


导读 目前整个大数据行业有很多宏大的思路和先进的架构,在百度商业数据产品是如何实现和落地的呢?本文将为您揭秘面向百度商业数据产品的全流程DataOps实践。
分享嘉宾|叶玮彬 百度 资深研发工程师
出品社区|DataFun
大规模数据报表生产的挑战与诉求
首先和大家分享百度商业数据产品及其对数据平台的诉求。
1.百度商业数据产品矩阵介绍
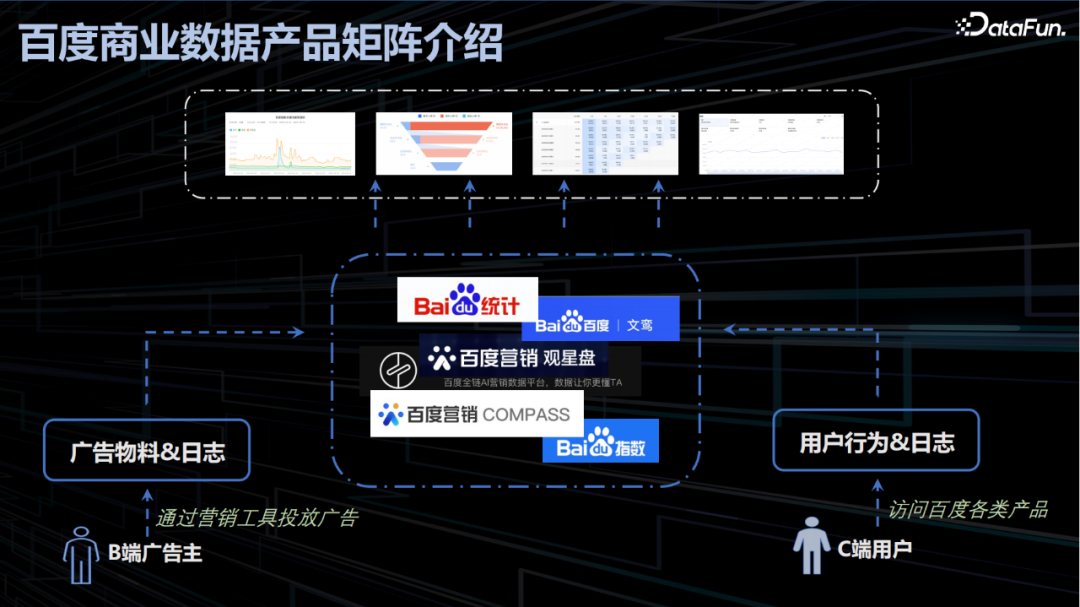
以上百度商业矩阵主要体现其核心商业产品和数据形式:
百度核心商业数据产品,主要包括用于网站埋点统计和全流程托管分析的百度统计,反映词汇趋势热度及分析洞察的百度指数,支撑广告主追踪热点并完成投放决策的观星盘,以及其他面向产品、销售、运营等人员的数据产品;
成体系化的数据流转,一是 B 端广告主投放广告的物料数据和投放行为日志,二是 C 端用户访问、搜索及消费相关的行为日志。两端数据经过用商一体的加工分析流转到各个数据产品后以丰富多样的形式呈现。
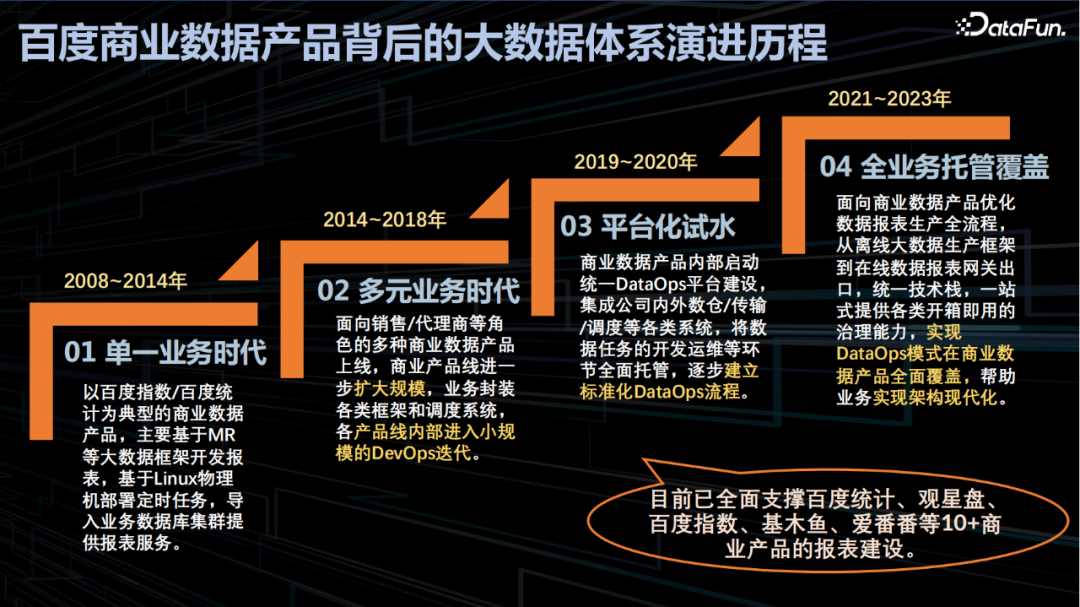
2.百度商业数据产品背后的大数据体系演进历史
3. 大规模报表生产背后的数据挑战
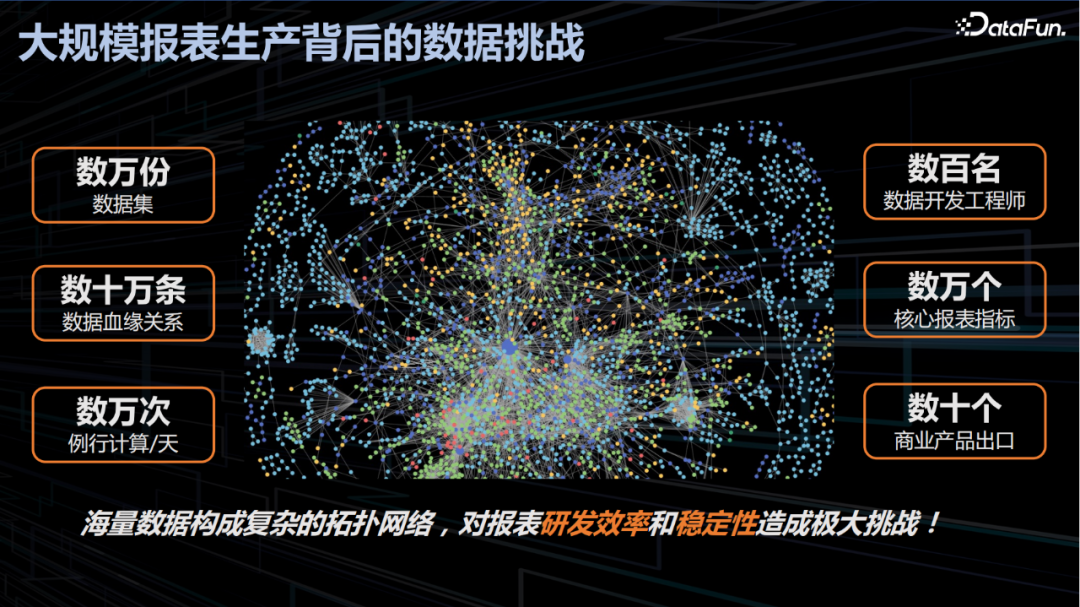
经过分析总结,百度商业数据产品在集团内部主要面临以下三类挑战:
海量数据:百度具有数万份的数据集、数十万条数据血缘关系、每天数万次例行计算,海量数据形成复杂的拓扑网络在管理上带来挑战,一体化的数据平台统一纳管便于数据及血缘的查找和追踪。
数百名数据开发工程师:开发丰富的数据产品需要大量的高成本数据开发工程师,企业会产生高昂的用人成本,便捷高效的辅助开发产品或平台能为生产提效,节省人力成本达到降本增效的目的。
数万个核心报表指标和数十个商业产品出口:大量的指标和出口产品一旦发生故障都需要能快速解决修复,清晰的血缘管理能高效辅助问题定位和排查分析,提高数据及产品的交付质量和用户满意度。
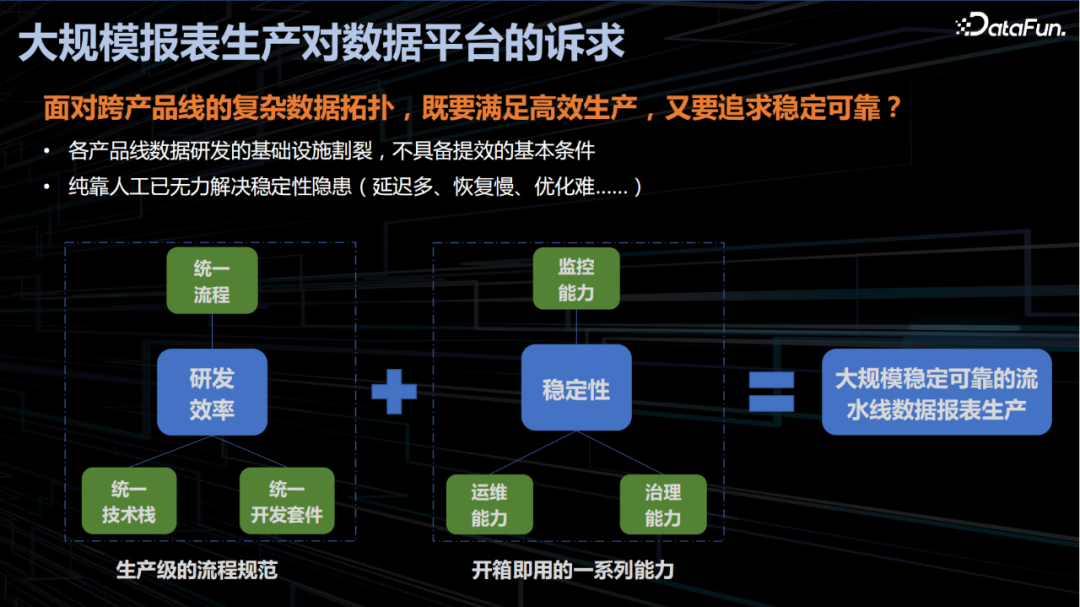
面对数据挑战,百度数据平台通过建设大规模稳定可靠的流水线数据报表生产链路,解决相关诉求,其核心建设思路和目标主要包括以下两点:
提升研发效率:通过统一流程、统一技术栈、统一研发套件形成生产级的流程规范,解决各个产品线数据源的基础设施割裂带来的效率问题和规范问题;
优化产出稳定性:通过建设监控能力、运维能力、治理能力等一系列开箱即用的套件,解决面对大规模数据和任务手工无法解决的延迟多、恢复慢、优化难等稳定性隐患。
下面,重点分享全流程 DataOps 的设计思考。
02
全流程 DataOps 的设计思考
1. 面向大规模数据报表生产的分层架构

一般来说,在做数据产品交付时,我们会采用分层设计的方式,百度的数据分层架构主要分为:原始数据层、数仓层、指标层、报表层,各层之间通过统一制品的技术中间件衔接。如果将数据生产类比为一般的工业生产,那么分层架构可以看作统一操作规范的生产流水线,统一制品的技术中间件可以看作统一标准规格的生产工具,两者结合保证了数据报表生产的质量和效率。
2. 如何选型
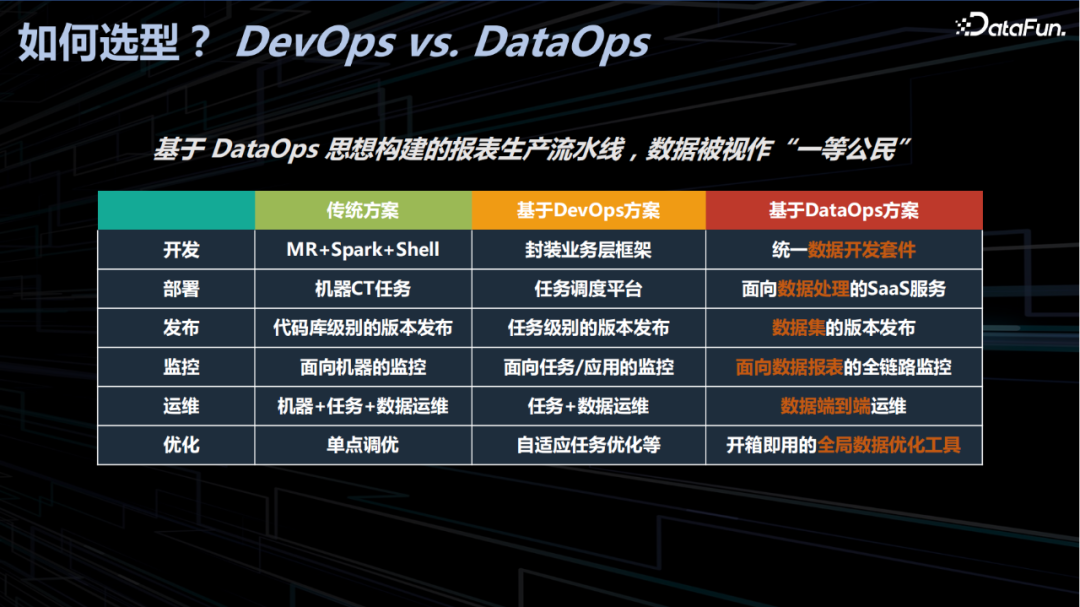
面向统一的分层架构,如何选型以实现流水线的生产和高效运维呢?不同于传统的完全割裂的开发运维方案,DevOps 通过任务调度平台和一些数据功能的拼凑实现统一业务框架,DataOPs 则以数据为视角,重塑全流程,实现数据生产流水线,因此DataOps理念更符合我们对统一平台的设想和预期。

DataOps 以数据为视角,不仅要实现数据研发流程托管,还需要考虑数据治理、任务监控与运维,保证数据生产的全流程在一个平台内完成,平台也贯穿数据和报表的全生命周期。
4. 面向大规模数据报表生产的 DataOps 流水
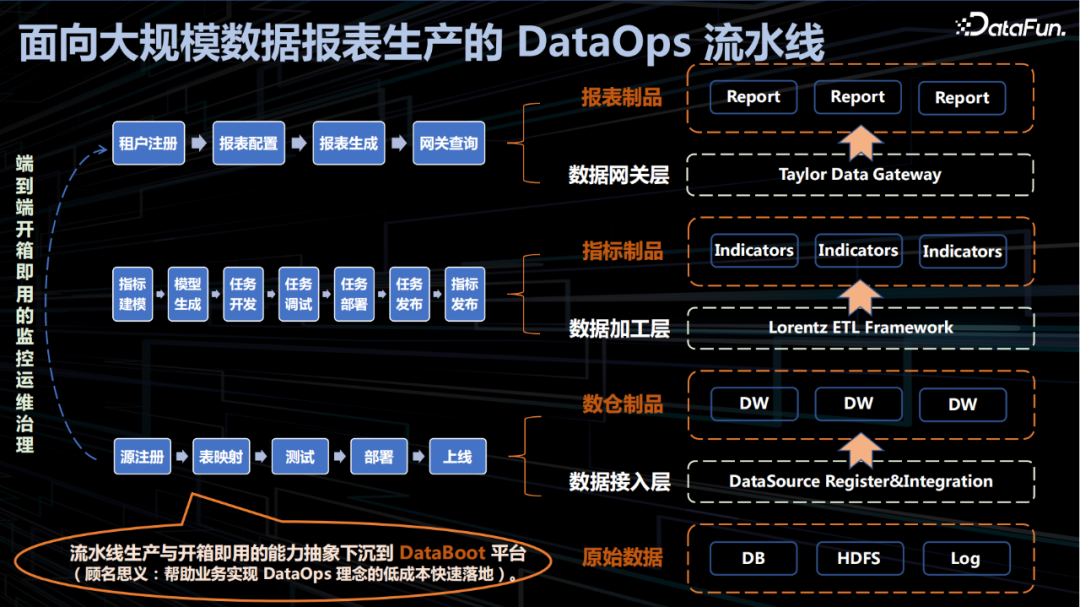
百度将流水线生产与开箱即用能力的 DataOps 理念落地到 DataBoot 平台,实现了数据端到端开箱即用的监控运维与治理能力,覆盖从数据的引入到使用过程数据接入层、加工层、网关层所有的处理套件与能力,见证了从原始数据到报表制品的转化。
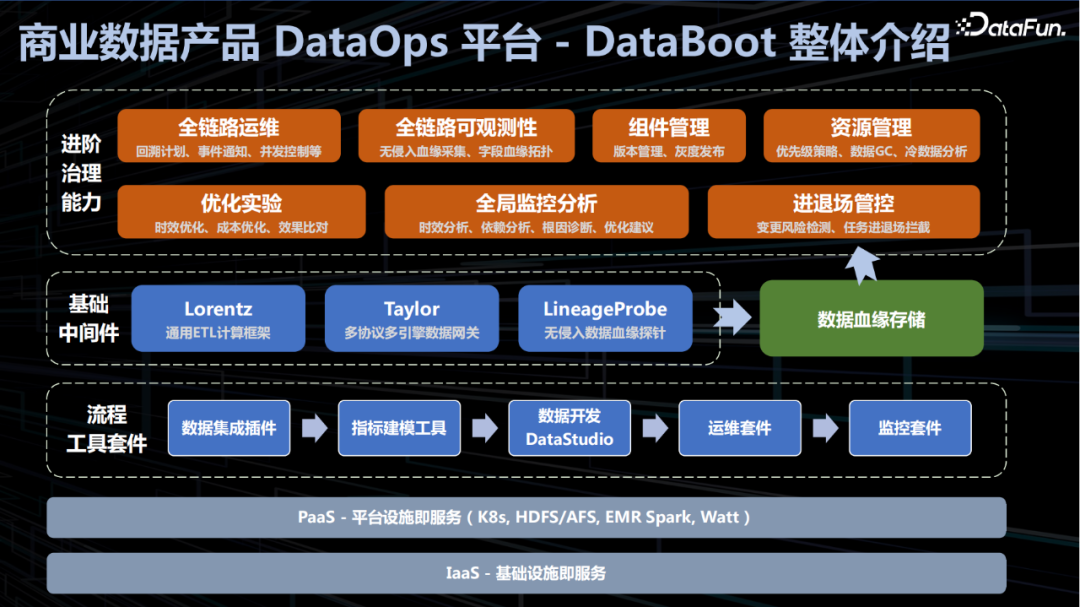
5. 商业数据产品 DataOps 平台- DataBoot 整体介绍
03
全流程 DataOps 平台化实践
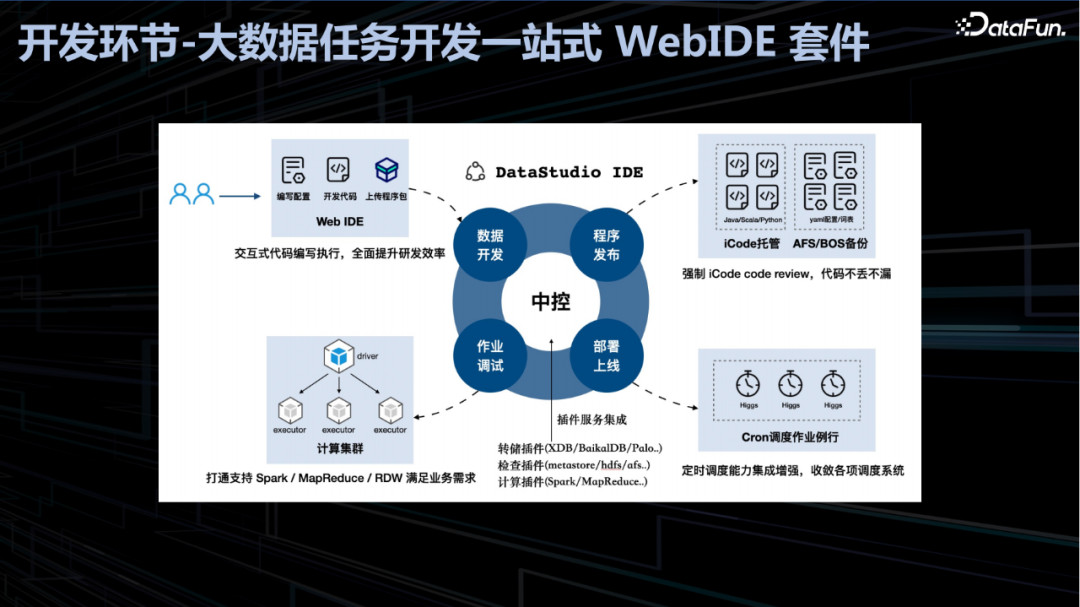
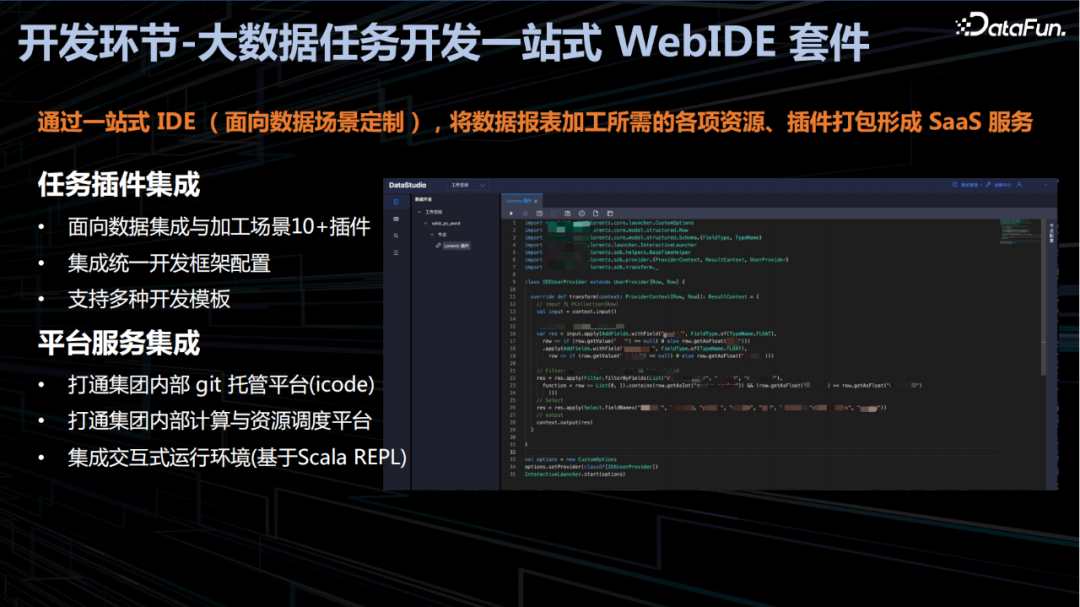
1. 开发环节-大数据任务开发一站式 WebIDE 套件
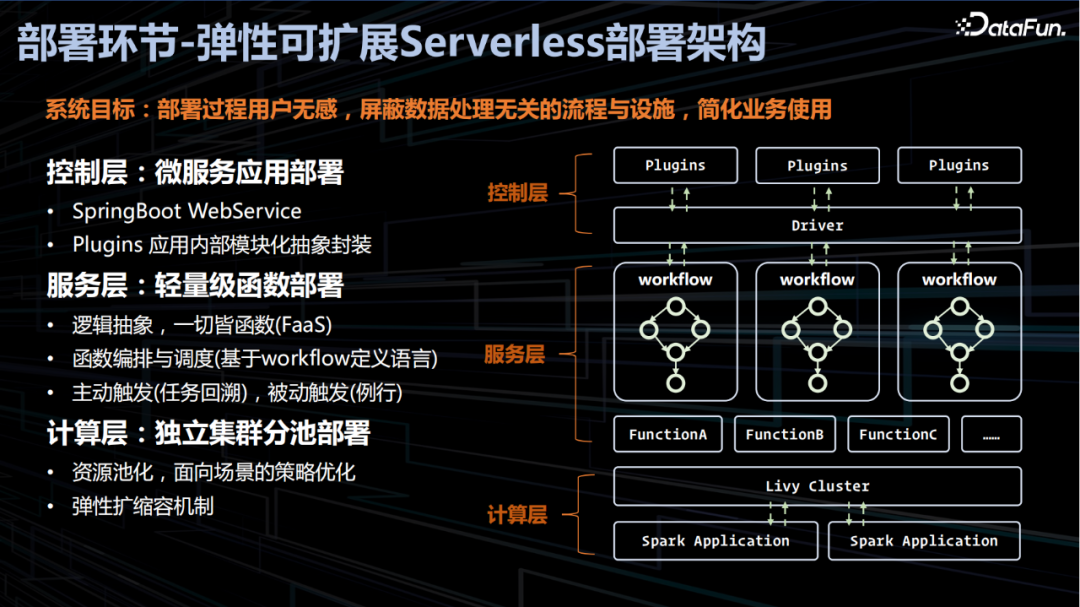
2. 部署环节
弹性可扩展 Serverless 部署架构
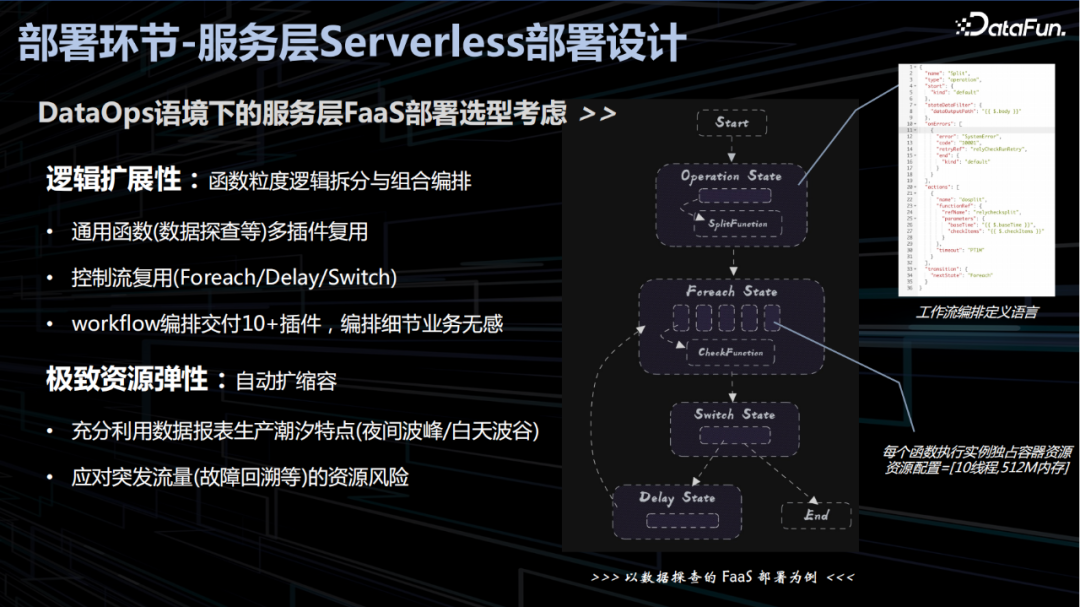
服务层 Serverless 部署设计
计算层 Serverless 部署设计
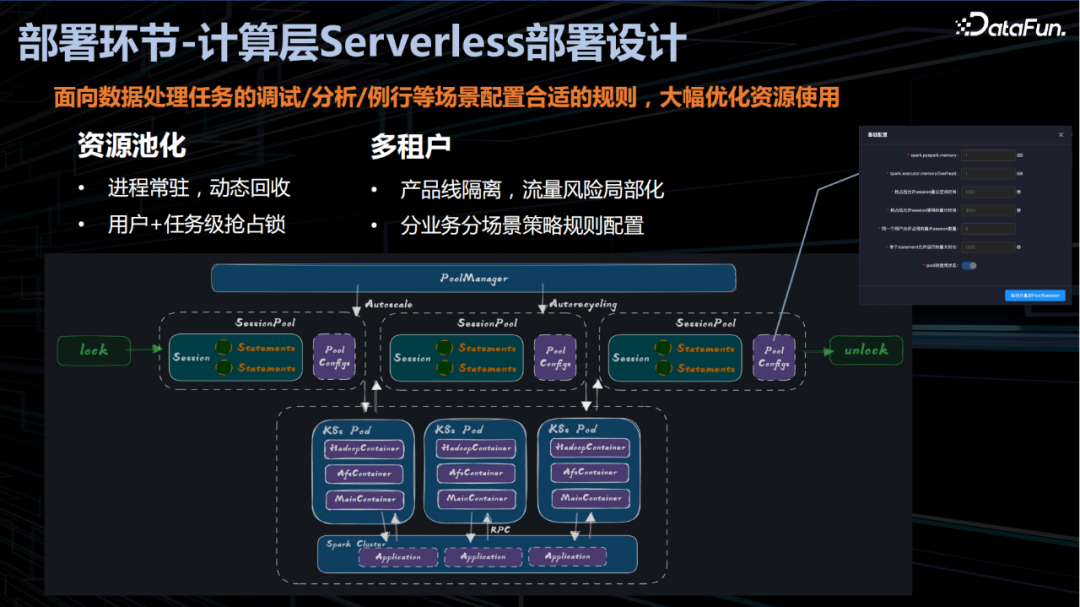
计算层支持资源池化和多租户。部署图中的 PoolManager 负责资源扩缩容和回收,类似 JVM GC 的功能。SessionPool 可以自动扩缩容,并且可配置化的实现不同的资源分配规则以达到任务的分级保障目的。底层的每个 K8s Pod 是一个计算实例,每个 Pod 有多个container,主 container 负责和 Spark 集群进行交互产生计算。
数据血缘探针织入式部署
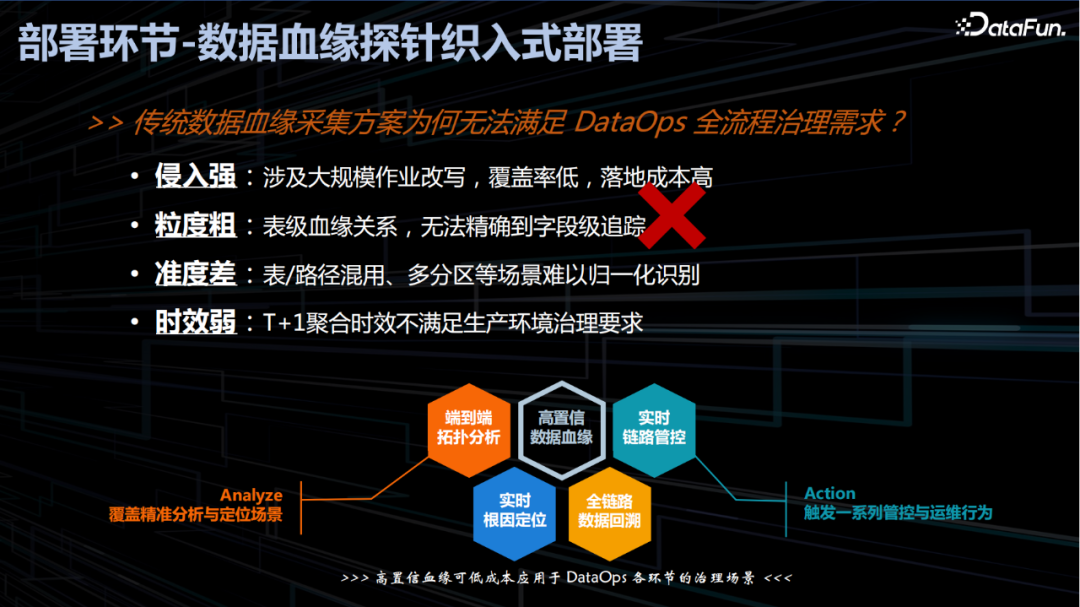
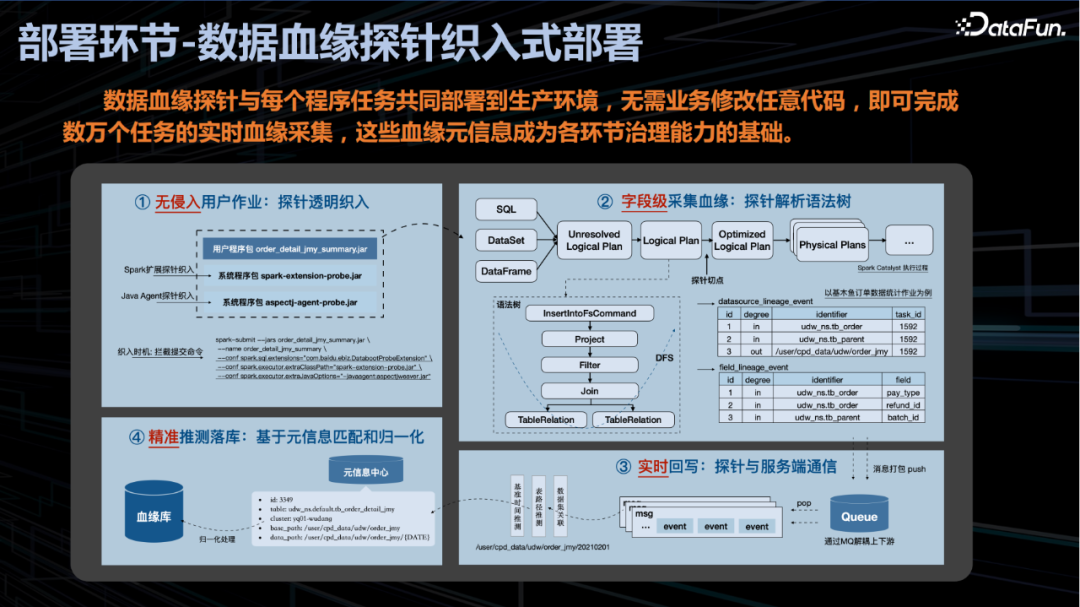
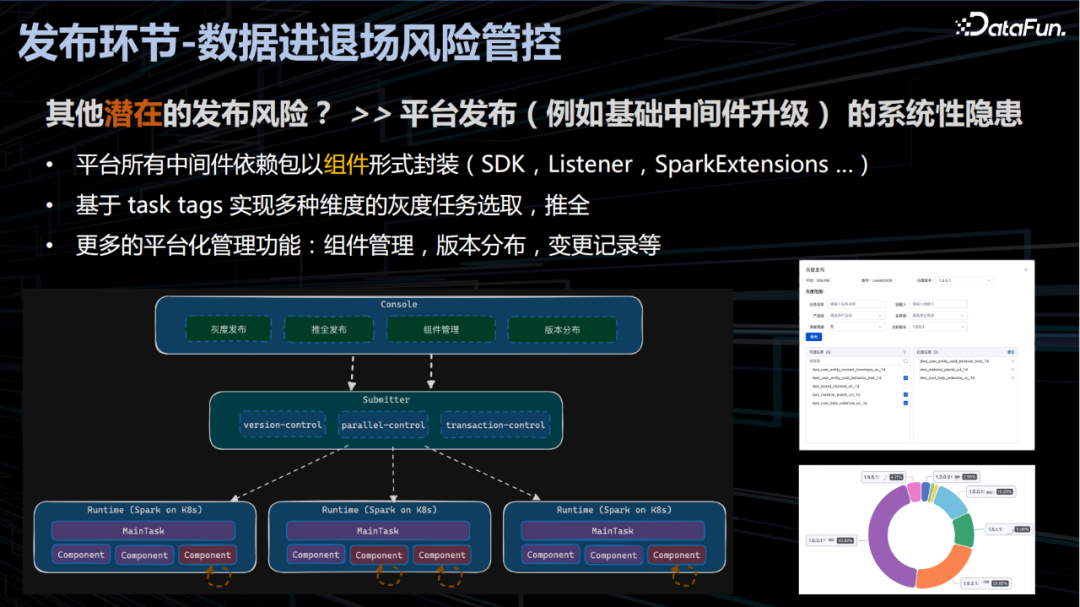
3. 发布环节-数据进退场风险管控
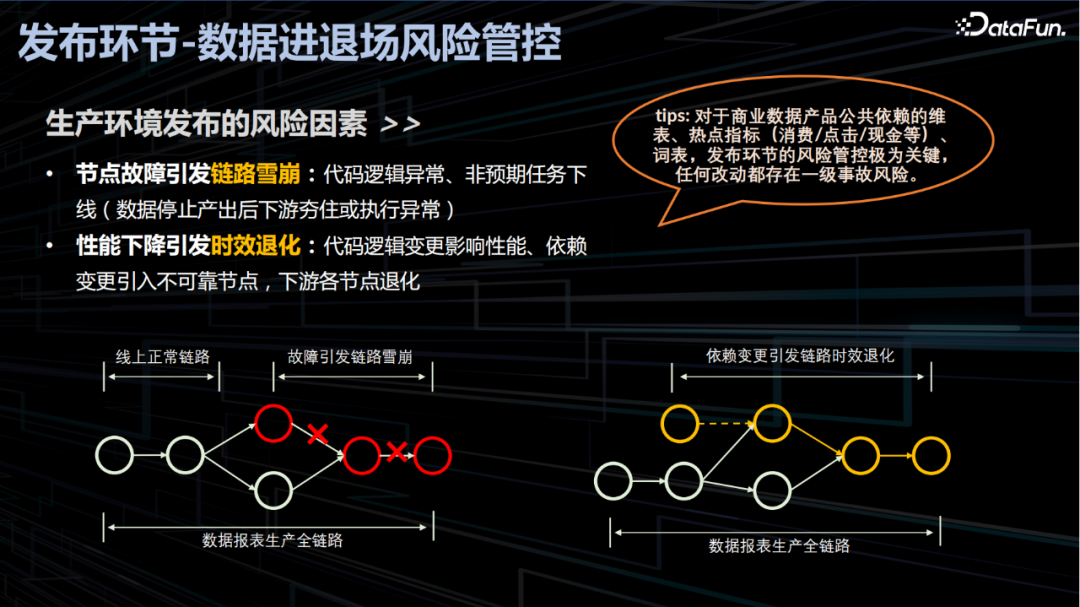
通常在数据发布到生产环境的过程中主要存在两种类型的问题造成严重生产事故。一是发布的代码逻辑存在问题造成发布节点及下游所有任务执行异常,引发全链路任务雪崩。二是发布的代码性能下降造成发布节点及下游节点数据产出延迟的连锁效应引发全链路时效性退化。
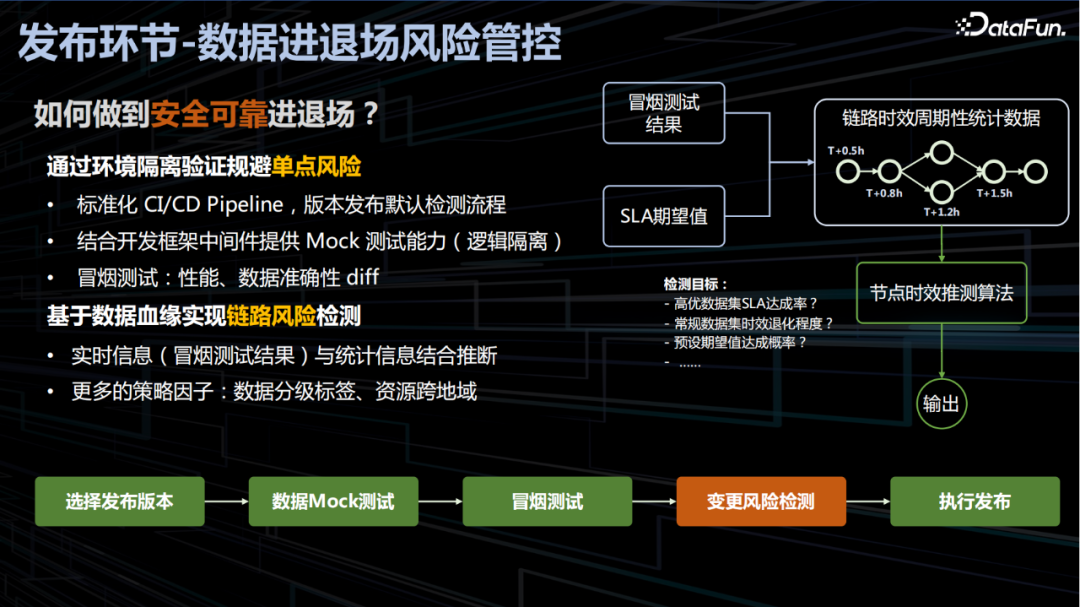
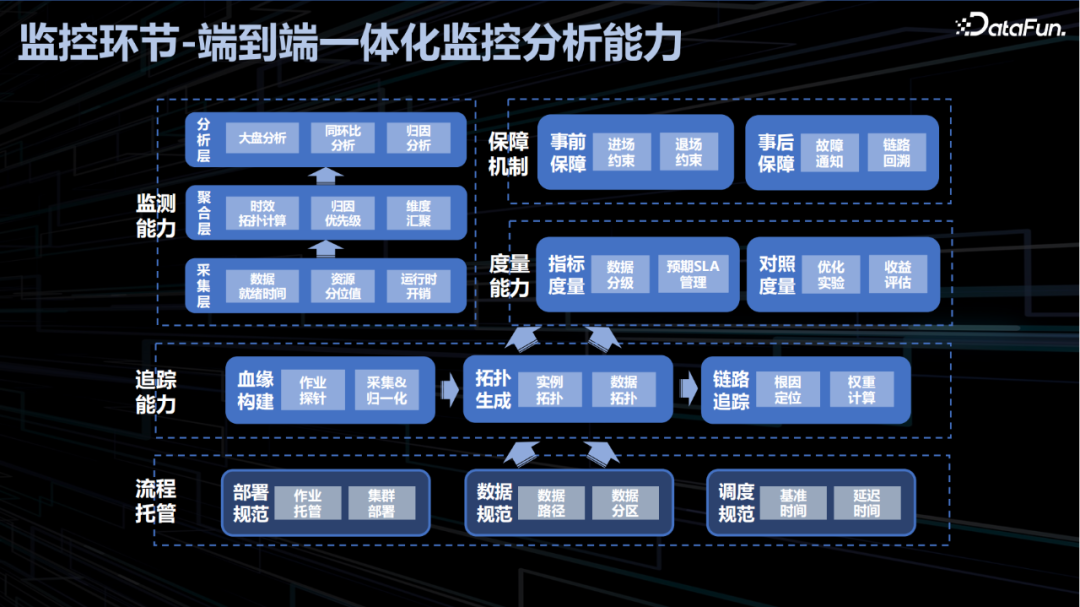
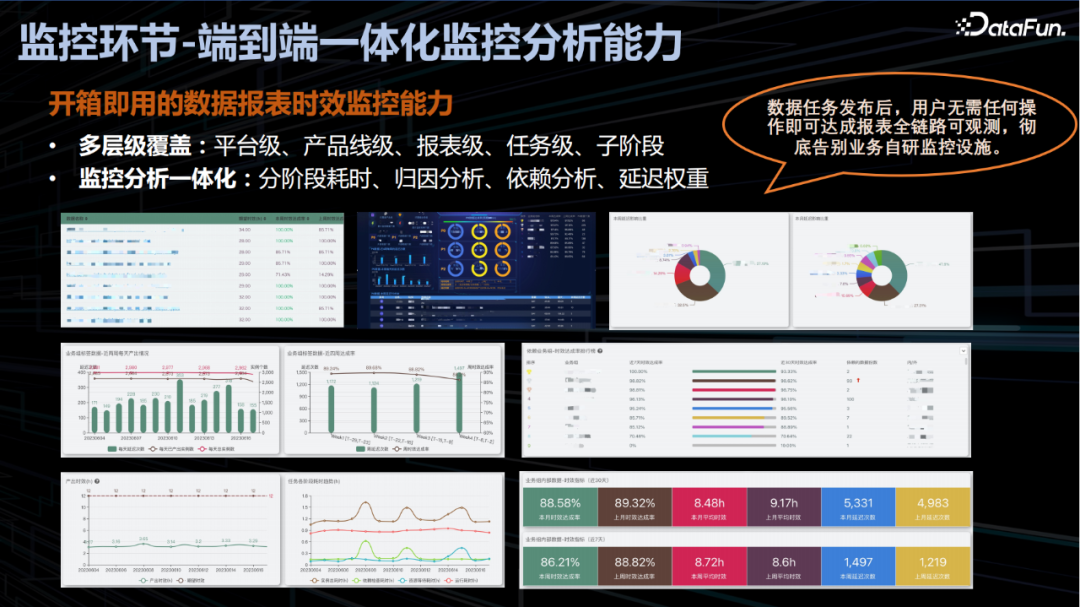
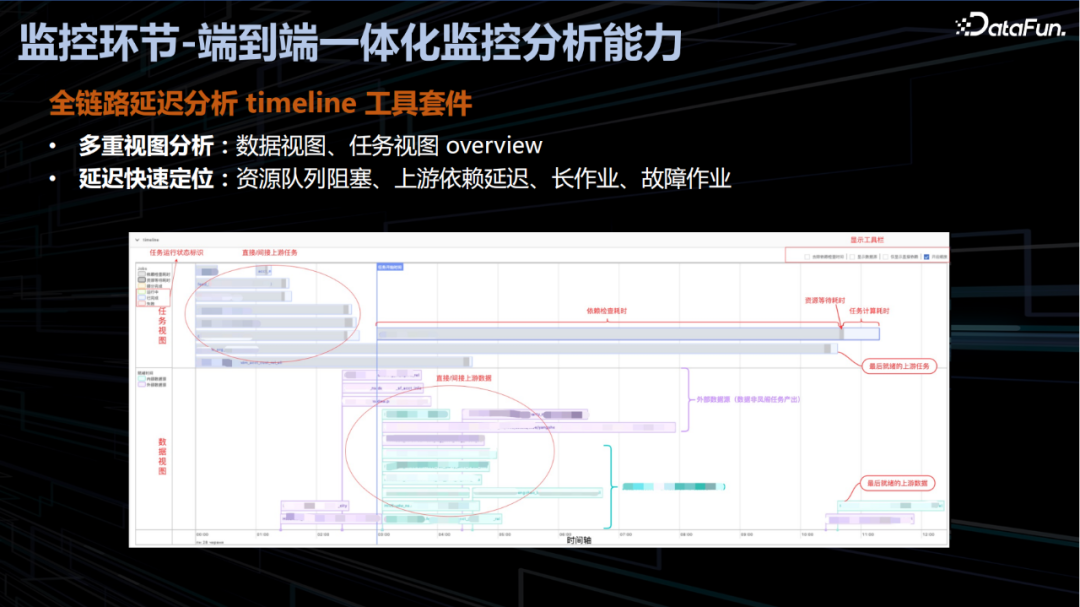
数据任务一旦发布用户无需自研监控设施即可开箱即用的达成数据报表的全链路可观测。线上化的监控能实现平台级、产品线级、报表级、任务级、子阶段等通过多层级覆盖,辅助快速识别风险的等级快速定位问题。另外,监控分析一体化能够自动化计算出分阶段耗时,自动故障自动归因等在提高故障定位效率的同时节约了大规模的人力投入,通过 timeline 工具套件实现数据报表的全链路分析,示例如下:
4. 运维环节-全链路数据回溯能力
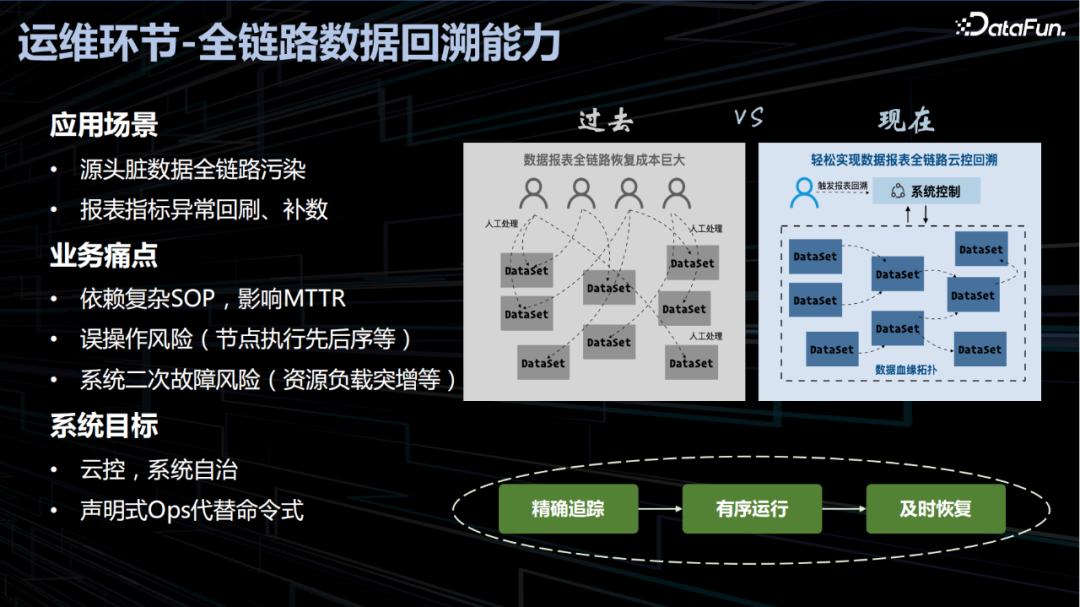
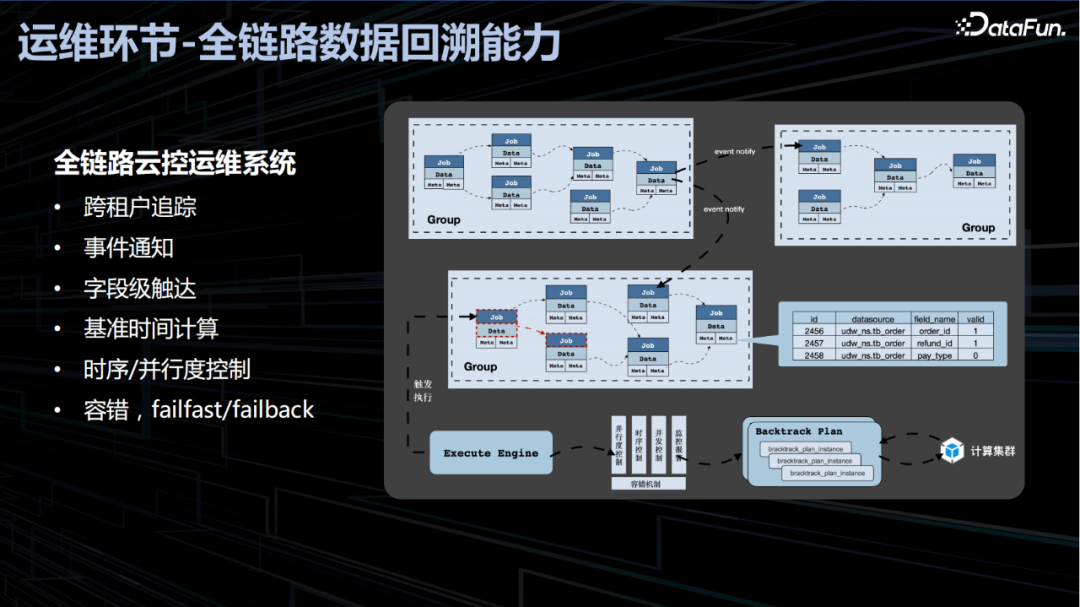
5. 优化环节
最后,分享一些关于大数据计算在优化过程中遇到的问题和解决方案。
问题分析与技术思考

面临如上问题时,百度商业数据平台在系统设计目标层面达成统一,首先通过声明式设计,以终为始,锚定数据报表的预期产出时间为时效性目标进行优化,减少了用户的心智负担。其次,完成目标生成、单点自动化调优和效果试验比对实现流程闭环。
全局数据报表时效性优化实验
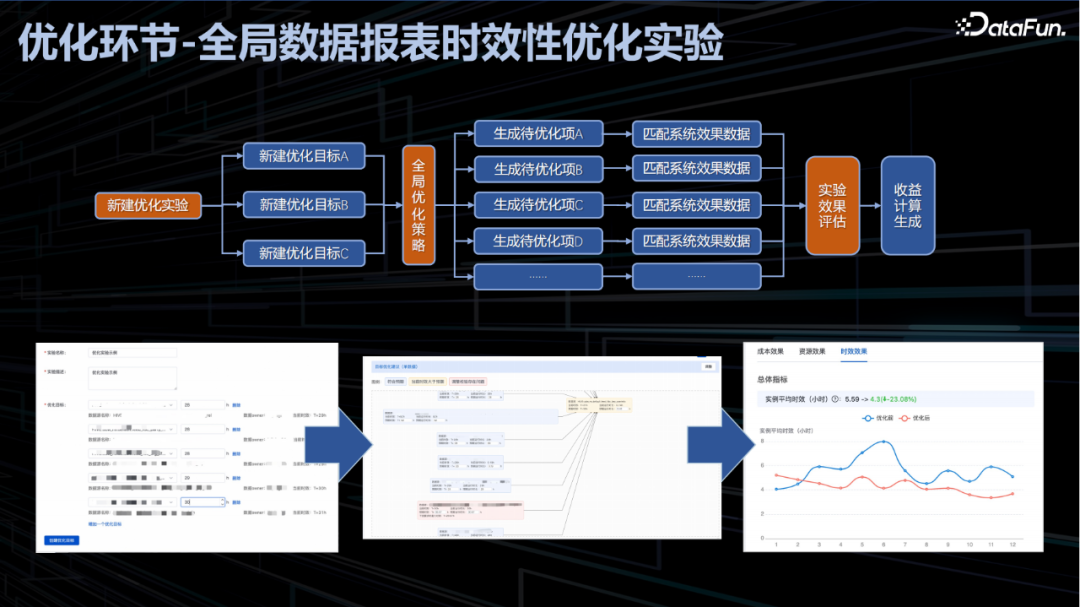
百度时效性优化系统负责将该系统设计目标和优化思路落地。主要通过设新建优化目标并基于全局优化策略生成待优化项,然后匹配系统效果数据生成试验评估效果,并自动完成优化前后的各类指标的可视化对比分析。
单点声明式动态调优
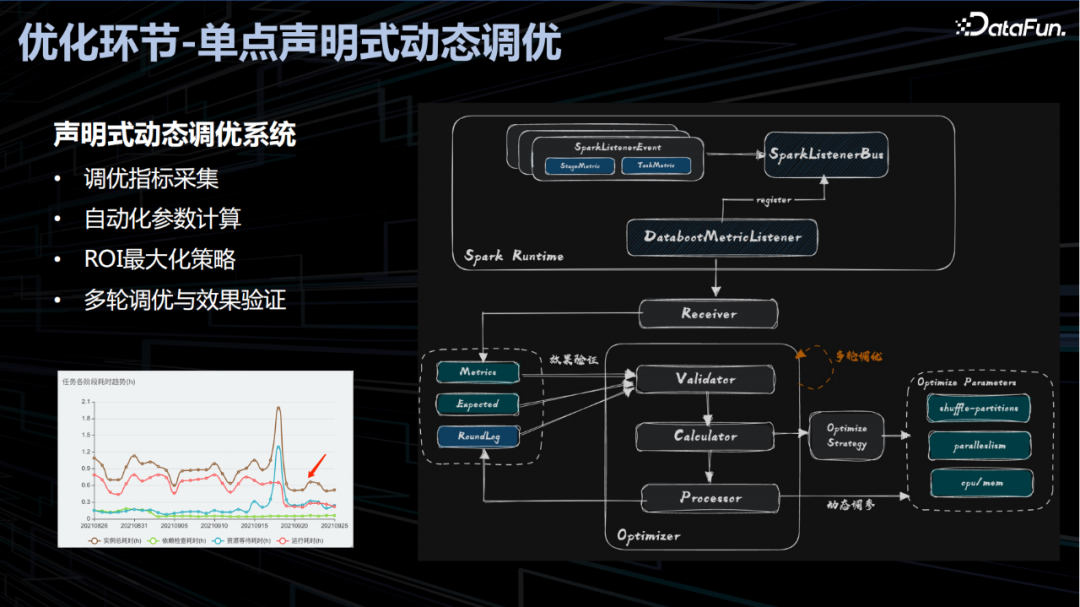
除了全链路调优,百度在基于单点的声明式动态调优也具备实践。主要通过探针采集作业的日常开销和实效性等指标并回传到 Receiver 模块存储,然后通过 Validator 判断调优效果是否符合预期,如果符合预期则退出,不符合则再通过 Calculator 生成策略并由Processor 实现 Spark 的动态调参,如此反复经过多轮调整后达到调优效果。
04
总结与展望
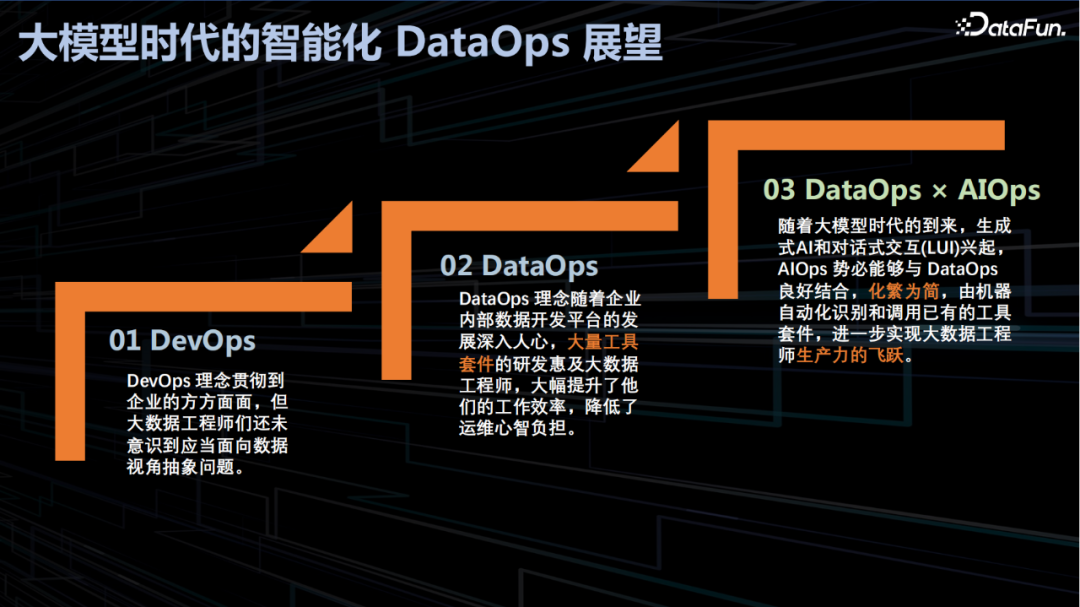
以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION

叶玮彬
百度
资深研发工程师
2014 年加入百度,现任商业平台部资深研发工程师,商业体系平台工程团队大数据方向 leader,百度商业大数据 LKT 成员。主要负责面向商业报表产品的大数据基建和应用架构工作,曾主导离线环境全面 Serverless 化改造,拥有数据治理领域十余项发明专利,对构建智能化 DataOps 大数据系统、保障复杂业务数据链路时效性与稳定性方面具有丰富经验。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢