
总之,我们证明目前的分子表示模型有我们没有完全理解的影响泛化能力的因素,希望通过大家的共同努力, 将泛化性问题彻底解决。

讲者介绍
田博学,研究员,博士生导师,于2020年6月加入清华大学药学院,以及清华-北大生命科学联合中心。田博学2008年本科毕业于华东理工大学,2009年硕士毕业于瑞典厄勒布鲁大学。2012年10月博士毕业于爱尔兰国立大学-高威,师从Leif A. Eriksson。2013年2月进入美国加州大学旧金山分校 Matthew P. Jacobson实验室从事博士后研究。田博学教授主要从事计算化学和计算生物学相关研究。论文发表在PNAS、JACS、PLOS computational biology等学术期刊。
报告内容
10月14日,AIR学术工作坊第5期|智能新药研发学术研讨会在AIR图灵报告厅如期举行。清华大学药学院研究员田博学教授,为我们做了题为《分子表示学习模型的局限性》的报告。
小分子表示学习模型
针对这一现象,田教授团队进行了分析,思考如何提升表示学习模型的泛化能力。进而提出了两个问题:1.为何分子表示学习模型的泛化能力比较差?2.如何使用更少的数据来训练模型?
对于第一个问题,田教授团队设计了一个分子量预测任务实验。按照经验分析,这类问题对于模型来说,只是实现了加法的计算,是一个非常简单的任务。在实验验证中,团队以分子量小于400的分子进行训练,发现得到的模型在当分子量超过400时表现非常差,泛化能力严重不足。
团队进而不使用分子表示学习模型,改为用简单的多层感知机模型进行测试,发现当使用仅有一层的多层感知机时,对于分子量预测的任务可以完美的完成。但是当使用两层的多层感知机时,模型的表现产生了严重的下降。
团队还尝试了增大训练过程中使用的数据量,对于不同数据量的训练数据进行了测试,发现当训练数据增大时,模型的表现在最初可以得到提高,但是在后来则会停止提高,并且最终低于人们的预期。因此,数据量并不是影响模型泛化能力的唯一因素。
通过一些技巧,团队得到了一些泛化能力较强的模型,并将模型的权重矩阵和泛化能力弱的模型的权重矩阵进行了对比,发现泛化能力强的模型,权重矩阵更加具有“规律性”,而泛化能力差的模型权重矩阵更加趋向于随机。这也与机器学习领域之前相关工作报导的结果一致。
为了尽可能缓解模型不能泛化的问题,田教授团队在OOD检测的方面进行了尝试,引入了摩根指纹等特征,但这种方法并不能从根本上解决模型不能够泛化的问题。
“之前的实验说明了,模型不能够外推,但是能不能内插呢?”团队进一步进进行了实验,使用分子量在350以上和300一下的分子进行训练,使其预测中间部分的分子量。在这个实验中取得的效果较好,这也从侧面说明AI在捕捉分子的相似性。
之前有工作用较小的数据点来覆盖尽可能大的化合物库,使用了贝叶斯优化的方法。同时也有工作用贝叶斯优化从大型的化合物库中寻找指定的最优解。田教授团队也在这个方向进行了一些探索。
蛋白质语言模型及其应用
团队将AlphaFold和语言模型结合起来,针对抗体的CDR-H3区域的结构进行了预测,效果远超过ESMFold和AlphaFold。团队还发现结构预测任务中,AlphaFold比较适合预测较短的序列,而语言模型比较擅长长序列的预测。
另外一篇工作是预测蛋白和DNA的结合位点。田教授认为,未来蛋白质大语言模型一定会发挥非常重要的作用,尤其是随着数据的快速积累,在未来会取得一定的突破。
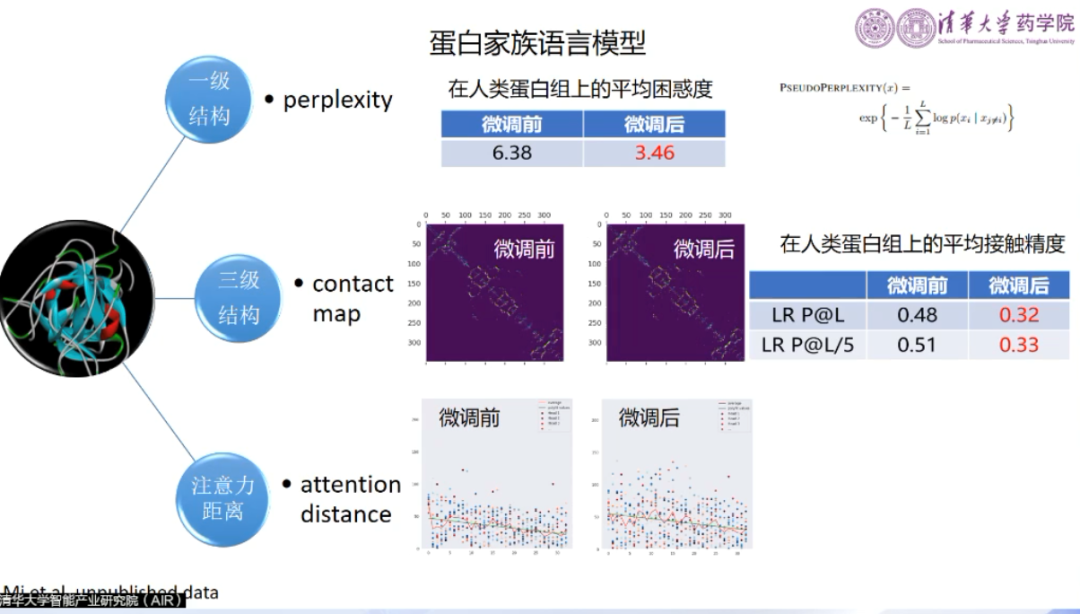
团队尝试用自然语言中的“方言”来类比蛋白质的不同家族。对于一些特定家族的蛋白质进行了模型的微调,在许多专属的任务上得到了很大的提升。如此虽然不能做到“通用”,但对于特定任务能够产生很好的效果。
田教授还回顾了团队联合清华药学院,百度飞桨,百度云智能,临港实验室举办的AI药物研发算法大赛。田教授希望比赛能够持续举办并扩大规模,吸引更多优秀的科研人员加入到AI药物研发这一领域。
AIR长期招聘人工智能领域优秀科研人员
关于AIR
往期精彩:
【内附完整论文】AIR近期亮点论文解读
AIR学术|上交大陈思衡:图网络学习-从社交网络到车路协同
AIR快讯|BioMedGPT-10B全球首个开源可商用百亿参数多模态医药大模型
AIR观点|聂再清:“智能涌现”和“触类旁通”能力,助力大模型成为人工智能时代的操作系统
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢