【新智元导读】来自英伟达等机构的研究者,竟然让GPT-4教会机器人转笔、玩魔方?通过编码大语言模型,可以完成超越人类水平的奖励设计,整个RL社区都震惊了。
GPT-4,竟然教会机器人转笔了!

英伟达、宾大、加州理工、德州奥斯汀等机构的专家提出一个开放式Agent——Eureka,它是一个开放式Agent,为超人类水平的机器人灵巧性设计了奖励功能。
论文链接:https://arxiv.org/pdf/2310.12931.pdf
项目链接:https://eureka-research.github.io/
代码链接:https://github.com/eureka-research/Eureka作者之一的英伟达高级科学家Jim Fan对此点评道:这简直就像物理模拟器API空间中的旅行者空间探测器!

以往,LLM和机器人结合的应用案例,往往是让大模型帮助机器人规划高级任务。比如,让LLM告诉机器人,把大象装进冰箱需要3步,打开冰箱,把大象放进去,再关上冰箱门。
然而控制机器人完成打开冰箱,放置大象,和关上冰箱门这3个具体的低级动作,机器人需要依靠其他的方式来控制完成。

但是英伟达等机构的研究人员开发出的Eureka系统,可以让GPT-4直接教机器人完成基本的动作。
具体来说,它是一个GPT-4加持的奖励设计算法,充分利用了GPT-4优秀的零样本生成、代码生成和上下文学习的能力,产生的奖励可以用于通过强化学习来让机器人获得复杂的具体技能。

在没有任何特定于任务的提示或预定义的奖励模板的情况下,Eureka生成的奖励函数的质量,已经能够超过人类专家设计的奖励!
从此,LLM+机器人又有了新玩法。
同往常一样,代码是开源的。

AI学者惊呼:全体RL社区都应该对Eureka论文感到敬畏和震惊。如果按他们的方法一遍一遍重复,RL会在不同的任务中取得超越人类的成功,并且完全不需要人工干预!几年前,RL似乎让业界有野心实现AGI,但后来发生的事情,让RL被降级为蛋糕上的樱桃,而LLM一直是那块缺失的拼图。如今,基于自我改进的正反馈循环很可能即将到来,进而让我们拥有超越人类的训练数据和能力。
Jim Fan还表示,Eureka可以应用机器人之外的许多场景,比如动画和游戏。
动画即是控制虚拟世界中的角色,这是劳动密集型的工作:工作室让艺术家用手画每一帧,或者让演员做MoCap。即便如此,动作也是静态数据,无法对动态变化的环境做出反应。而Eureka是通用的,提供了一种快速扩展物理逼真和响应式动画的方法。它可以成为艺术家的copilot,通过自然语言界面创造新的灵巧技能。而且,游戏甚至可以通过使用临时奖励功能微调控制器,来动态生成行为。

《艾尔登法环》的Boss战中,女神玛莲妮亚标志性的「水鸟乱舞」动作不知道需要多少天的手工工作Eureka在高级推理(编码)和低级电机控制之间,架起了一座桥梁,弥合了差距。它是一种「混合梯度架构」:一个黑盒、纯推理的LLM指导一个白盒、可学习的神经网络。
外循环运行 GPT-4 以优化奖励函数(无梯度),而内循环运行强化学习以训练机器人控制器(基于梯度)。
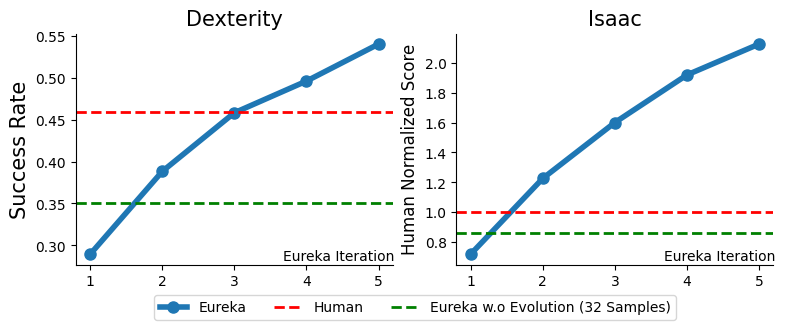
研究者之所以能扩大Eureka的规模,这要归功于IsaacGym,这是一款GPU加速的物理模拟器,可将现实速度提高1000倍。在10个机器人执行的29项基准任务中,Eureka在83%的任务中获得的奖励超过了人类编写的专家奖励,平均提高幅度达52%。研究人员展示了Eureka设计的奖励以及使用这些奖励为每个环境训练的策略:
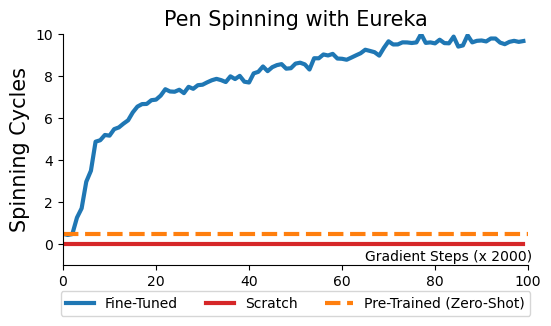
在两个开源基准测试:Isaac Gym (Isaac) 和Bidexterous Manipulation (Dexterity)中,Eureka针对10个机器人和29个独立任务设计了奖励。最让人惊讶的是,Eureka竟然学会了转笔!要知道,即使是CGI艺术家,也很难把它逐帧制作成动画。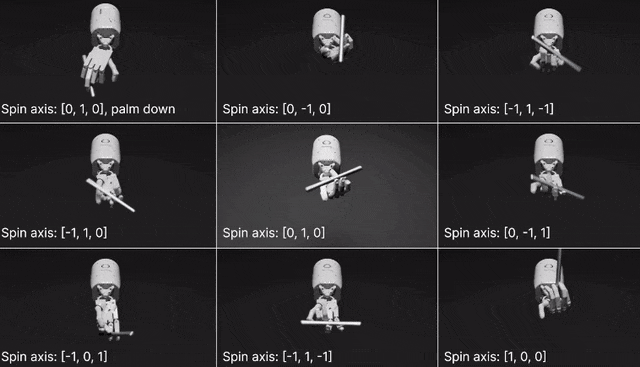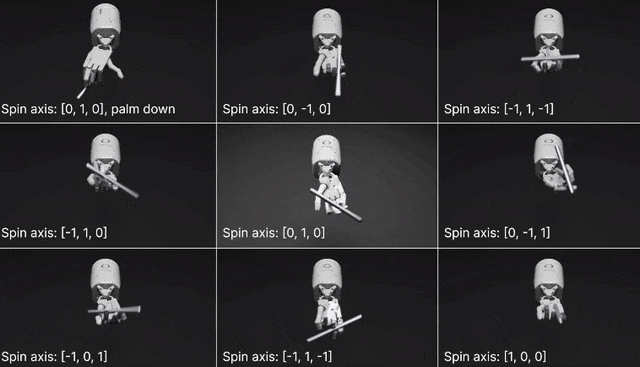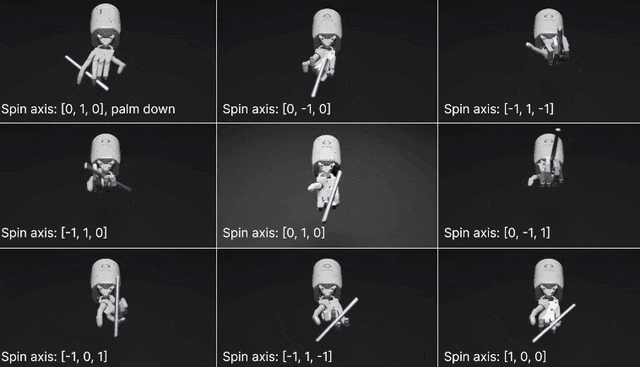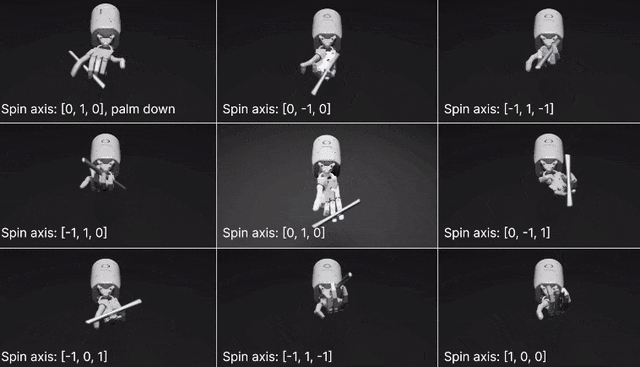
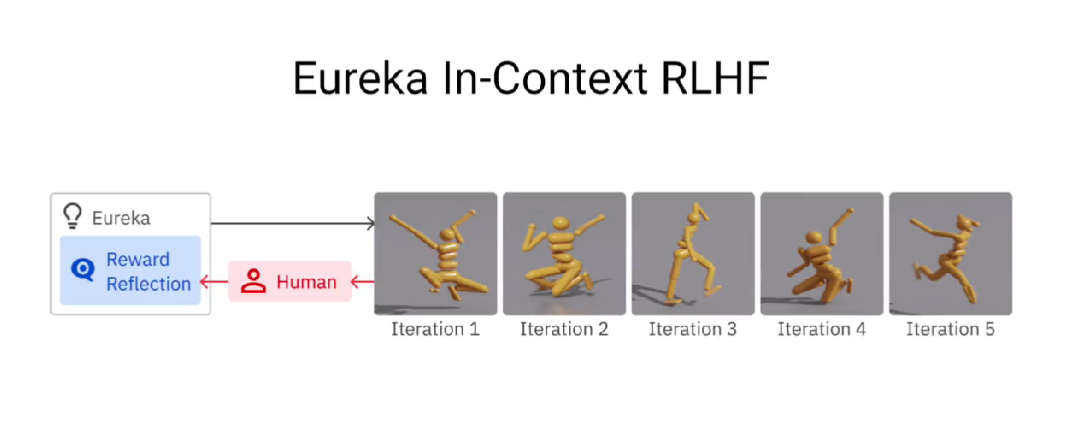
网格中心的视频展示的是笔的旋转轴垂直于手掌,将笔平行与手掌进行旋转(经典的转笔动作)。此外,研究人员还训练了围绕不同轴转笔的其他几种变体。并且,Eureka还实现了一种新形式的上下文RLHF,它能将人类操作员的自然语言反馈纳入其中,以引导和调整奖励功能。而且,机器人工程师设计复杂的运动行为时,这种RLHF还可以提供强大的co-pilot功能。在机器人学习中,大语言模型一直擅长的是生成高级计划和中级动作,比如拾取和放置(VIMA、RT-1 等),但在复杂的高频运动控制上,LLM就有所欠缺了。而Eureka时刻通过编码实现了奖励功能,这是LLM学习灵巧技能的关键入口。Eureka通过在上下文中发展奖励功能,实现了人类水平的奖励设计。
模拟器环境代码作为上下文,快速启动初始「种子」奖励函数。
GPU上的大规模并行RL,可以快速评估大量候选奖励。
奖励反射可在上下文中产生有针对性的奖励突变。
将原始环境用作LLM上下文
首先,通过使用原始的IsaacGym环境代码作为上下文,Eureka已经可以生成可用的奖励程序,而无需任何特定任务的提示工程。这就使得Eureka成为一个开放式的通用奖励设计师,在第一次尝试时就可以轻松地为所有的环境生成奖励函数。其次,Eureka 会在每个进化步骤中生成许多候选奖励,然后使用完整的RL训练循环对其进行评估。而有了英伟达的GPU原生机器人训练平台IsaacGym (https://developer.nvidia.com/isaac-gym),这一规模可以迅速扩大,将模拟时间提高了1000倍。Eureka奖励反思(Reward Reflection)
Eureka依赖于奖励反思,这是对RL训练的自动文本总结。因为GPT-4在上下文代码修复上的卓越能力,使得Eureka能够执行有针对性的奖励突变。研究人员在一系列不同的机器人实施例和任务上对 Eureka 进行了全面评估,测试其生成奖励函数、解决新任务以及整合各种形式的人类输入的能力。
研究人员的环境由10 个不同的机器人和使用IsaacGym模拟器执行的29个任务组成。首先,研究人员包括来自 IsaacGym (Isaac) 的 9 个原始环境,涵盖从四足、双足、四旋翼、协作机器人手臂到灵巧手的各种机器人形态。除了囊括了机器人外形尺寸之外,研究人员还通过纳入Dexterity基准测试中的所有 20 项任务来确保评估的深度。Dexterity包含20项复杂的双手动任务,需要一双影子手来解决各种复杂的具体操作技能,从物体交接到将杯子旋转180度。评估结果
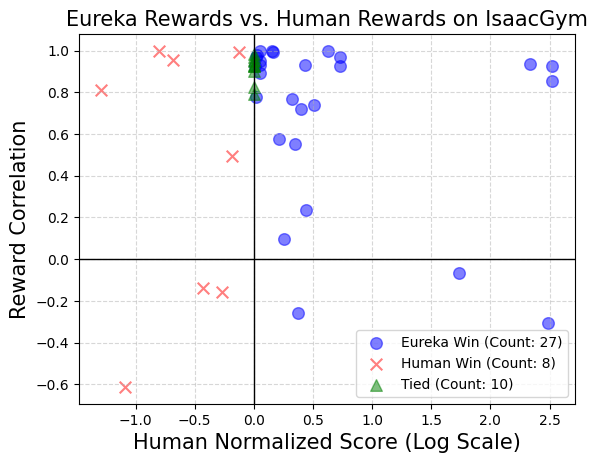
在29项任务中,Eureka生成的奖励在83%的任务上表现优于人类专家编写的奖励,平均标准化提升为52%。特别是,Eureka在高维Dexterity环境中实现了更大的收益。Eureka进化奖励搜索可以随着时间的推移实现持续的奖励改进Eureka通过将大规模奖励搜索与详细奖励反思反馈相结合,逐步产生更好的奖励,最终超过人类水平。研究人员通过计算所有Isaac任务上的Eureka和人类奖励之间的相关性来评估Eureka奖励的新颖性。如上图所示,Eureka主要生成弱相关的奖励函数,其表现优于人类的奖励函数。此外,研究人员观察到任务越难,Eureka奖励的相关性就越小。在某些情况下,Eureka奖励甚至与人类奖励呈负相关,但表现却明显优于人类奖励。通过课程学习来教会灵巧转笔
转笔任务需要影子手不断旋转笔,以实现一些预定义的旋转模式,完成尽可能多的循环。(1)指示 Eureka 生成奖励函数,用于将笔重新定向到随机目标配置,然后(2)使用 Eureka 奖励微调此预训练策略以达到所需的笔序列-旋转配置。如图所示,Eureka微调很快就适应了策略,成功地连续旋转了许多个周期。相比之下,预训练或从头开始学习的策略连单个周期都无法完成。Eureka能否根据人类反馈进行调整呢?
目前为止,Eureka可以通过环境反馈全自动运行。为了捕捉人类的细微偏好,Eureka还可以使用自然语言反馈来共同引导奖励设计。带有人类反馈的Eureka只用了5次查询,就教会了人形机器人如何稳定地跑步!https://eureka-research.github.io/
内容中包含的图片若涉及版权问题,请及时与我们联系删除







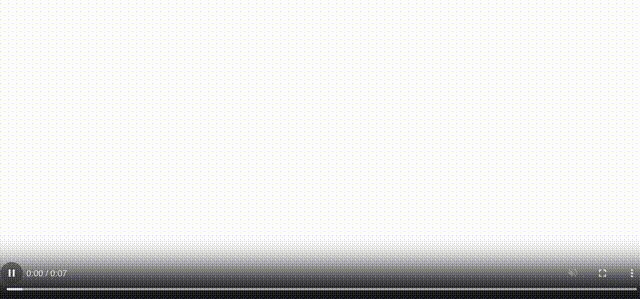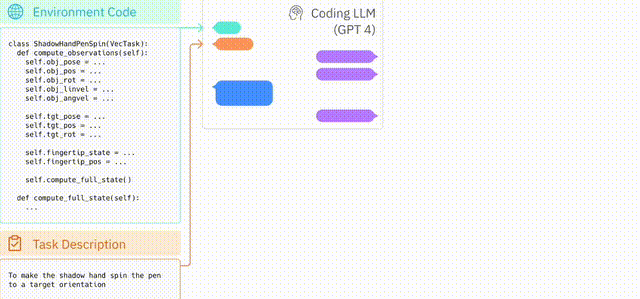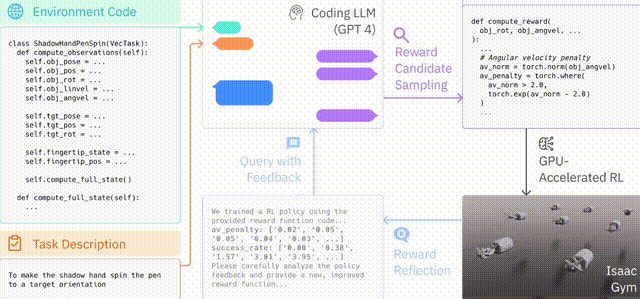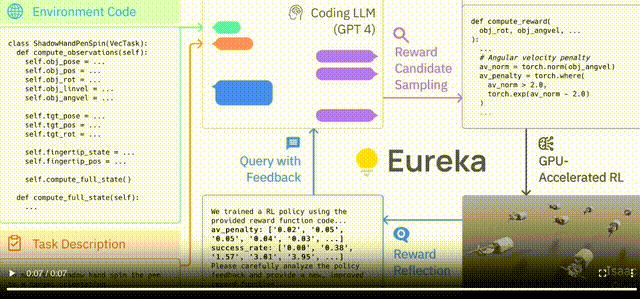










评论
沙发等你来抢