
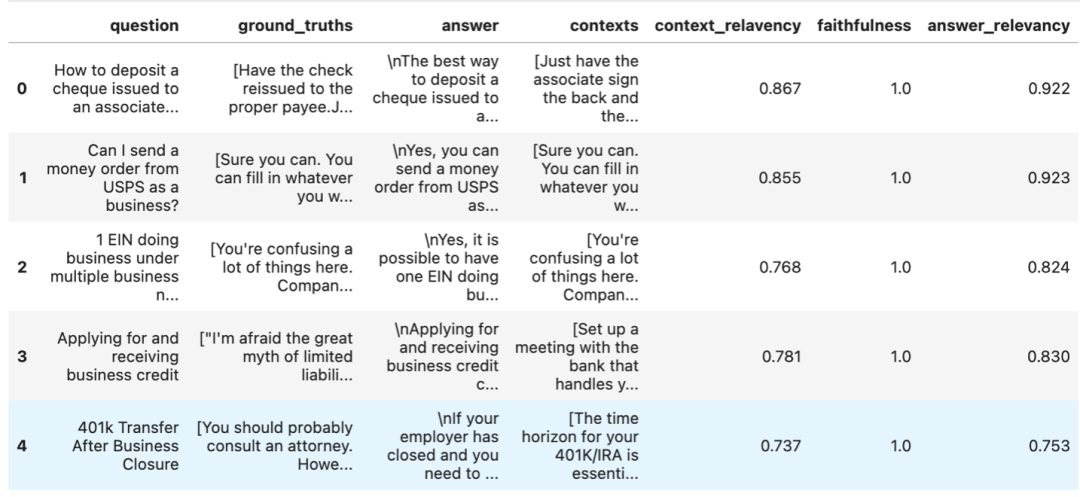
地址:https://arxiv.org/pdf/2309.15217.pdf
该框架考虑检索系统识别相关和重点上下文段落的能力,LLM以忠实方式利用这些段落的能力,以及生成本身的质量。
该工具已开源:https://docs.ragas.io/en/latest/getstarted/install.html

github的地址:https://github.com/ explodinggradients/ragas,也提供了快速调用的入口。
from ragas import evaluate
from datasets import Dataset
import os
os.environ["OPENAI_API_KEY"] = "your-openai-key"
# prepare your huggingface dataset in the format
# Dataset({
# features: ['question', 'contexts', 'answer', 'ground_truths'],
# num_rows: 25
# })
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}
本文对该工作的一些评估进行介绍,供大家一起参考。
一、三个维度的评估策略
考虑标准的RAG设置,即给定一个问题q,系统首先检索一些上下文c(q),然后使用检索到的上下文生成答案as(q)。
在构建RAG系统时,通常无法访问人工标注的数据集或参考答案,因此该工作将重点放在完全独立且无参考的度量指标上。
该工作特别关注三个质量方面:
首先,忠实性。答案应基于给定的上下文。这个可以确保检索到的上下文可以作为生成答案的理由。
其次,答案相关性。生成的答案应针对所提供的实际问题。
最后,上下文相关性。检索的上下文应重点突出,尽可能少地包含无关信息,因为向LLM处理长篇上下文信息的成本很高,当上下文段落过长时,LLMs在利用上下文方面的效率往往较低,尤其是对于上下文段落中间提供的信息。
那么,如何进行评估?
1、忠实性
如果答案中的主张可以从上下文c(q)中推断出来,那么答案as(q)就忠实于上下文c(q)。为了估计忠实度,首先使用LLM提取一组语句S(as(q)),这一步的目的是将较长的句子分解成较短且重点更突出的断言。
在此步骤中使用了以下提示:

其中,[question]和[answer]是指给定的问题和答案。

最终忠实度得分F的计算公式为F=|V|/|S|,其中|V|是语句数是根据LLM得到支持的语句数,而|S|是语句总数。
2、答案的相关性
如果答案as(q)以适当的方式直接回答了问题,就认为答案as(q)是相关的。
特别是,对答案相关性的评估并不考虑表面性,而是对答案不完整或包含多余信息的情况进行惩罚。
为了估算答案相关性,对于给定的答案as(q),促使LLM根据as(q)生成n个潜在问题qi,如下所示:
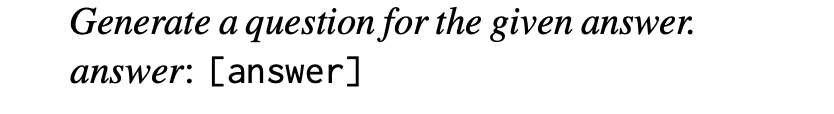
然后,利用OpenAI API提供的文本嵌入-ada-002模型获取所有问题的嵌入。对于每个qi,计算与原始问题q的相似度(q,qi),即相应嵌入之间的余弦值。然后计算出问题q的答案相关性得分AR:
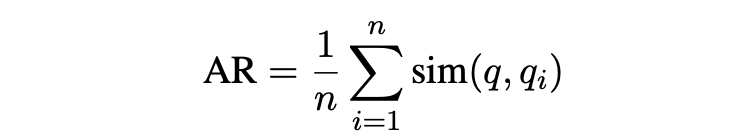
该指标评估生成的答案与初始问题或指令的一致性。
3、上下文相关性
上下文c(q)如果只包含回答问题所需的信息,则被视为相关。尤其是,该指标旨在惩罚包含冗余信息的情况。
为了估算上下文相关性,在给定问题q及其文本c(q)的情况下,LLM会使用以下提示从c(q)中提取对回答q至关重要的句子子集Sext:

上下文相关性得分的计算公式为
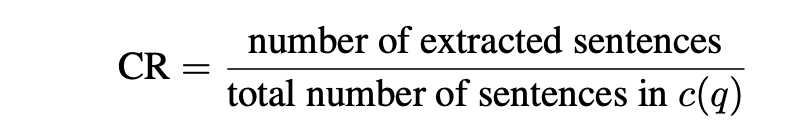
二、对照数据集:WikiEval
为了评估所提出的框架,最好需要问题-上下文-答案三元组的示例,这些示例要有人类判断的表。这样就能验证该工作度量标准在多大程度上与人类对忠实度、答案相关性和上下文相关性的评估一致。
由于不知道有任何可用于此目的的公开数据集,因此创建了一个新的数据集,称之为 WikiEval4,首先选择了 50 个维基百科页面,涵盖了自 20225 年开始以来发生的事件。
在选择这些页面时,优先考虑那些最近有编辑的页面。对于这 50 个页面中的每一个,都要求 ChatGPT 根据页面的介绍部分提出一个可以回答的问题,提示如下:


然后使用 ChatGPT 回答生成的问题,并给出相应的介绍部分作为上下文,提示如下:

所有问题均由两名标注人员根据三个质量维度进行标注。
标注人员的素质要求是需要的,两名标注人员都能说流利的英语,并对三个质量维度的含义有明确的说明。在忠实性和上下文相关性方面,两位标注人员在大约 95% 的情况下意见一致。在答案相关性方面,他们在大约 90% 的情况下意见一致。标注人员之间的分歧在讨论后得到解决。
下面可以看看具体的标注方法:
1、忠实性
为了获得人类对忠实性的判断,首先使用 ChatGPT 回答问题,而不获取任何其他上下文。然后,要求标注人员根据问题和相应的维基百科页面,判断两个答案中哪个最忠实(即标准答案和无上下文生成的答案)。
2、答案相关性
首先使用 ChatGPT 获取答案相关性较低的候选答案,提示如下:

然后,请标注人员比较该答案,并指出两个答案中哪个答案相关性最高。
3、上下文相关性
为了衡量这一方面,首先通过搜索相应维基百科页面的反向链接,为上下文添加额外的句子。这样就能在上下文中添加相关但与回答问题不太相关的信息,对于少数没有任何反向链接的页面,则使用 ChatGPT 来完成给定的上下文。
三、实验设定及结论分析
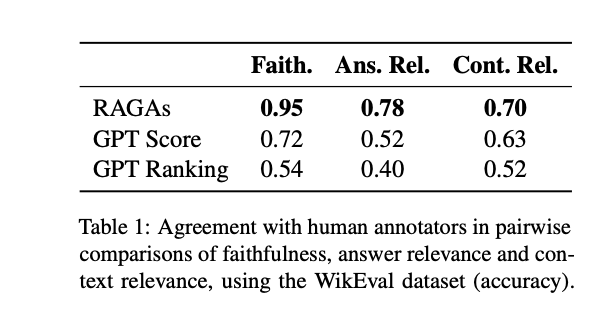
表1分析了上述方法与来自WikiEval数据集的人类评估之间的一致性。
具体计算方式为:每个WikiEval实例都要求模型比较两个答案或两个上下文片段,通过计算模型首选的答案/上下文(即估计忠实度、答案相关性或上下文相关性最高的答案/上下文)与标注人员首选的答案/上下文重合的频率,以准确率(即模型与注释者一致的实例比例)来报告。
其中:
GPTScore:要求ChatGPT为三个质量维度打0到10分。使用一个提示来描述质量度量的含义,然后要求根据该定义给给定的答案/上下文打分。例如,在评估忠实度时,使用了以下提示:

如果两个候选答案的得分相同,则随机打破平局。
GPT Ranking:不要求ChatGPT选择首选答案/上下文,提示中再次包含了所考虑的质量度量的定义,在评估答案相关性时,使用以下提示:

表1中的结果表明,该方案提出的指标与两个基准线的预测相比,更接近于人类的判断。
首先,就忠实度而言,RAGAs预测的准确度一般都很高。
其次,在答案相关性方面一致性较低,但这主要是由于两个候选答案之间的差异往往非常微妙。
最后,上下文相关性是最难评估的质量维度。尤其是ChatGPT在从上下文中选择关键句子时经常会遇到困难,尤其是对于较长的上下文。
四、RAGS平台支持的其他评估功能
1、针对不同embedding的评估
RAGS提供了针对不同类型embedding的评估框架,例如主流的openai embdding以及BGE embedding。

2、评估LlamaIndex以及langchain
llamaindex以及langchain是当前RAG系统的集成性方案,也可以使用RAGS来进行RAG方案的评估。

可以执行准确性、召回率等方面的评估。

总结
本文主要介绍了《RAGAS: Automated Evaluation of Retrieval Augmented Generation》这一关于RAG评估的工作。
跟昨天的工作类似,该工作提出了忠实性(即答案是否以检索到的上下文为基础)、答案相关性(即答案是否解决了问题)和上下文相关性(即检索到的上下文是否足够集中)三个评估维度。
当然,该工作也提供了测试数据集WikiEval,并做了评估,也被证明了其有效性。
这其实也揭示了当前测试评估中一个十分重要的点,那就是,如何确保评估的有效性和指引性。
该工作已经开源至github,但测试数据集只有中文,感兴趣的,可以迁移至中文上进行评估,加以实践。
参考文献
1、https://arxiv.org/pdf/2309.15217.pdf
2、https://github.com/ explodinggradients/ragas
3、https://docs.ragas.io/en/latest/getstarted/install.html
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢