


 杨成虎 | Fabarta 联合创始人兼 CTO
杨成虎 | Fabarta 联合创始人兼 CTO企业智能中的 Large Model 与 Knowledge
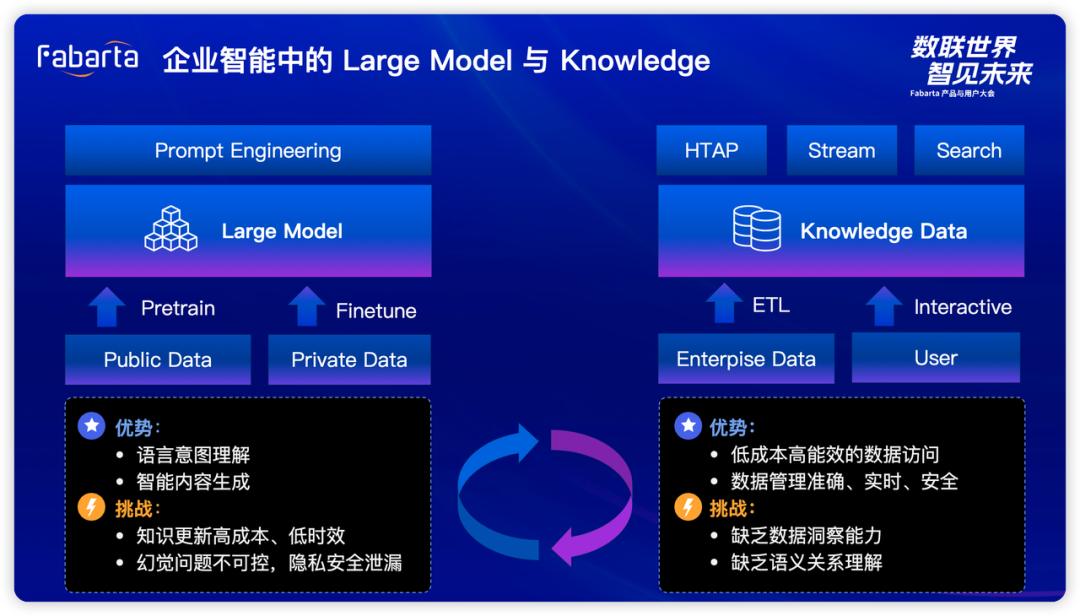
Data Centric LLM
数据的私有性、安全性和可控性:数据存储于多模态数据库中,数据库具有完备的数据管理安全能力。而不是存储于大模型中,数据读取不受控。 自然语言识别能力:数据洞察能力具备智能化, 不仅实现了自然语言查询与查询生成, 还可以作为数据补充的辅助; 结果可解释性和追溯性:数据结果并不直接来自大模型,而是通过大模型构建中间查询计划,再通过数据库执行对应的查询计划与一定的数据整合能力而产生数据结果。在整个过程中,查询计划可固化、可追溯、可调优。
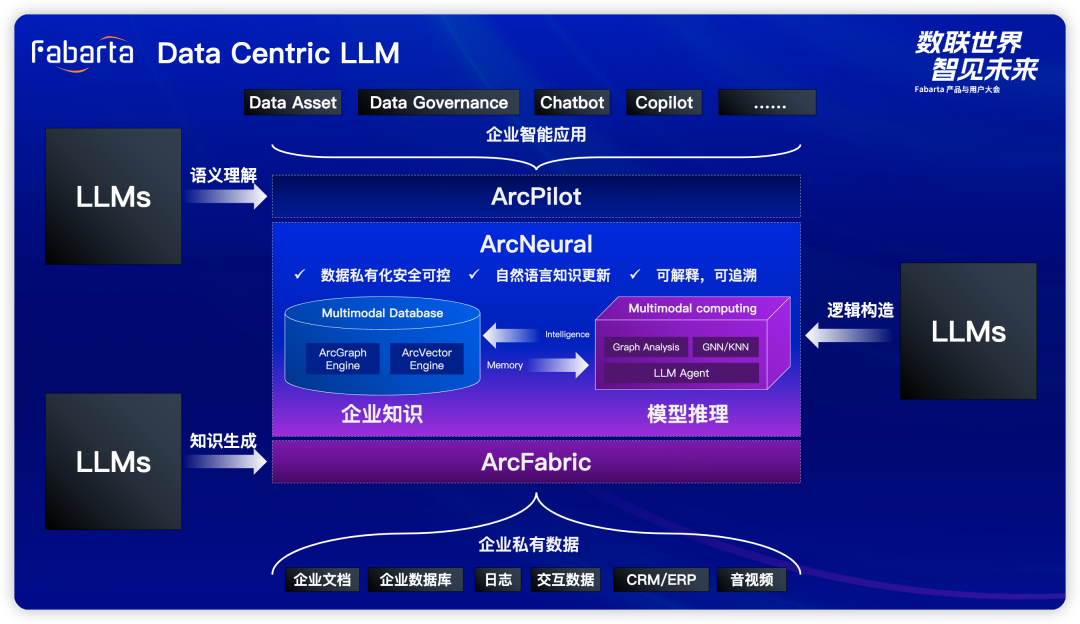
多模态智能引擎 ArcNeural
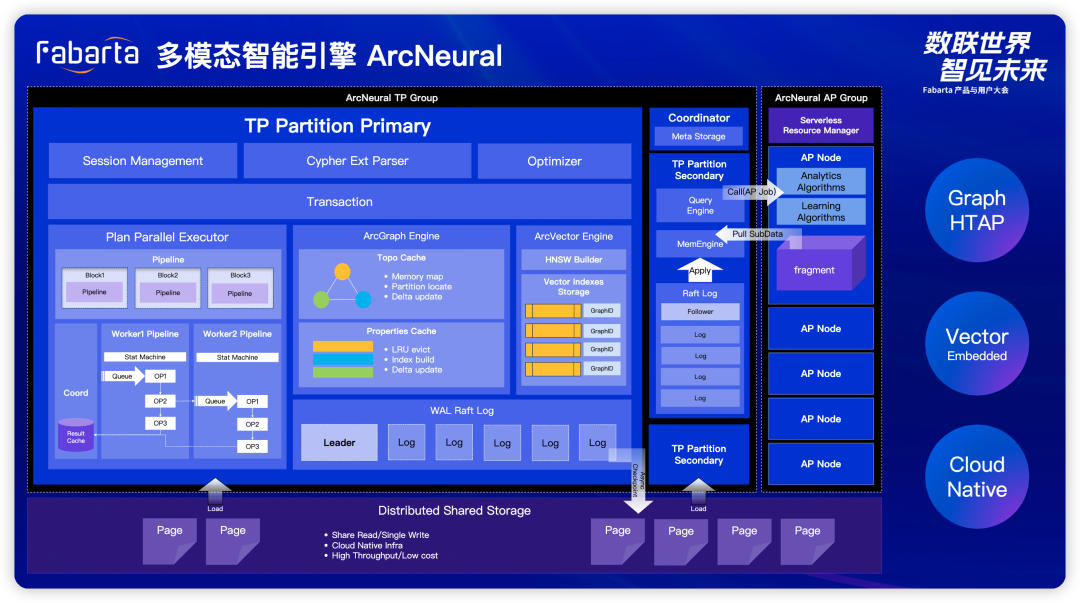
Graph HTAP:我们为用户提供了统一支持的高性能实时查询,并同时具备弹性的 AP 和 TP。不同于传统企业采购 Graph 时需要分别购买 TP 和 AP 两套系统,我们为您提供了一个一体化的 TP/AP 一体解决方案; 多引擎支持:我们不仅支持图数据引擎,还支持向量化引擎。通过插拔式引擎设计让我们能同时处理多种数据模态; 云原生架构:新一代数据库的显著特点,实现了存储和计算的分离。其中,蓝色主体部分代表我们的计算节点,而数据则存储在分布式共享存储上。这种存储方式既可以基于 OSS 存储,也可以采用其他分布式块存储,确保了存储与计算的分离弹性;
多模态智能引擎 ArcNeural:存储层的架构
多模态智能引擎 ArcNeural:HTAP Graph 技术
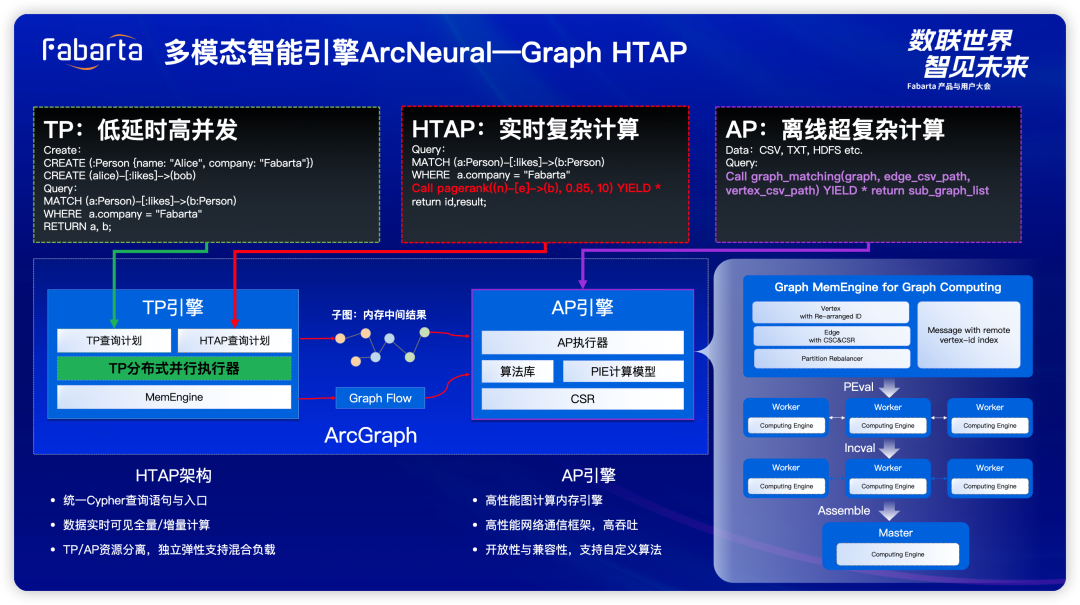
多模态智能引擎 ArcNeural:Serverless 技术
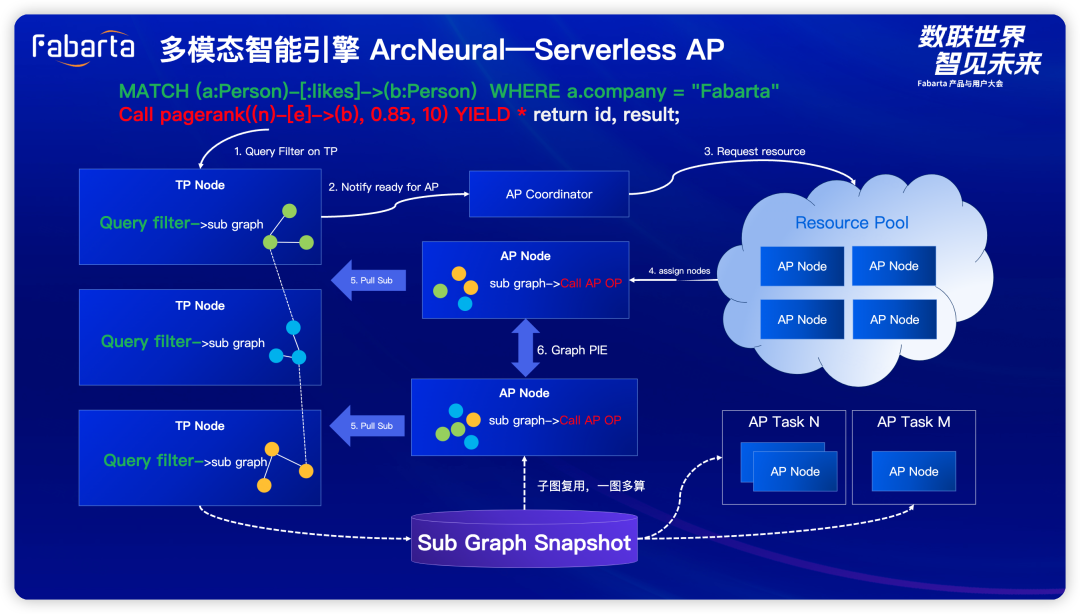
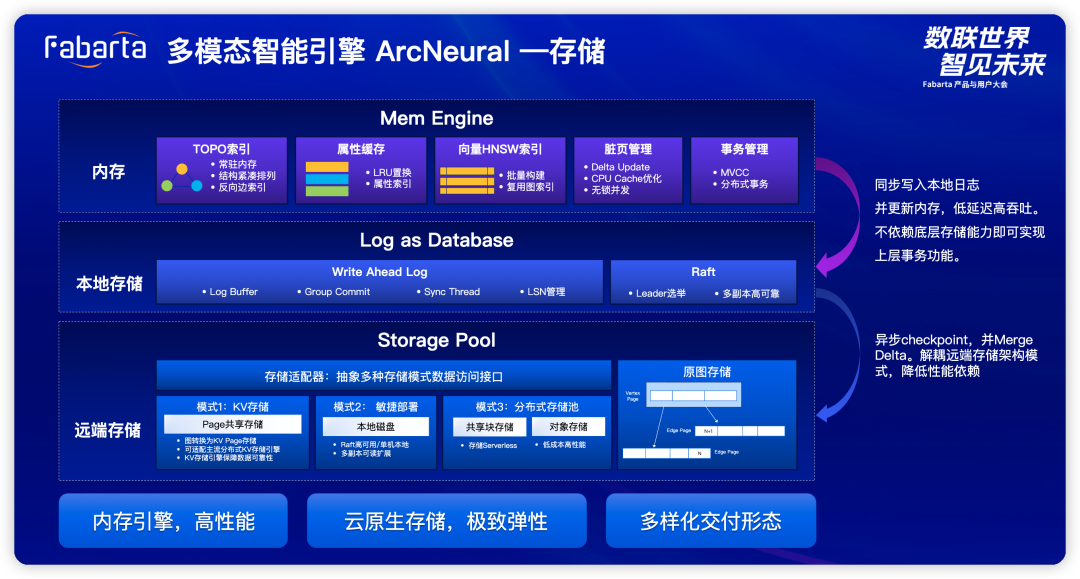
多模态智能引擎 ArcNeural:混合多模态存储(Vector Column Type)
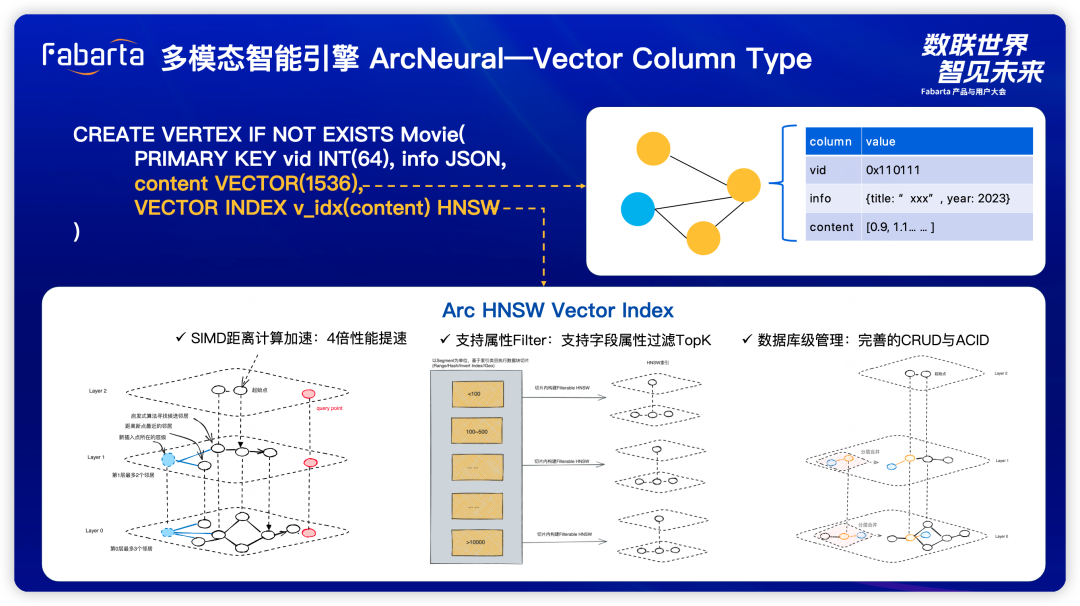
使用 SIMD 进行距离计算加速,与传统方式相比,我们的方法可以提高 4 倍的性能。 支持属性过滤的向量检索功能,同类系统只能进行纯向量检索,而不能进行其他字段(标量)的联合检索。 通过原有图技术沉淀,我们在向量数据模型上也实现了完整的 CRUD 和 ACID 功能。
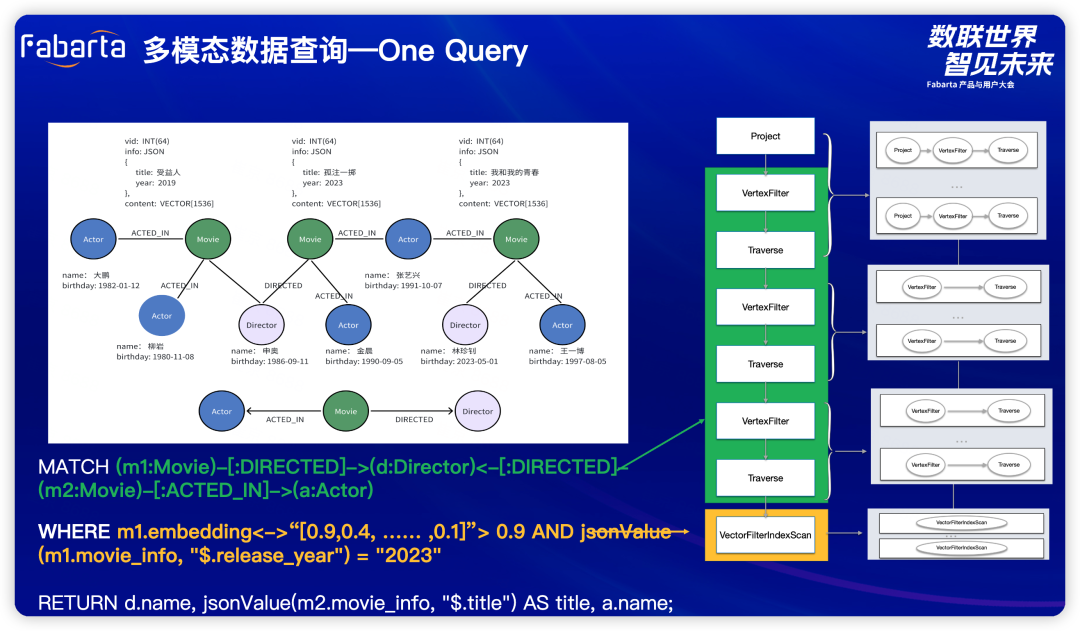
多模态智能引擎 ArcNeural:混合多模态查询(One Query)
ArcNeural 2.1 版本核心特征

多模态:我们的引擎支持多种数据格式,包括图数据、向量数据、JSON 以及传统的 Table 数据结构; 企业级数据管理:ArcNeural 提供完整且严谨的数据 ACID 处理能力,技术特色还包括内存引擎技术和多跳并行化处理; 企业级交付方面:除了支持云原生的弹性部署,我们的解决方案还适应于分布式系统、银行的多地多中心等高级要求,并且支持模块化部署,可以根据需要进行个性部署; 国产化:我们深感自豪地宣布,ArcNeural 完全满足国内的生产要求。从代码的完全可控性到对国产硬件的完美适配。在系统内核研发方面,我们使用现代编程语言 Rust 编写。最后,ArcNeural 支持面向合作企业和伙伴开源。
『一体两翼』产品矩阵
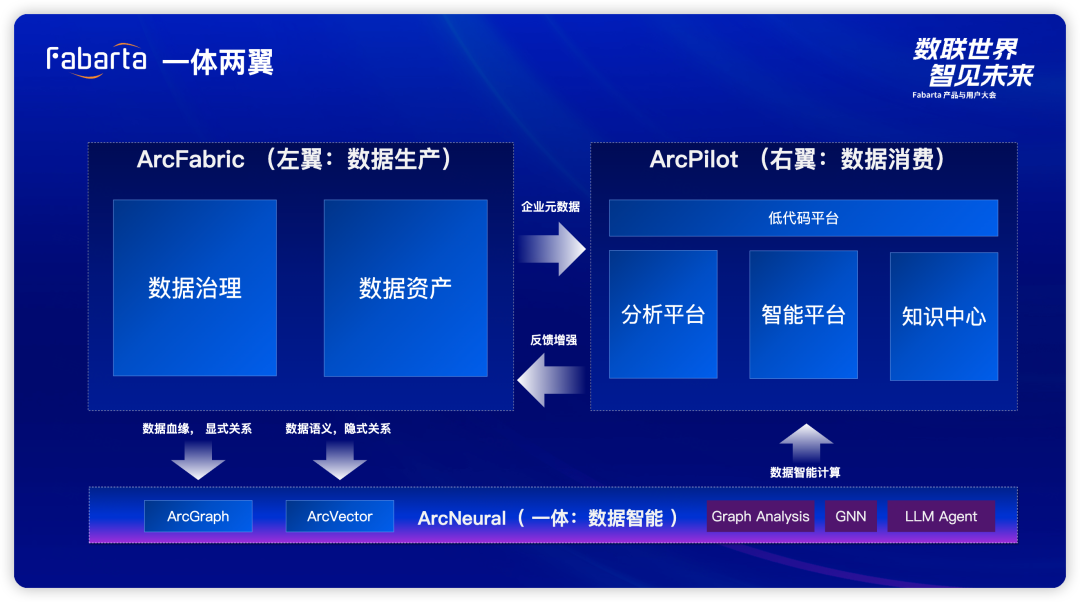
ArcNeural 为提供了数据智能体,具备完整的数据存、查、算处理能力,同时集成大模型的智能能力。但在严肃的企业2B业务场景中落地,还需要关注数据的生产端与业务数据消费端,为此,我们采用了“一体两翼”的策略。 左翼 - ArcFabric:关注数据的生产 数据治理和数据资产:这两个模块主要对企业数据进行管理、元信息抽取,甚至补充; 产生的显式关系:例如结构化数据的血缘关系,这部分数据会存储在我们的图引擎中; 产生的隐式关系:例如非结构数据的内容关联,这类数据则会存入向量引擎表达;
右翼 - ArcPilot:关注数据的消费 低代码平台和用户交付:使得数据的消费变得更为便捷; 数据智能平台和知识中心:为企业提供强大的数据分析能力和知识存储;
右翼通过不断实现业务,通过数据积累,不断对数据知识体系进行修正,正向反馈给左翼,以帮助左翼更智能的管理企业数据,不断强化企业知识图谱。 企业智能 IT —— Arc42
数据治理和数据资产:这两个模块主要对企业数据进行管理、元信息抽取,甚至补充; 产生的显式关系:例如结构化数据的血缘关系,这部分数据会存储在我们的图引擎中; 产生的隐式关系:例如非结构数据的内容关联,这类数据则会存入向量引擎表达;
低代码平台和用户交付:使得数据的消费变得更为便捷; 数据智能平台和知识中心:为企业提供强大的数据分析能力和知识存储;
企业智能 IT —— Arc42
基于一体两翼的理论范式,我们首先在自己企业内部去落地实践,Fabarta 作为一家企业,也有很复杂的代码,或者是文档,CRM等多样性的数据,同样需要智能化的实现内部数据管理。 带着这样的初衷我们构建了企业智能 Arc42 这套系统,这套系统中我们打通了数据的生产、管理到消费。 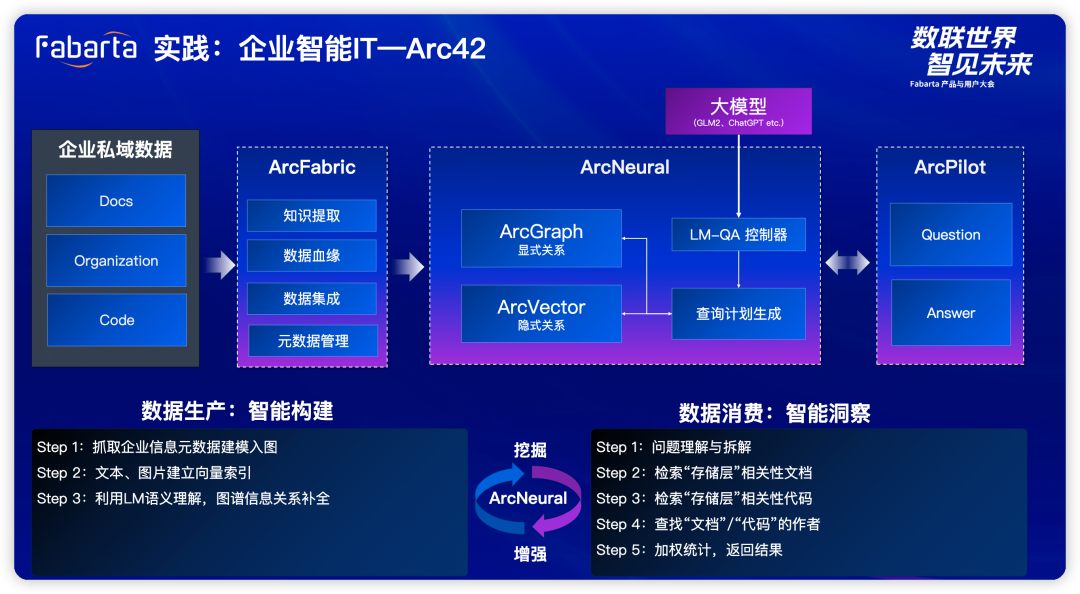
数据生产端将我们企业内部的,企业的组织,甚至代码通过我们 ArcFabric 的平台建了企业智能图,我们首先把显式关系抽取出来(比如文档结构在哪个目录下,大标题小标题,文档引用关系),然后进一步抽取其中隐式的关系(比如文档中心思想和哪篇相似,代码片段和哪些相似),最后通过大模型或者迭代构建完整的企业知识图谱,给我们的 ArcNeural。 数据消费端通过知识问答形式提供知识的呈现,用户提供一些传统自然语言的提问,由我们 ArcNeural 中大模型的控制器来与整个大模型交互生成相应的查询计划,生成相关多模态查询计划交给我们 ArcNeural 执行,最终得到相应的答案。
演示 1 :图+向量解决模型幻觉问题
我们首先展示了一个采用传统大模型+向量的方案,也是大家最为熟悉的形式。在这个演示中,我们提出了一个问题:Fabarta 2.0 数据库产品是否具备区块链的功能?这里用到的大模型是业内领先的。不过,它给出的答案表明我们有相关的代码,但实际上,我们并没有开发过此类技术或产品。 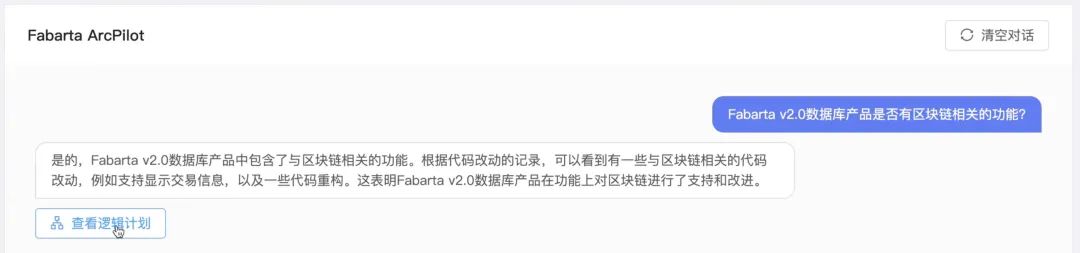
这种答案背后的原因是什么呢?通过查询计划,我们可以进一步追溯。具体来说,这个误解的原因是区块链有两个核心技术:区块(Block)和交易(Transaction)。而这两个术语在数据库技术中也经常出现。例如,我们在写数据库代码时,底层存储的数据块我们会使用 Block,而数据库事务也称为 Transaction。这使得大模型在处理这类问题时往往只关注局部信息。比如,仅凭三四行代码中的 Block 和 Transaction,它确实很像区块链技术。但如果我们放大视角,会发现我们的专长是数据库技术,并非区块链。 为了提高答案的准确性,我们引入了多模态技术。请看下面这个演示,对于相同的问题,这次我们得到了一个正确的答案。通过大模型,我们制定了更为复杂的查询计划,并在查询后利用图谱进行验证。这样,我们可以更全面地验证答案的准确性。虽然确实找到了一些相关的代码,但从文章的内容、组织关系和标题来看,这些代码与区块链技术并不相关。经过交叉验证,得出的结论是:我们并不具备相关的技术。这是一个准确的答案。 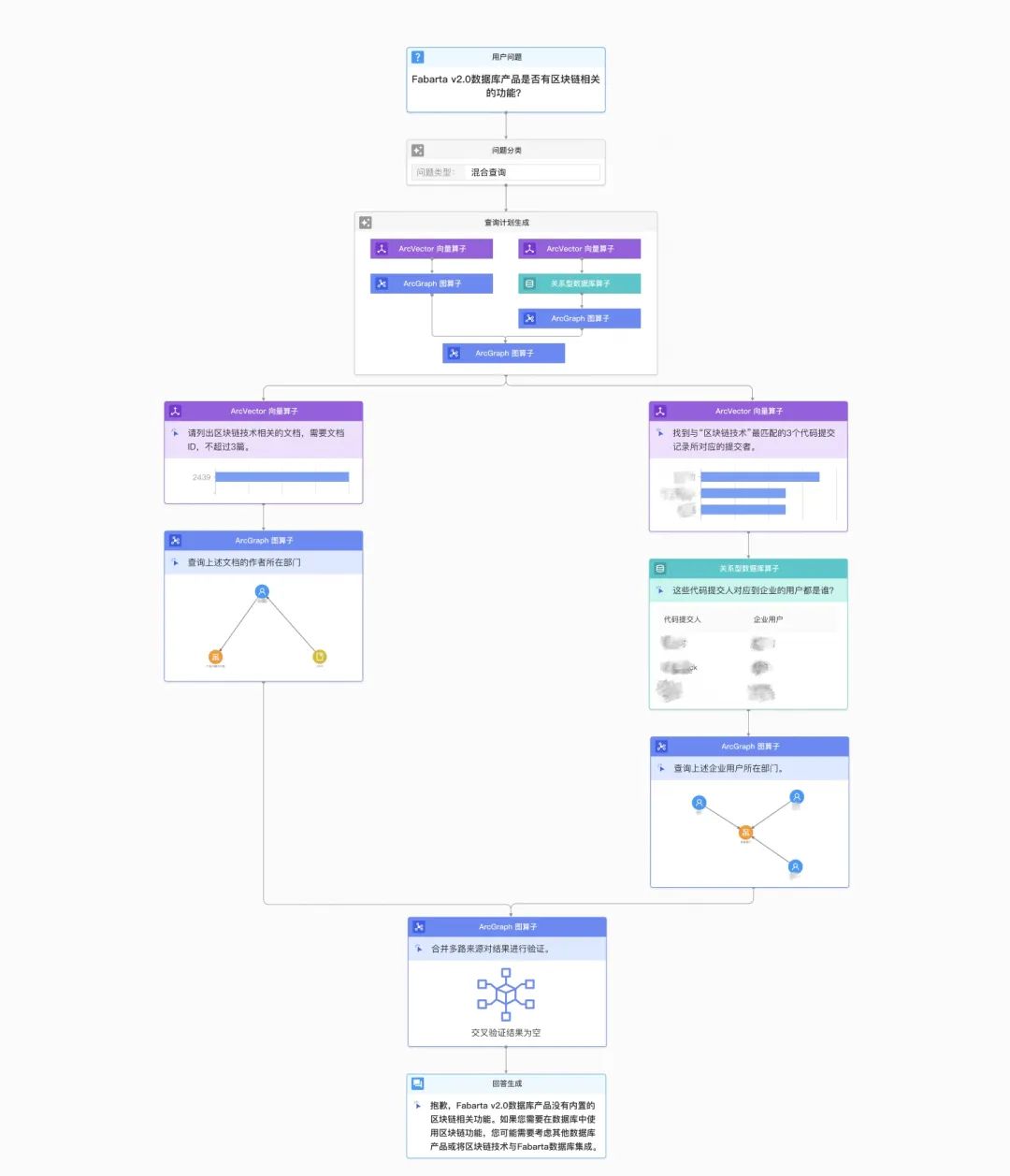
演示 2:图+多路召回帮助答案更精准
演示 1 :图+向量解决模型幻觉问题
演示 2:图+多路召回帮助答案更精准
接下来,我们想向大家展示,当使用传统大模型配合单维度数据时,它可能给出的答案是正确的,但并不是最准确的。 考虑这样一个场景:当我有一个关于编译器设计的技术问题,我应该去咨询谁?这并不是关于设计的具体问题,而是关于应该找谁去讨论。大模型给出了一个答案:一个叫做“小可”的同事,并附带他的代码提交记录。这些信息的确与编译器设计有关,但这并不意味着他就是最了解这个领域的人。因为真正的专家不仅仅是能够写代码,还需要深入了解架构设计。通过查看它的查询计划,我们可以看到它只考虑了代码的部分,这恰恰是单维度数据配合大模型的局限性。 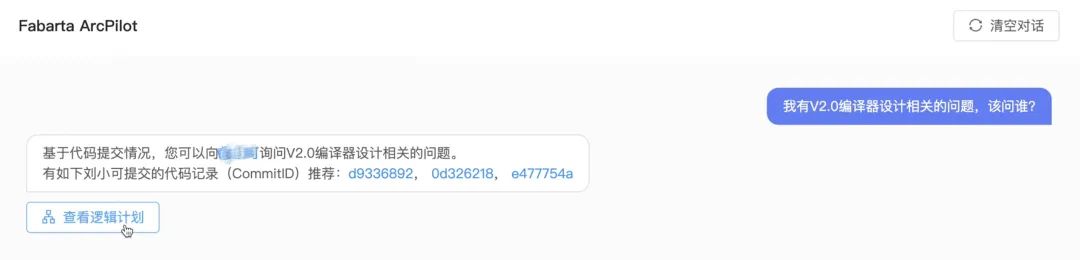
那么,让我们再次看一个使用 Arc42 高精准回答的例子。这次,答案已经指向了另一位同事。从他的答案摘要中,我们可以看出,答案不仅仅基于代码,还基于文档以及谁是文档的作者,这是一个更全面的多维度数据处理。在 Arc42 中,最核心的部分是生成查询计划。这样的查询计划反映了我们与大模型交互时的数据访问步骤。我们可以将这些步骤总结为数据库查询计划,并在数据库中进行处理、总结和提取。遇到问题或疑惑,我们都可以回头查看这个查询计划,追溯大模型背后的逻辑。 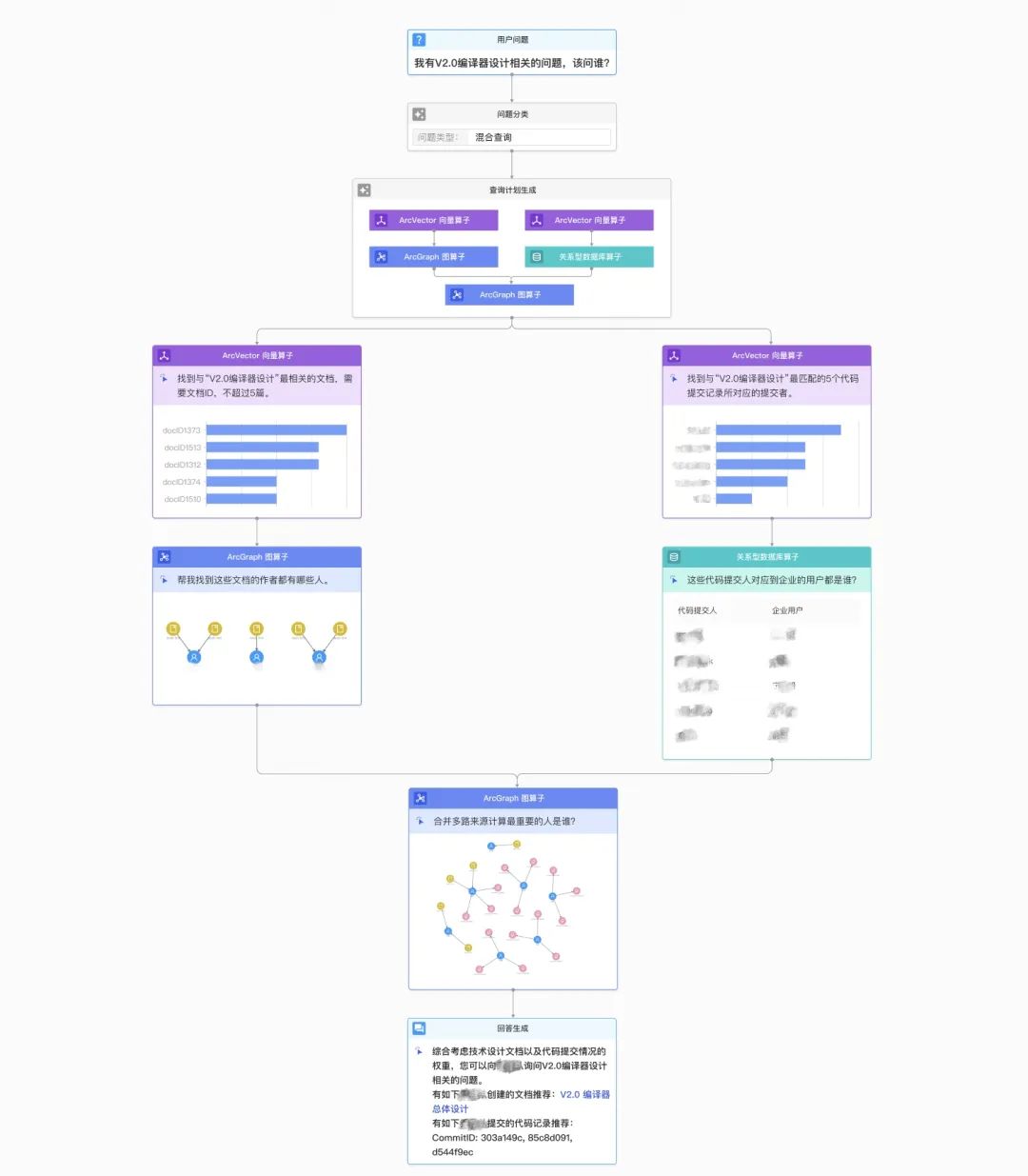
看这个例子,这次的查询计划相对复杂:它先寻找相关文档,然后找到文档的作者,并进一步查看相关的组织结构。它最终形成了一个包含代码、组织和文档的复杂子图。我们使用图算法在这个子图上寻找中心点,得到了最终的答案。我对这个答案感到很兴奋,因为它与我对团队的理解高度一致。 此外,我们还可以通过大模型对这些答案进行总结,帮助大家更好地理解内容。 我今天展示的都是真实的企业数据和场景。这就是我今天想与大家分享的,谢谢大家的聆听。 
往期优质文章推荐
往期推荐
往期优质文章推荐
往期推荐
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢