
科技文献挖掘系统
ScienceHammer是一个计算机科学领域的数据挖掘系统,利用自然语言处理与文本挖掘技术,从海量科技文献中提取出结构化信息,构建科技知识图谱。在该系统中,我们着重于:(1)整合多个来源的学术数据,主要包括开放的会议和期刊论文,抽取文本为信息抽取提供数据支撑;(2)提供一套完整的知识图谱构建流程,包括实体识别,关系抽取,知识融合等;(3)将知识图谱应用于其他智能系统,提供基础服务,为后续信息检索、人机对话、推荐系统等下游任务提供基础支持,快速高效地为计算机科学领域内多种需求的学术任务提供解决方案。 体验链接:http://101.124.42.4:4999/zh-hans/
一、科技知识图谱系统
科技知识图谱基于计算机领域的海量文献构建,以实体概念为节点、关系为边,构建并展示了计算机科学领域内的大型语义网络,经过不断地扩展与深化,实体关系三元组的数量达到1000万量级,对实体之间的联系进行了充分且系统的挖掘和抽象。通过输入用户感兴趣的实体词,可以进一步展示以该实体词为中心的知识网络。
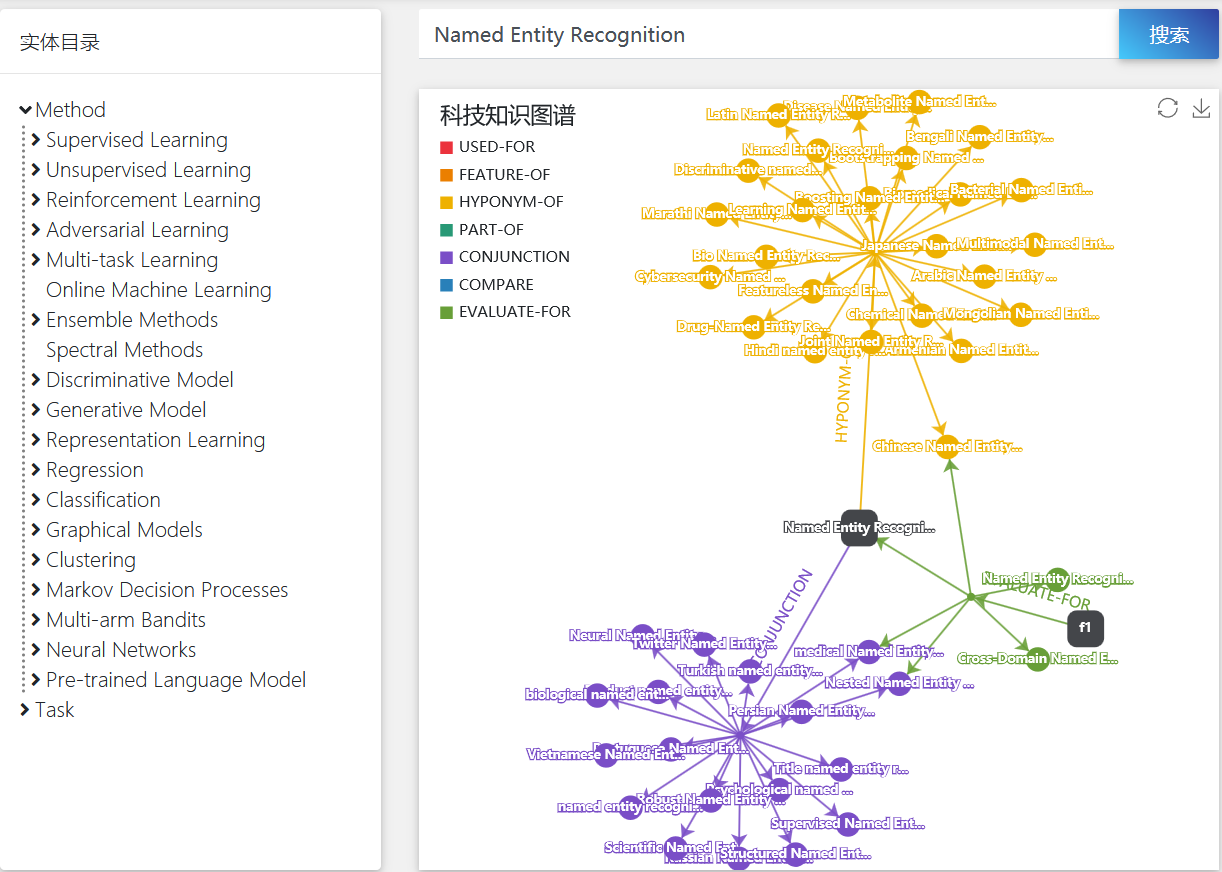
二、信息抽取系统
从给定的非结构化或半结构化文本文档中提取计算机领域相关的结构化信息,包括task等六类命名实体的识别,以及used-for等七类实体间关系的抽取。本系统支持纯文本和PDF文档两种形式的文本信息抽取,抽取结果可导出为JSON文件,为后续其他自然语言处理任务提供基础支持。
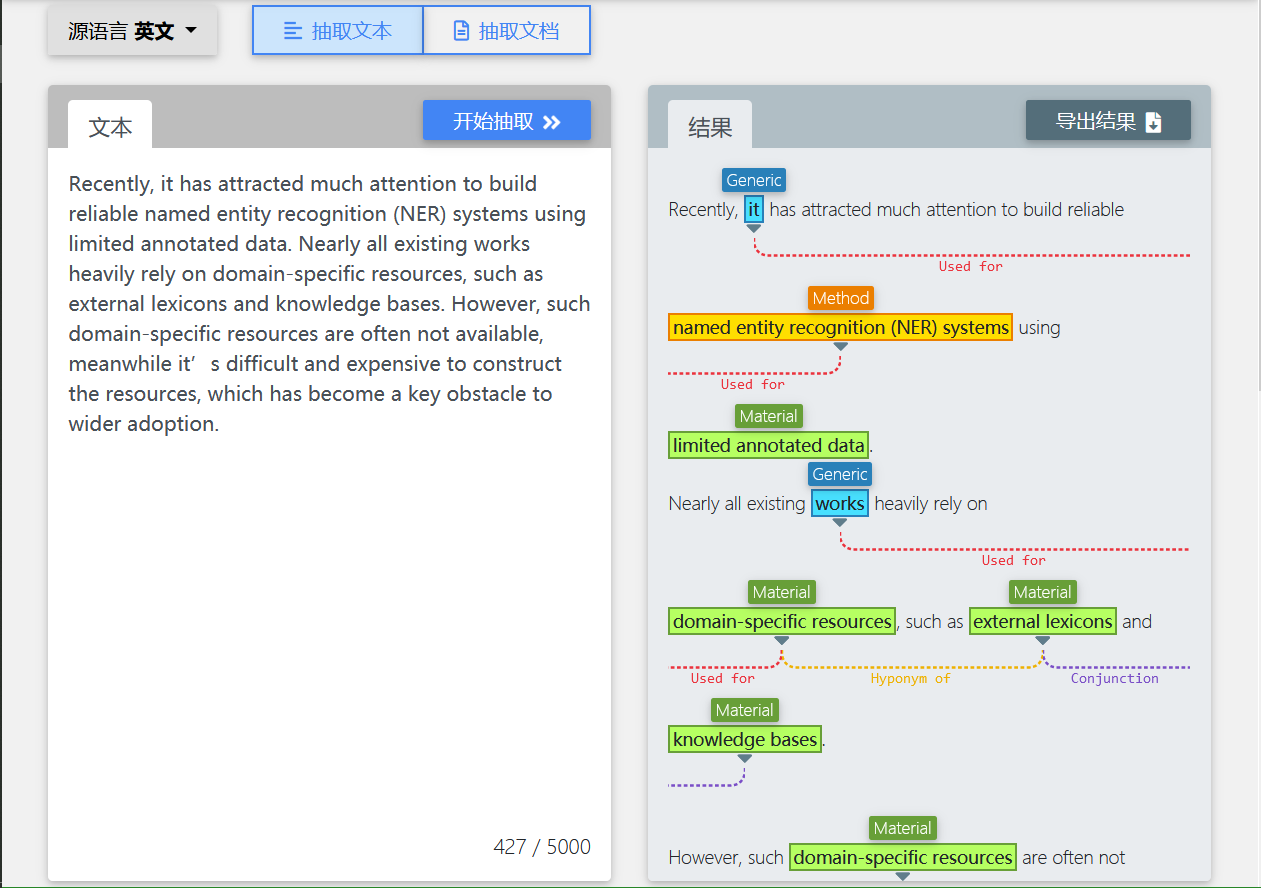
三、会议文集抽取系统
抽取历年来计算机领域相关会议的论文概要信息,对多个来源的学术数据进行合。对于系统目前支持的ACL等七大计算机领域开放会议和期刊论文,可选择生成2010到2020年的会议论文概要列表,包括论文题目、作者、摘要以及原文链接,有助于用户快速获取论文的有效信息,并为信息抽取等任务提供数据支撑。
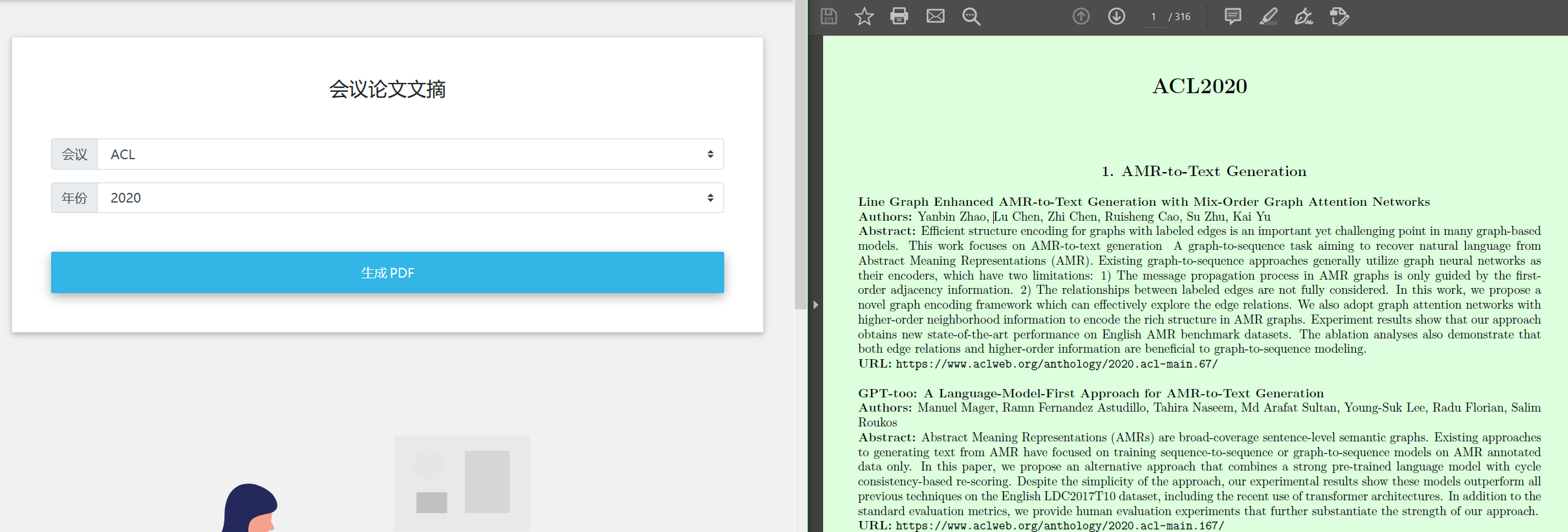
四、PDF文本抽取
目前科技文献主要存储形式为PDF, PDF已成为电子文档发行和数字化信息传播的一个标准,其广泛应用于学术界的交流以及各类公告的发行。如何从非结构化的PDF文档中抽取结构化数据是知识图谱领域所面临的一大挑战。本系统集成了PDF文本抽取功能,对科技文献中的复杂文本进行结构化抽取,为信息抽取提供数据支持。

五、论文标题生成
论文标题反映了论文的研究主题,而且论文标题通常作为该论文检索的索引。一个高质量的论文标题可以吸引更多读者阅读论文。本系统提供了论文标题生成功能,研究者输入论文摘要,系统可以生成多个候选的论文标题,研究者可以在这些生成的标题上更改得到最终的论文标题。

六、学者关系网络
一个研究者往往会在某方向上有多个工作,以一个研究人员为中心,其合作者和发表的论文列表可以很好的反映某方向的研究现状。本系统提供计算机科学领域学者关系网络,输入研究人员姓名,可以返回研究人员的合作者和研究人员发表的论文列表。
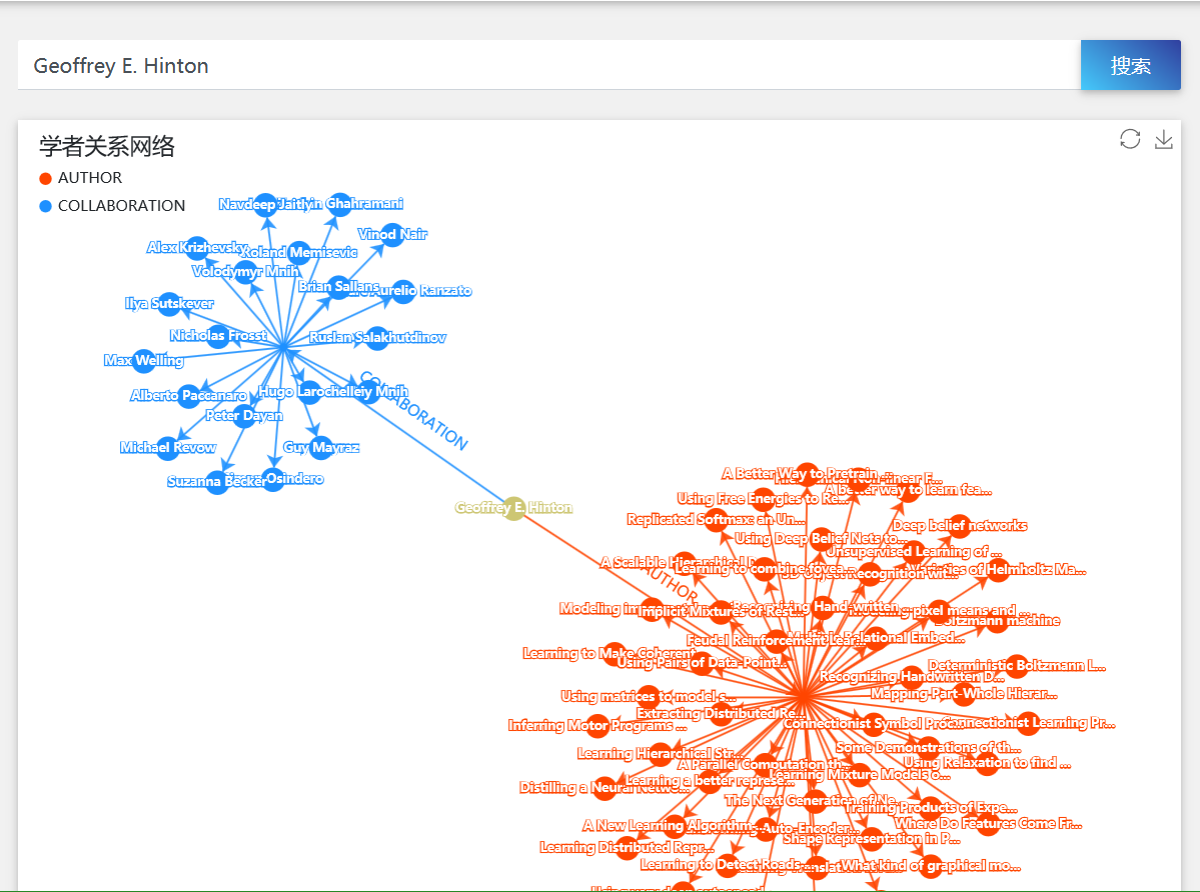
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢