今年早些时候,OpenAI宣布成立了一支专注于超级对齐的新团队,由Jan Leike和IIya Sutskever领导,超级对齐旨在构建一个能够与人类水平相媲美的自动对齐研究器。其目标是尽可能地将与对齐相关的工作交由自动系统完成。
其中一个重要手段就是可扩展监督(Scalable Oversight),即在确保模型能力超过人类水平后,仍旧能够与人类期望保持一致、持续地进行改进和学习。可扩展监督的重点是如何向模型持续提供可靠的监督,这种监督可以通过标签、奖励信号或批评等各种形式呈现。随着AI不断进步,RLHF可能会逐渐失效,人类评估模型的能力遭遇瓶颈。如何判断可扩展监督正在发挥作用?可扩展监督的目标是什么?在近期由青源会主办的「超级对齐」闭门研讨会上,OpenAI超级对齐负责人Jan Leike讲解了如何利用可扩展监督来解决对齐难题。OpenAI 超级对齐团队负责人,研究方向为强化学习,大语言模型的对齐engineering,通用人工智能等。2016 年加入谷歌 DeepMind 团队从事人类反馈强化学习(RLHF)相关研究,现领导 OpenAI 对齐团队,旨在设计高性能、可扩展、通用的、符合人类意图的机器学习算法,使用人类反馈训练人工智能,训练人工智能系统协助人类评估,训练人工智能系统进行对齐研究。
关于对齐问题,我已经思考10年之久。在OpenAI,我与 Ilya Sutskever 共同领导了超级对齐团队,并深度参与了一些项目,包括RLHF原始论文、InstructGPT、ChatGPT 和 GPT-4 的对齐项目。目前超级对齐的目标是弄清楚如何对齐超级智能,因此系统必须比人类更聪明。我们希望在四年内,利用OpenAI 20%的算力解决超级对齐的问题。
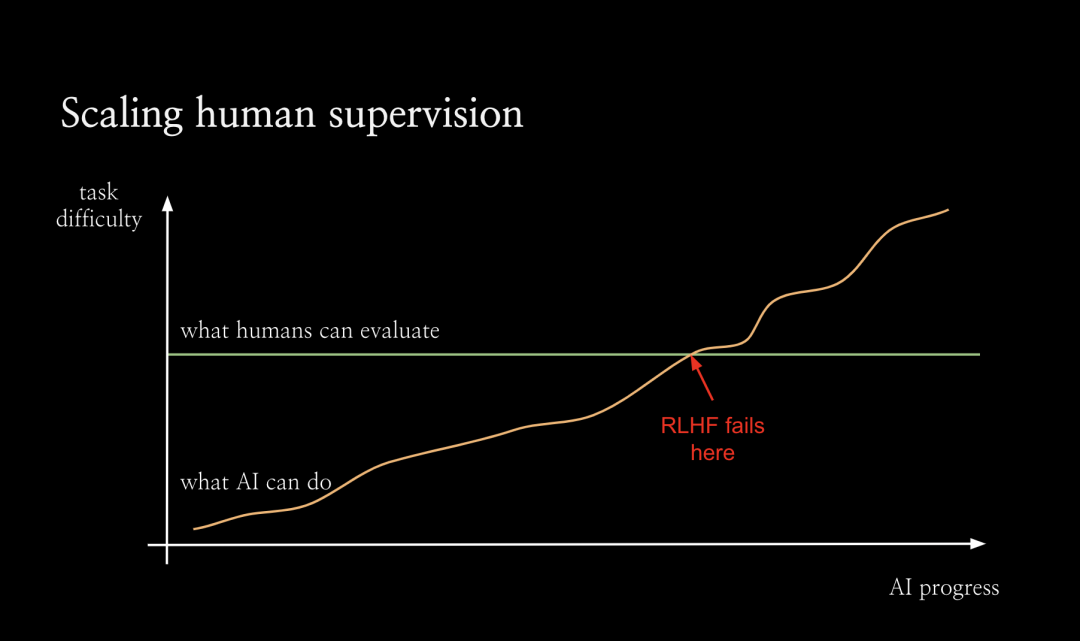
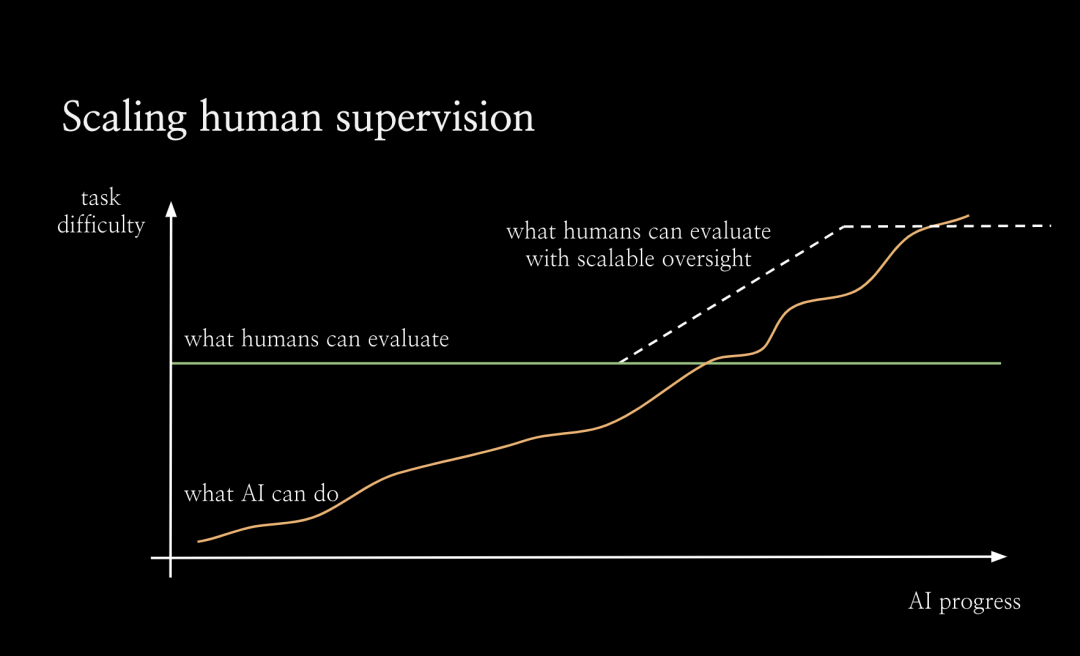
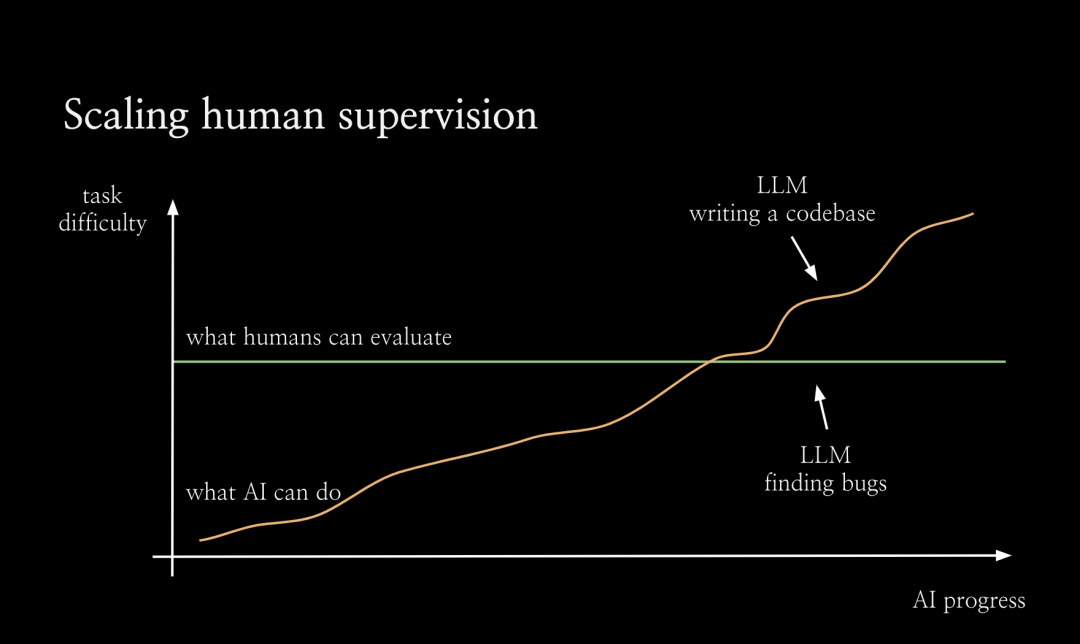
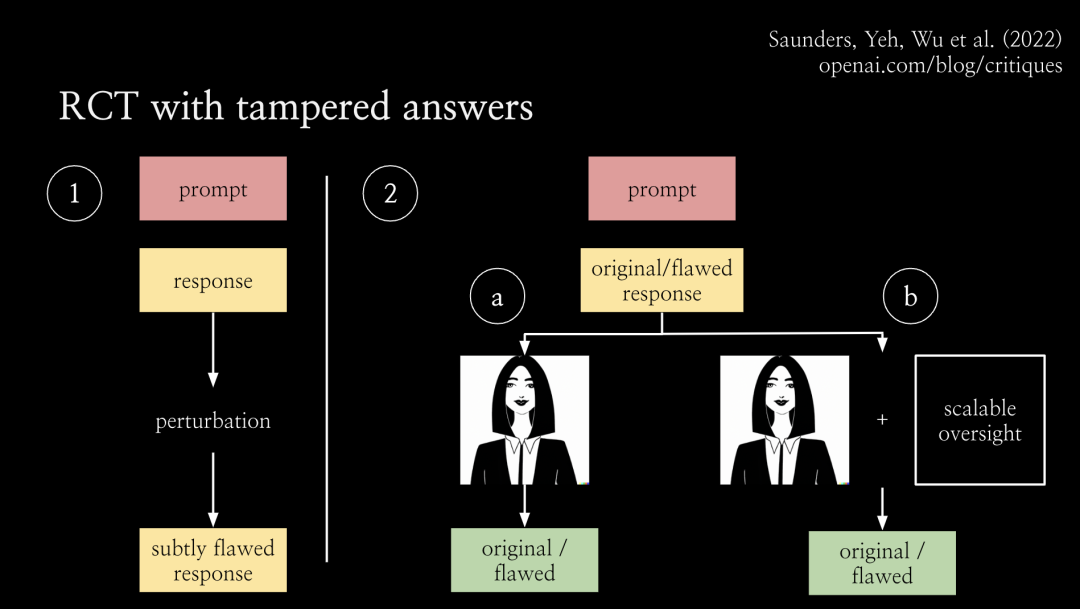
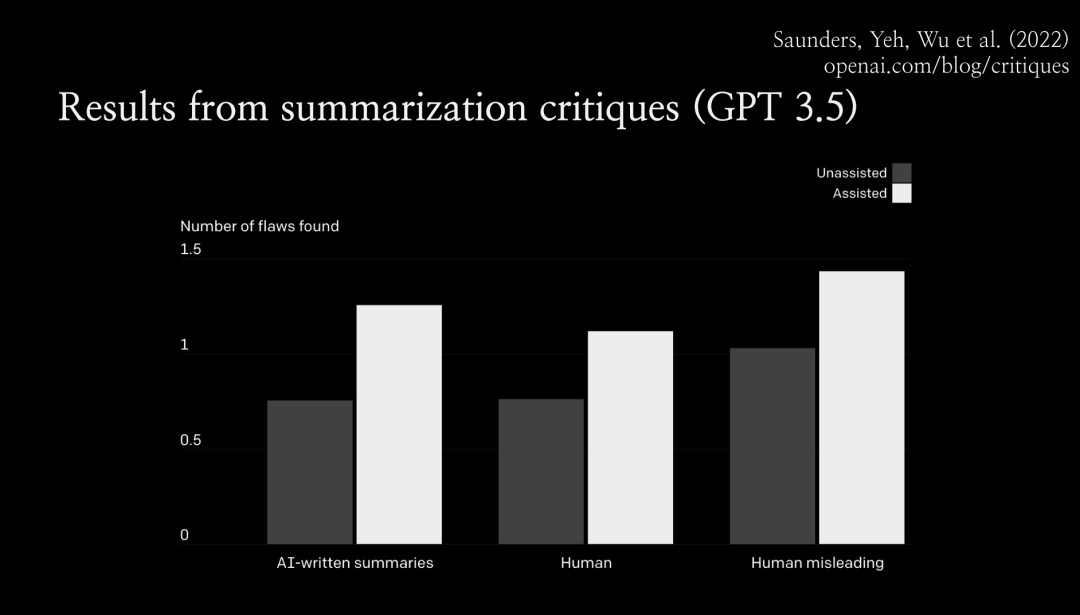
在超级对齐团队中,我们正在开展一系列不同的项目,这里我想重点讨论下可扩展监督(scalable oversight),这是解决对齐问题较为自然的方法之一。当然还有很多关于泛化、可解释性和训练模型机制的工作。为了促进可扩展的监督,我们从整体上考虑对齐的方式。如图所示,随着AI不断进步,它将能够解决越来越困难的任务。但默认情况下,人类评估任务的能力不会随着人工智能的进步而提升。从某一个临界点开始,人类将无法再可靠地评估人工智能系统。我认为,正是从这个点开始,RLHF失效了,因为人类将无法再为人工智能系统提供良好的训练信号了。因此从这个点之后,我们需要很大程度上依赖新的对齐技术,而这些技术尚未证明,手段也未知。我将其称为对齐的难题:我们在对齐如大语言模型之类的AI系统方面取得了很大进展,但真正的挑战是对于那些过于复杂无法直接评估的任务上如何对齐系统。因此我们希望通过可扩展的监督来扩展人类评估复杂任务的能力,特别是借助AI本身来让人类更好地进行评估。我们希望看到:在可扩展的监督的助力下,人类可以更有效地监督人工智能系统。我不敢说一定会实现扩展,但这至少会让问题变得更容易。比如,如果你正在监督一个大语言模型编写整个代码库,输出10000 行代码。那么,你很难找到这个代码库中所有的bug。一般来说,人类不擅长发现软件中的漏洞,我们日常不得不处理很多有缺陷的软件。但是如果有一个语言模型为你指出代码库中的漏洞,那么代码检查工作就会变得容易的多。语言模型会告诉你,使用某个输入运行该程序,会在某一行代码处报错。你可以逐步运行该程序,直到这一行进行检查,这让事情变得容易多了。有时,它可以发现人类没有意识到的细节问题。我们的动机是:在某种程度上,让人类监督系统查找漏洞,比监督系统编写整个代码库要容易得多。如果有一个帮你查找漏洞的 AI 助手,就能更有效地监督代码库。进行可扩展监督的最简单方法之一是:让语言模型编写批评意见。如下图所示,我们让语言模型(在本例中为 GPT 3.5)为短篇小说写评论。或者,你可以做一些更复杂的事情,让类似 ChatGPT 的系统在对话中进行交互,要求它解释,给出细节和评论。随着语言模型变得更加灵活,它应该能更有效地帮助您评估困难的任务。所以最大的问题来了,我们如何通过实证检验这个假设?如何知道它实际上比人类更擅长发现规律,或者它确实让我们更好地评估困难任务?我们还可以使用许多其他设置,例如,通过辩论实现人工智能安全:你可以训练辩论智能体,然后将其用作助手。如何判断可扩展监督正在发挥作用呢?衡量(评估效果提升)的进展实际上非常困难。而且我们真正感兴趣的任务是现实世界的任务。例如,用户在 ChatGPT 中提出的最难的问题,也就是现实世界中的困难任务。此外,我们没有标准答案。如果你想衡量在现实任务上的提升,我们将面对既困难又无法评估的任务。所以这看起来是一个根本性的矛盾,事实上,我们至少可以局部性地衡量提升。我认为可扩展监督之所以起作用,是因为这种评估模式比生成本身更容易。所以对于很多任务来说,评价任务其实比把任务做好要容易得多。这是最经典的真理。在计算机科学中,你会遇到 NP 问题,你可以在多项式时间内判定某个问题,但你不一定能生成它。在许多其他设定场景中也是如此。比如在体育运动中,你可以通过一支球队进球多少来判断是否获胜,但实际上要打好比赛真的很难。在学术研究中,对优秀论文进行同行评审比提出想法并按照论文中的方式进行实验更容易。我们一直在使用一种通过篡改答案实现的随机对照实验(RCT with tampered answers)。基本设置是,向模型输入prompt,并生成回答。这种答案不一定是完美的,你可以篡改回答,通过某种方式使其变得更糟。这样一来,就得到了一些有少量缺陷的回答。那么在第二步中,就拥有了一些答案对,包括原始回答和经过篡改的回答。之后分别利用原始回答和经过篡改的回答开始运行随机对照实验,将其展示给人类或被可扩展的监督辅助的人类。该任务是,让人类分辨出该回答是原始版本还是被篡改的版本,或者更复杂一点,找出具体的缺陷。而且正是因为你篡改了回答,即使你不知道原始答案是否正确,你也知道篡改的缺陷。这个问题既没有标准答案也没有完美的回答,但人们总是能判断出被篡改答案的版本。事实上,理想情况下,他们每次都会发现缺陷。 因此,通过将其随机分配给有可扩展监督协助或无协助的人,你可以通过实验说明可扩展的监督技术实际上在评估任务中对人类有多大帮助。此外,还可以将不同的可扩展监督技术相互比较,看看哪一种更有效。我想在尽可能贴近真实的情况下进行实证测试,看看哪些技术效果最好,它们实际效果如何,以及如何使它们发挥作用。下面是 GPT3.5 模型总结小说故事任务中的结果。实验结果表明,人类在有协助的情况下发现的缺陷比无协助的情况下多出约 50%。 事实上,通过可扩展监督,有协助的人确实在经过篡改的答案中发现了更多缺陷。(论文链接:Self-critiquing models for assisting human evaluators https://arxiv.org/abs/2206.05802)众所周知,GPT-4 在编写代码方面表现不错,至少如果它是相对简单的代码,或者它使用了一堆您可能不熟悉但在互联网上非常流行的库。因此,它对于此类任务实际上非常有用。未来的模型在代码编写方面可能会更加出色,人们会想用模型编写大量代码。但我们怎么知道他们实际上是在以正确的方式做这件事呢?如何判断他们的行为符合我们的意图?随着编码任务变得越复杂,实际上可能会变得越困难。如图所示,模型可能会出现一系列不对齐问题,这些问题从左到右严重程度不同。最普通的问题可能只是模型没有那么努力,并留下了一些它认为我们不会发现的错误。所以 RLHF 不会因此惩罚它。 此外还有另一个极端,模型开始进行秘密地欺骗性地对齐。它试图将这些难以检测到的「木马病毒」注入代码中,一旦你运行代码,它就会为模型提供支持。目前,GPT-4 还无法做到这一点,但未来的模型可能有能力做到这一点。所以这当中的不对齐问题值得担忧。 因此,我们希望通过实现可扩展的监督,去发现模型意识到的所有错误。这一技术的终极目标是,模型能告诉我们它所意识到的所有代码漏洞吗?如果能做到这一点,那么模型就无法隐藏木马,因为如果它尝试隐藏木马病毒,它就会知道木马病毒在那里,然后它会告诉我们。我们就会立刻停止运行代码。 这也非常适合我们的通用评估协议。如果我们训练一个模型来执行这些篡改,我们会训练一个模型将错误引入代码中,然后模型会意识到引入的错误类型。从这个意义上说,我们希望能够 100% 捕获模型本身引入代码的篡改问题。这就是我们目前正在致力于可扩展监督的工作。Q1:关于超级对齐,您的文章和 OpenAI 网页上写的使命是,引导和控制比我们更智能的人工智能系统。但据我所知,在控制论中,有一个原则是系统不可能控制更智能的系统。只有更智能的系统才能控制低级系统。因此如果有一个比我们人类更聪明的人工智能系统,人类就不可能控制那种系统。对此您有何看法?Jan:我不认为这是不可能的,这就是我们目前正在努力的方向。人类还有很多优势,我们可以在比我们更聪明的系统上操作。比如说服务器,我们可以复制它。我们可以向副本询问同样的问题。我们可以提高模型的内存,可以通过可解释性来查看其激活,并尝试构建对齐探测器。而且系统看不到自己的激活情况。诸如此类。Q2:在OpenAI的超级对齐计划中,关键的研究问题和挑战是什么?Jan:基本上,现在有两个关于超级对齐的主要项目,可扩展的监督和泛化。我们正在尝试理解并证明模型如何从可以以高置信度监督的简单设置泛化到我们无法监督的更困难的设置。与人类监督超级智能类似,我们还无法做到让一个小模型监督大模型。例如,对于一个为 RLHF 生成偏好数据的小型语言模型,然后凭经验研究其泛化能力。我们致力于可解释性研究,这是一个非常年轻的领域,很难说我们实际上能在该领域做多少事情。如果我们有完美的「大脑扫描仪」,我们可以测量新的网络激活,在每个时间点都具有完美的测量精度。还有一个机械可解释性问题,试图对整个模型进行逆向工程,这似乎非常雄心勃勃。我认为我们的目标可能更专注:尝试构建对齐检测器。第四个项目是对抗性对齐,我们故意尝试训练欺骗性的对齐模型,或更准确地说,训练未对齐的模型,这些模型试图隐藏其未对齐的情况。然后看看什么样的模型能通过评估?我们能否以可解释性的方式看待它,看看出了什么问题,并对我们的整个缓解措施进行压力测试。Q3:你刚才提到评估比生成容易,但作为一名强化学习研究者,我的经验是培养一个好的批评家比找到一个好的演员要困难得多。有时评论家做出的预测不够好,但我们已经有了一个好演员,有非常好的表演能力。此外,判断一篇论文好不好很容易,但是判断论文中的一句话好不好却很难。根据我的理解,您的目标或评价是否主要关注高层的活动,而不是底层的活动,例如活动中的每个动作?您有何评论?Jan:强化学习场景下的「评论家」并不是真正的模型评价者。我认为正确的类比应该是奖励函数和智能体,而奖励函数仍然可以依赖于每一个时间步骤和每一个行动,但它通常是关于结果的。结果通常是很容易评估的事情,但制定出真正完成任务的策略是很难的。Q4:一些人认为可以通过引用信息规则来构建「AI 宪法」,并且可以以类似于标签原则的方式来调节AI的价值,从而提高AI的安全性。这种方法可行吗?有哪些限制和挑战?Jan:我不认为「宪法 AI」(Constitutional AI)是过度可扩展的监督,我不认为它本身解决了对齐的难题。所以如果你想在一个困难的任务中通过编写「宪法」监督人工智能,你可以像运行 RLHF 一样,看看会发生什么。但问题是,你不知道它是否正确地工作,无法进行评估。一般来说,当你评估「宪法 AI」时,需要创建一个验证集,有一堆人类对偏好的注释,然后衡量「宪法」的泛化能力。在可扩展的监督设置下,你仍然需要这样做。您仍然需要解决如何评估任务的问题。「宪法 AI」确实让很多事情变得容易了。总的来说,我认为可以把它看作是RLHF的一个非常重要的改进,但是我不认为它在这个难题上有什么进展。Q5:我们人类的价值是如何下降的?在培养我们的人类价值方面,你最好的社会系统活动是什么?也许联邦学习真正的价值对齐是关于为什么我们的社会和价值观是这样的。黄铁军:这是一个非常重要的问题,我同意人工智能系统将有一个与人类的价值不同的价值空间,我们所信任的不是人工智能系统,而是价值空间,即人工智能系统的共识。例如,我不能完全相信任何人,但我相信人类的结果,例如,即使我们不相信科学家本人,但是我们却可以相信他论文和演讲中的某些经过人们讨论的论点。人工智能系统的价值比任何特定的人工智能系统本身都重要。我相信,未来的人工智能系统有一个价值世界,人类有一个价值世界。有些价值相契合,有些价值需要辩论,最后构建一个人工智能和人类普适的价值体系。Jan:现在没有一个完美的答案。你可以做一些很有效的事情。比如,通过向 ChatGPT 输入 prompt,可以先向语言模型输入一段关于国家和文化背景的信息,甚至是关于用户的信息。然后你需要从那个地区或了解这个文化背景的人里面找一些人参与训练。针对特定的情境写下问题的回答,并将其融入到训练中。Q7:模型如何能够为现实世界中存在的不确定性问题提供有用的建议?例如,这个模型能否跟上地球的状况,并为环境保护和物种灭绝提供有用的或最佳的政策。黄民烈:我认为人工智能给出建议是非常具有挑战性的,存在很大的风险。例如,我们正在为心理学训练大语言模型。心理学和情感支持是非常复杂的,你应该非常谨慎地给出任何建议,例如:他是否应该服用一些药物,或者他应该采取什么样的训练来改善他的症状。更安全的解决方法是不要给出任何建议,让人类自己做决定吧。这就是我的观点。Q8:为什么大语言模型会产生有害的内容。是由于数据不当,或模型结构不当,或不合理的训练方法造成的吗?黄民烈:我认为这主要是因为数据不正确。因为对人类来说,社交媒体数据中有很多偏见。我们在网络上有数字数据足迹。然后我们抓取数据来训练我们的模型。我们不可避免地将这种浏览和不公平反映到模式中。对于这种一般的生成模型,即使我们可以非常仔细地清理数据,我们仍然无法避免生成不正确的数据,模型会自己组合和创造。在某些情况下,我们有一些对抗性的攻击方法可以使系统失效。模型本身非常复杂,是一个不可解释的黑盒子。模型失效的机制尚不清楚。Jan:在我看来,很多东西可能只是来自于训练前的数据。张弘扬:既然主要是糟糕的数据导致系统失效,那么是否意味着可以通过高质量数据直接解决该问题,而无需进行对齐?张弘扬:微软在最近发表的论文《A Textbook is all you need 》中,使用高质量的数据来训练一个小模型,甚至可以击败大语言模型。 Jan:如果你问模型如何制造生化武器或者帮助你制造生化武器。模型看过所有的生物学教科书和所有的研究论文,阅读并消化他们,通过它们的推理能力从其它领域迁移知识。你不能通过从训练前移除这些数据来解决这一问题。 更重要的是,就像很多你不想让模型说的冒犯性的话。有一些可能被认为非常冒犯的短语,如果仅仅逐字逐句地看,其中的词听起来是无害的,就好比「童言无忌」。如果从预训练中去掉所有这些数据,这个模型就不会意识到它说了一些冒犯性的话。因为,我们想让模型明白它在说一些冒犯的话,以便训练它不要那样做。这似乎是不可避免的,或者看起来我认为不太可能通过移除预训练数据来解决问题。在某种程度上,有时你训练的模型并没有产生「不对齐」。但也许你用不符合人类偏好的函数训练它。此时,如果最终模型与你的偏好不相符,这并不奇怪。Q9:超级对齐的目标是尽量减少日益强大的 AI 系统所带来的风险并尽量最大化它的好处。但仅仅通过超级对齐不足以实现这一目标。如何看待超级对齐背景下的人工智能治理问题?Jan:这两者是不同的问题。它们在某些方面是重叠的。如果你能解决对齐问题,就有能帮你解决其它问题的对齐后的模型。对于开源模型来说,对齐治理问题可能也特别突出。我们可以做出一个完全对齐的开源模型,人们也可能去掉对齐让模型做一些不安全的事情。因此,如何管理模型的使用和误用,包括开源模型,似乎是一个非常开放的问题。5000字详解OpenAI超级对齐四年计划:定义、挑战与方法
内容中包含的图片若涉及版权问题,请及时与我们联系删除










评论
沙发等你来抢