本文旨在为用户选择合适的开源或闭源语言模型提供指导,以便在不同任务需求下获得更高的性价比。
通过测试比较 LLaMA-2 和 GPT-3.5 的成本和时延,本文作者分别计算了二者的 1000 词元成本,证明在大多数情况下,选择 GPT-3.5 的成本更低、速度更快。基于上述评估维度,作者特别指出,LLaMA-2 等开源模型更适合以提示为主的任务,而 GPT-3.5 等闭源模型更适合以生成为主的任务。(编者注:本文发表于 7 月 20 日,在这之前 LLaMA 推理系统未充分优化,若按最新系统测试,本文结论未必再成立,但其分析方法仍有意义。)
本文作者 Aman Sanger 毕业于麻省理工学院数学与计算机科学专业,曾就职于谷歌、Bridgewater 和 you.com ,同时是 Abelian AI 联合创始人。
(本文由OneFlow编译发布,转载请联系授权。原文:https://cursor.sh/blog/llama-inference)
作者 | Aman Sanger
OneFlow编译
翻译|杨婷、宛子琳
LLaMA-2-70B 可看作是 GPT-3.5 的替代品,但如果你追求的是经济实惠,那么放弃 OpenAI 的 API 并不明智。
考虑到价格和时延:
我们不应将 LLaMA-2 用于强生成型(completion-heavy)工作负载。
相反,LLaMA 最适合分类等以提示为主的任务。以下情况也很适合选择 LLaMA-2:
其他任务中,GPT-3.5 相比 LLaMA 2 更便宜、更快速。
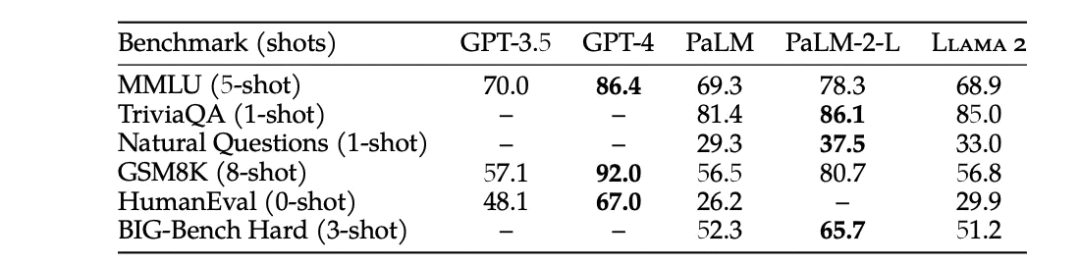
简单声明:使用 LLaMA 而非 GPT-3.5 的原因之一是微调(1)。不过,本文我们仅探讨成本和时延。我不会将 LLaMA-2 与 GPT-4 进行比较,因为前者更接近于一个 3.5 级别的模型。基准性能测试也支持这一观点:
图1:GPT-3.5 在所有基准测试中都优于 LLaMA(2)
在大致相同的时延下,我将通过比较使用 LLaMA-2-70B 和 GPT-3.5-turbo 提供模型服务(serving)的成本来证明上述论断。我们在 2 个 80GB 的 A100 GPU 上部署 LLaMA ,这是将 LLaMA 加载到内存中所需的最低配置(16 位精度)(3)。
在使用 2 个 A100 进行测试时,我们发现,LLaMA 生成词元的定价要比 GPT-3.5 高。我们推测,如果使用 8个 A100 GPU 进行测试,LLaMA 的定价会更有竞争力,但代价是无法接受的高时延。
另一方面,就提示词元而言,LLaMA 的价格比 GPT-3.5 便宜 3 倍以上。
1
Transformer 基础数学原理
通过一些简单的数学公式,我们得到以下关于 LLaMA-2 的公式。当序列长度为 N,批处理大小为 B 时:
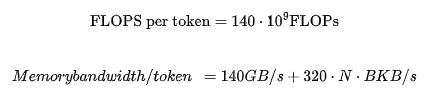
其中,140 是该模型参数的两倍,320 KB/s 通过算术推导而出。下文将解释如何得出这些数字。
另有一些论文和/或博客文章对 Transformer 的数学原理进行了出色的解释。针对推理部分,Kipply 的文章提供了很好的参考(4)。另外我认为,规模定律(5)推广了用于 Transformer FLOPs 的简化公式。
为验证这些数字,我们从 LLaMA 的架构细节开始。隐藏维度为 4096,注意力头的数量为 64,模型层数为 80,每个注意力头的维度为 128:
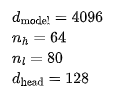
2
计算模型的浮点运算数(FLOPs)
前向传播的 FLOPs≈2P,P 为模型参数数量。模型中的每个参数都属于某个权重矩阵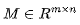 。对于每个输入词元,每个矩阵都会在矩阵乘中与表示该词元的向量进行一次运算。
。对于每个输入词元,每个矩阵都会在矩阵乘中与表示该词元的向量进行一次运算。
对于每个 M,我们用一个维度为 m 的向量 x 进行左乘。该向量-矩阵乘的总 FLOPs 为 2mn(6),即权重矩阵中元素(entry)个数的两倍。Transformer 所有权重矩阵中的元素总数就是模型总参数量 P,所以不考虑注意力机制,总共有 2P 个 FLOPs。
对于 LLaMA 等(相对)较短序列的大模型而言,注意力对 FLOPs 的贡献可以忽略不计。对于每个层和每个注意力头,注意力运算如下:
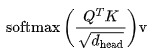
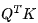 需要将一个
需要将一个 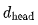 的向量与一个
的向量与一个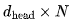 的矩阵相乘,得到
的矩阵相乘,得到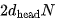 个 FLOPs。缩放因子(scaling factor)和 Softmax 可以忽略不计。最后,将 Attention 向量与 V 相乘需要额外的
个 FLOPs。缩放因子(scaling factor)和 Softmax 可以忽略不计。最后,将 Attention 向量与 V 相乘需要额外的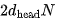 FLOPs。将所有注意力头和层的计算求和,得到
FLOPs。将所有注意力头和层的计算求和,得到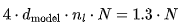 MFLOPs。因此,对于最大的 8192 序列长度,注意力运算仅占总体 140 GFLOPs 中的 10.5 GFLOPs。为简化计算可以忽略不计。
MFLOPs。因此,对于最大的 8192 序列长度,注意力运算仅占总体 140 GFLOPs 中的 10.5 GFLOPs。为简化计算可以忽略不计。
生成词元时,我们需要为每个词元的生成重新读取模型的所有权重和 KV 缓存。这意味着,为执行任一矩阵乘法,我们需要将每个矩阵的权重从 RAM 加载到 GPU 寄存器中。当有足够多的独特矩阵时,权重的实际加载而不是矩阵乘法本身会成为瓶颈,因此,让我们来比较一下提示词和生成词在模型中的处理路径。
为说明这一点,我们可以大致描述一个简单的 1 层 Transformer 生成一个批次词元的路径:1.读取输入嵌入矩阵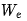 ,并为该批次中的每个输入计算相应的嵌入向量。2. 从内存中读取每个矩阵
,并为该批次中的每个输入计算相应的嵌入向量。2. 从内存中读取每个矩阵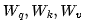 ,以计算每个输入的向量
,以计算每个输入的向量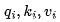 。3.注意力运算——这需要读取缓存的键(key)和值(value)。为每个输入返回一个向量。4.从内存中读取
。3.注意力运算——这需要读取缓存的键(key)和值(value)。为每个输入返回一个向量。4.从内存中读取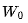 ,并与前一个 step 的输出相乘。5.从 step 1 中读取输出,并将其添加到 step 4 的输出中,然后执行 layernorm。6.读取
,并与前一个 step 的输出相乘。5.从 step 1 中读取输出,并将其添加到 step 4 的输出中,然后执行 layernorm。6.读取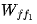 ,并进行乘法运算,以得到第一个前馈层的输出。7.读取
,并进行乘法运算,以得到第一个前馈层的输出。7.读取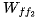 ,并进行乘法运算,得到第二个前馈层的输出。8.从 step 5 中读取输出,并将其添加到 step 7 的输出中,然后执行 layernorm。9.读取非嵌入层
,并进行乘法运算,得到第二个前馈层的输出。8.从 step 5 中读取输出,并将其添加到 step 7 的输出中,然后执行 layernorm。9.读取非嵌入层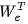 ,然后进行矩阵乘运算,得到批次中每个输入的词元对数概率。10.对下一个词元采样,并将其反馈到 step 1。现在来计算内存需求。在 step 1、2、4、6、7 和 9 中,我们大致读取了一遍模型的所有参数。(7)在 step 3 中,我们读取了每个批次元素的 KV 缓存。在所有 step 中,我们读取了相对于模型大小来说可以忽略不计的中间激活值。因此,内存带宽需求为模型权重+ KV 缓存。除 KV 缓存外,随着批次大小的增加,内存需求基本保持不变,稍后会对此进行详细讨论。请注意,这是单个词元的内存需求。通过 Transformer 处理提示词元的内存路径在处理提示时,我们会一次性读取模型的所有权重,但产生了注意力机制的内存开销。考虑一批序列通过相同的 Transformer 的大致路径:
,然后进行矩阵乘运算,得到批次中每个输入的词元对数概率。10.对下一个词元采样,并将其反馈到 step 1。现在来计算内存需求。在 step 1、2、4、6、7 和 9 中,我们大致读取了一遍模型的所有参数。(7)在 step 3 中,我们读取了每个批次元素的 KV 缓存。在所有 step 中,我们读取了相对于模型大小来说可以忽略不计的中间激活值。因此,内存带宽需求为模型权重+ KV 缓存。除 KV 缓存外,随着批次大小的增加,内存需求基本保持不变,稍后会对此进行详细讨论。请注意,这是单个词元的内存需求。通过 Transformer 处理提示词元的内存路径在处理提示时,我们会一次性读取模型的所有权重,但产生了注意力机制的内存开销。考虑一批序列通过相同的 Transformer 的大致路径:读取输入嵌入矩阵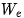 ,并为批次中的每个序列计算相应的嵌入矩阵。
,并为批次中的每个序列计算相应的嵌入矩阵。
从内存中读取 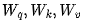 矩阵,以计算矩阵
矩阵,以计算矩阵 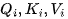 。
。
执行注意力运算。
从内存中读取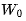 ,并与上一个 step 的输出相乘。
,并与上一个 step 的输出相乘。
从 step 1 中读取输出,并将其添加到 step 4 的输出中,然后执行 layernorm。
从内存中读取 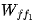 ,并进行乘法运算,得到第一个前馈层的输出。
,并进行乘法运算,得到第一个前馈层的输出。
从内存中读取 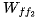 ,并进行乘法运算,得到第二个前馈层的输出。
,并进行乘法运算,得到第二个前馈层的输出。
从 step 5 中读取输出,并将其添加到 step 7 的输出中,然后执行 layernorm。
从内存中读取非嵌入层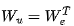 ,然后进行乘法运算,得到提示序列的词元对数概率。
,然后进行乘法运算,得到提示序列的词元对数概率。
在 step 1、2、4、6、7 中,我们读取了模型的所有参数。在 step 3 中执行了注意力运算,在这里,使用 FlashAttention 所需的内存带宽远低于读取模型权重(适用于合理的长度序列和批次大小)所需的内存带宽。在所有 step 中,我们读取了激活值,这些矩阵与模型大小(同样适用于合理长度的序列和/或批次)相比,可以忽略不计(8)。注意,这是所有词元的内存需求。总之,提示词处理的每个词元所需的内存需求显著较低生成词元,因为我们在提示词的序列维度上批量执行矩阵乘法。KV 缓存大小是神经网络中所有层、所有注意力头的所有键值对的总大小之和,对于所有先前的词元而言,每个词元和批次元素占 320 MB。LLaMA 2 决定移除多头注意力。但是,他们使用分组查询注意力代替多查询注意力,从而提高性能。这导致键和值的 8 个头(或组)变为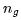 ,而不是通常多头注意力的 128 个头,以及多查询注意力的 1 个头。对于N 个词元,KV 缓存的大小为
,而不是通常多头注意力的 128 个头,以及多查询注意力的 1 个头。对于N 个词元,KV 缓存的大小为 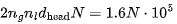 个头。使用 16 位精度就是 320N KB。给定批次大小为B,会得到 320 ⋅NB KB。对于较短的序列/小批次,第一项(term)占主导。否则,第二项要大得多。然而,由于我们只有 160GB 的内存,而模型占用了 140GB,在我们的实验中,KV 缓存将对内存带宽产生一定影响。简单起见,我们忽略了通信成本,因为模型的并行计算会显著增加复杂性。我们可以合理地假设它不会使计算减速过多(特别是我们将 LLaMA 拆分到 2 个 GPU 上)。提示处理或首个词元的时间是 Transformer 推理中最高效的部分,与 GPT-3.5 相比,预计其价格会降低 3 倍。对于具有P个参数和长度为N的提示的模型,处理提示的内存需求约为 2P 字节,而计算需求为 2PN FLOPs。由于 A100 可以处理 312 TFLOPs 的矩阵乘和 2TB/s 的内存带宽,当序列长度 N>156时,计算就成为了限制因素。(9)在 A100上,FLOPs 利用率可能接近 70% 的最大浮点计算执行率(MFU),约为200 TFLOPs。两个 80GB 的 A100 GPU 的成本约为每小时 4.42 美元(10),即每秒 $0.0012 美元。LLaMA 的每个词元需要的 FLOPs 为140 TFLOPs。考虑到 2 个 A100 GPU 的总 FLOPs 需求,可得出每秒的词元数为:与 GPT-3.5 每千个词元 0.0015 美元的价格相比,这个价格非常实惠!几乎降低了四倍!时延也很短!在我们的两块 GPU 上,批次大小为 1 时,应该能够在 170 毫秒内处理 512 个词元,并在 530 毫秒内处理 1536 个词元。我们可以通过实际数据来验证以上说法。我们使用了 HuggingFace 的 text-generation-inference 存储库的内部分支来测算 LLaMA-2 的成本和时延。
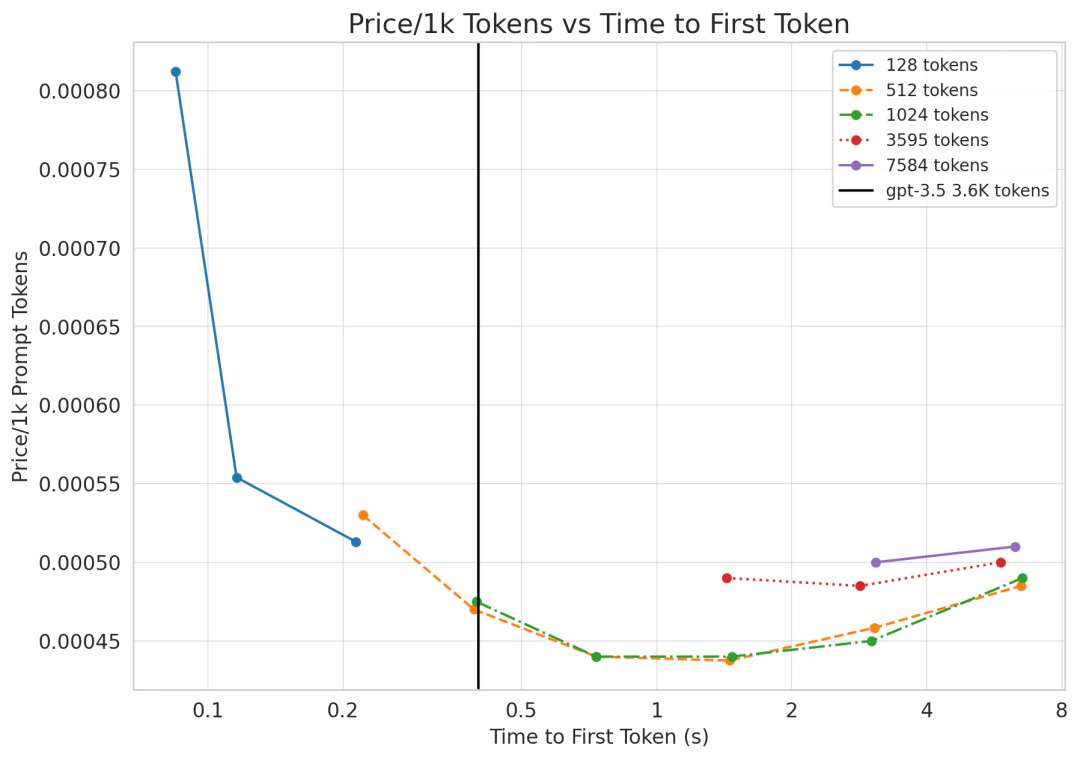
个头。使用 16 位精度就是 320N KB。给定批次大小为B,会得到 320 ⋅NB KB。对于较短的序列/小批次,第一项(term)占主导。否则,第二项要大得多。然而,由于我们只有 160GB 的内存,而模型占用了 140GB,在我们的实验中,KV 缓存将对内存带宽产生一定影响。简单起见,我们忽略了通信成本,因为模型的并行计算会显著增加复杂性。我们可以合理地假设它不会使计算减速过多(特别是我们将 LLaMA 拆分到 2 个 GPU 上)。提示处理或首个词元的时间是 Transformer 推理中最高效的部分,与 GPT-3.5 相比,预计其价格会降低 3 倍。对于具有P个参数和长度为N的提示的模型,处理提示的内存需求约为 2P 字节,而计算需求为 2PN FLOPs。由于 A100 可以处理 312 TFLOPs 的矩阵乘和 2TB/s 的内存带宽,当序列长度 N>156时,计算就成为了限制因素。(9)在 A100上,FLOPs 利用率可能接近 70% 的最大浮点计算执行率(MFU),约为200 TFLOPs。两个 80GB 的 A100 GPU 的成本约为每小时 4.42 美元(10),即每秒 $0.0012 美元。LLaMA 的每个词元需要的 FLOPs 为140 TFLOPs。考虑到 2 个 A100 GPU 的总 FLOPs 需求,可得出每秒的词元数为:与 GPT-3.5 每千个词元 0.0015 美元的价格相比,这个价格非常实惠!几乎降低了四倍!时延也很短!在我们的两块 GPU 上,批次大小为 1 时,应该能够在 170 毫秒内处理 512 个词元,并在 530 毫秒内处理 1536 个词元。我们可以通过实际数据来验证以上说法。我们使用了 HuggingFace 的 text-generation-inference 存储库的内部分支来测算 LLaMA-2 的成本和时延。图2:每个数据点表示不同的批次大小。对于提示词元, LLaMA 的定价始终比 GPT-3.5 低得多,但生成 3.6K 个词元时, LLaMA 的时延略落后于 GPT-3.5 的 0.4 秒。
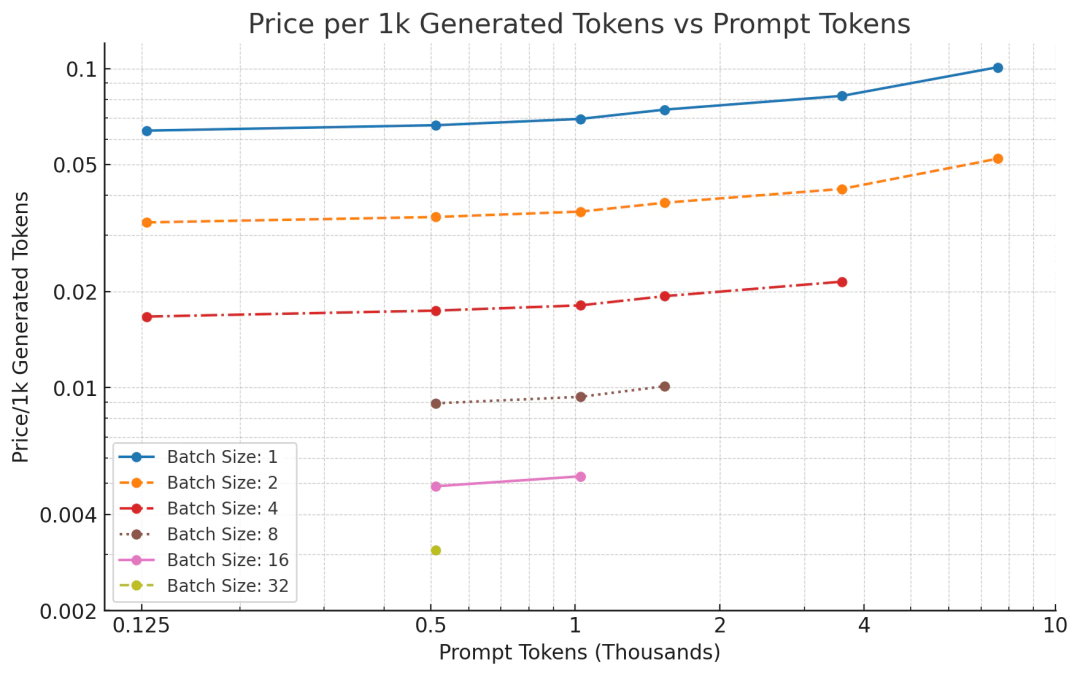
如图所示,相比 GPT-3.5 每千个词元 0.0015 美元的价格,LLaMA 每千个词元的价格要便宜得多!对于较长的序列,第一个词元的时延似乎稍显落后,但解决方案非常简单。如果将 LLaMA 在 8 个 GPU 上(而不是 2 个 GPU) 进行并行化处理,速度将会提升近 4 倍,这意味着在提示任务中,LLaMA-2 显著优于 gpt-3.5!理论上来说,LLaMA-2 在文本生成方面的词元生成价格与 GPT-3.5 相当,但实际上,LLaMA-2 词元的生成价格更高,竞争力更低。生成词元时,我们将从计算限制(compute-bound)转变为内存限制(memory-bound)状态(11)。假设批处理大小为 1,然后确定我们可以实现的吞吐量。每个 80GB 的 A100 GPU 的峰值内存带宽为每 GPU 2TB/s。然而,就像 FLOPs 利用率一样,在推理工作负载中(1.3 TB/s),你只能接近 60-70% 的利用率。由于 KV 缓存在小批次处理中可以忽略不计,我们在两个 A100 GPU 芯片上能够实现的吞吐量为:新价格的竞争力更低。以每秒 0.0012 美元的价格计算,可得出成本为:对于 GPT-3.5 级别的模型来说,这样的定价和速度非常糟糕。但前文关于批处理大小的注释表明,由于内存瓶颈如此严重,以至于我们可以增加批处理大小而生成速度不会降低。批处理越大,成本就越低。然而,我们不能无限地增加批处理大小,因为 KV 缓存最终会占用所有的 GPU RAM。幸运的是,分组查询注意力能够缓解这个问题。在词元数为 N,批处理大小为 B,精度为 16 位的情况下,缓存大小为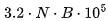 字节。以 4096 个词元为例,在批处理大小为 1 的情况下,缓存大小为 1.3 GB。在两个 A100 GPU 上,我们有 160GB 的空间。其中,模型占用了 135GB 的空间,仅剩下 25GB 的空间可用于 KV 缓存。由于内存存储的额外低效,对于较长的序列长度,我们最大的批处理大小约为 8。在速度(大约)增加 8 倍的情况下,我们预计每 1000 个词元的价格为 0.00825 美元。尽管这个价格仍高于 gpt-3.5-turbo 的价格,但已经更接近了。对于较短的序列长度(总计一千个词元),我们可以将批处理大小增加到 32,这意味着每 1000 个词元的价格为 0.00206 美元。理论上讲,相比 gpt-3.5-turbo 的价格,这个价格具有竞争力。另一个方案是,我们还可以增加 GPU 数量。通过租用 8 个 80GB 的 A100 GPU,我们获得了 1.28TB 的内存。去除模型权重后,我们仍有超 1TB 的内存可供 KV 缓存使用,这意味着,可以实现的批处理大小超过 512 个词元。值得注意的是,实际成本并不会降低 512 倍,因为 KV 缓存现在占用的内存带宽比模型尺寸大 8 倍,所以成本可能会降低近 64 倍。增加计算资源也可以解决时延问题。GPT-3.5 的吞吐量约为 70 TPS。如果将模型分布在 8 个 GPU 上而不是 2 个 GPU 上,那么吞吐量可以提高至约 74.4 个词元/秒。虽然我们在运行这个实验时并没有使用到 8 个 A100 GPU,但让我们来看看在 2 个 80GB A100 GPU 上的数值情况。图 3:对于所有数据点,我们在生成 512 个词元时测算了生成单个词元的价格然而,正如图表所示,尽管随着批处理大小的增加,每 1000 个词元的生成成本呈线性下降趋势,但与 GPT-3.5 每 1000 个词元 0.002 美元的定价相比,仍有一定差距,尤其对于较长的序列长度更是如此。使用大型批次大小进行生成可获得与 GPT-3.5 相媲美的定价,但会显著增加首个词元的生成时间。随着批次大小的增加,成本会线性降低,但首个词元的生成时间会线性增加。当批次大小为 64 时,我们可获得比 GPT-4 更好的价格优势,但会面临以下情况:对于只有 512 个词元的情况,首个词元的生成时间接近 3 秒!(12)当批次大小为 64 ,词元数为 3596 时,生成时间为 20.1 秒。(13)因此,相对于 OpenAI 的 API,LLaMA-2 更合适以下类型的工作负载:1. 具有大量提示但生成的词元很少或为零的场景——处理纯提示任务非常简单。2. 带有少量提示或没有提示的词元生成场景——我们可以调整批次大小到 64 以上,在不牺牲时延的情况下,获得与 gpt-3.5-turbo 相比具有竞争力的定价。增加批次大小需要有相对较大的工作负载,而这对于大多数创业公司来说是不可能的!对于大多数用户和大多数工作负载而言,使用量极不稳定。当然,一种解决方案是,根据需求自动调整 GPU 的扩展,但即使如此,平均每个 GPU 预计只能达到最大吞吐量的 50% ——尤其在考虑到冷启动时间的情况下。基于上述情况,我们建议在提示型任务中使用开源模型,将生成型任务留给 GPT-3.5 等闭源模型。大多数量化方法都会带来损失,这意味着性能会下降。通过 8 位量化,我们很可能达到具有基本竞争力的性能,使所有计算出的价格降低 2 倍!虽然量化和不完美的利用率会相互抵消,但综合考虑这个因素,我们预期的价格将与所测算到的价格相当。然而,大多数开源量化方法的目标是使模型易于在少量/较小规模的消费级 GPU 上部署,而不是大规模优化吞吐量。有几个开源库专门对较低精度量化进行了优化,同时保持了性能。然而,这些库优化的目标是在少量/较小规模的非数据中心 GPU 上提供模型服务,并不是为了大规模吞吐量的需求。具体来说,它们主要针对低批次推理的情况进行优化(主要批次大小为 1)。尽管它们能够提供(最佳情况下)3-4 倍的加速,但每 1000 个词元的生成仍需 0.017 美元。Bits and Bytes 库提供了(事实上的)无损量化,也就是不会对性能造成影响的优化。然而,它的主要优势是减少内存使用量,而不是提高速度。例如,最近的 NF4 表示法只能提升矩阵乘法的速度,而不能提高推理吞吐量的速度。根据经验,人们似乎没有在这方面测算速度的提升。(14)LLaMA.cpp 库主要针对苹果硬件进行优化,同时还支持 CUDA,并支持快速的 4 位精度的推理,但在这里进行朴素量化(naive quantization)可能会显著降低性能。此外,LLaMA.cpp 库还针对低批次场景进行了优化。GPT-Q 是另一个量化库。虽然我还尚未测试 GPT-Q,但一直有这个计划。希望我们能利用GPT-Q ,将价格降低2倍!再次强调,该实现针对低批次场景进行了优化。此外,论文中所指的 3 倍以上的速度提升只适用于 3 位量化,对于我们的用例来说,这种量化过程的损失过大。如前所述,我们有几种可靠的开源量化方法,但我认为,OpenAI 的量化实现更适合进行大批次优化。人们普遍猜测 GPT-4 使用了混合专家(mixture of experts)技术(15)。如果 GPT-3.5-turbo 也使用了这一技术,那么为达到相同的性能水平,你可以使用部署一个更小(因而更快)的模型。推测采样通过让一个较小的模型连续生成多个词元来规避语言模型解码缓慢的问题(16)。值得注意的是,长远来看,这并不会显著提高吞吐量,但可以大大降低时延。作为参考,这个代码库(https://github.com/dust-tt/llama-ssp.git)实现了一个简化版的推测采样在进行大规模推理时,OpenAI 可能会使用一些技巧,比如为预填充一批请求分配多个 8-GPU 节点,然后为该请求批次分配一个单独的 8-GPU 节点用于生成词元。这样可以兼顾两者的优点,既能使用大于 64 的批次大小,又可以获得极低的首个词元生成时间。我们将上述发现用于指导公司应该如何以及在何时使用开源模型。我们发现开源模型非常适用于提示型任务,如分类或重新排序。下表为 LLaMA-2-70B 时延的数据点表格,以及一些附加计算指标。
字节。以 4096 个词元为例,在批处理大小为 1 的情况下,缓存大小为 1.3 GB。在两个 A100 GPU 上,我们有 160GB 的空间。其中,模型占用了 135GB 的空间,仅剩下 25GB 的空间可用于 KV 缓存。由于内存存储的额外低效,对于较长的序列长度,我们最大的批处理大小约为 8。在速度(大约)增加 8 倍的情况下,我们预计每 1000 个词元的价格为 0.00825 美元。尽管这个价格仍高于 gpt-3.5-turbo 的价格,但已经更接近了。对于较短的序列长度(总计一千个词元),我们可以将批处理大小增加到 32,这意味着每 1000 个词元的价格为 0.00206 美元。理论上讲,相比 gpt-3.5-turbo 的价格,这个价格具有竞争力。另一个方案是,我们还可以增加 GPU 数量。通过租用 8 个 80GB 的 A100 GPU,我们获得了 1.28TB 的内存。去除模型权重后,我们仍有超 1TB 的内存可供 KV 缓存使用,这意味着,可以实现的批处理大小超过 512 个词元。值得注意的是,实际成本并不会降低 512 倍,因为 KV 缓存现在占用的内存带宽比模型尺寸大 8 倍,所以成本可能会降低近 64 倍。增加计算资源也可以解决时延问题。GPT-3.5 的吞吐量约为 70 TPS。如果将模型分布在 8 个 GPU 上而不是 2 个 GPU 上,那么吞吐量可以提高至约 74.4 个词元/秒。虽然我们在运行这个实验时并没有使用到 8 个 A100 GPU,但让我们来看看在 2 个 80GB A100 GPU 上的数值情况。图 3:对于所有数据点,我们在生成 512 个词元时测算了生成单个词元的价格然而,正如图表所示,尽管随着批处理大小的增加,每 1000 个词元的生成成本呈线性下降趋势,但与 GPT-3.5 每 1000 个词元 0.002 美元的定价相比,仍有一定差距,尤其对于较长的序列长度更是如此。使用大型批次大小进行生成可获得与 GPT-3.5 相媲美的定价,但会显著增加首个词元的生成时间。随着批次大小的增加,成本会线性降低,但首个词元的生成时间会线性增加。当批次大小为 64 时,我们可获得比 GPT-4 更好的价格优势,但会面临以下情况:对于只有 512 个词元的情况,首个词元的生成时间接近 3 秒!(12)当批次大小为 64 ,词元数为 3596 时,生成时间为 20.1 秒。(13)因此,相对于 OpenAI 的 API,LLaMA-2 更合适以下类型的工作负载:1. 具有大量提示但生成的词元很少或为零的场景——处理纯提示任务非常简单。2. 带有少量提示或没有提示的词元生成场景——我们可以调整批次大小到 64 以上,在不牺牲时延的情况下,获得与 gpt-3.5-turbo 相比具有竞争力的定价。增加批次大小需要有相对较大的工作负载,而这对于大多数创业公司来说是不可能的!对于大多数用户和大多数工作负载而言,使用量极不稳定。当然,一种解决方案是,根据需求自动调整 GPU 的扩展,但即使如此,平均每个 GPU 预计只能达到最大吞吐量的 50% ——尤其在考虑到冷启动时间的情况下。基于上述情况,我们建议在提示型任务中使用开源模型,将生成型任务留给 GPT-3.5 等闭源模型。大多数量化方法都会带来损失,这意味着性能会下降。通过 8 位量化,我们很可能达到具有基本竞争力的性能,使所有计算出的价格降低 2 倍!虽然量化和不完美的利用率会相互抵消,但综合考虑这个因素,我们预期的价格将与所测算到的价格相当。然而,大多数开源量化方法的目标是使模型易于在少量/较小规模的消费级 GPU 上部署,而不是大规模优化吞吐量。有几个开源库专门对较低精度量化进行了优化,同时保持了性能。然而,这些库优化的目标是在少量/较小规模的非数据中心 GPU 上提供模型服务,并不是为了大规模吞吐量的需求。具体来说,它们主要针对低批次推理的情况进行优化(主要批次大小为 1)。尽管它们能够提供(最佳情况下)3-4 倍的加速,但每 1000 个词元的生成仍需 0.017 美元。Bits and Bytes 库提供了(事实上的)无损量化,也就是不会对性能造成影响的优化。然而,它的主要优势是减少内存使用量,而不是提高速度。例如,最近的 NF4 表示法只能提升矩阵乘法的速度,而不能提高推理吞吐量的速度。根据经验,人们似乎没有在这方面测算速度的提升。(14)LLaMA.cpp 库主要针对苹果硬件进行优化,同时还支持 CUDA,并支持快速的 4 位精度的推理,但在这里进行朴素量化(naive quantization)可能会显著降低性能。此外,LLaMA.cpp 库还针对低批次场景进行了优化。GPT-Q 是另一个量化库。虽然我还尚未测试 GPT-Q,但一直有这个计划。希望我们能利用GPT-Q ,将价格降低2倍!再次强调,该实现针对低批次场景进行了优化。此外,论文中所指的 3 倍以上的速度提升只适用于 3 位量化,对于我们的用例来说,这种量化过程的损失过大。如前所述,我们有几种可靠的开源量化方法,但我认为,OpenAI 的量化实现更适合进行大批次优化。人们普遍猜测 GPT-4 使用了混合专家(mixture of experts)技术(15)。如果 GPT-3.5-turbo 也使用了这一技术,那么为达到相同的性能水平,你可以使用部署一个更小(因而更快)的模型。推测采样通过让一个较小的模型连续生成多个词元来规避语言模型解码缓慢的问题(16)。值得注意的是,长远来看,这并不会显著提高吞吐量,但可以大大降低时延。作为参考,这个代码库(https://github.com/dust-tt/llama-ssp.git)实现了一个简化版的推测采样在进行大规模推理时,OpenAI 可能会使用一些技巧,比如为预填充一批请求分配多个 8-GPU 节点,然后为该请求批次分配一个单独的 8-GPU 节点用于生成词元。这样可以兼顾两者的优点,既能使用大于 64 的批次大小,又可以获得极低的首个词元生成时间。我们将上述发现用于指导公司应该如何以及在何时使用开源模型。我们发现开源模型非常适用于提示型任务,如分类或重新排序。下表为 LLaMA-2-70B 时延的数据点表格,以及一些附加计算指标。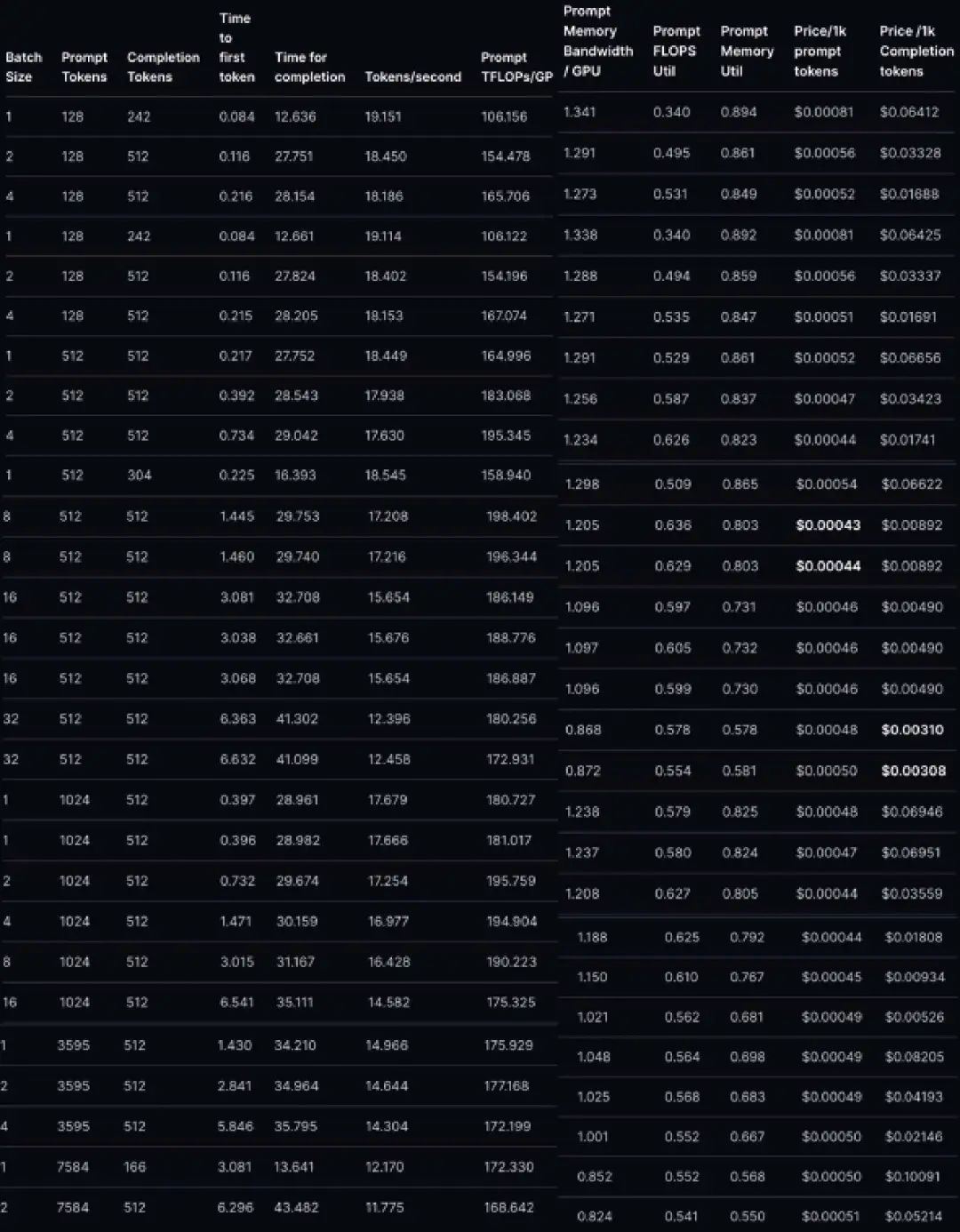
(1)虽然我们受 OpenAI 资助,但在本文的分析中尽可能保持了公平公正的态度。例如,我们认为开源模型比 gpt-3.5 更适合处理提示型任务。
(2)https://ai.meta.com/research/publications/LLaMA-2-open-foundation-and-fine-tuned-chat-models/
(3)尽管有容量,但我无法配置任何 4/8-GPU 节点。
(4)Chen, Carol. "Transformer Inference Arithmetic",https://kipp.ly/blog/transformer-inference-arithmetic/, 2022.
(5)https://arxiv.org/abs/2001.08361
(6)在矩阵 1xm 与矩阵 m x n 的乘法运算中,计算 FLOPs 可以通过简单的推导证明。两个 k- 维向量之间的点乘需要 2k 个Flops,因为我们先进行 k 个独立的乘法操作,然后进行 k 次加法操作以求和乘积的数组。矩阵乘法则执行了 l·n 个点乘操作,其中每个向量是 m- 维。这意味着矩阵乘法的总 FLOPs 为 2mnl。在向量与矩阵的乘法运算中,l=1,所以 FLOPs 仅有 2mn。
(7)我们两次读取了嵌入矩阵,但与模型大小相比,它非常小,甚至可以忽略不计。
(8)在足够大的序列长度下,实际存储的中间激活会比模型权重使用更多的内存带宽,与 flash-attention 的使用量相当。这篇论文使用了类似 flash-attention 的技术来减少这些中间激活的内存带宽消耗:https://arxiv.org/pdf/2305.19370.pdf
(9)实际上,这可能是在短提示上首个词元生成的时间几乎是恒定的原因。计算/词元和每个词元的内存带宽都可以表示为参数数量的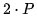 或 2 倍。由于 A100 在 16 位精度下的 FLOPs 为 312,内存带宽仅取决于生成的词元数量,而 FLOPs 取决于提示和生成的词元数量,因此直到提示词元的数量达到
或 2 倍。由于 A100 在 16 位精度下的 FLOPs 为 312,内存带宽仅取决于生成的词元数量,而 FLOPs 取决于提示和生成的词元数量,因此直到提示词元的数量达到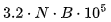 个之前,首个词元的时间都受到内存带宽的限制(因此保持恒定状态)。
个之前,首个词元的时间都受到内存带宽的限制(因此保持恒定状态)。
(10)https://www.coreweave.com/gpu-cloud-pricing
(11)考虑到 LLaMA 的内存和计算要求,说服自己这是真的 。
(12)在 8-A100s 上,我们可以预期进行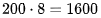 次 TFLOPs 计算。然而,对于具有64 个批次大小、512 个提示词元、共计 32768 个词元的情况,这意味着计算的时延将为
次 TFLOPs 计算。然而,对于具有64 个批次大小、512 个提示词元、共计 32768 个词元的情况,这意味着计算的时延将为
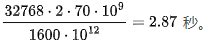
(13)在同样可以进行 1600 次 TFLOPs 计算的情况下,我们需要处理 3596 个提示词元。首先,在这一序列长度和批次大小的情况下,我们依然可能再次受内存带宽的限制,进一步降低处理速度。即使不考虑内存带宽限制,与之前相比,处理时间也将放缓 7 倍,意味着需要 20.09 秒。
(14)参见 huggingface的博文和这篇推特。
(15)https://www.semianalysis.com/p/gpt-4-architecture-infrastructure
(16)https://arxiv.org/pdf/2302.01318.pdf
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/

内容中包含的图片若涉及版权问题,请及时与我们联系删除


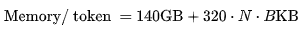
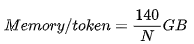
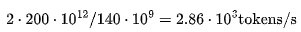
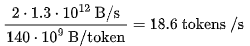

评论
沙发等你来抢