
扩散模型在图像生成取得了很好的效果,但却并不适合生成分子数据,流匹配模型是更具前景的分子生成技术。

讲者介绍
周浩,清华大学智能产业研究院副研究员,他的主要的研究兴趣是面向离散符号的深度生成模型,主要应用包括文本生成,药物分子设计,新材料设计等,加入AIR前曾作为负责人领导并从零搭建了字节跳动的文本生成中台和AI辅助药物设计两个方向的研发团队,曾获中国人工智能学会优博,中国计算机学会NLPCC青年新锐学者,自然语言处理顶级会议ACL2021的最佳论文和国际文本生成大会INLG2022的最佳短论文。
报告内容
自然语言处理中文本生成的效果在不断地突破,周浩教授认为根本原因是文本生成工具(模型)在不断变强,例如从Seq2Seq,Attention,到BERT、GPT等。周浩教授今天也将分享课题组在工具(生成模型)方面做的一些探索。
分子表示
分子的3D空间结构是其最重要表示形式,因为3D空间是分子数据本身分布的空间。分子的结构即类似于自然语言的语义,对分子3D结构的刻画和建模是非常重要的。
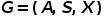 ,其中
,其中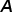 是组成分子的原子的邻接矩阵,刻画分子图的拓扑结构,
是组成分子的原子的邻接矩阵,刻画分子图的拓扑结构,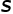 是原子类别特征,
是原子类别特征,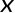 是原子坐标特征。
是原子坐标特征。分子表示的归纳偏置
不变性:不管对一个分子如何旋转平移,分子的性质和表示是不变的。 等变性:分子力场具有等变性,在旋转分子之后也会相应地改变。 对称性:分子数据天然地具有对称性。
扩散生成模型
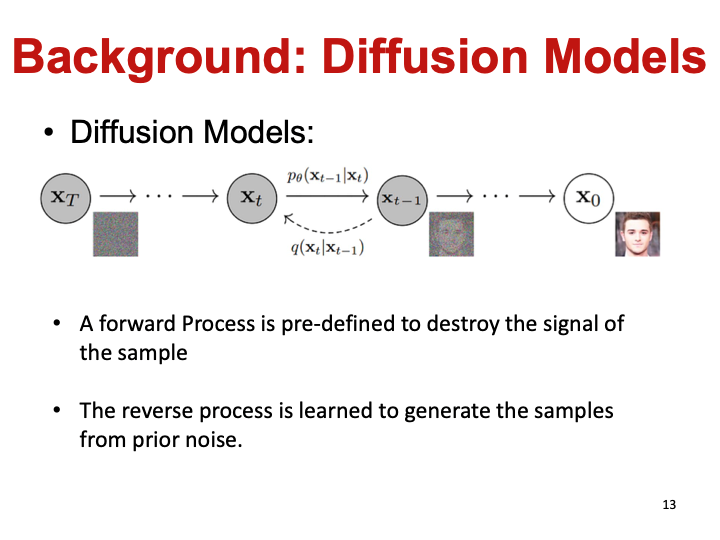
扩散模型在图像生成领域非常有效,但却不适合直接应用于分子,因为分子和图像的性质具有很大区别。
扩散模型这种粗粒度到细粒度的加噪模式很适合建模图像,因为就算给图像加了很多噪声,还是不会破坏图像结构,可以大致识别出图像。但对于分子数据,加一些噪声可能就极大地破坏了原本的语义结构,导致逐步去噪这样的学习过程太过困难。
此外,现在文本生产流行的从左往右的建模方法也不适合于分子,因为分子结构并没有从左向右的顺序性质。
接下来,周浩教授介绍其团队在3D分子生成方向的一些探索。
3D分子生成
现有方法面临的挑战
周浩教授提出目前3D分子生成不同于图像生成问题,面临着结构限制(Structure Constraint)的挑战。图像数据有着固定的内在结构,即每一个像素的位置都是固定的,这导致对图像加很大的噪声通常还是不影响对于图像的识别。但分子数据则不一样,稍微加噪改变其原子种类和坐标,就会完全破坏分子的结构,导致无法识别是怎么样的分子。这会导致训练的时候方差非常大,所以扩散模型并不适合用来训练分子生成。

流匹配模型
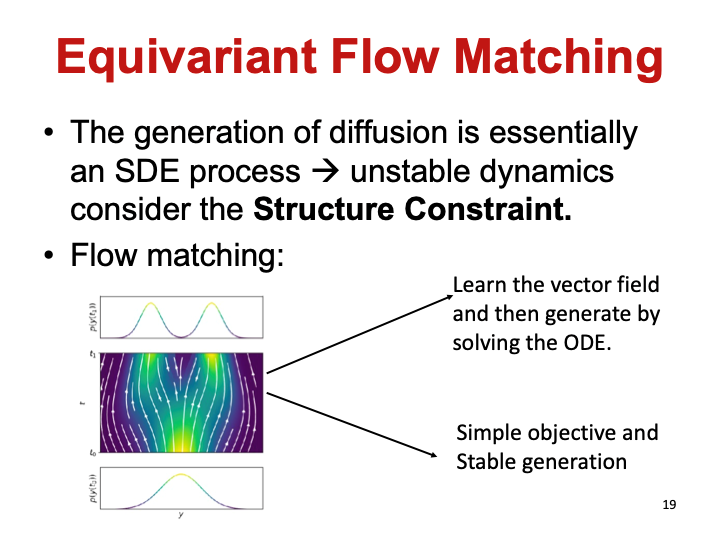
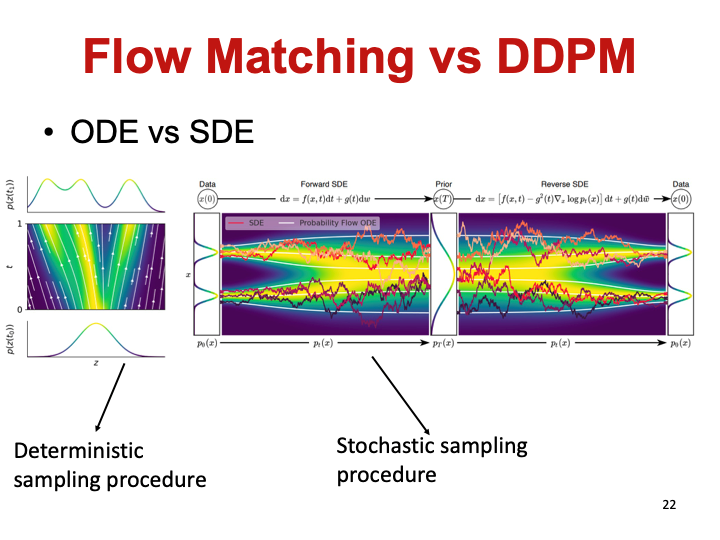
流匹配模型和扩散模型在学习目标上一致,都是学习将一个噪音分布转换成目标数据分布。只不过扩散模型的每一步预测一个噪声,而流匹配模型每一步学习匹配一个向量场。
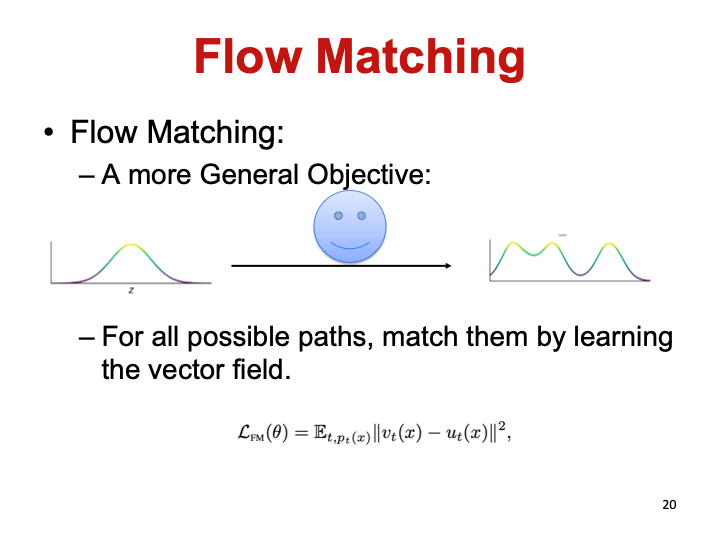
每一步的向量场由噪声和目标之间做差值而得到:
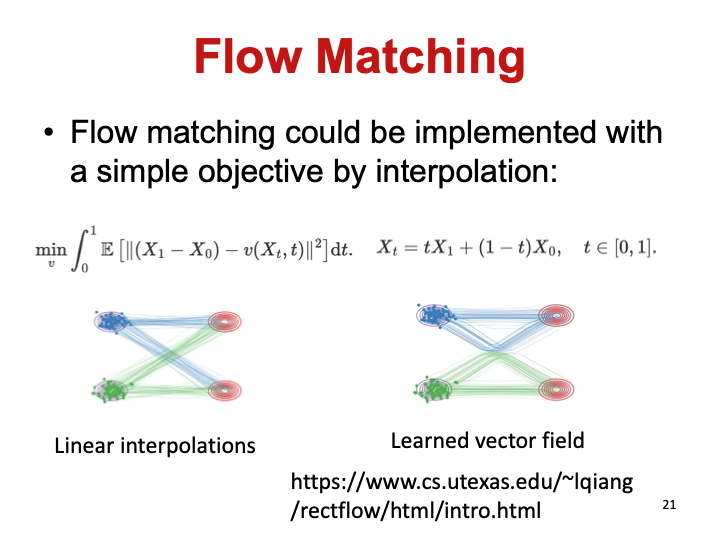
流匹配模型的学习结果是将噪音和目标分布之间学成一个确定性的过程。而扩散模型会在噪声和目标分布之间乱转,导致步数很长学习效率很低,学到的也不是合法分子。
等变流匹配模型
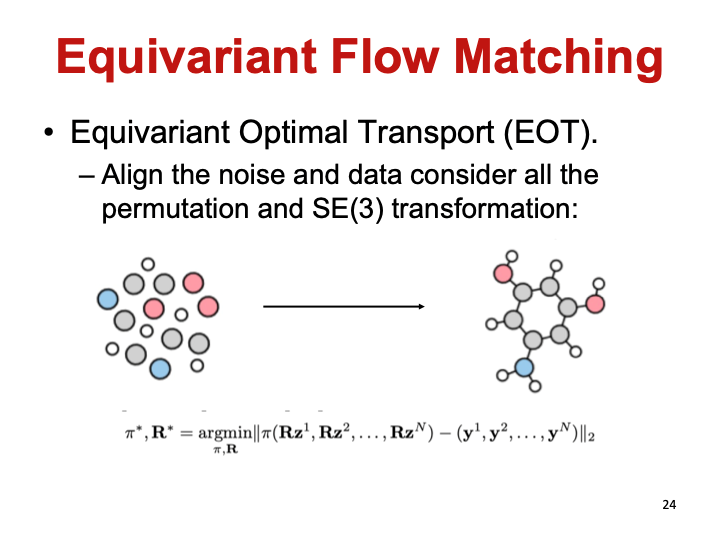
等变最优传输算法可以很好地解决分子的多模态问题。其对于离散的原子类型和连续的原子坐标可以进行同时建模,求出最优混合概率路径进行学习。

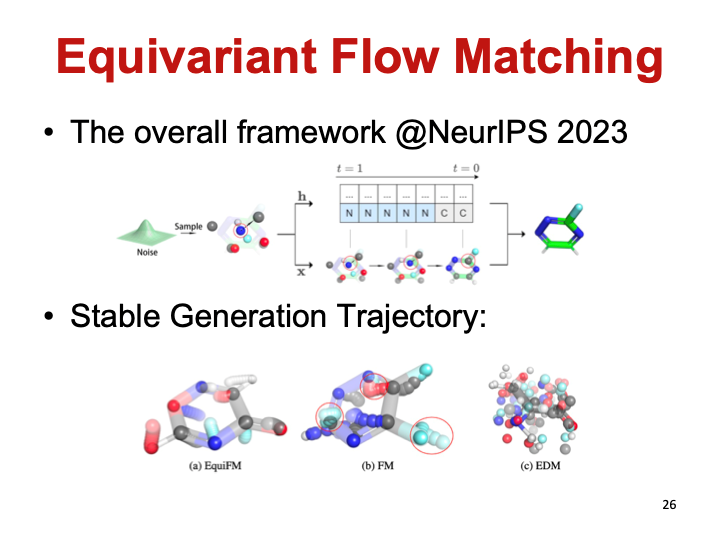
模型效果如下。等变扩散模型的生成轨迹可以明显地看出是在乱动,无法生成合法的分子;直接用流匹配模型会好一些,但生成过程还是很冗余,降低学习和推理的效率;而等变流匹配模型可以通过最优传输的路径直奔目标而去,生成合法分子的可能性和效率都大大提高。
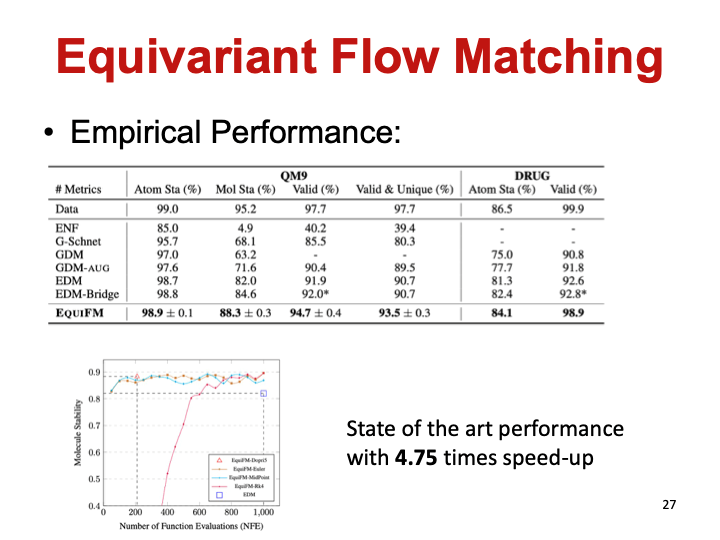
以下是一些定量结果,下图的Mol Sta指标显示,等变流匹配模型生成合法分子的可能性和稳定性相比于等边扩散模型有很大的提升,从82%提升到了88%。
更进一步地,周浩教授提出,不要在样本空间(分子3D空间)做生成,而是直接在参数空间中做生成,这是他认为更加有潜力的一种方法。
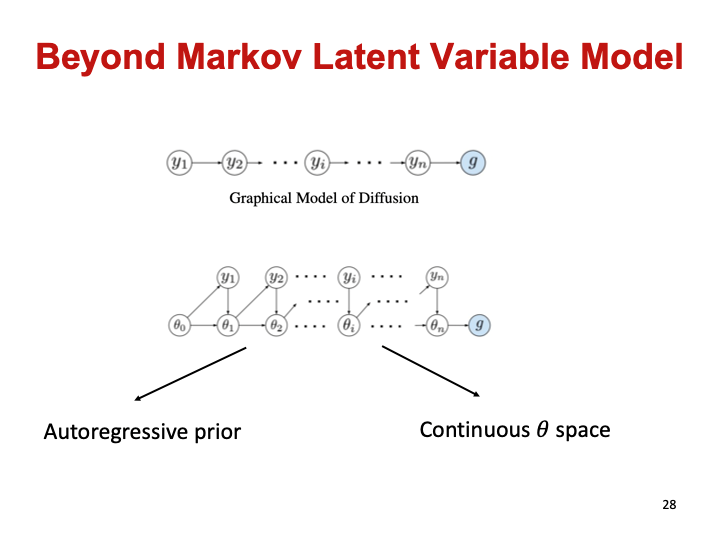
这种方法的优势是,所有的模态都在统一的连续参数空间中运作,这样自然地解决了前面所说的分子多模态问题,也会导致更小的训练方差。因为分子类型和坐标一定是属于不同空间的,不同的空间学习的时候会干预冲突。

我们验证了这种方法生成分子的合法性和生成效率同步提升,基本逼近理论的极限。
AIR长期招聘人工智能领域优秀科研人员
关于AIR
往期精彩:
【内附完整论文】AIR近期亮点论文解读
AIR学术|上交大陈思衡:图网络学习-从社交网络到车路协同
AIR快讯|BioMedGPT-10B全球首个开源可商用百亿参数多模态医药大模型
AIR观点|聂再清:“智能涌现”和“触类旁通”能力,助力大模型成为人工智能时代的操作系统
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢