
今天为大家介绍的是发表在IJCAI
2023上的一篇Transformer架构下考虑多角度关系的图表示学习模型的会议论文。本文提出一种新的注意力机制Graph
Propagation Attention(GPA)用于建模点到点、点到边和边到点之间的关系;并在此基础上提出一个有效的Transformer架构Graph Propagation Transformer
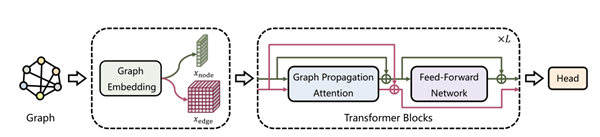
(GPTrans)以进一步学习图数据特征。模型整体分为Graph
Embedding、Graph
Propogation和FFN三个模块。

1 介绍
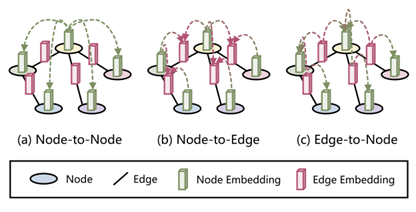
尽管transformer-based模型的图表示学习方面表现良好,但他们仍然存在以下问题:(1)没有显式的利用图数据中节点与边的关系。(2)dual-FFN结构在transformer模块中效率低下。为了克服上述问题,本文提出一种基于transformer架构的图表示学习模型GPTrans,其中关键组件是它的GPA模块。如图1所示,GPA模块通过对节点到节点、节点到边和边到节点三种连接进行建模,在前一层的节点嵌入和边嵌入之间进行信息传播。这种设计使不再需要dual-FFN模块,因此提高了效率。
2 模型
2.1
Graph Embedding
以单个图作为输入,首先给图增加一个虚拟节点来表征图级特征信息;其次,对于节点嵌入,将节点属性和节点度(入度和出度)的统计量三方面的信息相加得到节点嵌入;以有向图为例,可表示为如下公式:
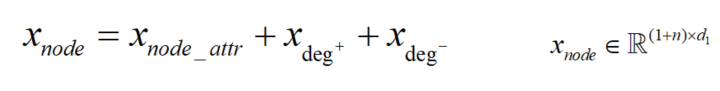
对于边的嵌入,Transformer的优势是它的全体接受域,但带来的问题就是模型必须显式的编码位置信息或位置的相互依赖性。对于图而言节点不是顺序排列的,为了编码图的空间信息,使用节点间的最短路径(SPD)的距离作为位置信息与边特征融合,如果两节点之间不可达则设置一个特殊值-1。
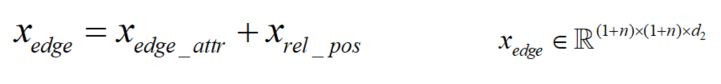
2.2
Graph Propagation Attention
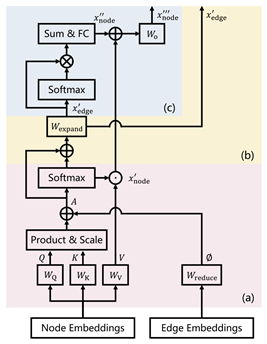
使用全局的自注意力来建模点到点的信息传递使用参数矩阵WQ、WK和WV将节点嵌入xnode投影到查询、键和值上:
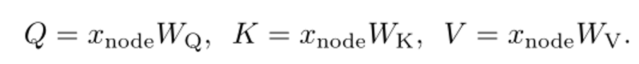
通过一个可学习矩阵将Edge Embedding映射为注意力偏执,与经典Transformer结构中的position encoding类似,这里将边嵌入中的节点相对位置编码映射为偏执通过影响注意力系数的方式来控制对各节点特征的聚合。注意力偏执公式如下:

然后,将ϕ添加到Product&Scale的注意力映射中,并计算出节点嵌入x'。由于ϕ是通过可学习矩阵从高维边缘嵌入投影出来的,因此注意图将具有更灵活的模式来聚合节点特征
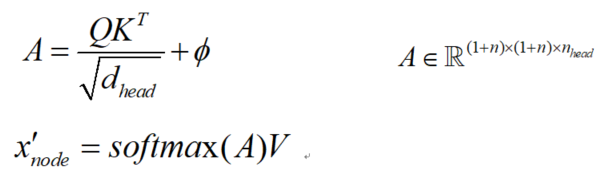
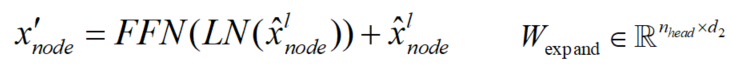
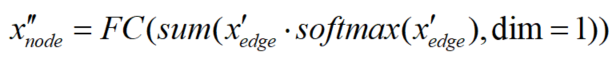
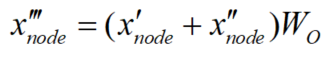
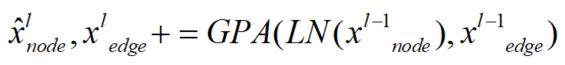
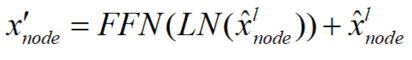
3 实验
3.1
baseline
数据集为PCQM4M、 PCQM4Mv2、MolHIV、MolPCBA、ZINC,并设置5种参数规模。首先在OGB大规模的两个数据集PCQM4M和PCQM4Mv2上将GPTrans与基于Transformer和非Transformer的方法进行对比,如表1所示;评价指标为平均绝对误差(MAE)。
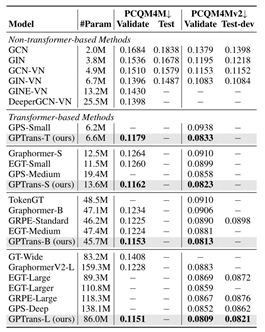
进一步以PCQM4Mv2预训练的权值作为初始化,在OGB分子数据集MolPCBA和MolHIV上对模型进行微调,验证GPTrans的迁移学习能力。所有实验用不同的随机种子进行了五次,取结果的平均值和标准差,如表2,3所示。在ZINC子集上进行从头训练,如表4所示,与基线对比得到一个非常好的MAE结果。上述结果均表明GPTrans在图级任务上表现良好。
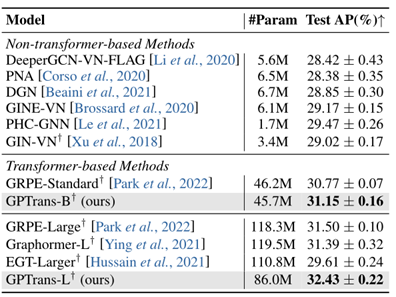
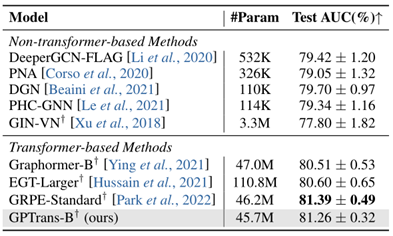
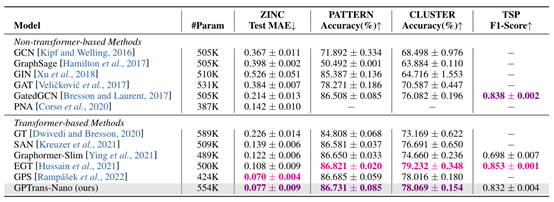
由表4可以看出GPTrans-Nano在PATTERN和CLUSTER数据集上的准确率分别为86.731±0.085%和78.069±0.154%。这些结果在很大程度上优于许多卷积/消息传递图神经网络,表明所提出的GPTrans可以作为传统GCNs的替代方案,用于节点级任务。在边分类的性能上,GPTrans在很大程度上优于Graphormer并与EGT相当,表明模型在边级任务上也具有很大竞争力。
3.2 消融实验
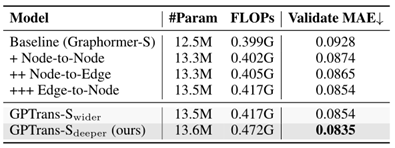
FLOPs是用一个有20个节点的图来计算的。作者在graphormer-s的基础上构建了100
epoch的baseline,并通过逐步引入GPA模块将其在PCQM4Mv2数据集上的验证MAE从0.0928降低到0.0854。此外,作者发现在参数数量相似的情况下,更深的模型优于更宽的模型。
4 总结
本文利用GPTrans进行图表示学习,通过在Transformer-block中构建自注意力机制,探索图中节点和边之间的消息传递。特别是在GPTrans中,作者提出了一种Graph Propagation Attention (GPA)机制,以节点到节点、节点到边和边到节点三种方式显式地在节点和边之间进行消息传递,提高了图结构数据在Transfomer架构下的表征能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢