

fastNLP是由复旦大学邱锡鹏教授领导开发的基于深度学习的自然语言处理框架。我们的代码已经在gitee和github开源:
在fastNLP中我们将NLP任务中的各个部分抽象成了对应的类,通过这些类fastNLP得以模块化,可以在不同任务间复用大部分构件,简化NLP相关任务的开发工作。
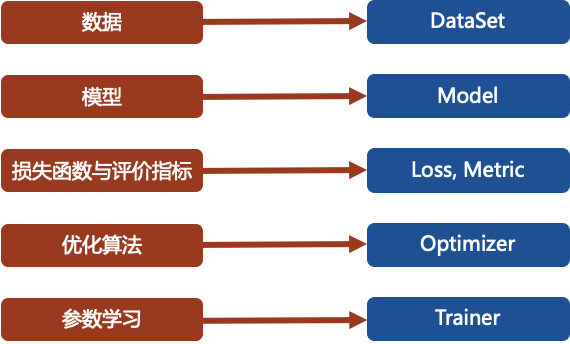
具体来说,fastNLP中包含了以下的类
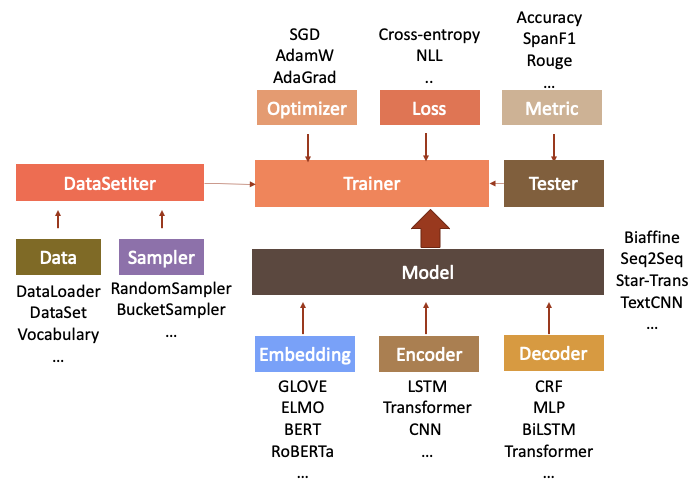
为了承载以上的类,fastNLP主要由以下的文件结构构成

那么使用fastNLP有什么好处呢? • Tabular式的数据结构 • 预处理、模型代码参考 • 高效切换Glove、ELMO、 BERT等 • 开箱即用的可扩展训练、测试代码
Tabular式的数据结构
在索引数据的时候,我们习惯于通过数据下标获取某个样本;而对于神经网络的批处理来说,需要整列读取具有相同性质的数据。在fastNLP中,DataSet可以通过下标索引某个sample,同时通过类的方式存储,方便批处理。
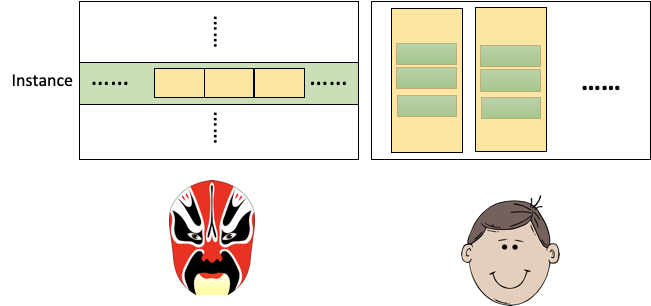
预处理、模型代码参考
在fastNLP中我们提供了多个数据集的预处理代码
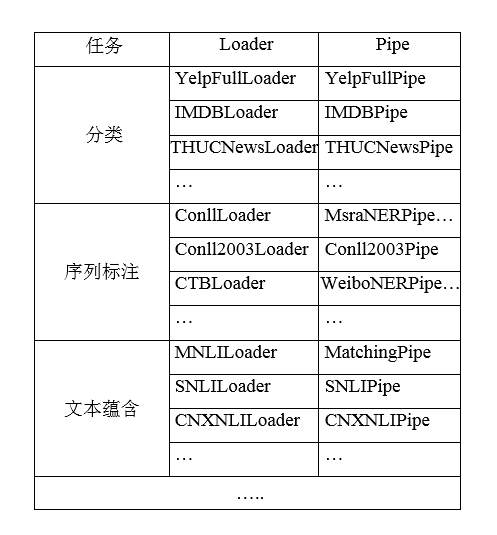
fastNLP同时也提供了多种模型的实现方便直接使用
高效切换Glove、ELMO、 BERT等
不同的任务可能需要使用不同的embedding,并且在上下文预训练时代,我们甚至需要使用BERT/RoBERTa作为embedding。在fastNLP中,可以通过一行代码切换不同的embedding或者组合多种embedding

代码示例:

开箱即用的可扩展训练、测试代码
在fastNLP中我们提供了便捷的、可扩展的训练、测试代码。通过使用callback函数,可以在训练的多个阶段插入自定义的操作

用fastNLP做文本分类
现在大家都知道BERT的效果非常好,如果想使用BERT来进行文本分类,在FastNLP中需要几步呢?答案是只需要4步即可。通过借助fastNLP中的数据预处理代码、模型和Trainer,我们可以快速开发、试验不同的模型。

用fastNLP做序列标注
fastNLP中同样也提供了中文序列标注的相关代码。通过如上的几行代码即可实现中文命名实体识别模型的训练

fitlog:可视化、可交互调参工具
在使用fastNLP的过程中,我们发现尽管写代码的过程可以被fastNLP极大地简化,但是调参的过程还是比较麻烦,需要手动记录超参数及实验结果等,这个过程不但效率较低,而且容易出错。为了解决这个痛点,我们开发了fitlog这个可视化、可交互的自动记录工具。
在fastNLP中使用 fitlog 非常容易,只需要使用一个FitlogCallback就可以进行实验记录。

在实验过程中,我们可以在本地启动一个网页服务实时地查看结果。这里是一个前端页面的例子,每一行记录了一次实验的超参数、实验结果等信息。我们提供了非常多的交互方式,例如下拉筛选,针对特定实验进行备忘编辑等。相较于Tensorboard,fitlog更关注于不同超参数之间的性能对比,所以在 fitlog 中可以选择多条实验记录直接计算性能的平均值、方差等。
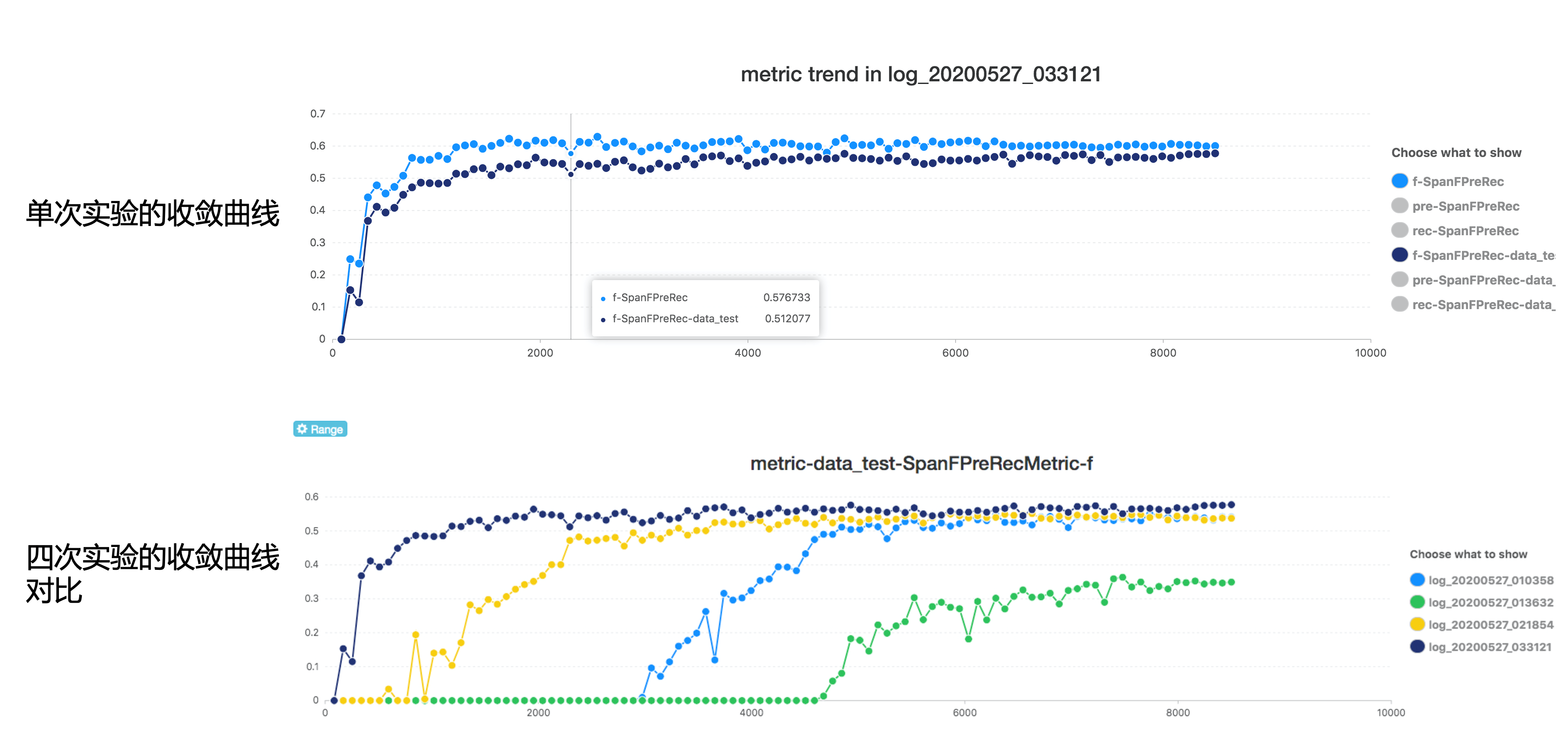
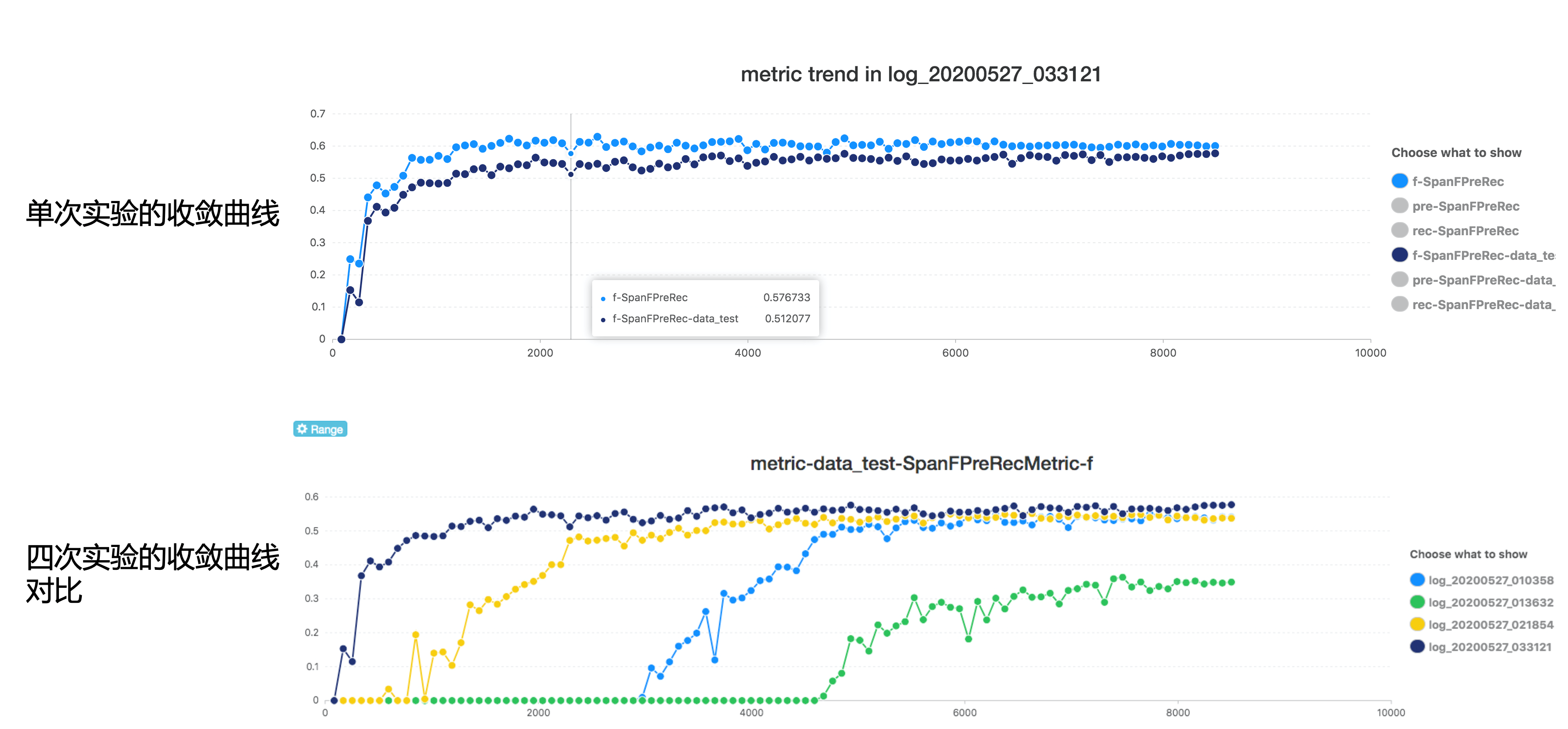
fitlog也支持查看loss和metric的收敛曲线。既可以查看某次实验的优化过程,也可以查看多次实验收敛的对比情况。
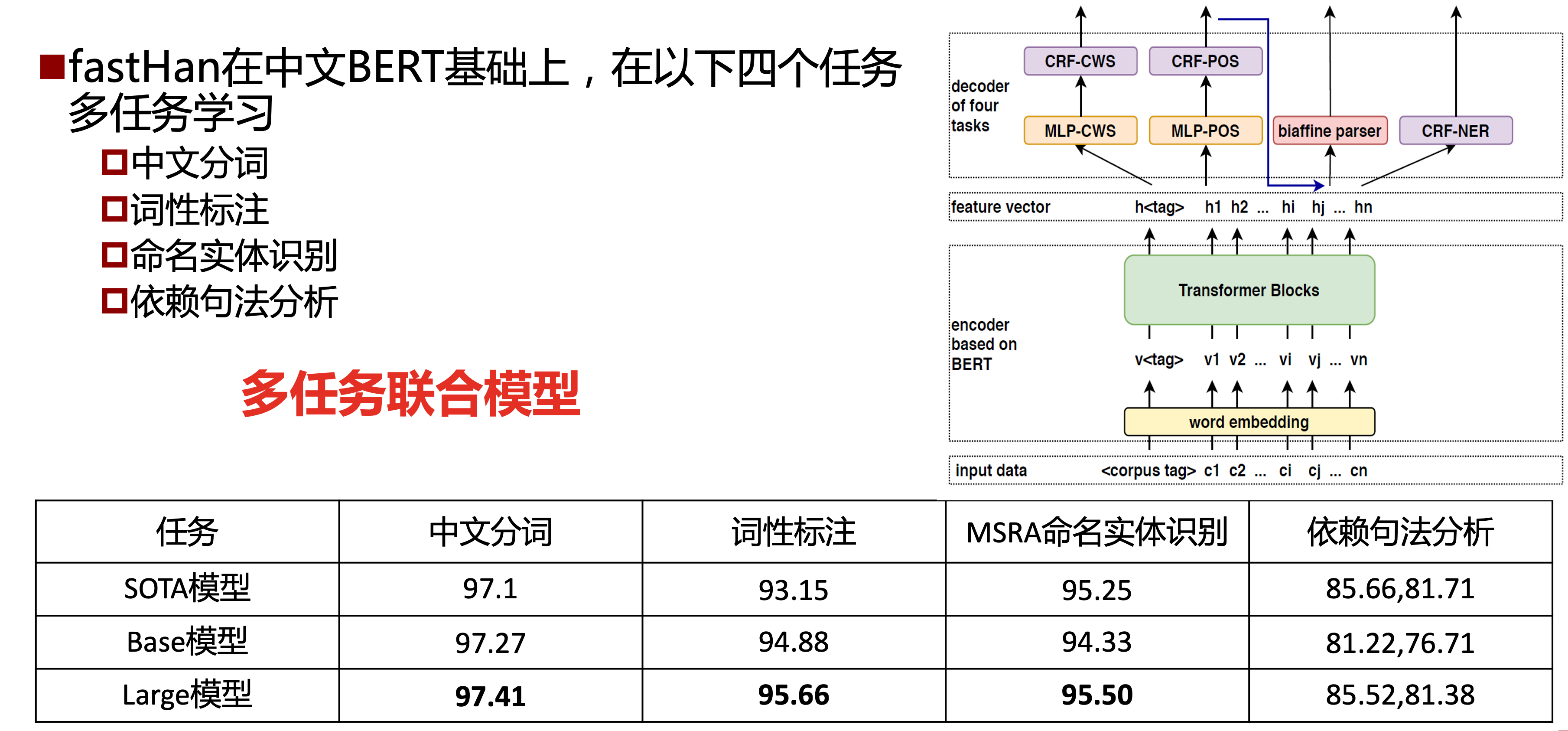
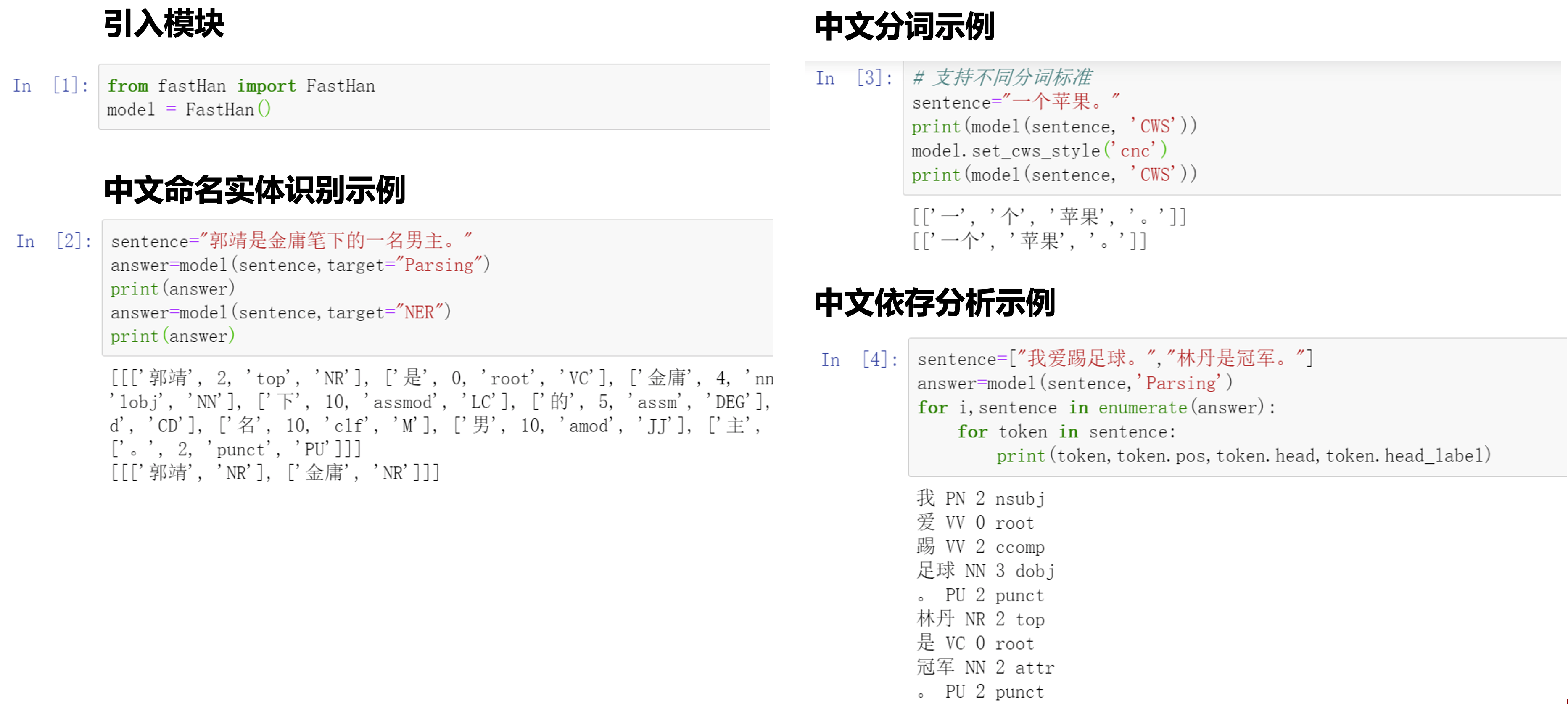
fastHan:中文自然语言处理工具包
通过结合多任务学习以及我们在中文句法任务上的相关研究,我们得以使用一个深度学习模型同时完成中文分词、词性标注、实体识别、句法分析等任务,并达到或接近了目前最好的性能。
这里是实际使用的例子,fastHan会自动下载模型权重,可以上手即用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢