
点击下方卡片,关注「AI视界引擎」公众号

高精度、轻量级和实时响应性是实施自动驾驶的三个重要要求。同时考虑所有这些要求是一项挑战。在这项研究中作者提出了一种自适应、实时和轻量级的多任务模型,设计用于同时处理目标检测、可驾驶区域分割和车道检测任务。
为了实现这一研究目标,作者开发了一个端到端的多任务模型,具有统一和简化的分割结构。作者的模型在不需要任何特定的自定义结构或损失函数的情况下运行。作者在BDD100k数据集上取得了有竞争力的结果,特别是在可视化结果方面。
性能结果显示,目标检测的mAP50为81.1%,可驾驶区域分割的mIoU为91.0%,车道线分割的IoU为28.8%。此外,作者引入了一个真实道路数据集,用于评估作者模型在真实场景中的性能,这明显优于竞争对手。这表明作者的模型不仅表现出竞争性能,而且比现有的多任务模型更灵活、更快速。
代码:https://github.com/JiayuanWang-JW/YOLOv8-multi-task
由于深度学习的快速进展,计算机视觉领域得以蓬勃发展,尤其在自动驾驶应用中。自动驾驶系统(ADS)为日常驾驶提供了增强的便利性,有效减轻了驾驶员的疲劳并减少了交通事故。ADS在消费车辆和商用卡车中都备受关注,旨在确保安全、舒适和高效的驾驶体验。
ADS可以仅依赖多个摄像Head和计算机视觉技术,也可以集成一系列先进的传感器,包括激光雷达、摄像Head和雷达。这两种方法都有各自的优势。与摄像Head相比,激光雷达传感器对光线和夜晚效果不太敏感。此外,它可以提供大视野的3D信息。然而,激光雷达传感器的长期开发周期和高成本阻碍了它们的广泛应用。
相反,使用摄像Head具有成本效益高和易于安装的优势。当将仅使用摄像Head捕获的图像作为输入,并将它们与深度学习模型结合到ADS中时,满足实时处理的严格要求变得至关重要,特别是需要保持超过每秒30帧(FPS)的帧率。更快的响应增加了避免事故和确保生存的可能性。鉴于边缘设备的有限计算能力,使用深度学习在自动驾驶中实现实时性能和高精度是具有挑战性的。
已经提出了许多用于自动驾驶中的单个任务的方法,其中许多已经取得了出色的结果。在目标检测任务领域,有两种主要方法。第一类包括两阶段技术,以Fast RCNN为代表。尽管这些方法强调检测精度,但它们通常以计算效率为代价。第二类由YOLO系列领衔的一阶段方法代表,从v1到最新v8不等。YOLOv8以其实时检测能力而闻名,并已广泛应用于各种检测任务。它主要关注检测而不是分割。虽然它们为分割任务引入了一个分割Head,但所采用的损失函数和评估指标都针对检测任务。此外,YOLOv8每个模型只能执行一个任务。在这种情况下,YOLOv8不适用于自动驾驶任务。在多任务条件下实施它需要多个模型,这显著增加了训练和推理时间。在自动驾驶的背景下,一个关键指标是推理时间或FPS。
在分割任务领域,该领域的一个里程碑是全卷积网络(FCN)。此外,U-Net和SegNet在可驾驶区域分割任务中是常见的模型。然而,车道线分割与可驾驶区域分割不同,因为车道线在道路图像中具有明显的细长特征。车道线分割需要Low-Level和多尺度特征进行有效分析。
最近,模型如PointLaneNet和MFIALane在车道线分割领域取得了广泛的关注。尽管它们在各自的领域取得了出色的结果,但由于所需特征的分辨率不同,将它们整合到一起面临挑战,分割操作在像素级别进行,而检测任务在一阶段方法中使用网格单元,并在两阶段方法中使用选择性搜索。尽管它们的焦点不同,但分割和检测任务都需要从输入图像中提取初始特征。因此,可以共享一个Backbone网络。与为每个任务使用单独的模型相比,将三个不同的Neck和Head集成到具有共享Backbone的模型中可以节省大量计算资源和推理时间。
最近,已经提出并应用了几种多任务模型在ADS中,例如YOLOP,Shokhrukh等人提出的多任务学习模型,稀疏U-PDP和HybridNet。所有这些方法都选择了三个任务来构建全景自动驾驶系统:目标检测、可驾驶区域分割和车道线分割,这些任务都来自公共的伯克利深度驾驶(BDD100K)数据集。这些方法中的每一种都取得了出色的结果。通常,它们的模型由两个组件组成:编码器和解码器。
然而,仍然存在一些挑战需要解决。首先,它们的Neck或Head组件具有复杂的结构,可能会进一步影响推理时间。其次,在设计损失函数或Neck结构时,它们通常会专注于专门的任务。因此,模型可能会牺牲其普遍性。因此,开发一个快速、稳健且具有普适性的模型至关重要。
将三个Head组合成一个模型是一个重大挑战,因为它们依赖于一个共享的Backbone网络,而这个Backbone网络必须能够同时捕捉三个任务的特征。在这种情况下,实验可能在一个或多个任务中表现出色,但某些任务可能会产生明显较差的结果。一个可能的解决方案是为每个任务定制特定的损失函数。然而,这种方法缺乏泛化性。当作者引入新任务时,必须相应地修改模型,例如YOLOP ,Shokhrukh等人为可驾驶区域和车道线分割分别提出了特定的损失函数或Neck结构。这对于实际应用并不友好。因此,开发一个通用模型仍然是一个挑战。
在作者的研究中,作者提出了A-YOLOM,一个专门设计用于多任务的自适应模型。值得注意的是,A-YOLOM可以有效地使用一个模型处理多个任务。此外,通过在相同类型的任务中采用一致的损失函数,作者保持了一种统一的方法。重要的是,作者引入了一个特别针对分割Neck的自适应模块,从而消除了不同场景任务需要不同设计的需求。
总结一下,作者研究的主要贡献如下:
开发了一种轻量级模型,能够将三个任务集成到一个统一的模型中。这对于需要实时处理的多任务特别有益。
设计了一个新颖的自适应连接模块,专门用于分割架构的Neck区域。这个模块可以自适应地连接特征,进一步增强了模型的普适性。
设计了一个轻量级且通用的分割Head。对于相同类型的任务Head,作者有一个统一的损失函数,这意味着作者不需要为特定任务进行定制设计。
在公开可用的自动驾驶数据集上评估了作者的模型,在推理时间和可视化方面取得了有竞争力的结果。此外,作者还使用真实道路数据集进一步评估了作者模型的性能,并明显超越了竞争对手。
在本节中,作者将详细介绍作者的模型。具体而言,作者的讨论将涵盖三个主要组件:Backbone、Neck和Head。此外,还包括损失函数。
A-YOLOM的结构如图1所示。
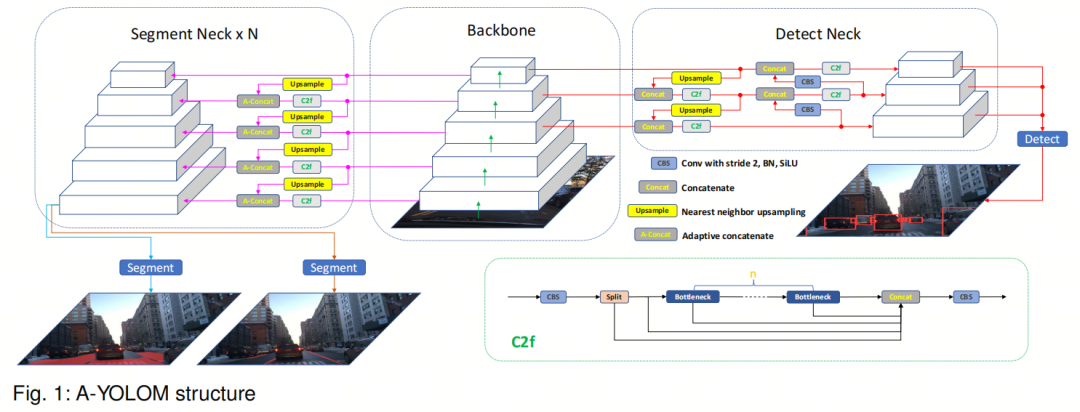
作者的模型是一个一阶段网络,具有简单的编码器-解码器架构。编码器包括Backbone网络和Neck,而解码器由Head组成。
值得注意的是,作者总共有三个Neck:一个用于目标检测的检测Neck,另外两个用于可驾驶区域和车道线的分割Neck。作者的模型具有简单而高效的结构,不仅扩展了其应用范围,还确保了实时推理性能。
在作者的工作中,作者利用了一个共享的Backbone网络,并为3个不同的任务使用了3个Neck网络。
Backbone网络由一系列卷积层组成,专门用于从输入数据中提取特征。鉴于YOLOv8在检测任务中的出色性能,作者的Backbone网络遵循了YOLOv8。
具体来说,它们改进了CSP-Darknet53,它是YOLOv5的Backbone网络。与CSP-Darknet53相比,这个Backbone网络的主要区别是使用了c2f层代替了c3模块。c2f模块将High-Level特征与上下文信息相结合,进一步提高了性能。
还有一些较小的差异,例如使用3x3卷积代替初始的6x6卷积,以及删除了第10和第14个卷积层。这些改进使Backbone网络比YOLO系列的前任更加有效。
Neck负责融合从Backbone网络提取的特征。在Backbone网络之后,作者使用SPPF模块来增加感受野,减少与SPP相比的计算需求。然后将这些特征传递到各个Neck。
在作者的模型中,作者使用了3个Neck:一个用于目标检测任务,另外两个用于分割任务,分别用于可驾驶区域和车道线。值得注意的是,在图1中,由于作者有两个分割任务,左侧分割Neck中的N的值等于2。这意味着作者为不同的分割任务有两个相同的分割Neck。来自不同Neck底部层的天蓝色和棕色线条分别通向不同的分割Head。
对于检测Neck,作者采用了PAN结构,包括自上而下和自下而上的两个FPN。这个结构将Low-Level细节与High-Level语义特征合并,丰富了整体特征表示。这对于目标检测非常重要,因为小目标依赖于Low-Level特征,而较大的实体则从High-Level特征提供的更广泛上下文中受益。在检测任务中,通常会出现不同尺度的目标。这种目标尺寸的多样性是作者选择PAN结构作为检测Neck的主要原因。

对于分割Neck,作者采用了FPN结构,以有效处理多尺度目标而闻名。此外,作者在Neck和Backbone网络之间引入了一个自适应连接模块。如算法1所示,该模块在每个相同的分辨率上运行,自适应地确定是否应该连接特征。这个添加增强了模型的普适性,使其适用于各种分割任务。
解码器处理来自Neck的特征图,为每个任务进行预测。这包括预测目标类别、它们对应的边界框以及特定分割目标的Mask。
在作者的工作中,作者采用了两个不同的Head:检测Head和分割Head。
检测Head采用了一种分离的方法,遵循YOLOv8 Detect Head,使用卷积层将高维特征转换为类别预测和边界框,而不包括目标性分支。
请注意,检测Head的输出在训练、验证和预测模式之间有所不同。在验证和预测模式下,处理遵循图1的右侧部分。使用三种不同的分辨率作为输入,并输出一个包含类别预测和它们各自边界框的张量。在训练模式下,检测Head周期性地将卷积层应用于每个输入,总共输出三个张量。每个张量包含特定于其分辨率的类别预测和边界框。然后使用这些结果计算损失函数。

作者的分割Head在不同的分割任务中是相同的。具体来说,它包括一系列卷积层,用于提取上下文信息,并包括一个反卷积层,将分辨率恢复到原始图像大小。最终,作者获得一个与原始图像大小相匹配的像素级二进制Mask。0表示背景,1表示目标。算法2说明了分割Head的处理过程。此外,分割Head的简化架构,仅包括7940个参数,极大地增强了模型的可部署性。
作者采用端到端的训练方法,使用多任务损失函数。具体来说,作者的损失函数包括两个组成部分:检测和分割。公式如下:
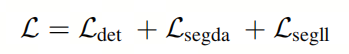
其中表示目标检测任务的损失函数,表示可驾驶区域分割任务的损失函数,表示车道线分割任务的损失函数。
对于检测任务,损失函数分为三个主要部分:分类损失,目标损失和边界框损失。分类损失使用二元交叉熵损失来衡量预测概率与实际标签之间的差异。目标损失采用DFL,表示为。DFL通过广义分布捕捉边界框的位置,使网络能够迅速聚焦在靠近注释位置的区域,从而增加它们的概率。边界框损失使用CIoU损失,表示为。CIoU损失综合了重叠、距离和纵横比一致性的方面。因此,它使模型能够更精确地定位目标的形状、大小和方向。
因此,检测损失可以表示为:
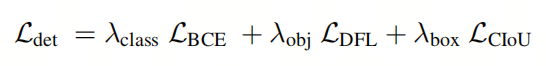
其中,和是相应的系数。对于分割任务,作者使用相同的损失函数。这意味着和具有相同的公式。但它们分别进行反向传播。作者将它们统称为。公式如下:
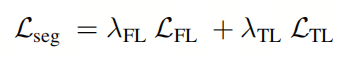
其中和分别是Focal Loss和Tversky损失。这两者都是分割任务中广泛使用的损失函数。和是相应的系数。
Focal Loss提供了处理不平衡样本的稳健解决方案,确保模型不会过于偏向占主导和容易学习的类别。相反,它更加重视具有挑战性和不平衡的区域。Tversky损失是Dice损失的扩展,引入了两个额外的参数(α和β),以分配不同的权重给假阳性和假阴性,从而增强了其处理不平衡任务的能力。

作者的训练方法代表了在泛光自动驾驶任务中普遍存在的经典多任务学习方法的一种离经叛道。作者采用端到端的训练模式,每个批次仅进行一次反向传播。这意味着整个网络在不冻结特定层或交替优化的情况下进行了集体优化,从而减少了训练时间。算法3说明了逐步训练过程。
深度学习应用中的一个主要挑战是推理时间。特别是在自动驾驶任务中,需要在边缘设备上部署模型,这些设备通常具有有限的计算资源。因此,确保模型既轻巧又实时变得至关重要。
在表格I中,作者重新生成并测试了YOLOP1、HybridNet、YOLOv8和作者的模型的推理时间,所有模型在bs=1/32的GTX 1080 Ti GPU上进行了FPS测试。FPS的计算方法遵循HybridNet。
此外,作者还提供了每个模型的参数数量作为评估结果之一。
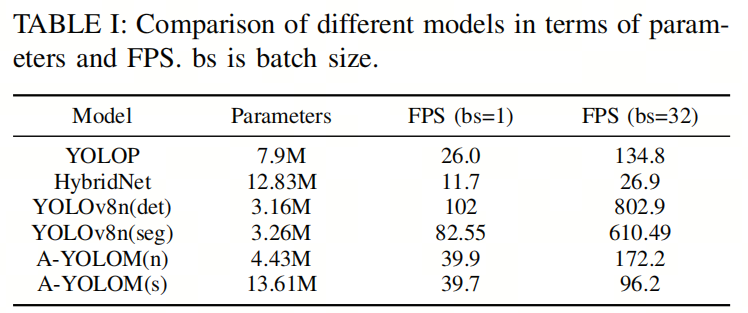
A-YOLOM(n)和A-YOLOM(s)之间的主要区别在于Backbone网络的复杂性。A-YOLOM(n)是作者设计的轻量级Backbone网络,降低了复杂性,使其非常适合在边缘设备上部署。A-YOLOM(s)具有更复杂的Backbone网络,提供了更强大的性能,但时间开销也更大,特别是在bs=32的情况下。与泛光自动驾驶中的其他领先多任务模型和单任务模型相比,A-YOLOM(n)更加轻量级且更高效。
具体来说,与YOLOP相比,A-YOLOM(n)的参数数量明显更少,FPS更高。它在bs=1时实现了1.53倍的加速,bs=32时实现了1.28倍的加速。这表明作者的模型更加高效。与HybridNet相比,A-YOLOM(n)在参数和速度上具有明显优势。
尽管A-YOLOM(n)的参数比HybridNet多,但它更快。由于HybridNet在bs=1和bs=32中都不能满足实时性能的要求,因此作者不会在后续部分中比较其性能。YOLOv8是一个单任务模型,这意味着它只能在一个模型内执行一个任务。这是作者列出两个版本的原因:一个是YOLOv8(det),另一个是YOLOv8(seg)。尽管它们都比其他模型更快,包括作者的模型,但它们需要在边缘设备上部署三个单独的模型,这意味着将一个检测模型与两个分割模型合并到一个边缘设备上,总共需要9.68M个参数。这比A-YOLOM(n)多了2.18倍,给边缘设备带来了巨大的压力。
此外,与作者的模型相比,YOLOv8在三个任务中的性能要差得多,作者将在接下来的部分讨论这一点。
本部分介绍了多任务实验的结果,包括目标检测、可驾驶区域分割和车道线分割。
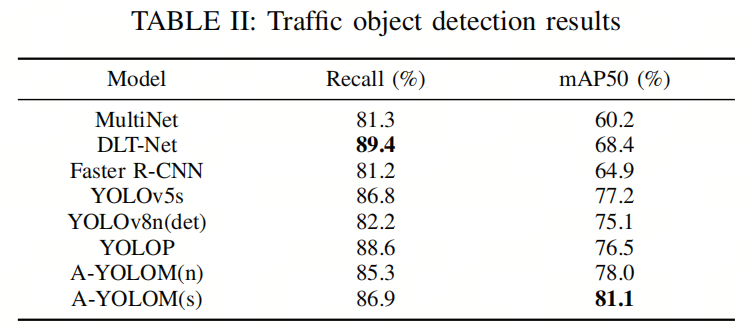
在检测任务中,作者遵循YOLOP的设置,将汽车、公共汽车、卡车和火车合并为“车辆”分类。比较结果如表II所示。根据定量结果,作者可以看到作者模型的两个版本在mAP50方面表现最佳。这表明作者模型在预测检测目标方面的准确性很高。特别是与MultiNet和Faster R-CNN相比。
此外,A-YOLOM(n)的Backbone网络、检测Neck和Head的复杂性水平与YOLOv8n(det)相当。然而,在召回率和mAP50方面,A-YOLOM(n)明显优于YOLOv8n(det)。这表明在多任务学习中,各种任务可以隐式地协助并进一步增强各个任务的性能。
另外,YOLOv8n(det)在召回率方面优于YOLOv5s,因为通常“s”规模的模型具有更复杂的Backbone网络以提高性能。作者模型的一个问题是召回率不够令人满意。YOLOP和DLT-Net的召回率比作者的模型更好。作者认为这是由于中权重较高造成的。这意味着模型更加保守,侧重于在不牺牲召回率性能的情况下获得更高的mAP。作者认为mAP50更好地反映了检测任务中的综合性能。
此外,作者的模型实现了实时性能,而根据表I,YOLOP在bs=1时不能实现。
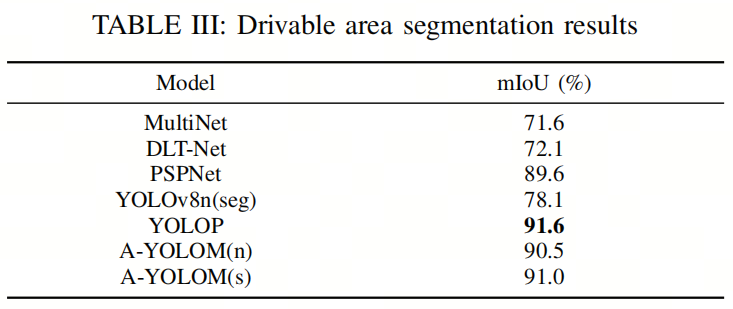
对于可驾驶区域分割任务,表III提供了定量结果。在mIoU方面,作者的模型分别达到了第二和第三佳表现。YOLOP的性能优于作者的模型,因为他们为分割任务定制了损失函数。就mIoU而言,A-YOLOM(n)和A-YOLOM(s)相对于YOLOP分别落后1%和0.5%。作者认为这个结果是可以接受的。虽然作者的模型可能在性能上略有损失,但它更加灵活和快速。
此外,作者的模型远远优于其他模型,如YOLOv8n(seg)、MultiNet和PSPNet。值得注意的是,虽然YOLOv8n(seg)比作者的模型更快,但它的部署成本更高,性能明显不如作者的。
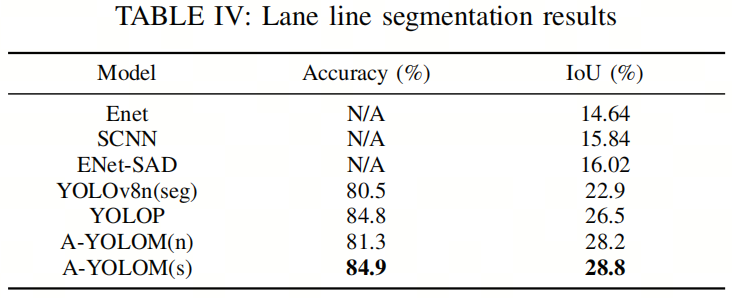
对于车道线分割任务,表IV提供了定量结果。A-YOLOM(s)在准确性和IoU方面均取得了最佳性能。具体而言,它在准确性方面取得了竞争性的结果,IoU比YOLOP高2.6%。
值得注意的是,作者的模型在所有分割任务中保持了相同的结构和损失函数,遇到新的分割任务时无需进行调整。
此外,YOLOv8(seg)稍逊于作者的模型。根据表III和表IV的结果,作者认为作者提出的Neck和Head与YOLOv8(seg)相比更适合分割任务。由于作者使用平衡准确性进行评估,Enet、SCNN和ENet-SAD采用了不同的准确性计算方法。
因此,作者不能直接将作者的准确性与它们进行比较。然而,作者在IoU指标方面的结果明显优于它们的结果。这已足以充分证明作者的模型相对于它们的卓越性能。
本节介绍了YOLOP和作者的模型之间的视觉比较。作者不仅在有利的天气条件下评估性能,还在包括强烈阳光、夜晚、雨和雪在内的恶劣条件下评估性能。作者将逐个分析每个场景。

图2显示了晴天的结果。众所周知,强烈的阳光会影响驾驶员的视野。同样,它也会影响模型的性能。这对可驾驶区域和车道线分割性能构成挑战。在这种具有挑战性的情况下,作者的模型胜过了YOLOP。
具体而言,在强烈阳光条件下(如左边和右边的图像中所示),作者的模型提供了准确的车道线预测,并提供了更平滑的可驾驶区域指示。
此外,作者的模型在检测较小和较远的车辆方面表现出更高的准确性。如中间和右边的图像中所观察到的那样,作者的模型成功地检测到了远距离的车辆,这些车辆分布在相反的行驶方向的道路上和房子附近。
根据可视化结果,作者认为作者的模型在这个场景中表现优于YOLOP。

图3显示了夜晚场景的结果。在夜晚场景中,由于光线有限和迎面来车的耀眼,图像质量下降。这对模型进行准确预测构成了挑战。在这个挑战下,作者的模型一直为车道线和可驾驶区域的预测提供更准确和更平滑的结果。AYOLOM(s)在分割任务和检测任务方面均表现出色。
具体而言,它在准确性方面超过了AYOLOM(n),即使在耀眼的情况下也可以准确检测到相反方向行驶的车辆,并与YOLOP相媲美。根据右图的检测结果,YOLOP在夜间检测远处的车辆方面略优于作者的模型。然而,与YOLOP相比,作者的模型在分割方面产生了显着更好的结果。特别是在中间图像中,YOLOP错误地将对向车道预测为可驾驶区域。这种错误预测对自动驾驶任务极为危险。

图4显示了雨天的结果。雨水会增加道路表面的反射,从而影响驾驶员的判断。这个问题也表现在深度学习模型中。此外,由于雨滴对挡风玻璃的折射和散射效应,可能会模糊整个图像,给模型的预测带来巨大挑战。在左图的结果中,作者可以看到由于路面反光,YOLOP无法准确分割可驾驶区域。在中间场景中也出现了类似情况。YOLOP甚至难以区分汽车引擎盖和道路。
然而,作者的模型在这种情况下仍然表现出色。特别是对于A-YOLOM(s),它受到的路面反光影响较小。作者的模型在车道线检测方面也优于YOLOP,正如右图所示。然而,在这个场景中,YOLOP在检测任务中胜过作者。如左图所示,YOLOP可以检测到更远距离的车辆。

图5显示了雪天的结果。在雪天的条件下,积雪可能会遮挡道路或车道,为模型带来额外的挑战。一些积雪被清除到道路一侧,这对模型的车辆预测构成了挑战。例如,在中间图像的左侧,YOLOP错误地将积雪丘陵识别为车辆。如果道路上有小的积雪丘陵,车辆通常可以越过它。将这些小积雪丘陵误认为是静止车辆可能是危险的。因此,高召回率并不总是更好。在召回率和精确度之间取得平衡非常重要。
在所呈现的所有三个结果中,作者的模型在分割任务方面明显优于YOLOP,特别是A-YOLOM(s)尤为突出。然而,根据右图的结果,在恶劣天气条件下,作者的模型在检测远距离和小目标方面略逊于YOLOP。
在本小节中,作者进行了两项消融研究,以阐明作者提出的自适应连接模块以及分割Neck和Head对整体模型的影响。
为了评估作者提出的自适应连接模块的影响,作者将包括和不包括该模块的性能进行了比较。具体而言,YOLOM(n)和YOLOM(s)作为Baseline,代表了两个不同的实验组,具有不同的Backbone网。作者已经为它们精心设计了分割Neck结构,以满足特定分割任务的需求。然而,A-YOLOM(n)和A-YOLOM(s)都包括自适应连接模块,因此它们的分割Neck结构完全相同。

结果如表V所示。将A-YOLOM(n)与YOLOM(n)进行比较时,作者发现在检测和可驾驶区域分割方面的性能相当。然而,车道线的准确性和IoU显示出显著的提高。同样,将A-YOLOM(s)与YOLOM(s)进行比较时,作者观察到相同的改善趋势。这些结果表明,作者提出的自适应连接模块可以积极适应各种任务,并且在性能上要么与根据经验精心制作的模型竞争,要么胜过它们。
结果如表VI所示。YOLOv8(segda)和YOLOv8(segll)分别实施可驾驶区域和车道线分割任务。YOLOv8(multi)是一个综合的多任务学习模型,将YOLOv8(segda)、YOLOv8(segll)和YOLOv8(det)的Neck和Head结构合并为一个共享的Backbone。作者观察到性能有显著改善。这表明多任务学习可以相互增强各个任务的性能。
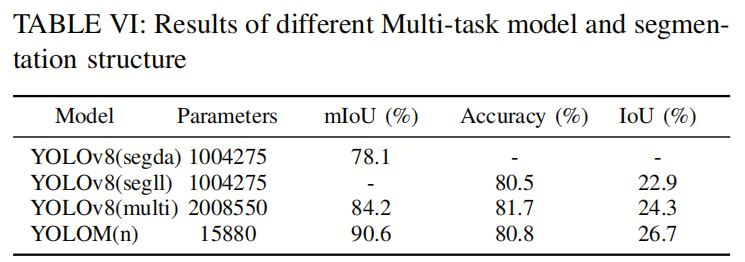
与YOLOv8(multi)相比,YOLOM(n)具有为分割任务量身定制的Neck结构。此外,它拥有显著更轻量级的Head结构,复杂度仅为0.008倍。这一显著改进源于作者独特的Head设计,它仅依赖于一系列卷积层,直接输出Mask,无需额外的protos信息。YOLOM(n)在可驾驶区域和车道线任务的mIoU和IoU方面均取得了显著改进的结果。
此外,在车道线任务中,作者提供了竞争性的准确性。这些结果表明,作者提出的Neck和Head创新在几乎没有参数和性能开销的情况下取得了可观的结果。
本节主要讨论在真实道路数据集上进行的实验。具体来说,作者使用仪表盘摄像机拍摄了几段视频,然后逐帧将它们转换为图像,以使用作者的模型和YOLOP进行预测。每个转换后的图像数据集包含了1428张分辨率为1280x720的图像。这些图像涵盖了三种情景:高速公路、夜晚和白天。

图6显示了来自真实道路数据集的结果。然而,作者的模型始终保持相对稳定的性能,尤其是AYOLOM(s)。在所有任务中,AYOLOM(s)均优于YOLOP。
与YOLOP相比,AYOLOM(n)只在检测任务中略逊一筹。这一点非常重要,因为自动驾驶系统必须能够在陌生的场景中运行。真实道路上的结果表明,作者的模型可以满足自动驾驶车辆在实际道路上的实际需求。
[1].You Only Look at Once for Real-time and Generic Multi-Task.
腾讯实验室提出GOLO | 实在优雅!一个简洁的像YOLO的DETR目标检测器来啦!!
SA-UNet开源 | StyleGAN2与UNet的完美邂逅,成就更好的语义分割模型

点击上方卡片,关注「AI视界引擎」公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢