
关于我们
数元灵科技专注于一站式湖仓智能平台新基建,我们的在研项目包括云原生湖仓一体框架,分布式训练引擎和算法框架,高性能数据、模型在线服务,以及云原生一站式AI开发生产平台。

在大模型的时代背景下,大数据与 AI 无疑是两个最重要的技术生态,尽管如此,大数据和 AI 的技术生态却在许多方面表现出明显的割裂感。这种割裂在存储、格式、流程、框架、平台等方面尤为突出,这使得开发者在实现端到端的数据处理和 AI 工作流程时,常常面临着重重挑战。
因此,作为开源数据湖仓项目 LakeSoul,我们致力于寻求新的解决方案,以便更有效地融合大数据和 AI,消弭其中的隔阂。我们采用了 Data + AI 一体化的技术实现方式,让用户可以快速打通从数据处理到 AI 模型的应用,实现数据湖和 AI 大型模型之间的双向奔赴。

1. 理想的融合
1.1 Data+AI 一体化的设计
LakeSoul 技术架构成功实现了Java 大数据生态和 Python AI 生态的完美结合,以此为基础,支持诸多 AI 框架的训练和推理。同时,LakeSoul 框架以其强大的数据管理和计算能力,提供了一套具有广泛适用性的解决方案。其支持的大数据计算引擎包括但不限于 Spark、Flink、Presto 等,满足常见的流、批计算和 BI 分析的需求;同时,LakeSoul 也与 AI 和数据科学的计算框架,如:PyTorch、Pandas、HuggingFace、Ray 等,实现了原生对接。
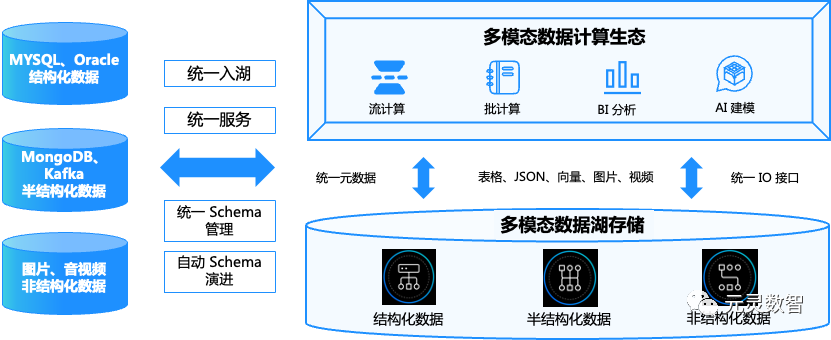
1.2 为 AI 模型提供坚实数据基础
LakeSoul 架构以其高效稳定的数据处理能力,轻松应对 TB 级别的大规模数据,无论是结构化数据还是非结构化数据。这种能力对大模型的训练和推理至关重要,因为提升大模型的推理效果,离不开大量的训练数据的支持。此外,LakeSoul 架构的高性能 Native IO 设计,可以确保大模型训练的效率,进一步提升其在 AI 领域的竞争力。
1.3 轻松解锁多模态数据的潜力
2. 应用案例
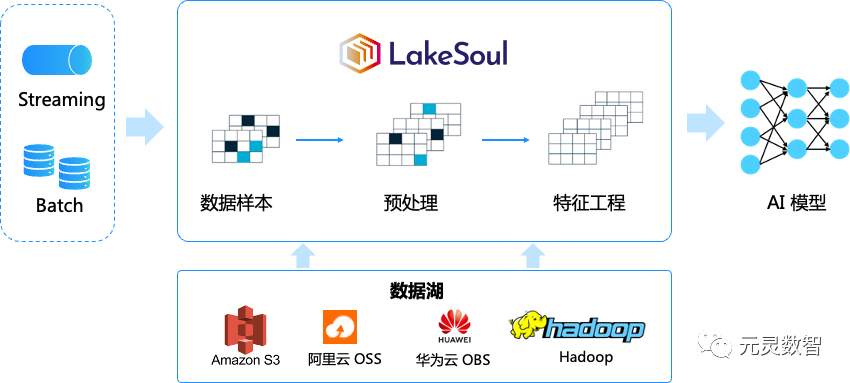
基于 LakeSoul 的 AI 建模过程如下图所示。LakeSoul 具备同时处理流数据和批数据的能力,并支持在数据湖上进行样本预处理,通过 Native IO,LakeSoul 能够直接连接 AI 模型。在接下来的部分,我们将详细介绍如何依托 lakesoul 湖仓平台、无缝衔接 Pytorch/HuggingFace 等 AI 生态,对模型的训练、推理以及应用等全流程提效。我们已将完整的代码发布在GitHub上,您可以通过以下链接访问:
https://github.com/lakesoul-io/LakeSoul/python/examples。
2.1 从一个二分类问题开始
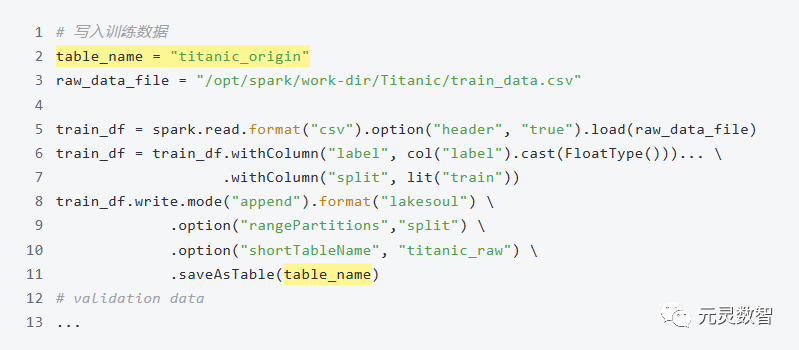
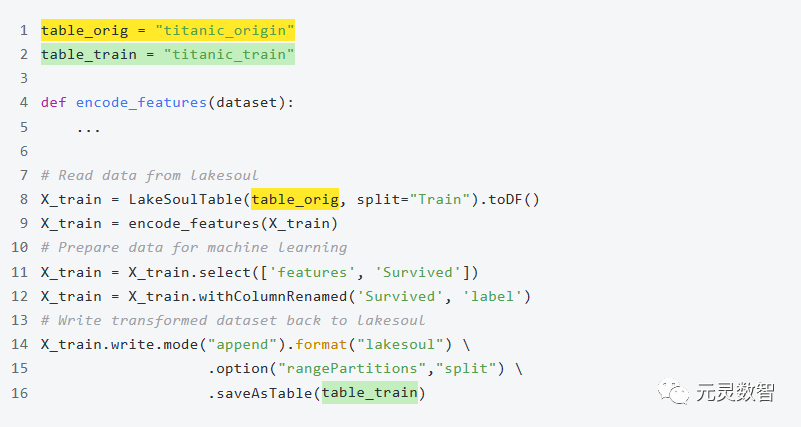
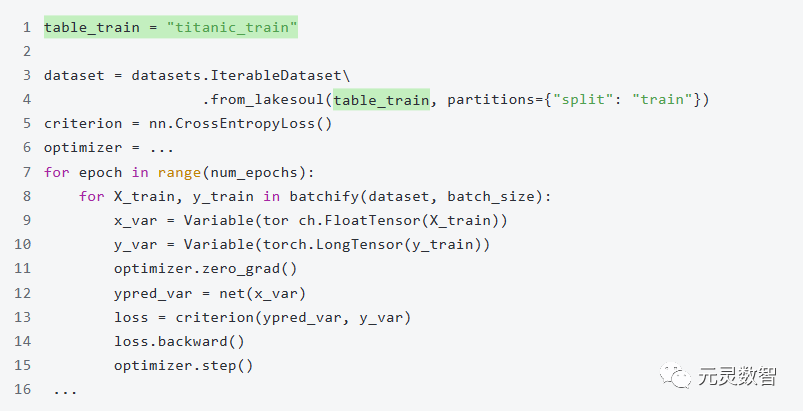
虽然在这个案例中处理的是静态数据集,但 LakeSoul 的设计理念和技术架构可以支持数据的实时更新、特征的实时更新,以及模型的在线学习。这个案例展示了 LakeSoul 在处理大规模数据集计算、特征工程、支持 AI 模型训练和验证的能力。
2.2 NLP 预训练模型微调
前面通过 Titanic 的例子已经说明了“数据入湖->预处理->模型训练”的流程,下面通过 IMDB 数据集训练一个情感倾向的模型,说明如何通过 HuggingFace 的 Trainer API 基于 Bert 模型(distilbert-base-uncased)来微调。

2.3 基于 CLIP 的图文互搜
前面 IMDB 的案例已经展示了如何利用 LakeSoul 和 HuggingFace Trainer API 训练模型。在这个案例中,我们将使用 Food 101 数据集,展示如何使用 CLIP 模型对样本进行推理,并实现图文互搜功能,处理的过程主要包括两个阶段:
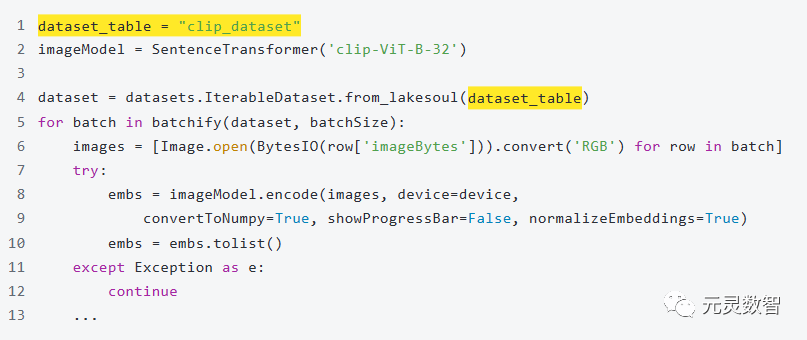
1. 模型推理:引入 HuggingFace 上的 CLIP 模型(clip-ViT-B-32-multilingual-v1),在这里 CLIP 模型用于对图像数据集中的图像进行推理,生成了每个图像的 Embedding:
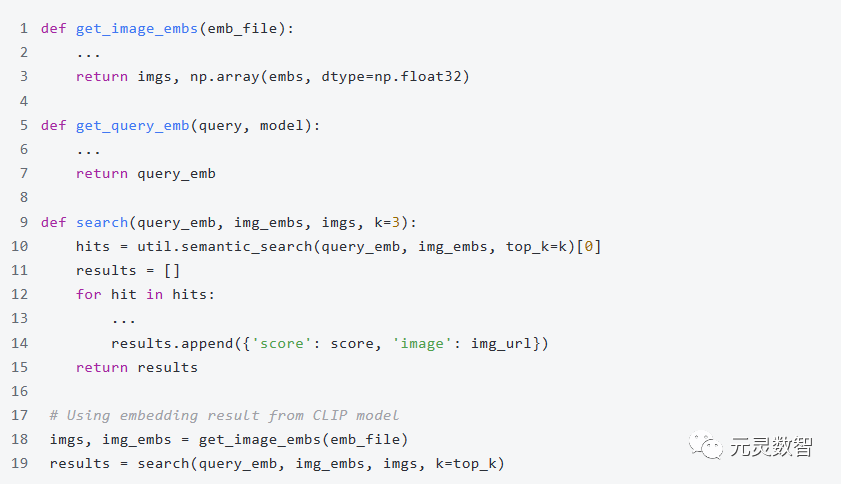
2. 语义搜索:具体而言,用户可以输入文本描述,系统则通过计算文本和图像的向量距离,返回最匹配的图像:
总结
在上一篇文章中,我们深入探讨了 LakeSoul 的 Data+AI 的设计理念,本篇文章中我们给了几个具体的实践案例。未来,我们计划发布更多的文章,详细介绍 LakeSoul 是如何与 PyTorch、HuggingFace、DeepSpeed、Ray 等领先的开源 AI 框架进行结合的。
本文转载自社区供稿内容,不代表官方立场。了解更多,请关注微信公众号"元灵数智":
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢