
今天是2023年10月30日,星期一,北京,雾霾。
我们今天来看看知识图谱与大模型研发过程中的虚与实。
知识图谱讲多一点,10条,大模型少一点,5条。
供大家参考。
一、知识图谱研发落地中的虚与实
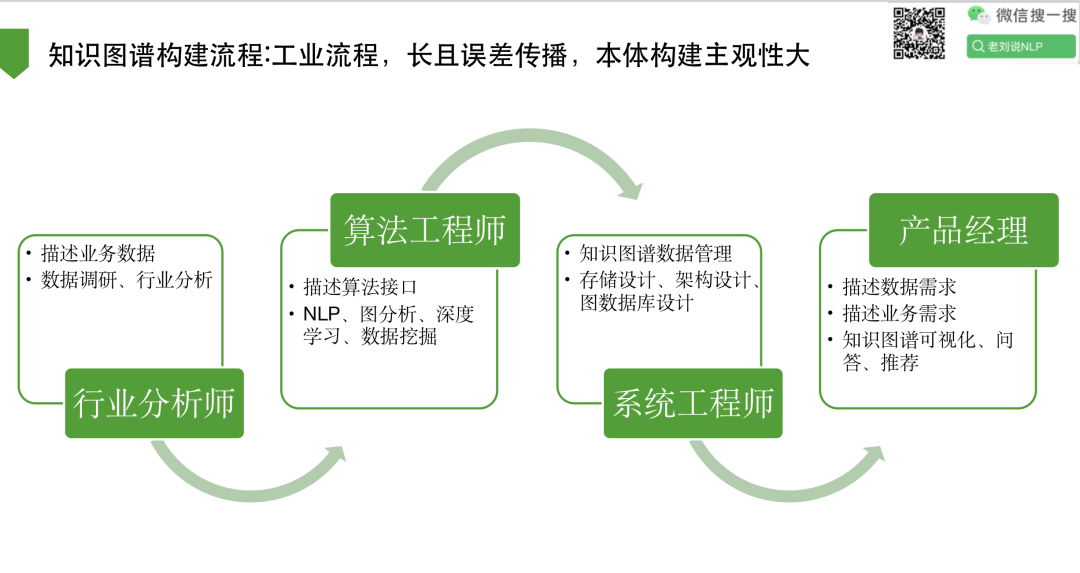
1、知识图谱构建流程:工业流程,长且误差传播,本体构建主观性大
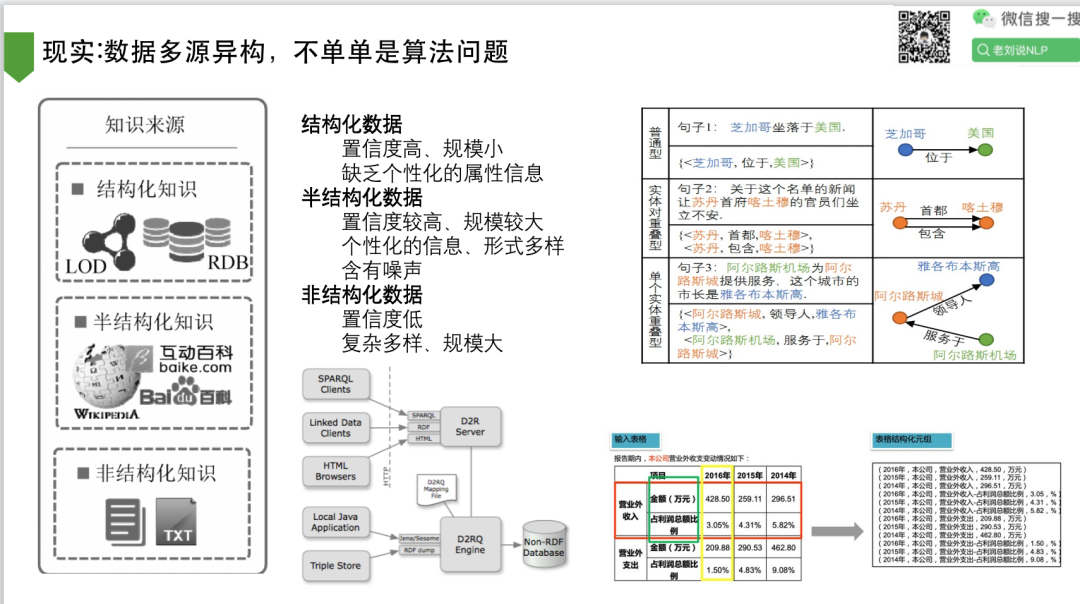
 2、现实:数据多源异构,不单单是算法问题
2、现实:数据多源异构,不单单是算法问题
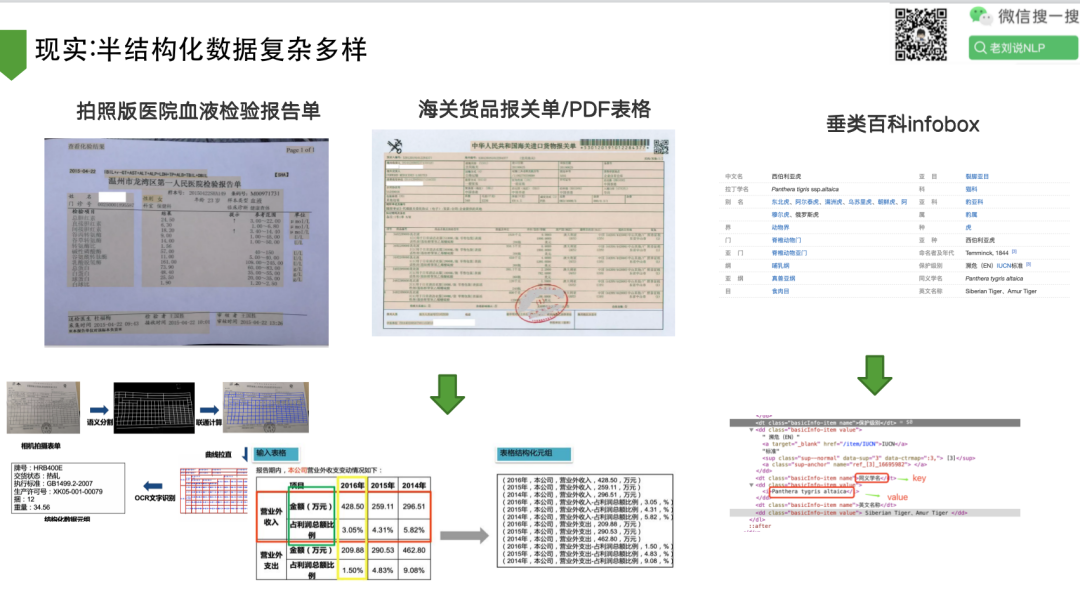
3、现实:半结构化数据复杂多样
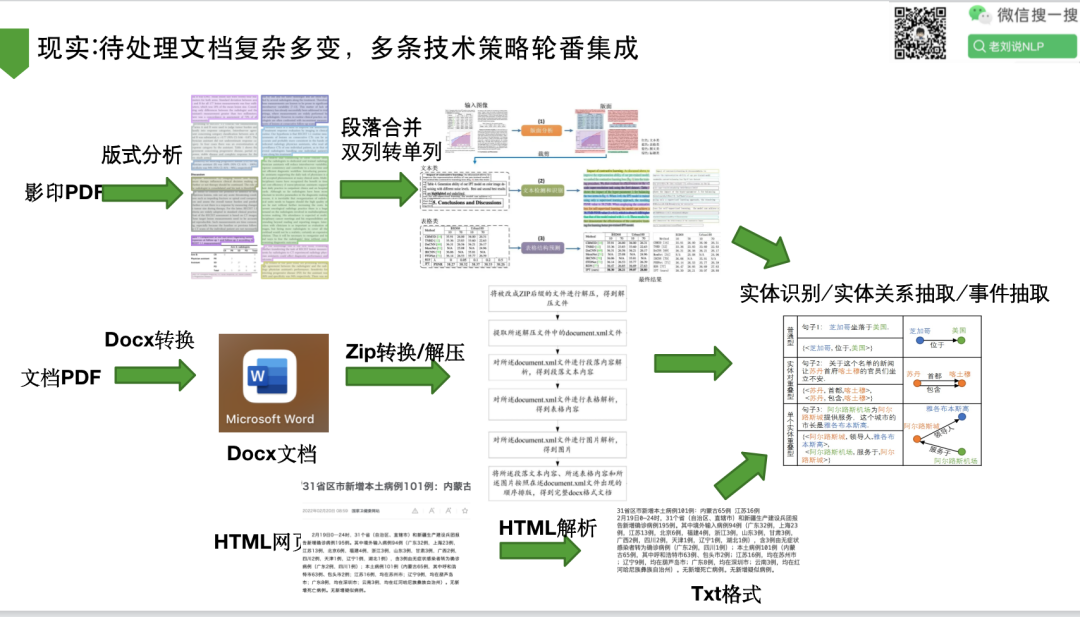
 4、现实:待处理文档复杂多变,多条技术策略轮番集成
4、现实:待处理文档复杂多变,多条技术策略轮番集成
5、现实:实体识别问题复杂,DIY强,标注需求量大

6、现实:远程监督构造数据算法在工业界很难落地

7、现实:实体关系抽取中的存在的诸多问题

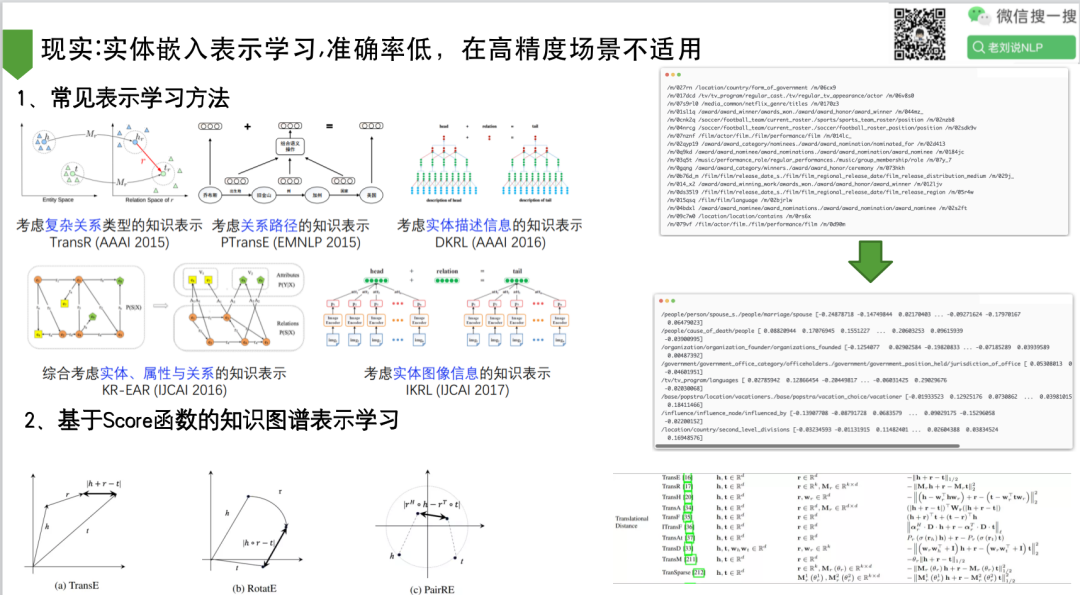
8、现实:实体嵌入表示学习,准确率低,在高精度场景不适用
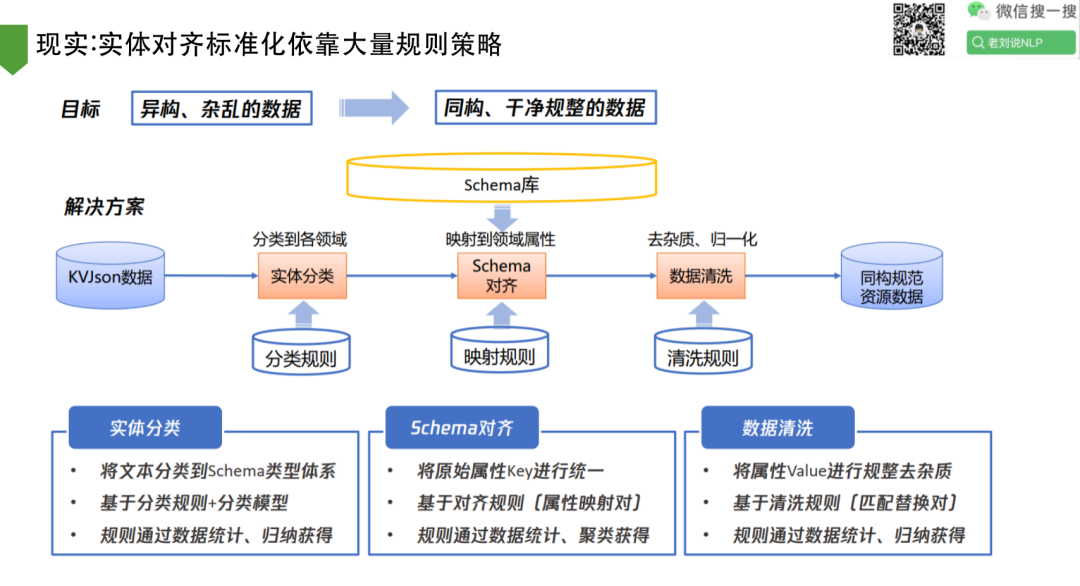
9、现实:实体对齐标准化依靠大量规则策略
二、大模型研发与落地的虚与实
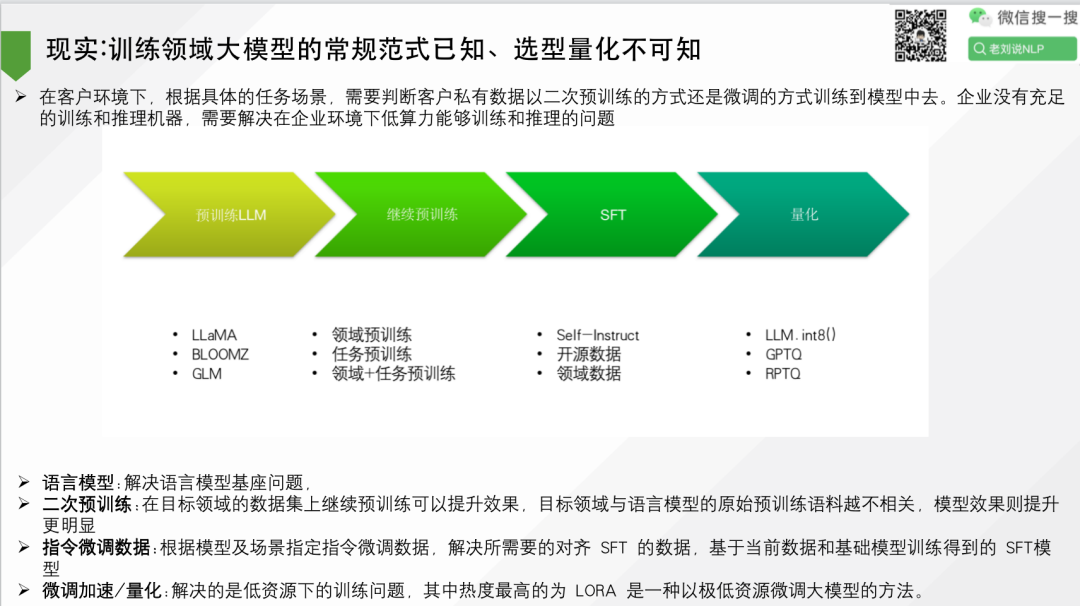
1、现实:训练领域大模型的常规范式已知、选型量化不可知
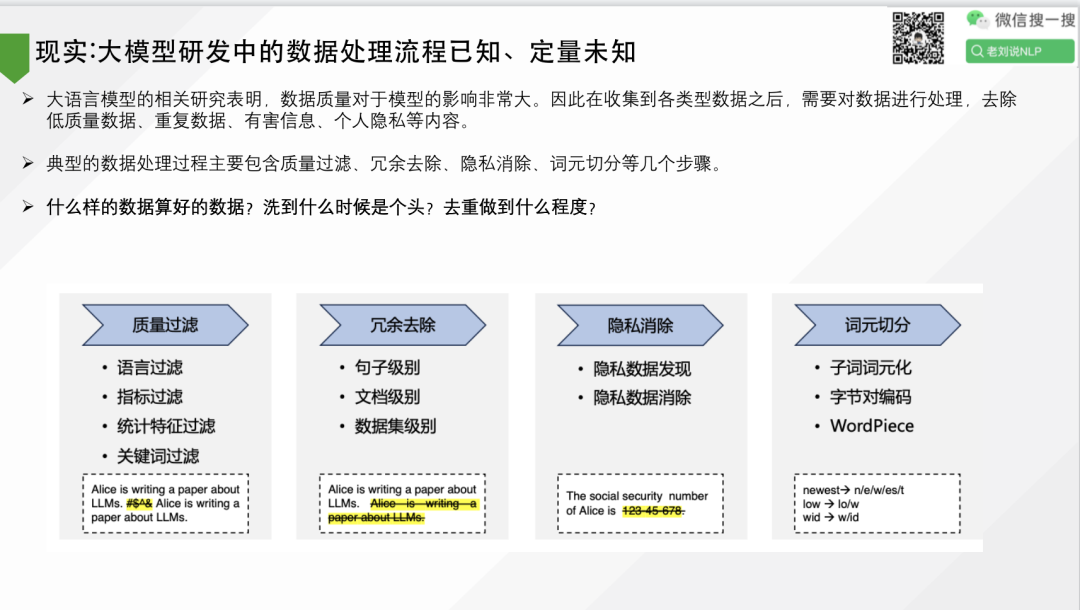
2、现实:大模型研发中的数据处理流程已知、定量未知
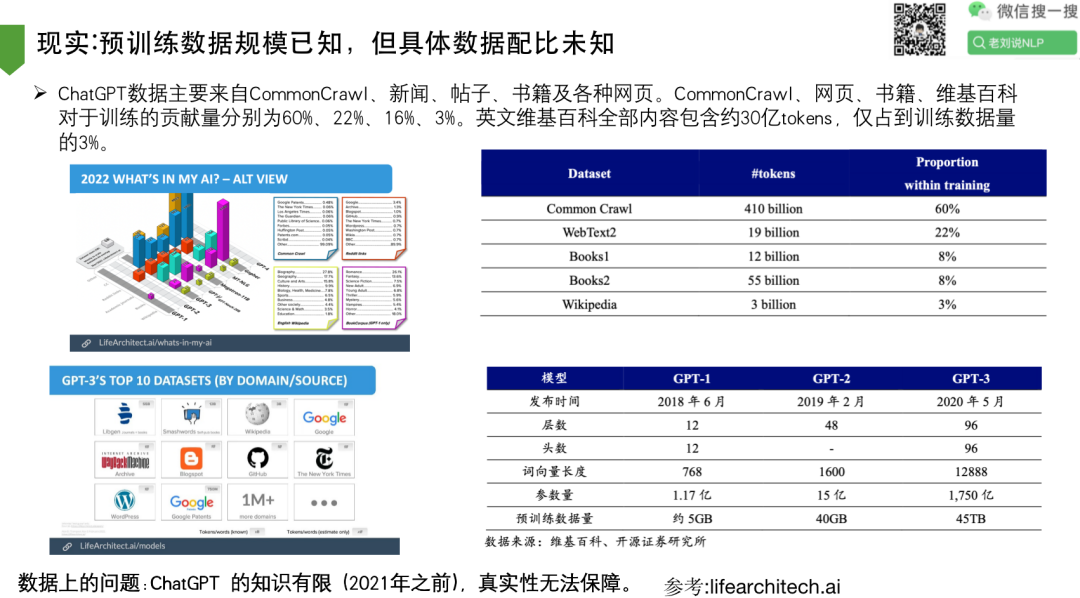 3、现实:预训练数据规模已知,但具体数据配比未知
3、现实:预训练数据规模已知,但具体数据配比未知
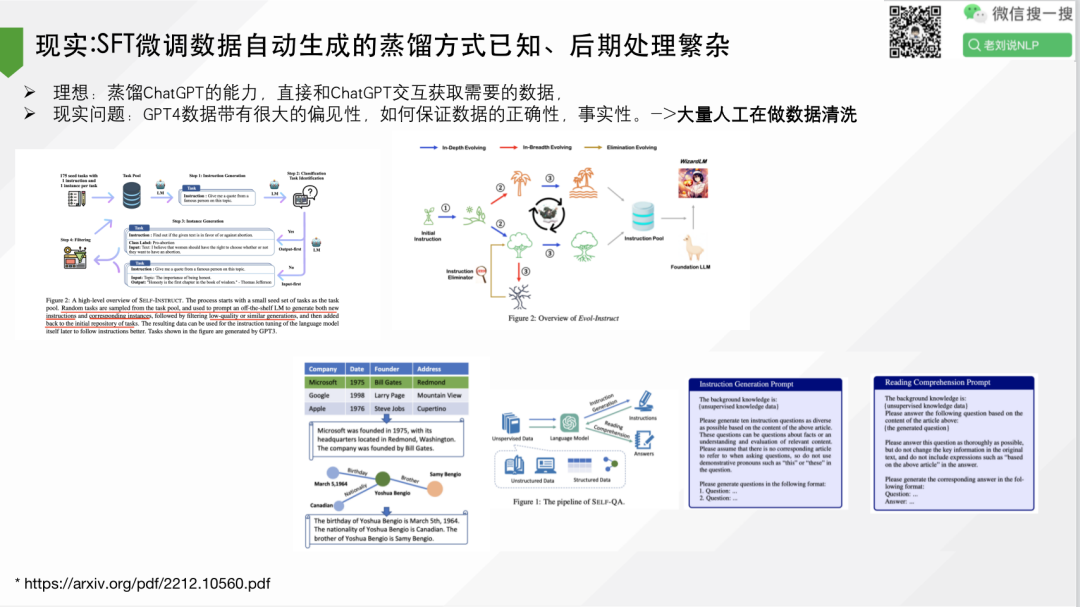
4、现实:SFT微调数据自动生成的蒸馏方式已知、后期处理繁杂
5、现实:大模型能力评测有偏、与真实业务隔阂大

参考文献
1、刘焕勇.《LLM+KG知识图谱研发和落地中的虚与实》,2023-10-26,北邮研究生课堂。
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢