
点击下方卡片,关注「集智书童」公众号

最近深度学习算法的一个趋势是训练参数数量众多、在大型数据集上训练的大规模模型。然而,这些大规模模型在面对真实世界情境时的稳健性仍然是一个较少被探讨的话题。
在这项工作中,作者首先对这些模型在不同扰动和数据集下的性能进行基准测试,从而代表了真实世界的变化,并突出了它们在这些变化下性能的下降。然后,讨论了基于完整模型微调的现有稳健性方案可能不是一个可扩展的选项,因为非常大规模的网络可能会忘记一些期望的特性。最后,提出了一种简单且具有成本效益的方法来解决这个问题。它涉及到对较小的模型进行稳健化,以较低的计算成本,然后将它们用作调整部分这些大规模网络的教师,减少整体计算负担。
作者在各种视觉扰动下评估了作者提出的方法,包括ImageNet-C、R、S、A数据集,以及用于迁移学习、Zero-Shot评估设置在不同数据集上的性能。基准测试结果显示,作者的方法能够高效地使这些大规模模型具有稳健性,需要显著较少的时间,并且还保留了原始模型的迁移学习和Zero-Shot特性,这是现有方法都无法实现的。
大规模的深度神经网络在大规模数据上的训练已经彻底改变了现代人工智能时代。它们在解决高度重要的实际问题方面非常有效,包括目标检测、Zero-Shot分类、图像分割、图像生成等许多应用 。
尽管大型模型在许多视觉问题上取得了令人印象深刻的结果,但它们在分布转移下的可靠性,例如光照变化、地理变化、摄像机属性等,仍然是一个未充分研究的领域。本文首先研究大型模型在分布转移下的行为。作者分析了受欢迎的模型在合成图像扰动、自然分布变化、不同风格的图像和数据集变化下的表现。作者的分析涵盖了不同规模、不同架构家族(Transformer或CNN)和训练模态(单模态或多模态)的模型,结果表明它们在分布转移下表现脆弱。
这个分析引出了一个问题:作者是否可以在不牺牲大视觉模型的原始特性的情况下,使其具备稳健性?关键是要同时保持在原始数据集上的准确性,在转移数据上提高稳健性,并保留大模型的迁移学习能力。此外,在训练和推理过程中提高计算效率也是有益的。
虽然之前的一些工作可以使大规模模型具备稳健性,但它们不具备上述所讨论的所需特性。一种方法是对模型进行微调。这通常要么在合成扰动下表现不佳,要么需要大量的训练时间。另一条研究方向可能是使用高级的数据增强技术(例如aug-mix、pix-mix)。它们在合成扰动和数据的自然变化下都是有效的。然而,它们需要更多的计算时间,并导致大模型忘记其原始特性和迁移学习特性。图1显示了最近提出的两种稳健性方法的这种分析的帕累托前沿图。
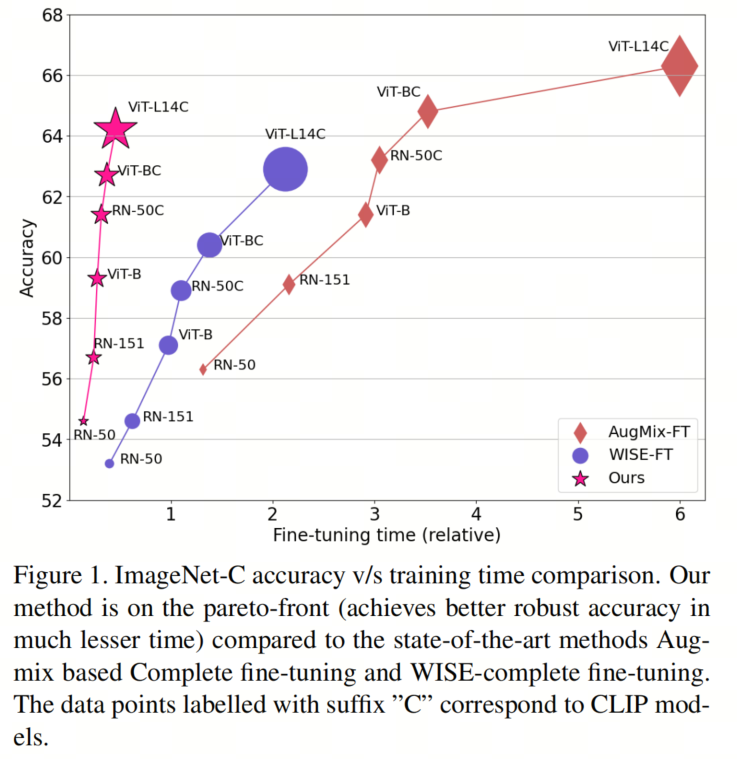
为此,作者提出了一种知识传递方法,以使大模型具备上述所有所需的特性。它高效地使大模型具备稳健性(参见图1)。作者采用了一种即插即用的方法:插入一个额外的小型稳健模块,并只更新现有大模型的一小部分。
为了实现稳健性,作者探索了一个新的方向:一个相对较小但稳健的模型向大模型传递稳健知识。虽然这提供了一个新颖的知识蒸馏方法,但直接应用会导致大模型忘记其原始特性。对于确保在模块中保持准确性、在稳健模块中引入稳健性,并在测试时选择正确模块这一具有挑战性的任务,作者提出了一种新颖的基于不确定性的知识蒸馏技术。这使作者能够实现所有所需的目标。由于作者的方法只涉及到大网络的一小部分的更新,因此它具有较低的训练延迟。
据作者所知,这是第一次使用这样的设置,涉及从较小模型到大模型的知识传递。此外,值得注意的是,可以使用之前的工作来使较小模型具备稳健性,比如高级的数据增强方法。
作者在第5节中对作者的方法在ImageNet数据上的各种分布变化进行了评估。这包括ImageNet-C、ImageNet-R、ImageNet-A、ImageNet-sketch、ImageNet-V2。作者还在ObjectNet及其扰动版本ObjectNet-C上进行了评估。作者展示了多模态(各种CLIP模型)和单模态(各种架构,包括ResNets和Vision Transformers)的结果。
与此同时,作者还在其他数据集上以迁移学习设置测试了作者的方法,以进一步分析模型的所需特性是否得到恢复。在所有这些情况下,作者的方法在稳健准确性方面优于之前的方法,同时在 clean 准确性方面表现良好。同时,它具备所需的特性,如迁移学习能力,并且在训练和推理过程中具有高效性。
近年来的研究表明,在大型数据集上训练大模型,例如视觉Transformer,可以显着提高准确性。最近一些工作 对这些模型进行了稳健性评估。此外,这些大型模型可以在单模态设置或多模态设置下进行训练。尽管它们在多个下游任务上表现良好,但对这些大型模型的任何修改都可能导致其中包含的知识被遗忘。相反,作者提出了一种方法,允许调整模型参数而不牺牲其属性。
已经提出了几种高级的数据增强技术,以提高基于深度学习的模型的稳健性。示例包括cut-out、cutmix、mixup、augmix、pixmix等。此外,最近提出的方法WISE通过插值微调和原始模型参数来提高稳健性。
通常,这些技术是计算密集型的过程,还会导致修改主网络参数,这可能会导致这些大型模型遗忘其原始特性。在作者的方法中,作者使用了一些这些先进的数据增强技术来使作者的教师网络具备稳健性。作者确保作者的稳健方法不会牺牲大型模型的特性,同时在计算效率方面也具备优势。
它涉及将知识从一个大型网络传递到一个较小的网络,通过最小化学生和教师网络的预测逻辑分布之间的距离来实现。在标准下游数据集上,它被证明是非常有效的。在所有这些知识蒸馏应用中,知识都是从较大的网络传递到较小的网络。相反,作者提出了一种方法,通过从较小的(教师)网络传递知识,来使较大的网络具备稳健性。
在本节中,作者分析了不同形状和大小的模型在不同训练设置(单模态或多模态)下,以及在合成和自然扰动下的图像分类性能。特别是,作者对多模态模型(视觉-语言)与单模态模型(仅图像)的行为进行了对比。
在单模态设置下,作者分析了在ImageNet上训练的ResNet-50、ResNet-101和ResNet-150,ViT-small、ViT-base和ViT-large模型。在多模态设置中,作者分析了包括ResNets的CLIP模型:CLIP-RN50和CLIP-RN101,以及Transformer:CLiP-ViT B/16、CLiP-ViT B/32。
作者还分析了在大型数据集上训练的自监督单模态模型与仅在ImageNet上预训练的模型之间的差异。为此,作者使用了最近提出的Mask自编码器和DINO V2 模型,这些模型在表示学习中被证明是非常有效的。作者分析了两种体系结构,ViTB/16、ViT-B/32用于MAE,ViT-B/14用于DINO V2。
作者在各种ImageNet的变体上评估了这些模型:ImageNet-Corrupted(ImageNet-C)、ImageNet-Rendition(ImageNet-R)和ImageNet Sketch(ImageNet-S)数据集。
对于自然变化,作者使用了包含自然对抗样本的ImageNet-Adversarial(ImageNet-A)。此外,作者还在ObjectNet数据集上评估了这些模型以及ObjectNet的扰动版本ObjectNet-C,作者通过将ImageNet-C的所有15种数据损坏应用于ObjectNet数据生成了这些扰动。
在单模态情况下,作者在ImageNet-C、ImageNet-R、ImageNet-S(补充资料)、ObjectNet和ObjectNet-C数据集上评估了timm上ImageNet训练的模型。此外,作者在Linear Probe和Zero-Shot设置下评估多模态模型。对于Linear Probe设置,请参阅CLIP论文。它在ImageNet数据集上进行,然后在所有这些数据集上进行评估。
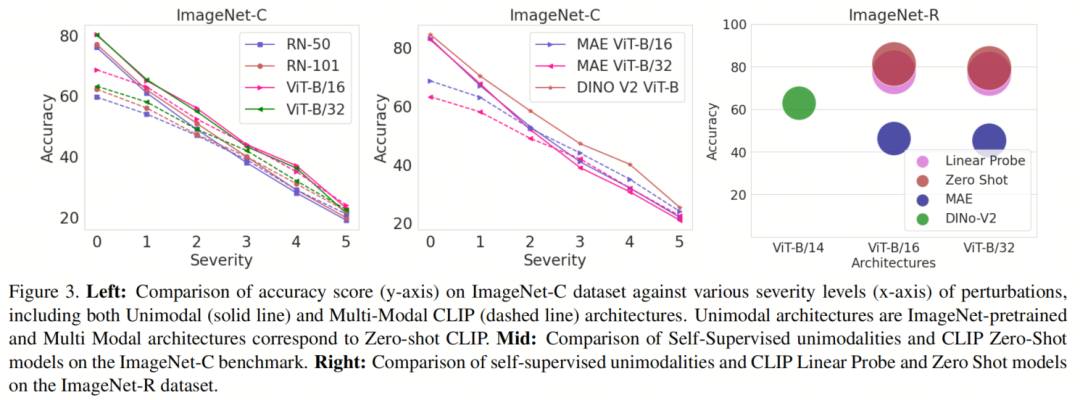
图3(左)显示了不同架构在不同严重程度下对ImageNet-C数据的分析,其中包括ImageNet预训练的单模态模型(实线)和Zero-ShotCLIP模型(虚线)。当严重程度增加时,它们都表现出类似的性能下降,尽管起始准确性不同,但在高严重程度下趋于相似的值。这意味着在高度扰动的情况下,它们都会表现出类似的性能下降。
然而,基于CLIP的模型的稳健性稍高。一个可能的原因是它们从较低的 clean 准确性值开始,这归因于它们的Zero-Shot性质。
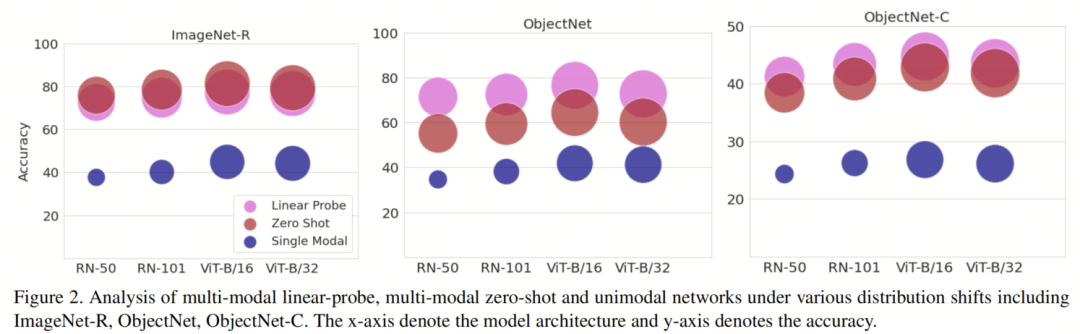
图2显示了不同CLIP模型架构在ImageNet-R、ObjectNet和ObjectNet-C数据集上的分析,包括Linear Probe和Zero-Shot设置,以及单模态(ImageNet预训练)对照组。在Linear Probe设置下,模型在ImageNet-R和ObjectNet数据集上保持准确性,但在ObjectNet-C上表现显著下降。
另一方面,Zero-Shot模型在ImageNet-R上的准确性更高(与ImageNet相比),在ObjectNet数据集上略低,并且在ObjectNet-C数据集上表现与Linear Probe设置相似。从结果中可以观察到,Zero-Shot CLIP在ObjectNet-C上比Linear Probe CLIP更具稳健性,这体现在准确性相对下降上。
此外,尽管Linear Probe是在ImageNet上进行的,但Zero-Shot CLIP模型在ImageNet-R数据集上表现更好。对于单模态情况,所有模型的准确性都显著下降,在所有变化下表现都比CLIP Linear Probe和Zero-Shot模型差得多。
作者进一步分析了另一种情况,即单模态模型是在大型数据集上以自监督方式训练的,而不是在ImageNet上预训练的情况。为此,作者使用了最近提出的Mask自编码器和DINO V2模型,这些模型在表示学习中被证明是非常有效的。
图3(中和右)提供了它们在ImageNet-C、ImageNet-R数据集上的稳健性分析,以及与CLIP模型的比较。对于ImageNet-C,与图3(左)类似,这些模型在最高严重程度下也趋于与多模态模型相似,并且从严重程度1到5的相对下降更高。在ImageNet-R上,同样,多模态模型表现明显优于单模态模型。这些观察结果与图2中的情况类似。
从所有的图表中可以观察到,在ImageNet-R、ObjectNet和ObjectNet-C数据集上,多模态网络要比单模态网络表现得更好,可以被视为在这些设置下更为稳健。然而,在ImageNet-C的扰动下,尤其是在更高的准确性水平下,它们也会出现显著的准确性下降。再次强调,所使用的所有架构在准确性下降方面表现相似。
此外,Zero-Shot多模态网络在分布转移存在时(比较从ImageNet到其他数据集的准确性下降)似乎比Linear Probe的多模态网络更为稳健。在架构方面,Transformer模型似乎比ResNets更为稳健,无论是在单模态还是多模态情况下,这是因为它们具有更高的准确性。
作者的目标是使大型预训练计算机视觉模型在不牺牲其原始性能的情况下具备稳健性。这是至关重要的,因为作者希望模型在领域内和领域外的环境中都能表现良好。计算效率也很重要,因为预训练已经需要大量的计算资源,所以高效的技术更加灵活。
一种流行的增强模型稳健性的技术是使用高级数据增强技术,如aug-mix或 pix-mix。这涉及到使用增强的数据集来微调模型参数,并且在提高稳健性方面非常有效。然而,这种微调是次优的,因为模型可能会忘记其原始表示特性,同时需要大量的计算资源。
为此,作者提出了一种新颖的插拔式方法。首先,作者在模型中插入了一个原始的分类头,一个稳健头和一个组合头。其次,作者从一个小的稳健教师(相对于大的预训练模型来说是小的)中引入稳健性到稳健 Head 。然而,这留下了一个具有挑战性的任务,即确保 clean Head 保留 clean 的准确性,同时在稳健 Head 引入稳健性。
更重要的是,作者需要确保这些 Head 在测试时能够被正确选择。第三,作者提出了一种新颖的基于不确定性的知识蒸馏技术,它允许作者实现所有所需的目标。下面讨论了所提出的方法,同时也在图4中进行了展示。
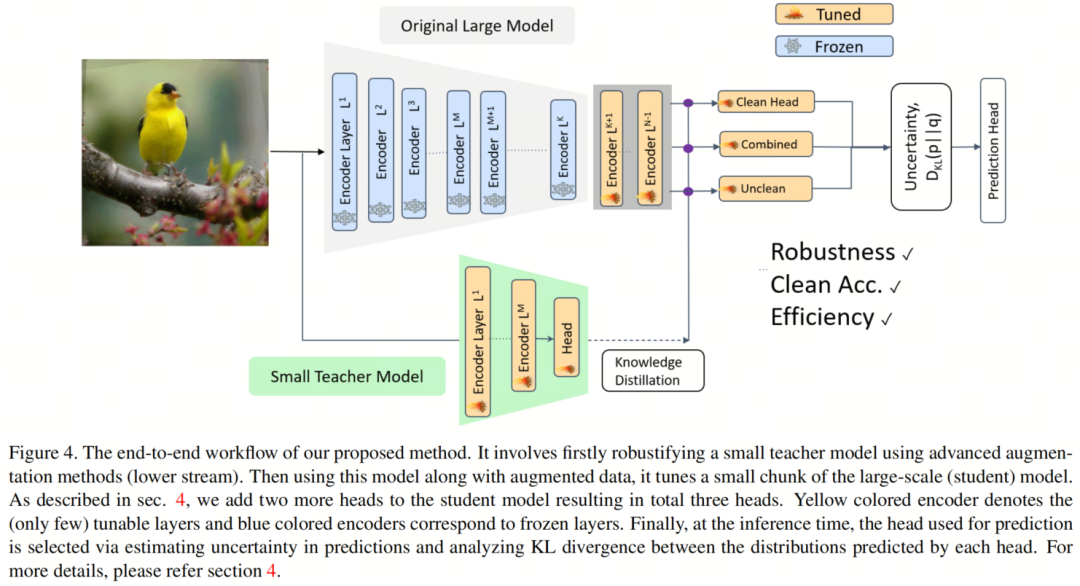
让作者将原始模型表示为。该网络可以看作由三个组件组成:是从初始层到第K层的Backbone网络,是从第(K+1)层到第(N-1)层的共享可调节部分,是从第N层到末尾的预测 Head 部分(参见图4)。因此,整个网络可以表示为:
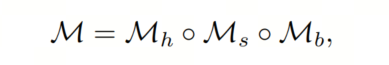
其中、、和分别表示各组件参数。
为了解决稳健性传递与保持 clean 准确性、迁移学习等所需特性之间的问题,作者在共享可调节部分的顶部插入了两个额外的预测 Head 。这导致了总共三个分类 Head ,如图4所示。
作者的方法的核心是使用知识蒸馏(KD)框架来为大型网络引入稳健性。在标准的KD中,通常是从大型网络传输知识到小型网络。
相反,作者提供了KD的一个新颖视角。作者表明,稳健性可以从小型稳健模型传递到大型模型。对于小型稳健教师(表示为Mt),作者采用小型的图像分类模型,并使用标准技术(增强技术AugMix 和DeepAugment的组合)来使其具备稳健性。小型教师对于高效的方法是必不可少的。
虽然作者引入了一个稳健 Head 并计划从小模型中引入稳健性,但确保 clean Head 保留 clean 准确性、稳健 Head 学习稳健性,并在测试时正确选择 Head 是一项具有挑战性的任务。接下来,作者将讨论一种实现这些目标的新策略。
作者更新共享可调节参数和预测部分的参数,同时保持Backbone网络冻结,如图4所示。作者在这里使用了与用于使小(教师)模型具备稳健性的相同的增强训练数据,表示为,其中包含 clean 和增强样本样本。鉴于增强的训练数据和稳健网络,模型的参数估计可以写成:
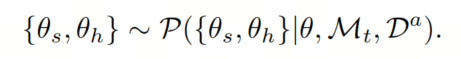
接下来,作者将讨论优化知识和稳健性蒸馏(稳健准确性)的策略。请注意, clean Head 的教师是初始大模型的副本,以保持原始特性。这个估计是通过使用分类损失和蒸馏损失 的加权组合来完成的,其中,表示预测网络的参数,表示教师模型的参数,表示学生模型的参数。
与 clean Head 相对应的 Head 部分(具有参数)仅使用 clean 样本进行更新。组合 Head ()同时使用 clean 和 unclean 样本,而 unclean Head ()仅使用增强样本。因此,对于在随机抽取的数据批次中的 clean 样本,由于 clean Head 部分预测而更新的参数集合是,组合 Head 部分是。
类似地,对于增强样本,由于 unclean Head 部分预测而更新的参数集合是,组合 Head 部分是。
因此,更新关于 clean 示例的最终损失函数(表示为)如下:
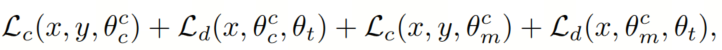
类似地,对于 unclean 示例(表示为),损失函数如下:
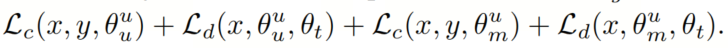
最终,对于给定的数据批次,成本函数L可以写成:
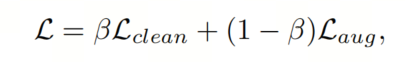
其中表示 clean 示例,表示 unclean 示例。
作者需要一种可靠的 Head 选择方式,以便在 clean 示例(保持 clean 准确性)上选择 clean Head ,而在发生转移的示例(稳健性)上选择 unclean Head 。
对应于每个 Head 的预测中建模不确定性可以成为选择最终 Head 作为最可靠 Head 的方法。在 clean 示例上, clean Head 应该是最可靠的,类似地,在增强示例上, unclean Head 应该是最可靠的。
为此,作者使用了Dropout,因为它允许贝叶斯近似。在训练时,作者使用dropout正则化来更新M的可调节部分,从图4中的编码器开始。这可以通过在现有实现中将dropout率设置为非零分数来完成。这个dropout是所有3个 Head 的一部分。
在推理时,作者激活每个 Head 的dropout,以估计来自模型的预测分布,而不是点估计。作者通过每个 Head 进行次前向传播,然后对于每个 Head ,计算输出的均值和标准差,并将它们用作模型预测分布的均值和标准差。这被称为蒙特卡洛Dropout。最后,作者直接使用标准差作为不确定性的度量()。
现在,有一种情况可能是,对于嘈杂的输入, clean 模型完全崩溃,并预测具有非常低(高度确定性)的随机输出。
考虑到测试分布是未知的,这可以是一个具有显著概率的情况。为了处理这种情况,作者还在推理时仅使用KL散度来计算 clean Head 和 unclean Head 的每个 Head 的预测分布与组合 Head 之间的距离。这导致了以下目标,用于选择最终的预测 Head :
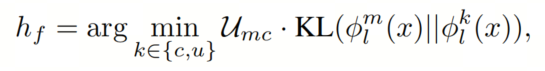
其中、、分别对应于 clean 、组合、 unclean Head ,、、是相应的预测函数。因此,通过eq. 6中的 Head 选择度量,可以选择 clean / unclean 的所需 Head 。
请注意,第三个 Head 在这里只是为了通过 Head 选择度量中的KL散度项来选择 clean Head 和 unclean Head 之间的正确所需 Head 。
上述描述的方法可以直接应用于单模态和多模态的视觉编码器,通过附加一个类似于Linear Probe设置的分类 Head 。对于这一点,作者进一步将作者的方案适应于这些多模态网络的Zero-Shot设置,它包括视觉和文本编码器。
为此,作者在文本编码器的存在下应用作者的方案,并使用视觉编码器嵌入和从文本编码器获得的提示嵌入(,其中Y表示与数据中的所有类对应的所有提示集)之间的点积, = · ,作为分类和蒸馏损失的模型预测。
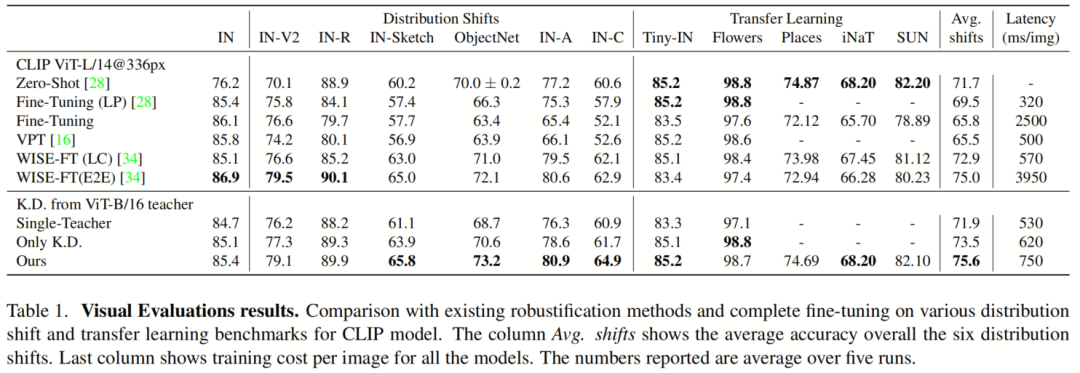
表1显示了作者的方法与各种分布转移情况下的Baseline方法在ImageNet数据集上的比较,以及转移学习能力和每个图像的训练时间。它使用CLIP ViTL/14@333px模型来评估所有方法。作者的方法使用ViT-B/16作为教师模型。可以看到,即使WISE-E2E在两种转移情况下表现最佳,但它在转移学习任务下表现不佳(准确度下降1.8和1.4),这是E2E微调方法的瓶颈。
另一方面,像VPT这样需要较低训练时间的方法在分布转移下表现不佳(与Zero-Shot模型相比,平均准确度下降超过5%)。另一方面,在四个分布转移任务中表现最佳,将准确度提高了2%(ImageNet-C),并且能够在转移学习实验中获得与Zero-Shot模型相同的准确度,并且比WISE-E2E快得多(大约快5倍)。
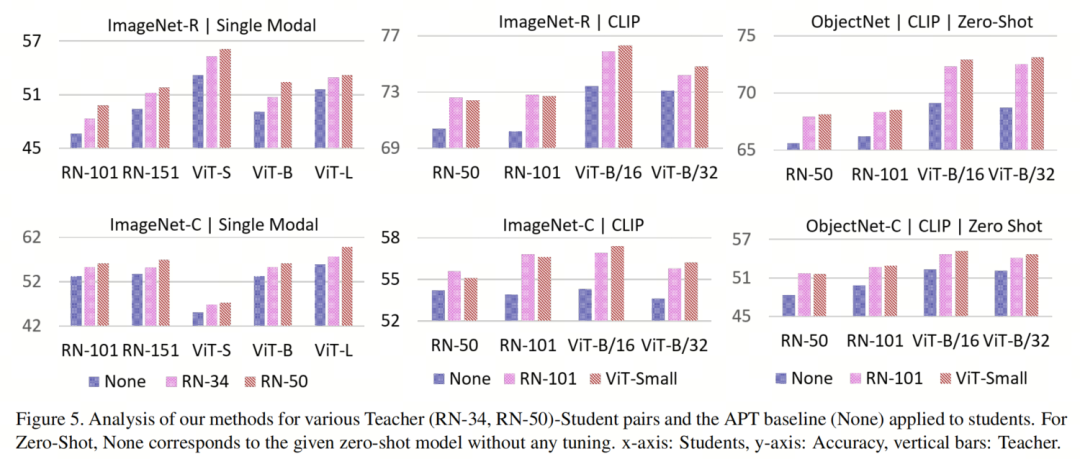
作者进一步针对作者的方法与作者定义的APTBaseline对各种模型架构进行评估,教师和学生。图5(左上和左下)显示了此分析,四个CLIP模型(RN-50、RN101、ViT-B/16和ViT-B/32)的视觉编码器作为学生,单模态网络作为教师在ImageNet-R和ImageNet-C数据集上评估。教师为None的行对应于APTBaseline。对于ImageNet-C,大多数情况下,准确度提高了超过3%,至少为2.5%。这种知识传递不太依赖于学生或教师的架构家族,因为在CLIP ViT/ResNet学生(将CLIP RN-50与ResNet-101或ViT-Small更新时观察到的改进小于0.3%)的教师上提供的改进只有微小的差异。
对于ImageNet-R,作者的方法提供了大多数情况下的2.0%增益,最大为2.9%,与APTBaseline相比。有关教师模型的准确性,请参阅附录。
现在,作者将作者的方案应用于使用文本和视觉编码器的多模态CLIP网络,以完成Zero-Shot设置,如第4节所讨论的。表2显示了在这种设置下作者的方法和Baseline的结果,适用于ImageNet数据的各种分布转移以及对新数据集(数据集转移)的Zero-Shot评估。
在这里,作者再次使用ViT-B/16作为作者方法的教师。可以看到,作者的方法在所有分布转移情况下表现最佳,最小差距为1%(IN-R),最大为4.5%(IN-C)。此外,它是5个数据集转移中4个中性能最好的Zero-Shot方法,最大改进为ObjectNet-C的3.9%。
这表明,与完全微调相比,它提高了模型的Zero-Shot性能,后者在表2中观察到在数据集转移下性能下降。
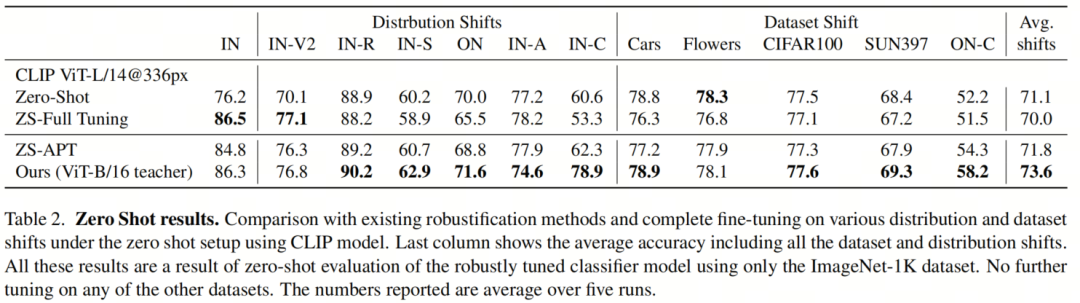
表5(顶部中部和底部中部)显示了在这种情况下对ImageNet-R、ImageNet-C数据集上的各种学生(单模态)和教师(CLIP)对的进一步准确性分析。评估是在ObjectNet数据集及其受扰动的版本ObjectNet-C上进行的。在这里,Baseline(以None为教师的行)只是Zero-Shot大规模网络(使用文本和视觉编码器),不使用调整集。
同样,在数据集转移的Zero-Shot设置下,作者的方案提高了相当多的准确性,至少提高了2.6%。再次强调,它不受教师网络的架构或模态性的影响(例如,CLIP RN-50学生和RN-101、ViT-S教师在图中)。

由于作者的方法在现有模型之上附加了额外的 Head ,尽管非常小,因此作者还分析了它在朴素模型之上增加的推理时间开销。作者观察到这个开销非常小。例如,表1中使用的CLIP ViT-L/14模型,Baseline的GFLOPs为81.17,而作者的GFLOPs为83.7(增加了3%)。
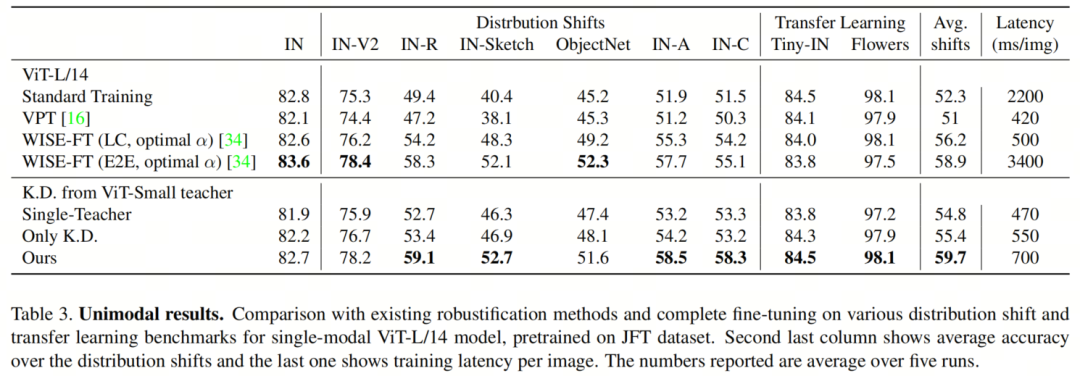
现在,作者将分析作者的方法,针对单模态学习网络的情况,将其与所有Baseline在不同的分布转移/转移学习任务上进行比较,就像多模态VE设置一样。表3显示了这些比较结果。
在这里,作者的方法再次在6种分布转移中脱颖而出,其中有四种的最小增益为0.8%,最大增益为3.2%。此外,正如表3所示,作者的方法还能够保持转移学习能力,而其他Baseline(VPT和WISE)则遭受损失,这些Baseline是针对Tiny-IN、Flowers、PLACES205、iNaturalist2021、SUN397数据集的原始模型的。
图5(最后一列)显示了使用ViT和ResNet架构的各种Learner-Teacher对进行比较的情况。同样,Teacher为None的行对应于APTBaseline。
对于ImageNet-C的大多数情况,作者的方法将准确性提高了超过3%,与Baseline相比。类似地,在ImageNet-R数据集上,它对于大多数情况都显示出大于5%,最大值为3.2%(RN-50教师和RN-101学生)。
此外,增加教师模型的大小(从RN-34到50)会提高性能。最后,作者比较的方法和Baseline都在受扰动的数据集上取得了显着的性能提高(特别是ImageNet-C),与ImageNet预训练模型相比。
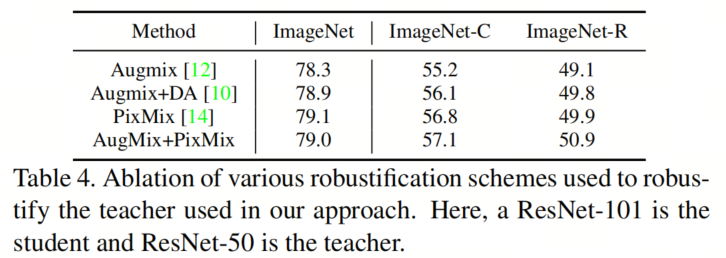
现在,作者比较了在作者的方法中使用不同的教师模型的增强方案的效果。作者局限于基于增强的方案,如AugMix、PixMix、DeepAugment等。
表4显示了在ResNet-101学生模型使用ResNet-50教师模型的单模态设置下进行的这种比较的结果。使用PixMix或与AugMix结合确实可以将准确性提高约1-1.5,超过了作者当前的技术(Augmix+DeepAugment)。作者的方案表明,可以有效地将教师模型的增益传递给学生。
作者首先从涉及蒙特卡洛辍学(MCD)不确定性和KL散度计算的推断方案的消融分析开始(参见论文第4.3.2节)。除了准确性之外,作者还定义了一个新术语,用于分析这些推断时间的消融分析。对于给定的数据集,它是测试集中被分配正确 Head (在分布内为 clean ,在分布/数据集转移时为非 clean )的示例的比例。作者用Fcorrect表示它。作者首先分析KL散度的重要性,然后将作者提出的方案与推断时没有任何KL散度计算的变体进行比较。
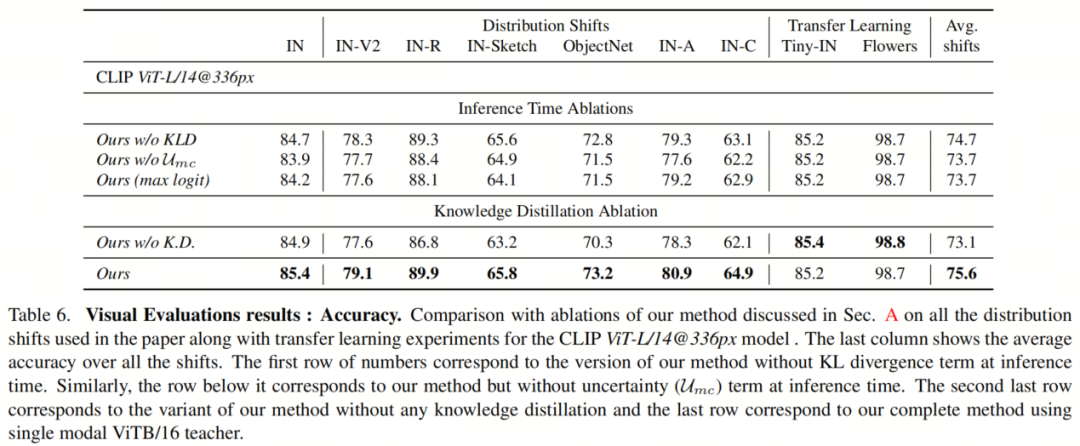
表6显示了作者的方法在论文中用于视觉评估设置的所有分布转移数据集上,在推断时使用和不使用(w/o)KL散度计算的分析。表中没有KL散度项的变体在表中表示为Ours w/o KLD。它还显示了转移学习实验的结果。学生模型对应于多模态CLIP ViT-L@333px网络,而单模态ViT-B/16被用作教师。表的最后一列包含了所有分布转移数据集的平均准确性。可以看到,与这种变体相比,使用作者的完整方法在所有分布转移情景中都有小幅增益(平均增益为0.9%)。因此,在推断时使用KL散度进一步纠正了模型性能。
此外,表7显示了在使用的所有分布转移数据集上对Fcorrect指标的分析。在这里,也观察到了明显的差异,这意味着KL散度在决定输入的正确 Head 方面有很大帮助。接下来,作者考虑了项的消融分析。
表6中还显示了关于的类似分析,与Ours w/o 对应的行表示这种情况。再次,去除不确定性组件会导致性能下降,但下降幅度比去除KL散度组件大(与推断时去除KL散度项相比,平均下降1.9%)。
因此,这两个组件对于最优预测都是必要的。此外,从表7中显示的Fcorrect分析可以看出,使用这个项在决定正确的 Head 方面有很大帮助,而且影响比KL散度项更大。
作者还将作者的 Head 选择方案与另一种情况进行比较,即在推断最终分类 Head 时使用 clean 和非 clean Head 的预测置信度,而不是KL散度或不确定性。表X还包含了这种方法的结果,该方法在行Ours(max logit)中显示。同样,作者提出的 Head 选择方案明显超越了它。
作者现在讨论了作者工作中提出的用于调整学生模型参数的知识蒸馏(KD)模块(见论文第4.3节)的重要性。为此,作者定义了作者的方法的另一个变体,具有多头架构,但没有任何KD。表6还显示了使用与上述情况相同的模型和场景进行此案例的分析,与作者的方法进行比较。与Ours w/o K.D.相对应的行对应于这种消融。
可以看到,与这种消融相比,作者的方法显著提高了性能(在分布转移中平均2.5%),从而显示出知识传递的实用性。在 clean 数据集上,只观察到了性能的轻微提高。因此,作者方法中的知识蒸馏组件在诱导鲁棒性方面发挥了重要作用。在附录表8中显示了对不同师生对的这种消融与作者方法的进一步比较。再次可以观察到,使用知识蒸馏的作者方法在性能上有显著提高,最高可达2.6%。
[1].Efficiently Robustify Pre-Trained Models.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢