
使用 Optimum Habana ,你可以轻松在 Habana Gaudi2 加速卡上对大语言模型 (LLM) 的进行快速训练和推理。本文,我们将介绍对 Codegen,一个用于代码生成的开源 LLM,进行低秩适配(Low-Rank Adaptation,LoRA)训练的全过程。我们还会使用 Codegen 对 Habana Gaudi2 的训练和推理效率进行基准测试。
Codegen
Codegen 是一系列基于 transformer 的自回归语言模型,使用标准的基于下一词元预测的语言建模目标函数进行训练。Codegen 由 Salesforce AI Research 开发和发布,提供多种尺寸(350M、2.7B、6.1B 和 16B 参数),每个尺寸还有基于不同训练数据集训练而得的变体。
其中,Codegen-NL 基于 The Pile 数据集训练而得,The Pile 是一个 825 GB 的自然语言数据集,由 22 个子数据集组成。基于 Codegen-NL,Codegen-Multi 是在 BigQuery 数据集的一个子集上进一步训练而得的,该子集包含来自六种编程语言(C、C++、Go、Java、JavaScript 和 Python)的开源代码。最后,Codegen-Mono 是以 Codegen-Multi 为初始权重,在 BigPython 这个大型 Python 代码数据集上进行训练而得的。
本文我们使用 Codegen-Mono 的最大变体 (Codegen-Mono-16B),下文简称为 Codegen。
LoRA
通过额外的微调,预训练的 LLM 通常可以适应与其预训练任务不同的任务。然而,在 Codegen 等模型中微调全部 16B 参数很吃资源,且在大多数情况下是不必要的。参数高效微调 (parameter-efficient finetuning,PEFT) 方法不对模型的全部参数进行完全微调,而是通过仅学习目标新任务所需的少量增量权重来使得预训练的 LLM 能够适应新任务。
低阶适配(LoRA)是 PEFT 的一种方法,最近相当流行。LoRA 使用两个低秩矩阵对 LLM 的增量权重进行参数化,其中秩用于控制微调期间可训练参数量。如下图所示,在每次前向传播期间,由低秩矩阵表示的增量权重将添加到预训练的 LLM 权重中。
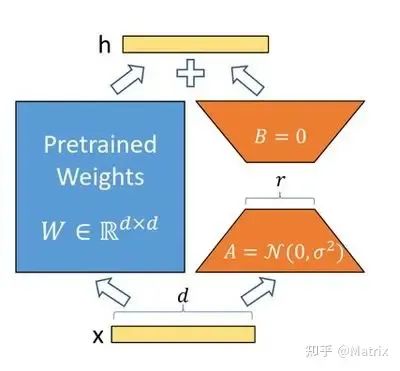
LoRA 使 Codegen 等模型不需要跨多个加速卡或 GPU 进行分布式训练,也能有效地适配新的数据集和任务。
硬件
Gaudi2 是 Habana Labs 开发的人工智能加速卡,其可为人工智能工作负载提供最先进的深度学习训练和推理性能。每张 Gaudi2 加速卡(代码中为 “HPU”)有 96GB 的内置内存,你可通过英特尔开发者云 (IDC) 访问到包含 8 张 Gaudi2 夹层卡(mezzanine card)的 Gaudi2 服务器,你也可以购买超微(Supermicro)或威强电(IEI)的服务器进行本地化部署。有关 IDC 上 Gaudi2 入门的详细说明,请参考这篇 Huggingface 博文。
本文,我们使用 IDC 上的 Gaudi2 加速卡进行训练和推理。
训练
我们的训练和推理主要基于 Optimum Habana,它是 Huggingface Transformers 和 Diffusers 库与 Habana Gaudi 系列加速卡之间的接口。首先,我们克隆 Optimum Habana 库,然后安装它以及必要的依赖项:
git clone https://github.com/huggingface/optimum-habana.git
pip install –e optimum-habana/
pip install –r optimum-habana/examples/language-modeling/requirements.txt
pip install –r optimum-habana/examples/text-generation/requirements.txt我们使用 sql-create-context 数据集进行微调。sql-create-context 数据集包含 78577 个自然语言查询示例、SQL CREATE TABLE 上下文及其对应的 SQL 查询语句。下面给出了该数据集的一个样本:
{
"question": "The 'firs park' stadium had the lowest average attendence of what?",
"context": "CREATE TABLE table_11206916_1 (average INTEGER, stadium VARCHAR)",
"answer": "SELECT MIN(average) FROM table_11206916_1 WHERE stadium = 'Firs Park'"
}我们从 sql-create-context 数据集中随机抽取 20% 样本对 Codegen-Mono 进行微调,也就是总共 15716 个微调样本。首先,我们下载、分割训练集并将其写入名为 “train-sql-create-context.json” 的文件中:
from datasets import load_dataset
dataset = load_dataset('b-mc2/sql-create-context')
ds_train_test = dataset['train'].train_test_split(test_size=0.2)
ds_train_test['test'].to_json('./data-for-finetune/train-sql-create-context.json')准备好训练数据集后,我们就可以开始进行 LoRA 微调了。要使用单张 Gaudi2 加速卡进行微调,我们可以在 Optimum Habana 中调用 run_lora_clm.py,如下所示:
cd optimum-habana/examples/language-modeling/
python run_lora_clm.py \
--model_name_or_path Salesforce/codegen-16B-mono \
--train_file "./data-for-finetune/train-sql-create-context.json" \
--report_to "tensorboard" \
--bf16 True \
--output_dir ./finetuned-models/codegen-on-sql-create-context-hpu1-lora8-bs4 \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--evaluation_strategy "no" \
--save_strategy "no" \
--learning_rate 1e-4 \
--logging_steps 1 \
--dataset_concatenation \
--do_train --use_habana --use_lazy_mode \
--throughput_warmup_steps 3 \
--lora_target_modules "qkv_proj" \
--lora_rank 8 \
--cache_dir /codegen/cache/要加快训练,我们可以通过 DeepSpeed 使用多张 Gaudi2 来训练模型。例如,只需调用 `gaudi_spawn.py`` 即可使用 8 张 Gaudi2 启动相同的训练作业:
cd optimum-habana/examples/language-modeling/
python ../gaudi_spawn.py \
--world_size 8 --use_deepspeed run_lora_clm.py \
--model_name_or_path Salesforce/codegen-16B-mono \
--train_file "./data-for-finetune/train-sql-create-context.json" \
--report_to "tensorboard" \
--bf16 True \
--output_dir ./finetuned-models/codegen-finetune-on-sql-create-context-hpu8-lora8-bs4 \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--evaluation_strategy "no" \
--save_strategy "no" \
--learning_rate 1e-4 \
--logging_steps 1 \
--dataset_concatenation \
--do_train \
--use_habana \
--use_lazy_mode \
--throughput_warmup_steps 3 \
--cache_dir /codegen/cache/ \
--use_hpu_graphs_for_inference \
--lora_target_modules "qkv_proj" \
--lora_rank 8 \
--deepspeed deepspeed_config.json上例中使用了 8 张 Gaudi2 进行微调,其 DeepSpeed 配置如下:
{
"steps_per_print": 64,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"bf16": {
"enabled": true
},
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 2,
"overlap_comm": false,
"reduce_scatter": false,
"contiguous_gradients": false
}
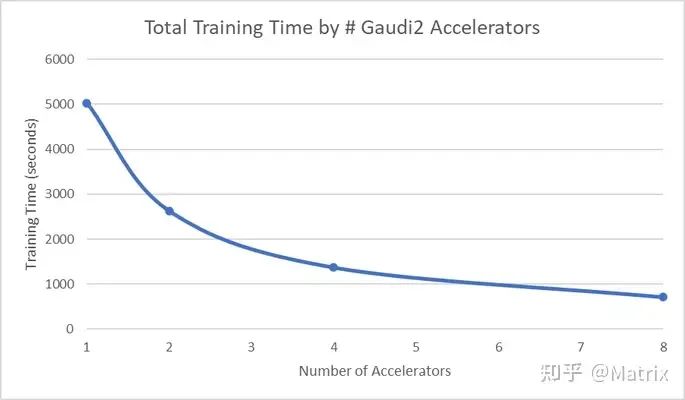
}利用多张 Gaudi2 和 DeepSpeed 可显著加快训练速度。下面我们展示了上述微调实验中使用的 Gaudi2 数量与总训练时间之间的关系。
推理
现在我们已经使用 LoRA 对 Codegen 进行了微调,我们可以观察下训练后的模型其生成质量是否有改善。我们使用以下查询来评估 LoRA 微调前后的 Codegen 的生成质量:
You are a text-to-SQL model. Your job is to answer questions about a database. You are given a question and a context regarding one or more tables in the database.
You must output the SQL query that answers the question. The SQL query must be between [SQL] and [/SQL] tags.
### Question:
The 'firs park' stadium had the lowest average attendence of what?
### Context:
CREATE TABLE table_11206916_1 (average INTEGER, stadium VARCHAR)
### Response:我们可以使用 Optimum Habana 中的 run_generation.py 脚本来用 LoRA 微调后的 Codegen 模型生成此查询的补全:
cd optimum-habana/examples/text-generation
python run_generation.py \
--model_name_or_path "Salesforce/codegen-16B-mono" \
--peft_model "../language-modeling/finetuned-models/codegen-on-sql-create-context-hpu1-lora8-bs4" \
--max_new_tokens 100 --bf16 --use_hpu_graphs --use_kv_cache \
--prompt "You are a text-to-SQL model. Your job is to answer questions about a database. You are given a question and a context regarding one or more tables in the database.
You must output the SQL query that answers the question. The SQL query must be between [SQL] and [/SQL] tags.
### Question:
The 'firs park' stadium had the lowest average attendence of what?
### Context:
CREATE TABLE table_11206916_1 (average INTEGER, stadium VARCHAR)
### Response:"生成的响应如下,回答正确:
### Response:
[SQL]SELECT MIN(average) FROM table_11206916_1 WHERE stadium = "Firs Park"[/SQL]现在让我们看下相同的查询在原始 Codegen 模型上的输出:
cd optimum-habana/examples/text-generation
python run_generation.py \
--model_name_or_path "Salesforce/codegen-16B-mono" \
--max_new_tokens 100 --bf16 --use_hpu_graphs --use_kv_cache \
--prompt "You are a text-to-SQL model. Your job is to answer questions about a database. You are given a question and a context regarding one or more tables in the database.
You must output the SQL query that answers the question. The SQL query must be between [SQL] and [/SQL] tags.
### Question:
The 'firs park' stadium had the lowest average attendence of what?
### Context:
CREATE TABLE table_11206916_1 (average INTEGER, stadium VARCHAR)
### Response:"如下所示,原始 Codegen 模型无法生成正确的 SQL 代码来回答问题:
### Response:
SELECT stadium, AVG(average)
FROM table_11206916_1
GROUP BY stadium
HAVING AVG(average) = (SELECT MIN(average)
FROM table_11206916_1)此示例展示了 LoRA 如何成功提高 Codegen 生成预训练数据集中未见的编程语言的补全的能力。
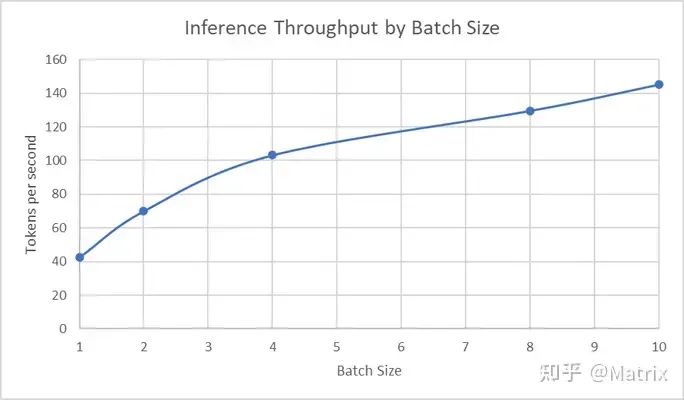
除了 LLM 的 LoRA 微调之外,Optimum Habana 还包括对 Codegen 等模型的推理优化,以在 Habana Gaudi2 加速卡上实现快速推理。使用我们的 LoRA 微调后的 Codgen 模型和上文中的 run_generation.py 脚本,其在各种 batch size 下的吞吐量如下图所示:
总结
通过本文,我们展示了如何使用 Habana Gaudi2 加速卡和 Optimum Habana 快速、轻松地通过 LoRA 微调 LLM。尽管本文仅以 Codegen 为例,但 Optimum Habana 中的 LoRA 微调和推理脚本与其他 LLM 广泛兼容。试试在英特尔开发者云的 Habana Gaudi2 上部署你自己的人工智能工作负载吧!
英文原文: https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/Accelerating-Codegen-training-and-inference-on-Habana-Gaudi2/post/1521248
原文作者:Tiep Le,Ke Ding,Vasudev Lal,Yi Wang,Matrix Yao,Phillip Howard,作者均来自英特尔
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
本文转载自社区供稿内容,不代表官方立场。了解更多,请关注知乎“Matrix”。
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢