
— 完 —
「量子位2023人工智能年度评选」开始啦!
今年,量子位2023人工智能年度评选从企业、人物、产品/解决方案三大维度设立了5类奖项!欢迎扫码报名
MEET 2024大会已启动!点此了解详情。

点这里👇关注我,记得标星哦~

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢