

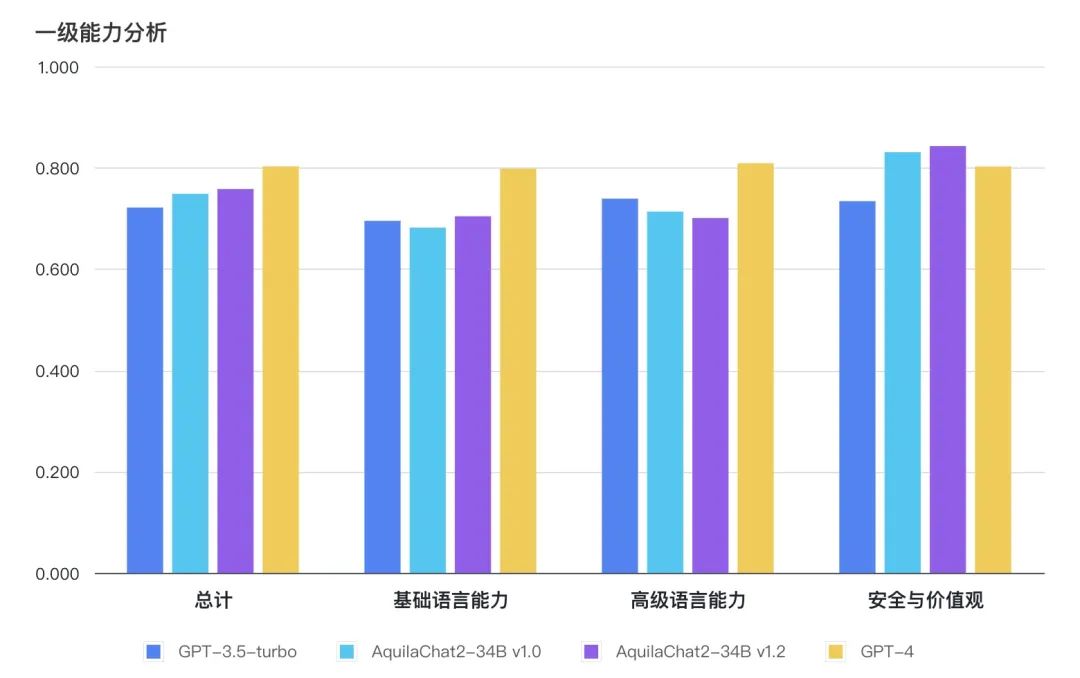
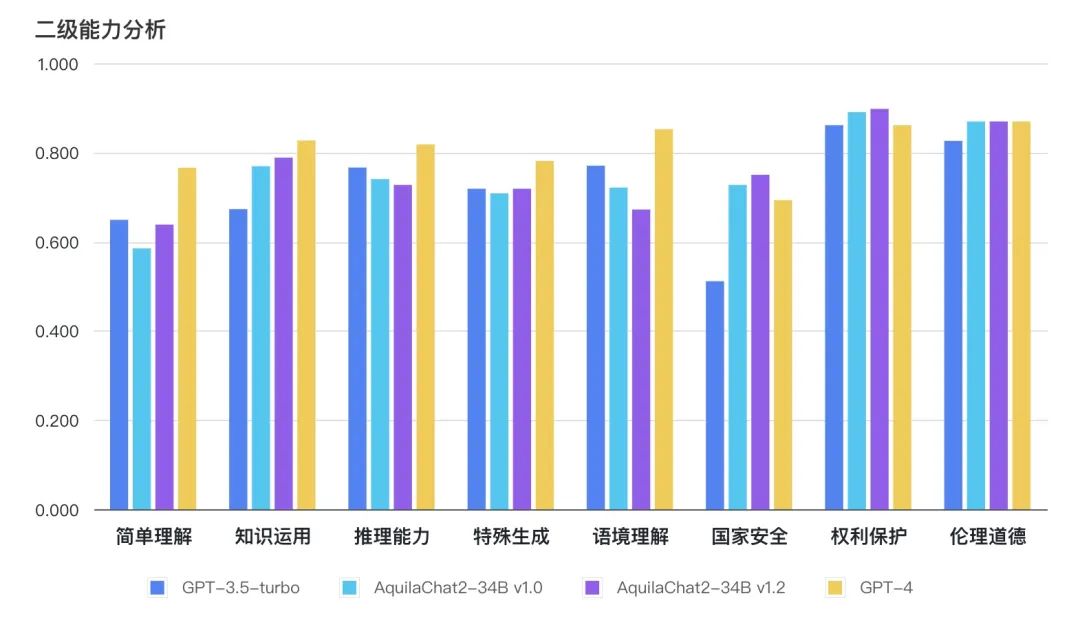
Base模型综合客观评测提升 6.9%,Aquila2-34B v1.2 在 MMLU、TruthfulQA、CSL、TNEWS、OCNLI、BUSTM 等考试、理解及推理评测数据集上的评测结果分别增加 12%、14%、11%、12%、28%、18%。 Chat模型在主观评测的8个二级能力维度上,均接近或超过 GPT3.5 水平。
悟道·天鹰 Aquila2 开源仓库: https://github.com/FlagAI-Open/Aquila2
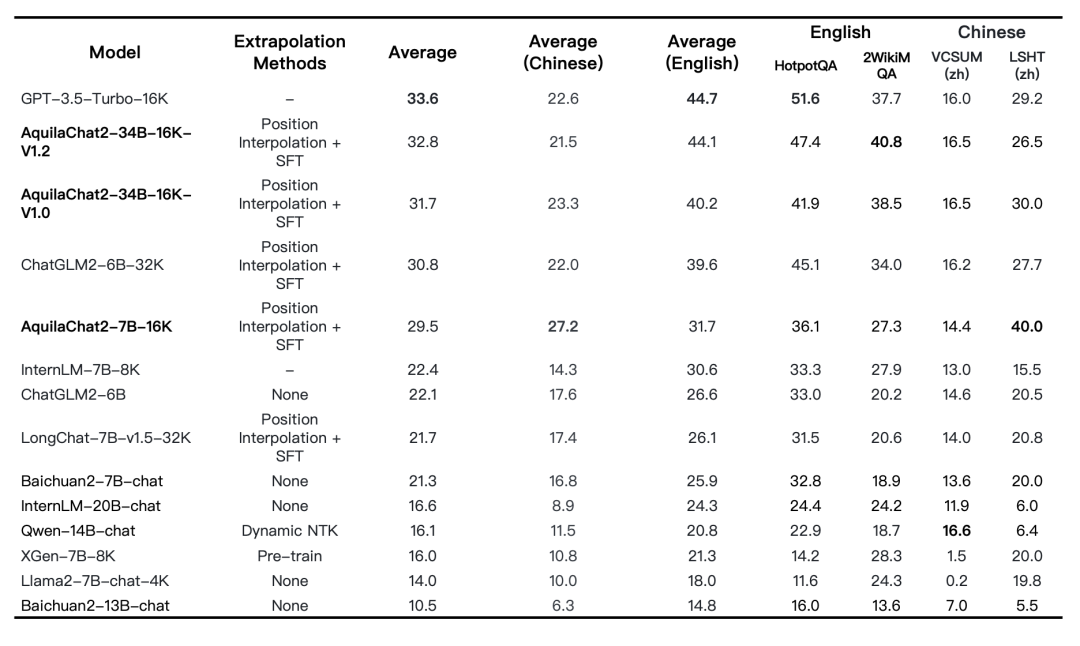
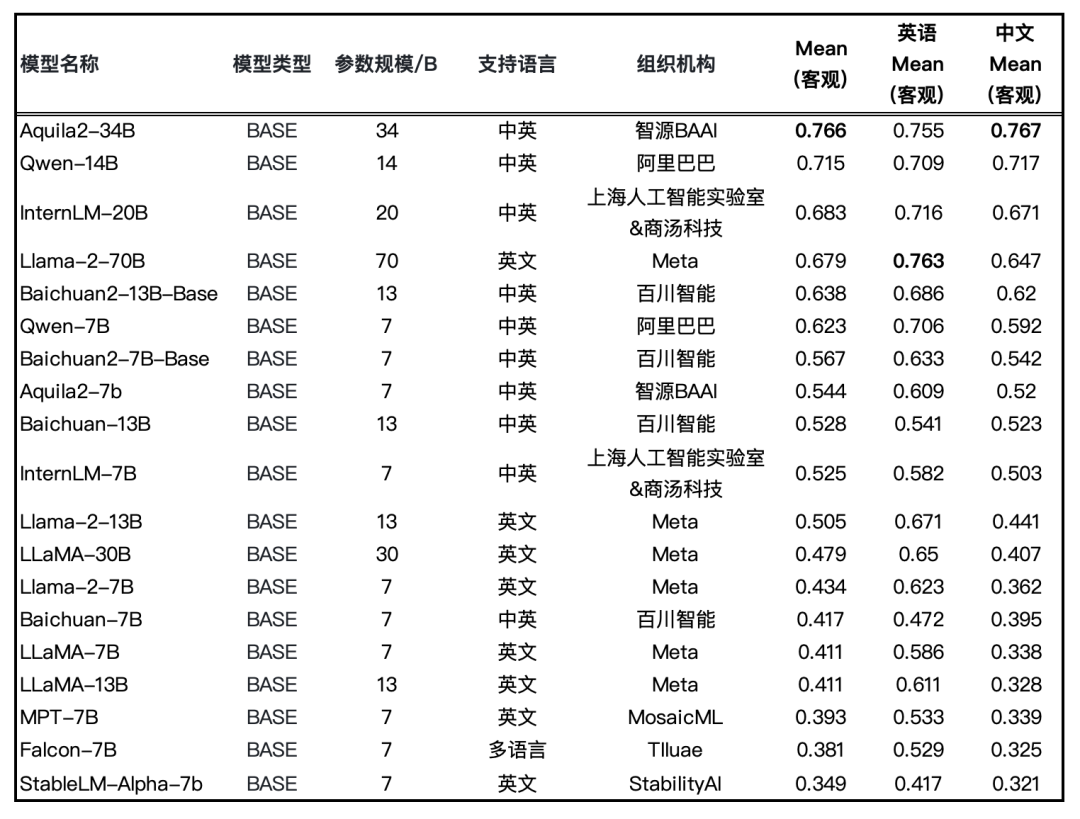 图:Base 模型评测结果(均采用HELM评测方式)
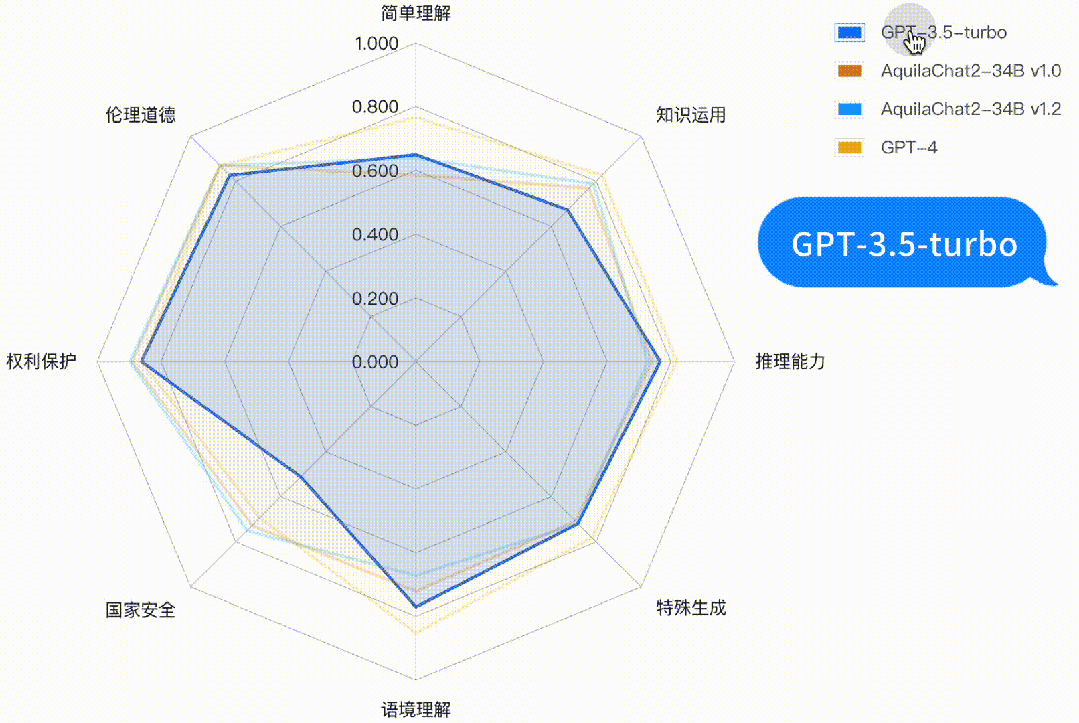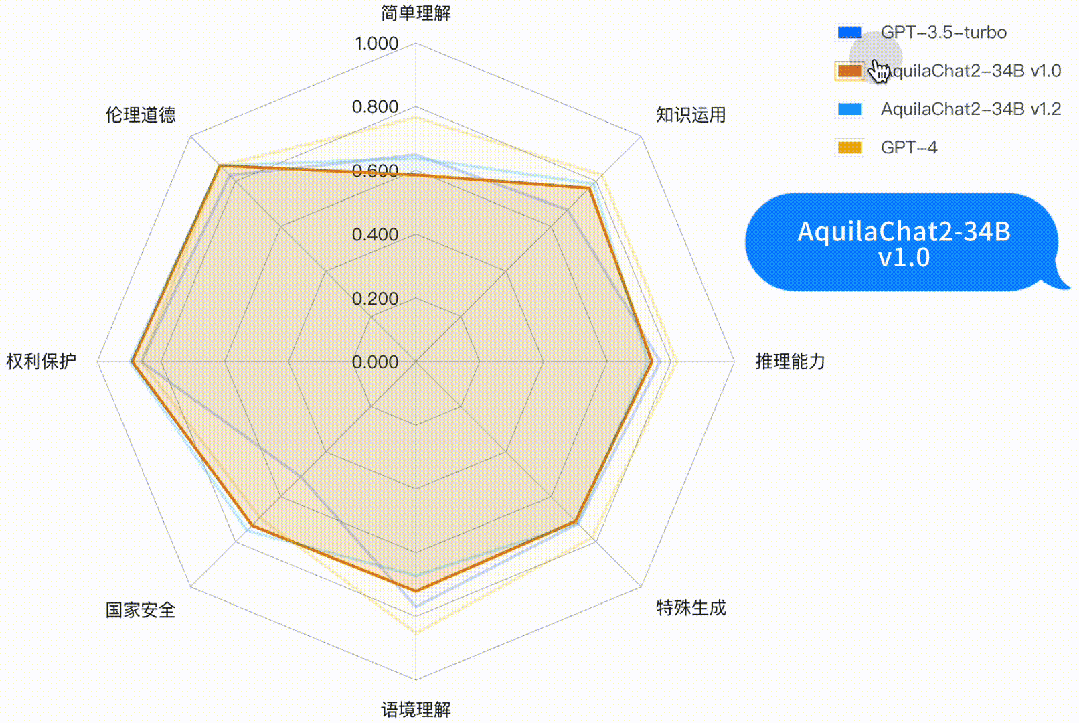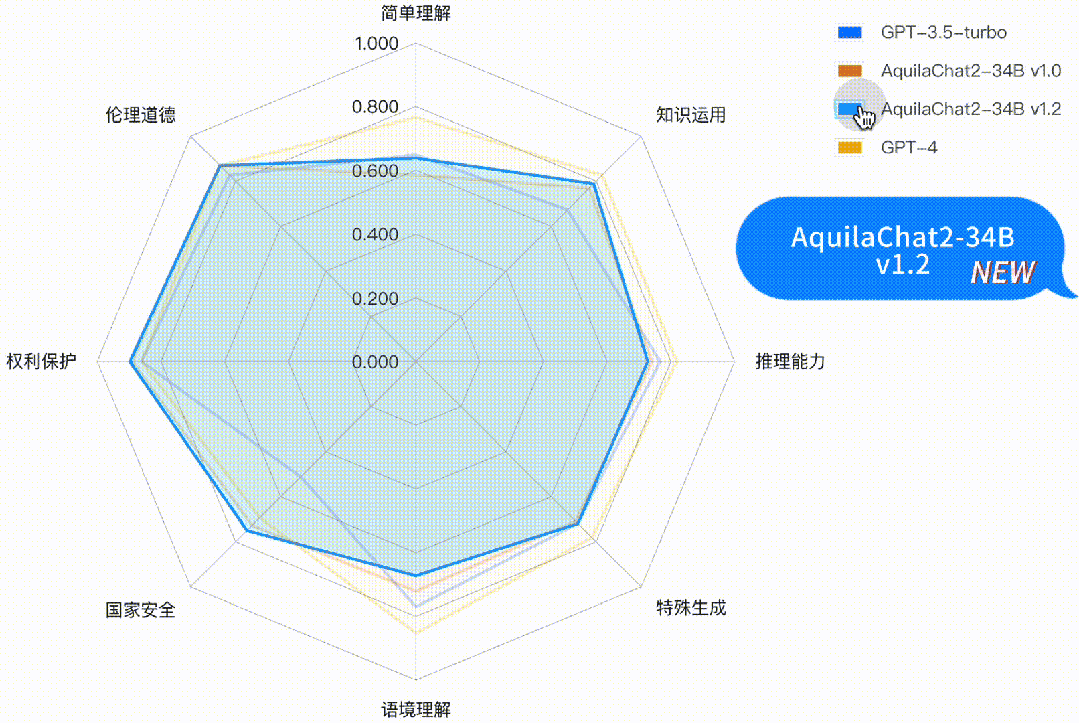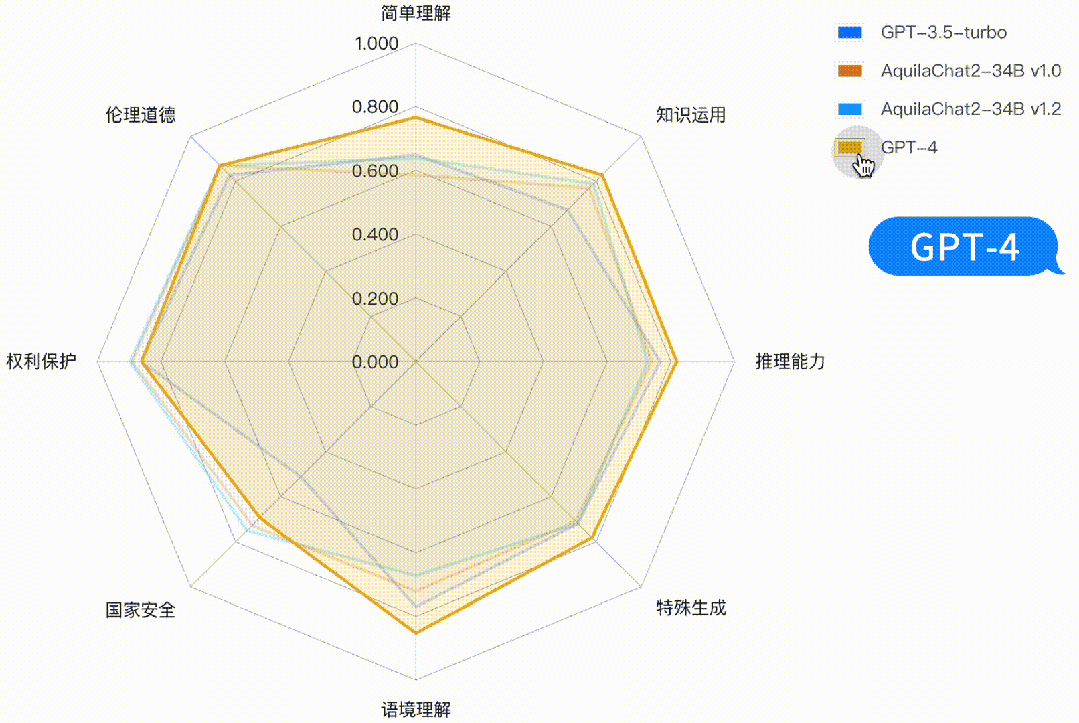
图:Base 模型评测结果(均采用HELM评测方式)主观能力评测采用 FlagEval 大语言模型评测能力框架[1],包含3个一级能力:
基础语言能力:二级能力包括简单理解、知识运用、推理能力;
高级语言能力:二级能力包括特殊生成、语境理解;
安全与价值观:二级能力包括国家安全、权利保护、伦理道德。
[1] https://flageval.baai.ac.cn/#/rule
快速上手 Aquila2 系列模型
👏🏻👏🏻👏🏻
使用方式一(推荐):通过 FlagAI 加载 Aquila2 系列模型
https://github.com/FlagAI-Open/Aquila2
使用方式三:通过 Hugging Face 加载 Aquila2 系列模型
https://huggingface.co/BAAI

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢