
白交 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4V来做目标检测?网友实测:还没有准备好。
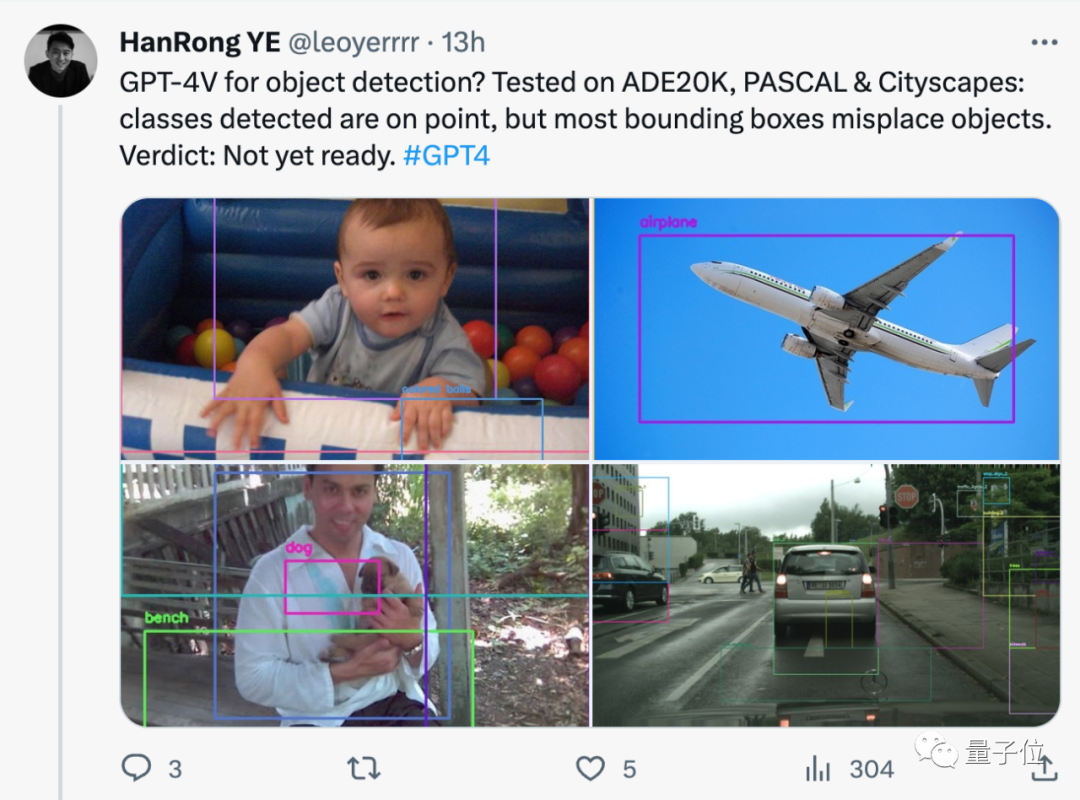
虽然检测到的类别没问题,但大多数边界框都错放了。
没关系,有人会出手!
那个抢跑GPT-4看图能力几个月的迷你GPT-4升级啦——MiniGPT-v2。
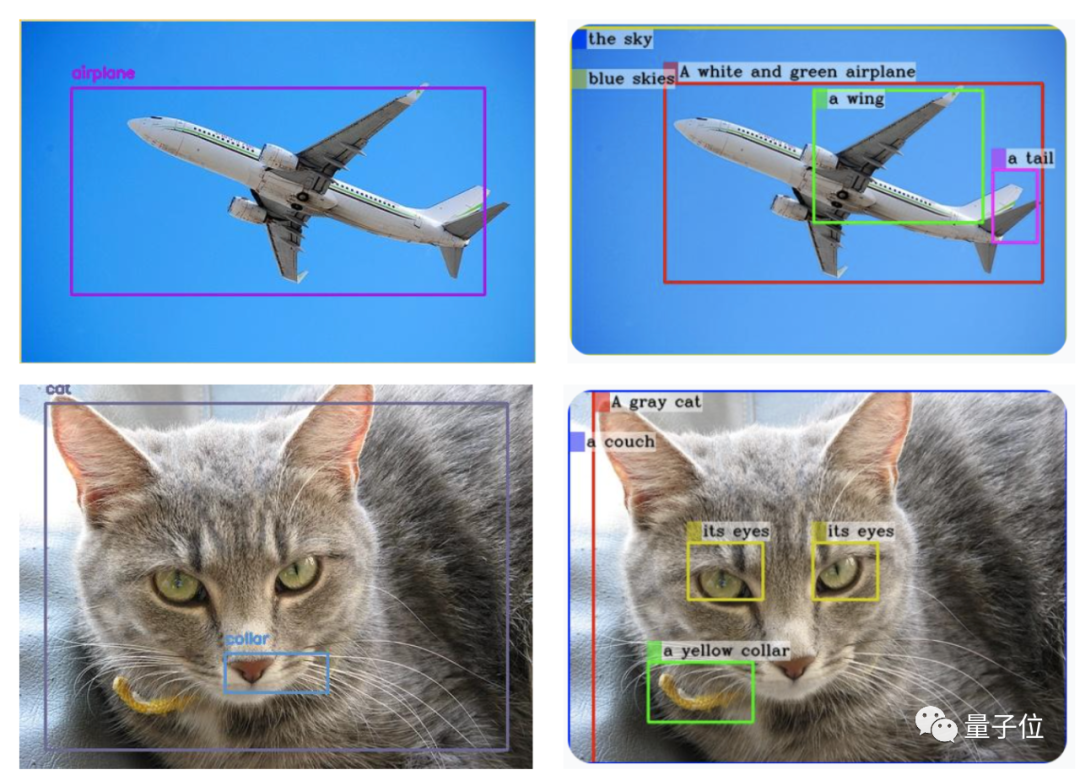
△(左边为GPT-4V生成,右边为MiniGPT-v2生成)
而且只是一句简单指令:[grounding] describe this image in detail就实现的结果。
不仅如此,还轻松处理各类视觉任务。
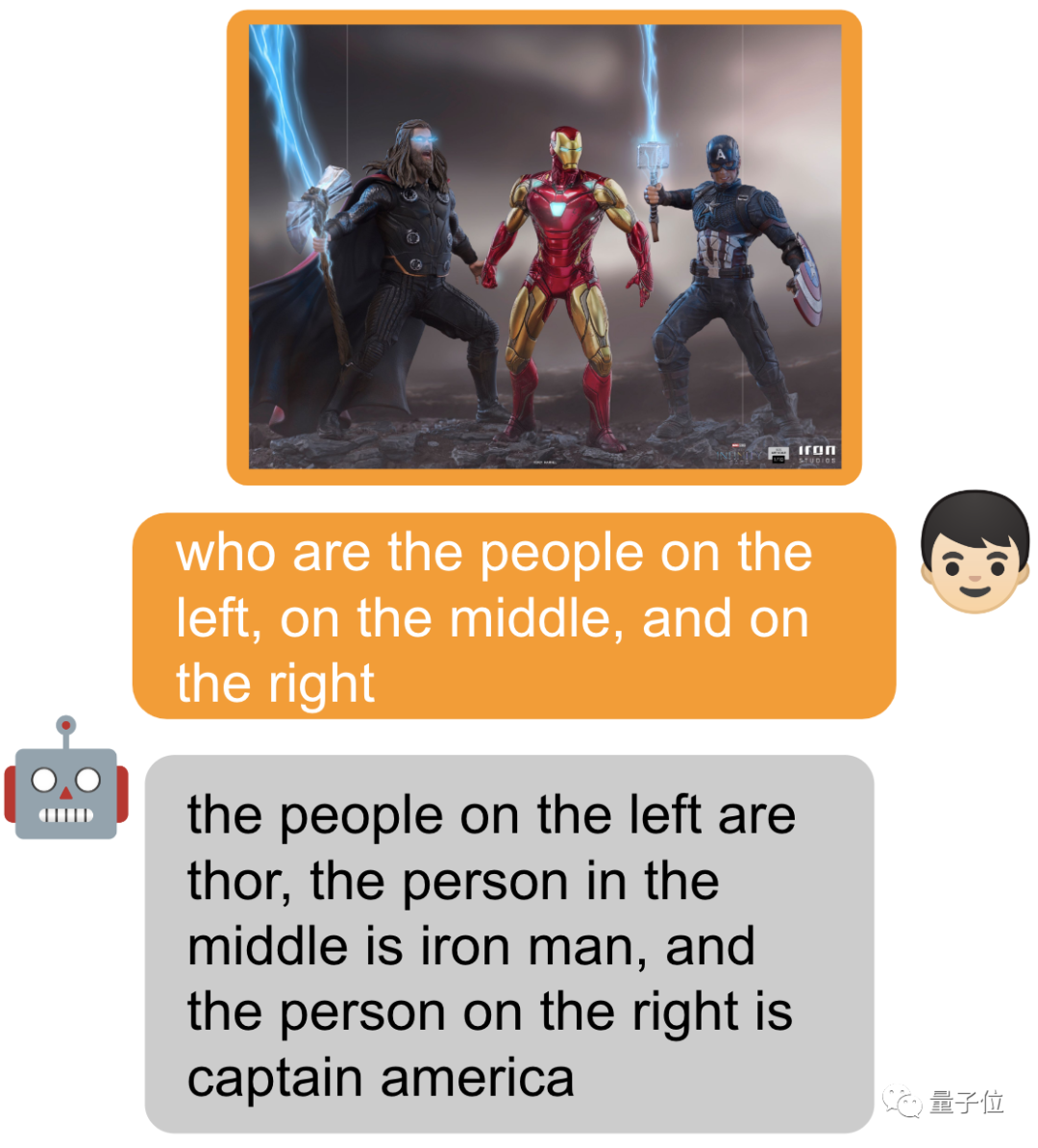
圈出一个物体,提示词前面加个 [identify] 可让模型直接识别出来物体的名字。

当然也可以什么都不加,直接问~
MiniGPT-v2由来自MiniGPT-4的原班人马(KAUST沙特阿卜杜拉国王科技大学)以及Meta的五位研究员共同开发。

上次MiniGPT-4刚出来就引发巨大关注,一时间服务器被挤爆,如今GItHub项目已超22000+星。
此番升级,已经有网友开始用上了~
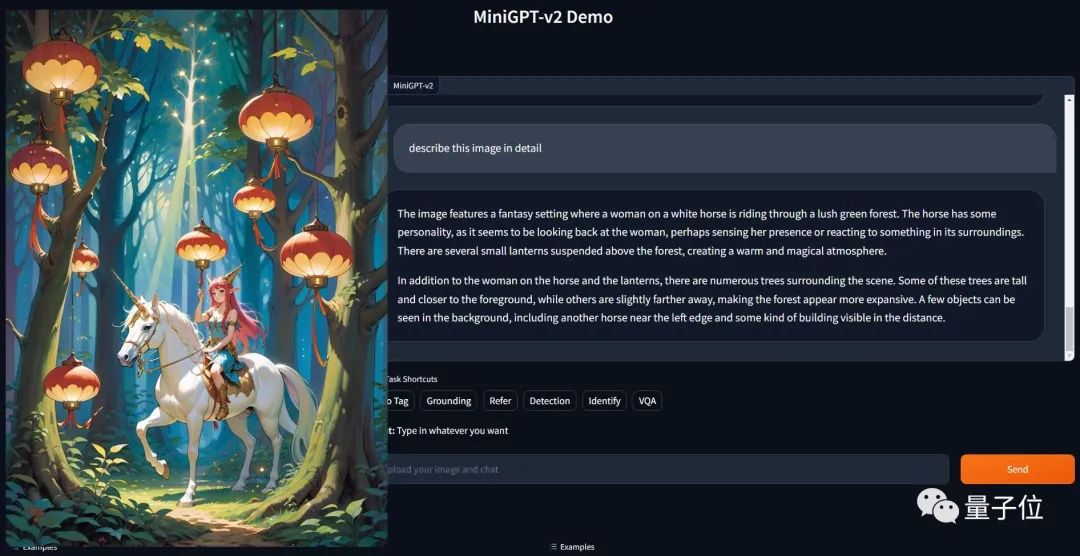
多视觉任务的通用界面
大模型作为各文本应用的通用界面,大家已经司空见惯了。受此灵感,研究团队想要建立一个可用于多种视觉任务的统一界面,比如图像描述、视觉问题解答等。

「如何在单一模型的条件下,使用简单多模态指令来高效完成各类任务?」成为团队需要解决的难题。
简单来说,MiniGPT-v2由三个部分组成:视觉主干、线性层和大型语言模型。
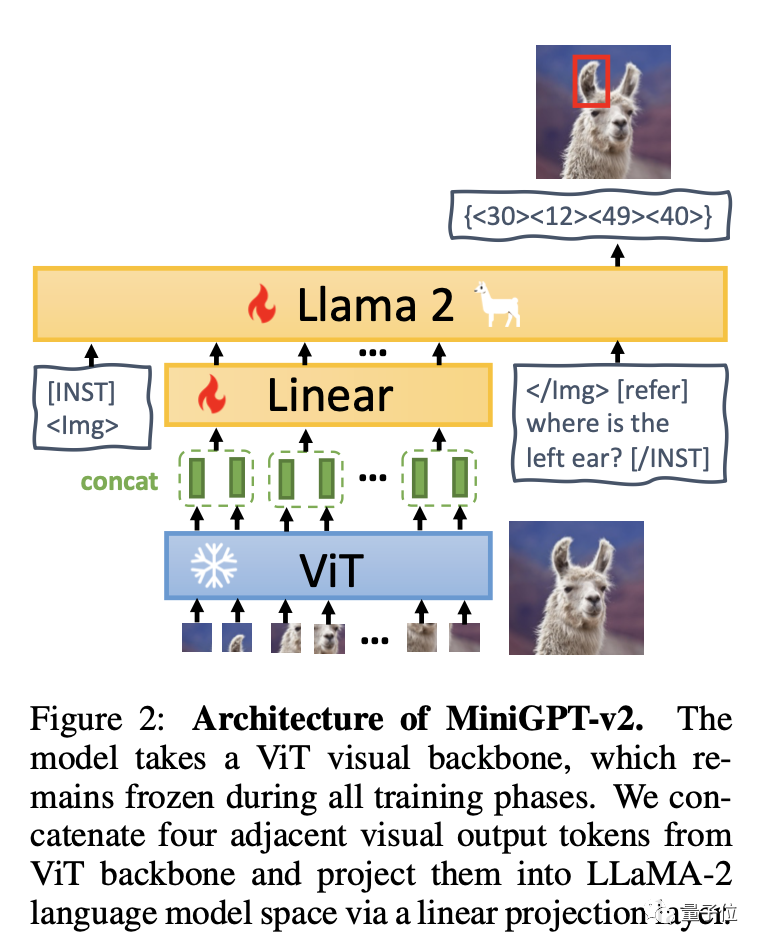
该模型以ViT视觉主干为基础,所有训练阶段都保持不变。从ViT中归纳出四个相邻的视觉输出标记,并通过线性层将它们投影到 LLaMA-2语言模型空间中。
团队建议在训练模型为不同任务使用独特的标识符,这样一来大模型就能轻松分辨出每个任务指令,还能提高每个任务的学习效率。
训练主要分为三个阶段:预训练——多任务训练——多模式指令调整。
最终,MiniGPT-v2 在许多视觉问题解答和视觉接地基准测试中,成绩都优于其他视觉语言通用模型。
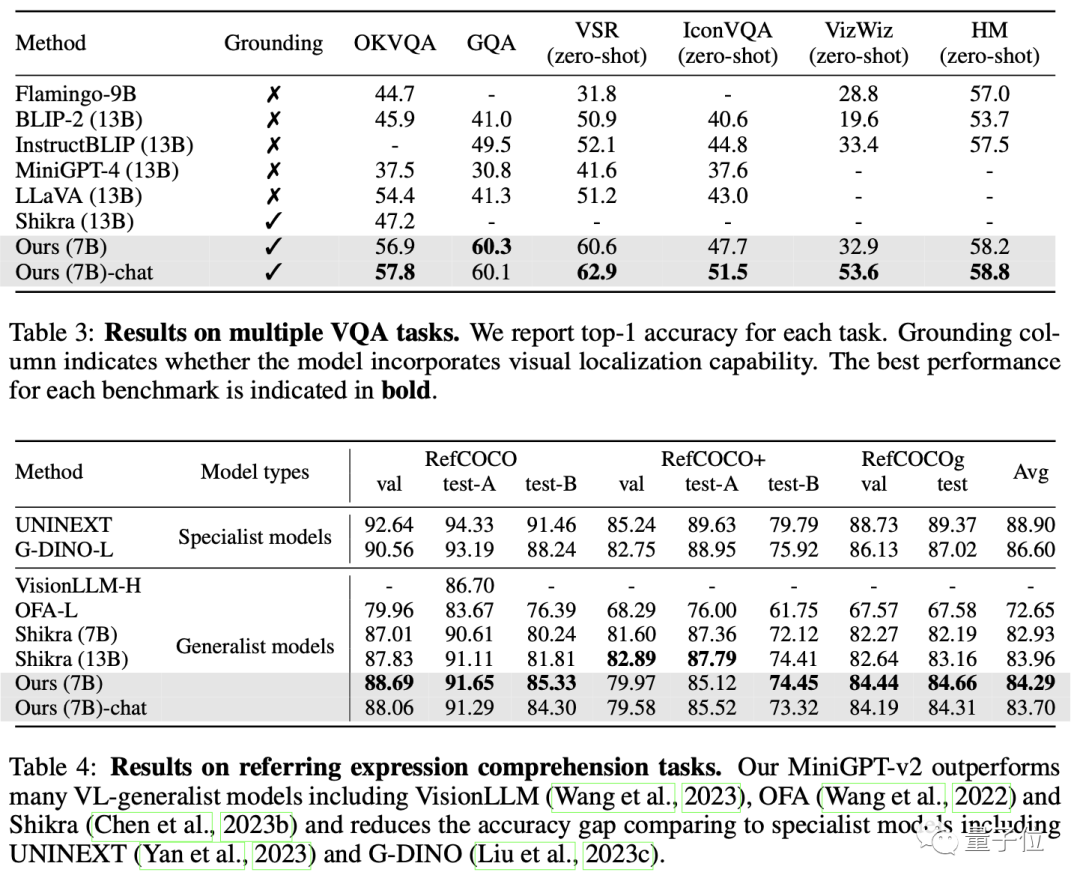
最终这个模型可以完成多种视觉任务,比如目标对象描述、视觉定位、图像说明、视觉问题解答以及从给定的输入文本中直接解析图片对象。

感兴趣的朋友,可戳下方Demo链接体验:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
— 完 —
「量子位2023人工智能年度评选」开始啦!
今年,量子位2023人工智能年度评选从企业、人物、产品/解决方案三大维度设立了5类奖项!欢迎扫码报名
MEET 2024大会已启动!点此了解详情。

点这里👇关注我,记得标星哦~

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢