

通用大模型虽好,但通过微调得到一个专属大模型不仅可以提高模型的可操控性、输出格式的可靠性和语气的一致性,还能让用户缩短提示长度,加速API调用,降低成本。
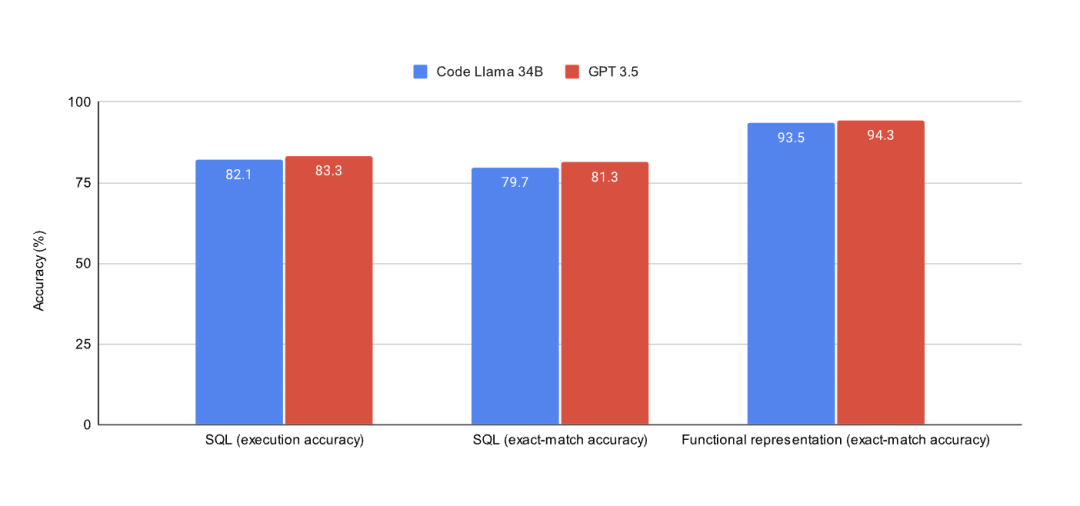
GPT-3.5在SQL任务(https://github.com/samlhuillier/spider-sql-finetune)和函数表示(https://github.com/samlhuillier/viggo-finetune)任务中的表现都略优于用LoRA微调的CodeLLaMA-34B(我发现的效果最好的模型)。
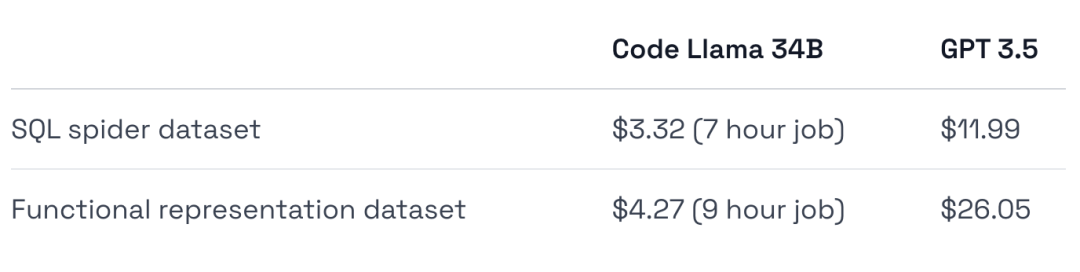
GPT-3.5的训练成本要高出4-6倍(部署成本甚至更高)。
实验设置
它们可以教导模型给出人们所期望的输出形式,而不是事实。SQL和函数表示任务都在寻求结构化输出。(这是Anyscale的建议。) 在开箱即用的情况下,预训练模型在这两项任务上表现不佳。
LLaMA架构
OpenAI很可能会做一些适配器或非全参数微调。(他们不可能同时管理和冷启动多个具有175B参数的模型。如了解相关信息请与我联系。) Anyscale的另一篇博文指出,在SQL和函数表示等任务中,LoRA几乎可以媲美全参数微调。(https://www.anyscale.com/blog/fine-tuning-llms-lora-or-full-parameter-an-in-depth-analysis-with-llama-2)
config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj","k_proj","v_proj","o_proj",],lora_dropout=0.05,bias="none",task_type="CAUSAL_LM",)
数据集
You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.You must output the SQL query that answers the question.### Input:Which Class has a Frequency MHz larger than 91.5, and a City of license of hyannis, nebraska?### Context:CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)### Response:
department : Department_IDCREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values.This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute'].The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']### Target sentence:I remember you saying you found Little Big Adventure to be average. Are you not usually that into single-player games on PlayStation?### Meaning representation:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])评估
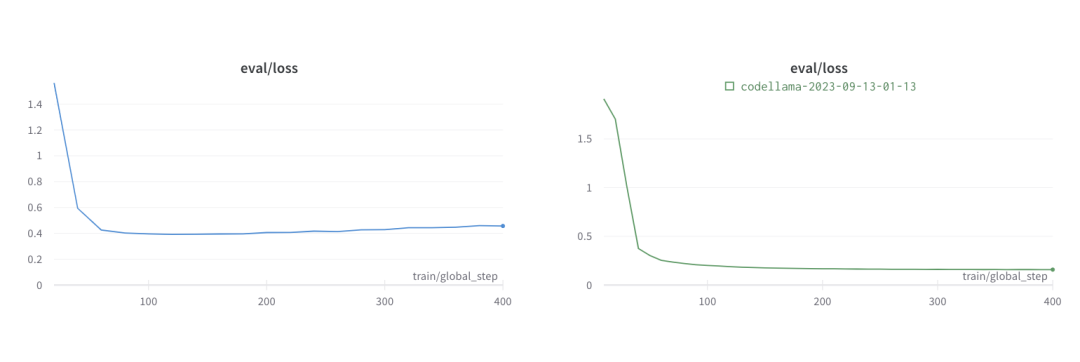
结论
想要验证微调是否为解决特定任务/数据集的正确方法
希望获得完全托管的体验
希望节省成本
希望从数据集中获取最佳性能
希望在训练和部署基础设施方面具有完全灵活性
希望保留某些私有数据
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢