
多轮对话问答数据采集平台是为了采集中文多轮对话问答数据而设计。鉴于目前基于机器阅读理解的多轮对话问答研究中采用的数据集大多为英文数据集(如SQuAD, CoQA, QuAC等),且数据规模不大,非常缺乏中文的问答数据。
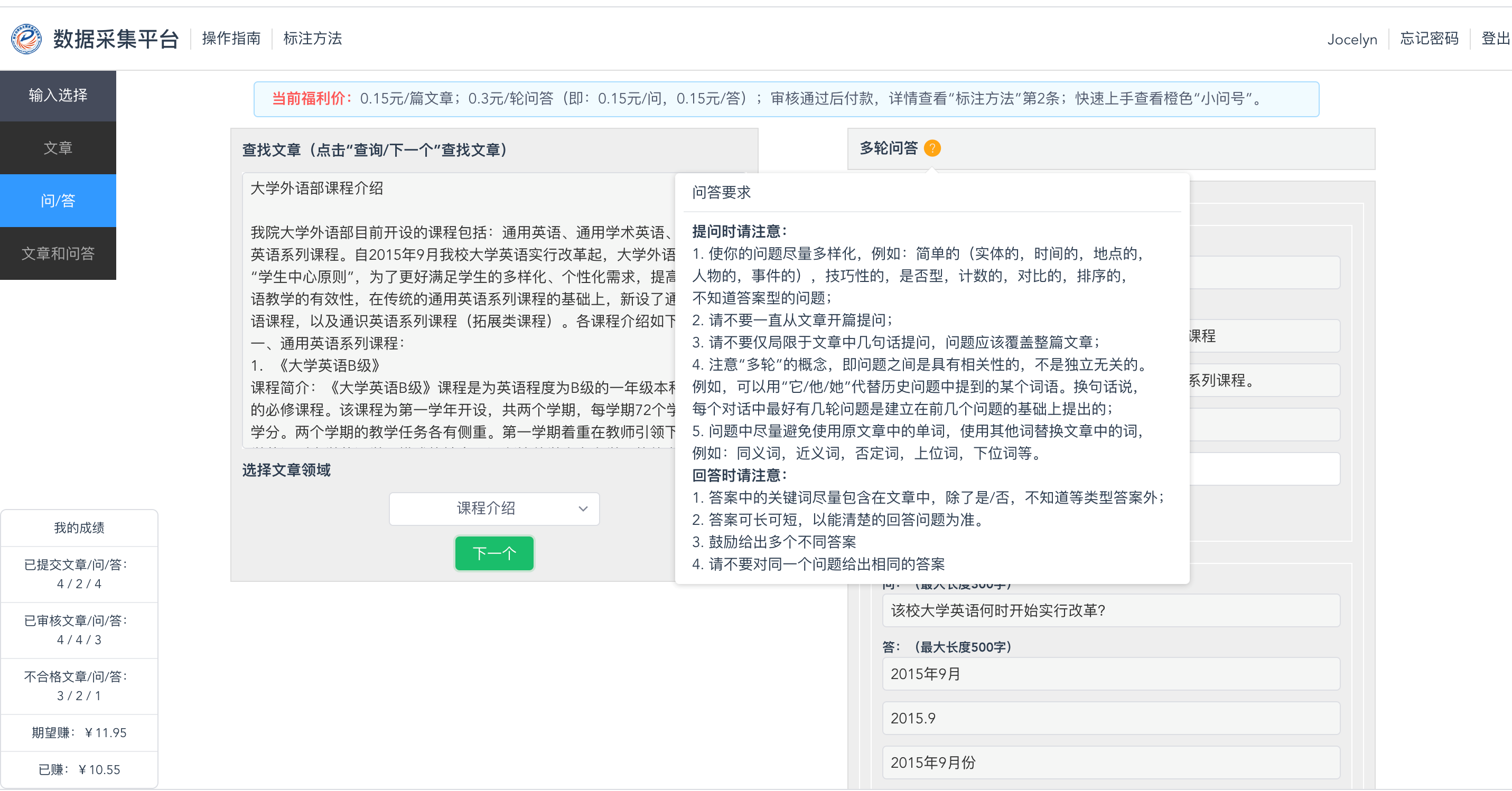
为了开展基于机器阅读理解的中文多轮对话问答研究,同时为中文多轮对话问答方向的研究提供丰富的标注数据集,促进中文多轮对话问答研究的发展,本课题组搭建了多轮对话问答数据采集平台(前台:http://qadata.founderit.com:8080 ;后台:http://qadata.founderit.com:8080/admin),该平台具有以下特点: 1. 该平台分为前台和后台,前台供标注者提交数据,后台供审核人员审核数据。 2. 该平台面向社会开放,采用众包方式有偿采集数据,任何有基础阅读理解能力的人员均可通过此平台提交文章、问题和答案数据,数据审核通过后,我们为其提供相应的劳动报酬(当前福利价:0.15元/篇文章;0.3元/轮问答(即:0.15元/问,0.15元/答);审核通过后付款,详情查看“标注方法”第2条。)。 3. 如图1所示,主要分为三种提交方式:(1)仅提交文章;(2)仅提交问题和(或)答案;(3)同时提交文章、问题和答案对。标注人员可选择其中任一方式进行标注和提交,主界面左上角有具体的标注方法,同时,在问题答案标注区的上方小问号处有标注方法提示(鼠标滑过即会显示提示),如图2所示,以及在标注框中有潜在的标注重点提示。

- 采集领域覆盖范围广,包含:政府政策、热点新闻、儿童故事、育儿知识、初中/高中试题、课程介绍、历史、文学、科学、金融、百科、社交网等十多个领域。
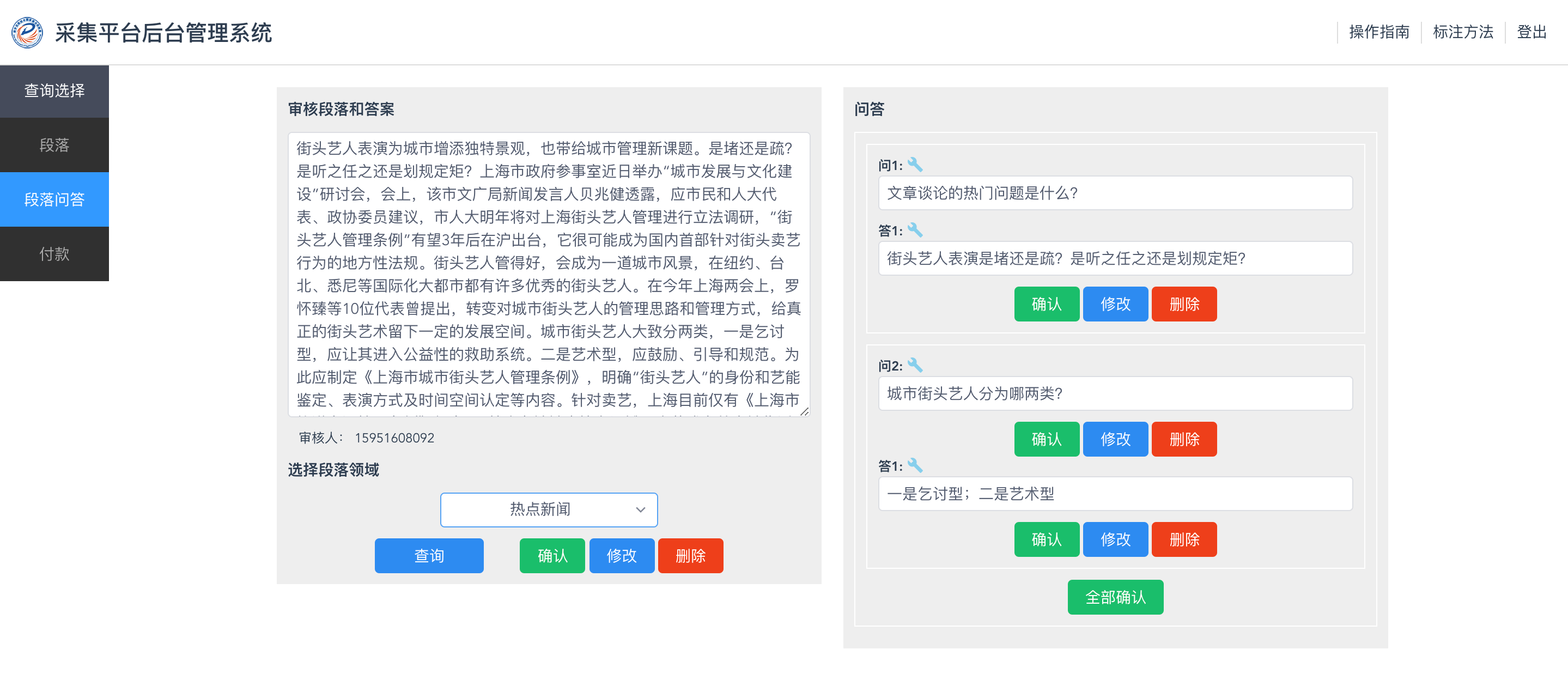
- 如图3所示,后台有增删改查及付款功能,对后台审核数据感兴趣的人员通过审核培训后,利用后台审核数据,我们根据审核数量支付劳动报酬。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢