
点击下方卡片,关注「集智书童」公众号

Vision-Language Pre-training(VLP)在极其庞大的参数辅助下取得了显著的进展,但这也给实际应用中的部署带来了挑战。知识蒸馏被广泛认为是模型压缩中的关键步骤。
然而,现有的知识蒸馏技术对VLP的深入研究和分析还不足,VLP相关的蒸馏实践指南也尚未得到探索。在本文中,作者提出了DLIP,一个简单而高效的“蒸馏视觉-语言预训练”框架,通过它作者研究如何蒸馏一个轻量级的VLP模型。
具体而言,作者从多个角度对模型蒸馏进行了分析,比如不同模块的架构特性以及不同模态的信息传递。作者进行了全面的实验,并给出了关于蒸馏轻量级但性能良好的VLP模型的见解。
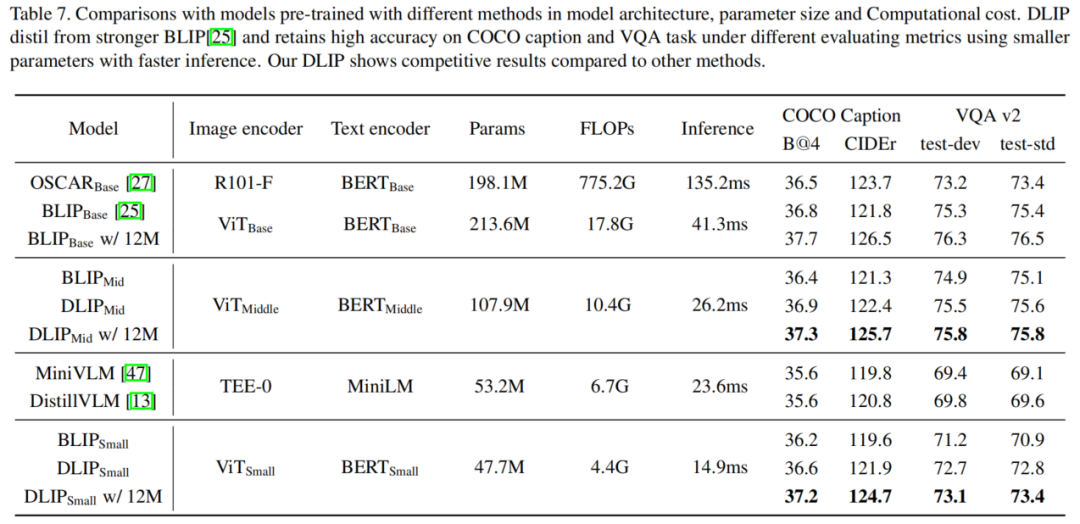
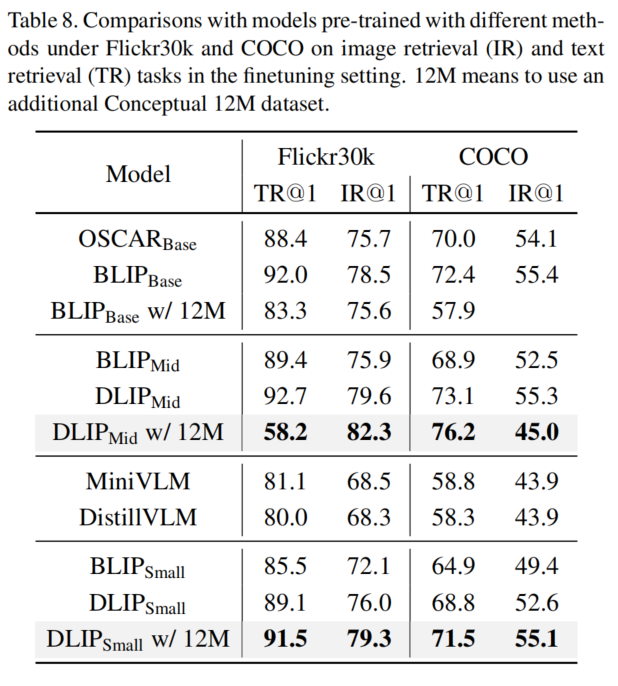
实验结果显示,DLIP在各种跨模态任务(如图像-文本检索、图像字幕和视觉问答)中可以实现最先进的准确性/效率平衡。例如,DLIP将BLIP的参数从213M压缩到108M,同时实现了可比或更好的性能。此外,与教师模型相比,DLIP在保留超过95%的性能的同时,参数和浮点运算数(FLOPs)减少了22.4%,推理速度提高了2.7倍。
由于基础模型的出现,大型语言和视觉模型被整合以获得多模态能力,并在广泛的多模态下游任务中取得了显著成功,如图像-文本检索、图像字幕和视觉问答(VQA)等。
然而,无论是视觉-语言预训练(VLP)还是多模态大型语言模型(MLLM),通常都依赖于具有数亿参数的庞大模型进行推断。在资源受限的服务器平台甚至更轻量级的移动设备上部署这些需要巨大计算成本的模型是困难的。因此,构建一个轻量级的多模态模型以减少模型参数和计算开销在实际场景中至关重要且实用。
最近的研究表明,深度学习模型中存在冗余。因此,一系列的模型压缩技术被提出来减小模型的大小并加速模型推断。促进模型压缩的典型方法是基于知识蒸馏(KD)。知识蒸馏旨在将大型教师模型中学到的知识传递给一个小型的学生模型,学生模型通过模仿教师模型的信息概念(如输出逻辑、特征图或隐藏表示)进行训练。例如,DistBERT通过关闭教师和学生模型的隐藏表示,将BERT-base模型的大小减小了40%。MiniLM进一步强调了在教师和学生模型之间最小化自注意力分布的重要性。然而,先前的蒸馏算法未考虑到视觉-语言模型的复杂架构以及多模态信息传递的影响。
对于完全基于Transformer的VLP模型,作者观察到对其进行蒸馏时面临两个基本挑战:
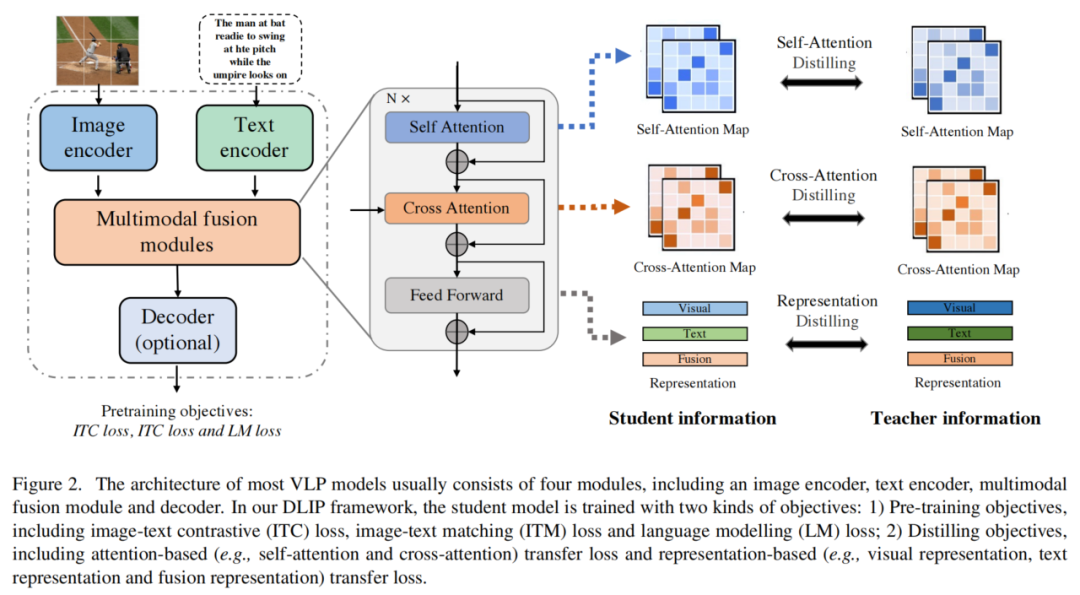
VLP模型的架构通常包含多个模块,包括图像编码器(例如,ViT )、文本编码器(例如,BERT )、多模态融合模块或任务解码器,如图2所示。因此,确定可以进行蒸馏的模块是一个非常复杂的任务。
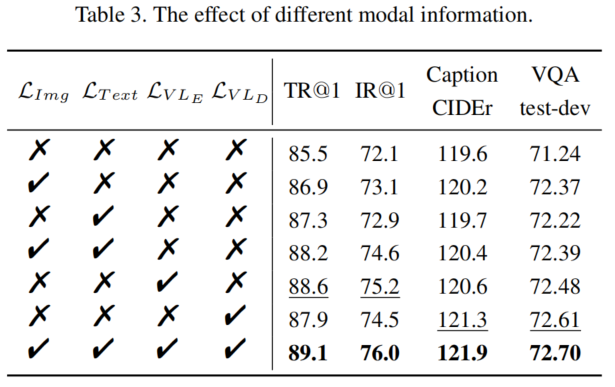
与单模态(只有图像或语言)蒸馏相比,VLP模型涉及多种信息传递,包括单模态信息(例如,视觉信息)和多模态融合信息(例如,视觉-语言信息)。因此,有必要研究不同信息传递对蒸馏中下游任务的影响。
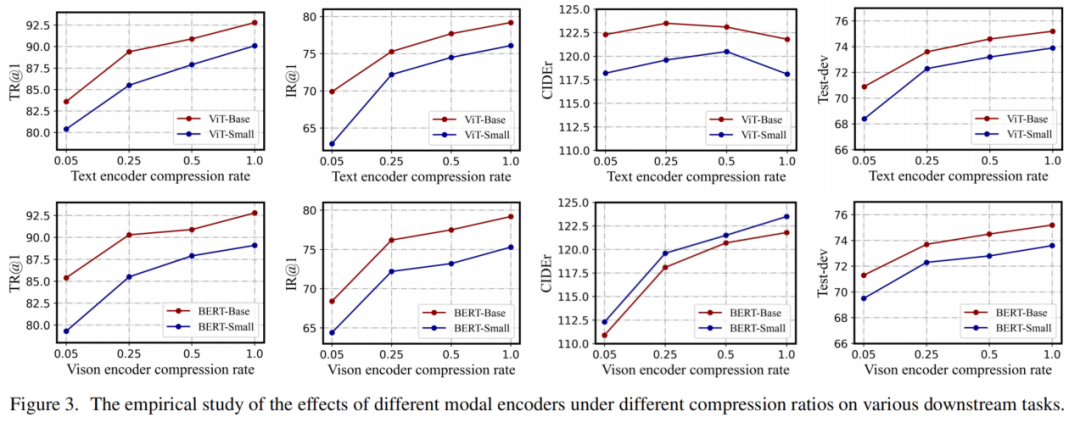
为了解决上述挑战,作者进行了一系列的对比实验,以深入研究和分析VLP模型。作者对不同模块压缩的作用进行了消融实验,并追求最小的变化,以确定VLP蒸馏中不同模态信息传递的影响。通过广泛的分析,作者总结了以下发现:
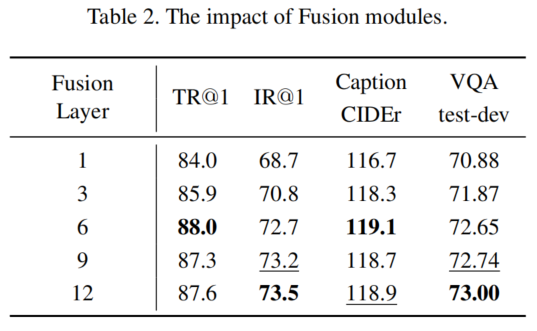
在模块的层面上,图像编码器和文本编码器在模型压缩中具有同等重要性。此外,大型融合模块是不必要的,适度的融合层是有益且高效的。
对于带有解码器的VLP模型,解码器需要单独进行蒸馏,以提高基于解码器的下游任务的性能。
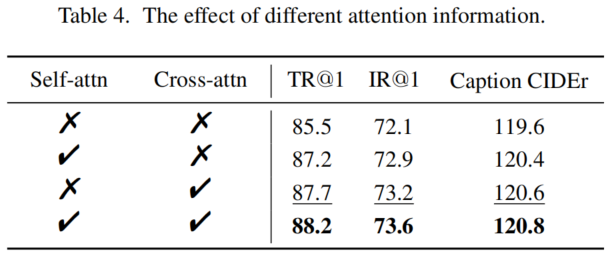
在模态的维度上,表示信息比注意力信息更适合用于蒸馏。此外,多模态信息比单模态信息更高效。
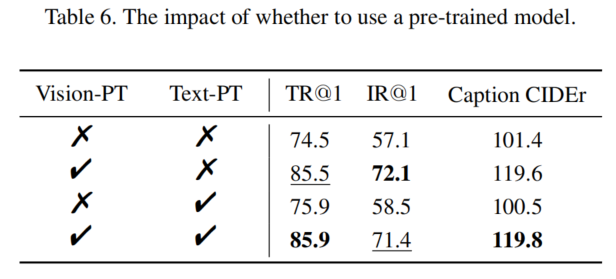
使用预训练模型进行初始化对于视觉编码器非常重要,但对文本编码器的影响较小。
基于后续章节详细介绍的洞见和其他有用的技巧,作者提出了Distilling Language-Image Pretraining (DLIP)框架,这是一个简单而高效的VLP蒸馏框架,用于训练更小、更快、更轻的VLP模型,如图2所示。
令人惊讶的是,尽管没有复杂的算法设计,作者的DLIP在效率和效果方面表现非常出色,并在广泛的多模态任务中胜过了最先进的基线模型,无论参数规模如何。
特别地,DLIP将BLIP的参数规模从213M压缩到108M,压缩比为1.9倍,同时实现了可比甚至更好的性能。此外,与教师模型相比,DLIP保留了超过95%的性能,并且只使用了22.4%的参数和24.8%的FLOPs,加速了推断速度2.7倍。
一个完全基于Transformer的VLP模型通常由几个重要模块组成,包括图像编码器、文本编码器、多模态融合模块和任务编码器,如图2所示。给定一个图像-文本对,VLP模型首先通过图像编码器和文本编码器提取出视觉表示 和文本表示 ,其中和是编码器层数。然后,视觉和文本表示被输入到一个多模态融合模块中,以生成跨模态表示。这些表示可以选择性地被送入任务解码器,然后生成最终的输出。
自从视觉Transformer(ViT)在视觉表示提取方面展现出巨大潜力后,许多研究工作已经将ViT或其变体形式(如Deit、CaiT和Swin Transformer)引入了VLP领域。
在本文中,作者专注于原始的ViT架构,因为作者只研究模型压缩对性能的影响。作者基于ViT构建了一系列不同配置的视觉编码器,如表1所示。
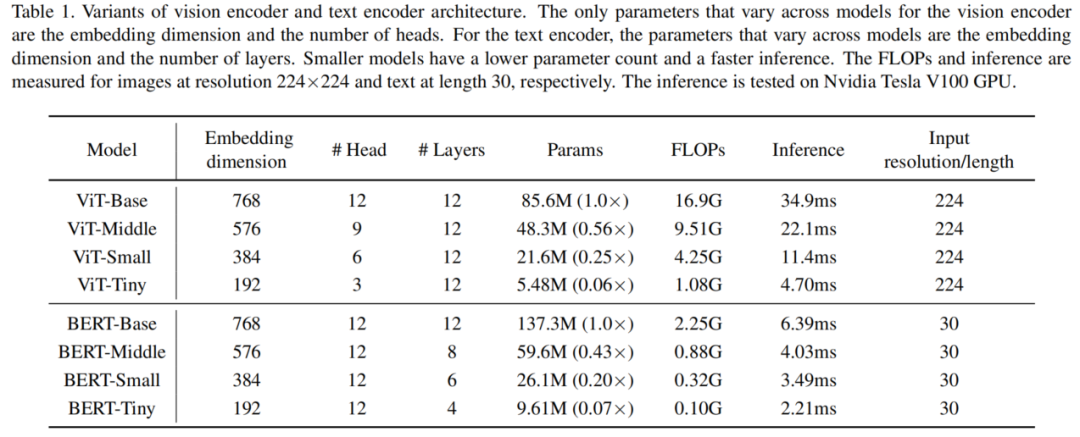
在VLP中,最常用的文本编码器是BERT,它首先将输入句子分割成一系列子词,然后在句子开头和结尾插入两个特殊的标记,生成输入文本序列。作者也使用BERT作为默认的文本编码器,并基于BERT构建了一系列不同配置的文本编码器,如表1所示。
存在两种融合方式,即合并注意力和交叉注意力。先前的研究已经证明,交叉注意力模型在性能和计算效率上优于合并注意力模型。因此,作者在多模态融合操作中使用交叉注意力,如图2所示。作者通过设置不同数量的交叉注意力层来控制多模态融合模块的大小。
在VLP模型中,解码器模块是可选的。许多VLP模型采用仅编码器架构,其中跨模态表示直接输入到输出层以生成最终的输出。对于Transformer编码器-解码器架构,跨模态表示被输入到解码器,然后传递到输出层。更重要的是,编码器-解码器架构更加灵活,可以执行诸如图像字幕生成等任务,而对于仅编码器模型来说可能不那么直接。
因此,在作者的DLIP框架中,作者考虑了解码器。解码器的结构与文本编码器类似,唯一的区别是它将双向自注意力层替换为因果自注意力层。
在DLIP框架下有许多不同的模型设计,为了训练一个轻量且高效的模型以更好地适应不同的下游任务,作者使用多模态编码器-解码器混合(MED)作为作者的基础架构。
该架构可以灵活地作为单模态编码器或基于交叉注意力的多模态编码器,或者作为多模态解码器操作。
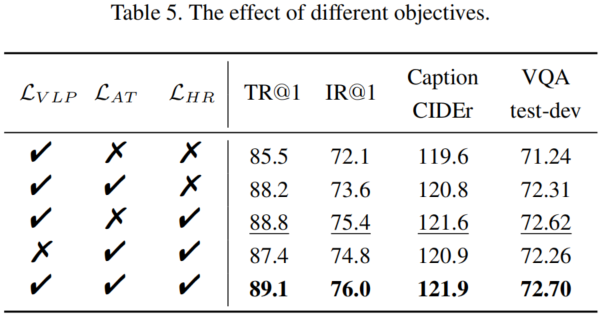
对于视觉-语言预训练,作者引入了三个流行的目标函数:
图像-文本对比(ITC)损失
图像-文本匹配(ITM)损失
语言建模(LM)损失
如下所述:
Image-Text Contrastive (ITC)损失的目标是通过鼓励正向图像-文本对在表示空间中具有相似的表示,与负向对形成对比,从而学习更好的单模态表示,并使视觉编码器和文本编码器的特征空间对齐。
ITC损失已被证明是一种有效的视觉-语言预训练目标。作者按照的方法使用ITC损失,其中引入了一个动量编码器来生成特征,并从动量编码器中创建软标签作为训练目标,以考虑负向对中的潜在正向对应关系。
Image-Text Matching(ITM)损失的目标是学习一种图像-文本多模态表示,能够捕捉视觉和语言之间的细粒度对齐关系。多模态融合表示用于预测一对图像和文本是否为正向(匹配)或负向(不匹配)的关系。
为了找到更具信息量的负样本,作者采用了中的硬负样本挖掘策略,即在一个批次中,具有更高对比相似度的负向对更有可能被选择用于计算损失。通过这种策略,可以增加训练中的对比度,提高模型对正负样本的区分能力。
Language Modeling(LM)损失的目标是在给定图像的情况下生成文本描述。它通过交叉熵损失进行优化,以自回归方式训练模型,最大化文本序列的似然性。与广泛应用于VLP的掩码语言建模损失相比,LM使得模型能够具备将视觉信息转化为连贯字幕的泛化能力。
通过LM损失,模型可以学习到将图像信息转换为有意义描述的能力,并提高模型在生成文本任务中的性能。视觉-语言预训练的总体损失函数可以表示为:
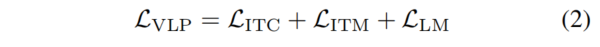
下面,作者介绍如何进行VLP模型的蒸馏(Distillation)。图2概述了多模态蒸馏的过程。作者从隐藏表示和注意力信息传递的角度设计了多个蒸馏目标。
对于隐藏表示信息的传递,先前的研究表明隐藏表示的对齐是一种有效的蒸馏策略,可以高效地从教师模型中学习信息。因此,作者使用隐藏表示蒸馏来最小化隐藏表示之间的差异。其目标函数如下所示:
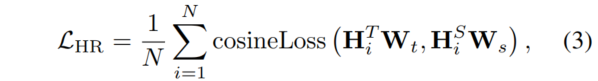
其中,表示Transformer的层数。和是可学习的线性变换,将教师模型和学生模型的表示映射到相同的维度空间。作者考虑了三种隐藏表示用于模态信息传递:视觉表示、文本表示和融合表示。
另一方面,注意力机制已成为自然语言处理(NLP)和计算机视觉(CV)任务中非常成功的神经网络组件,并且在VLP中也起着关键作用。注意力图通过以下方式计算:
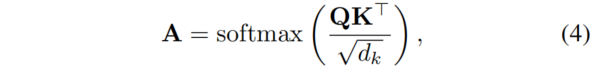
其中,和表示Transformer块中注意力层中的query和key。是Key的维度,用作缩放因子。一些研究表明,预训练语言模型的自注意力分布捕捉到了丰富的语言信息层次结构。在先前的工作中,将自注意力分布进行传递用于Transformer蒸馏,通过优化教师模型和学生模型的注意力分布之间的KL散度来实现:
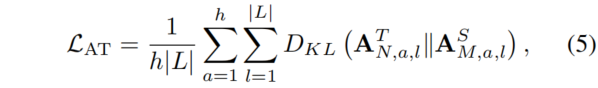
其中,和表示序列长度和注意力头的数量。和分别表示教师模型和学生模型的层数。和分别表示教师模型的第N层和学生模型的第M层的注意力分布。作者考虑了两种基于注意力的映射用于模态信息传递:自注意力图和交叉注意力图。
最后,作者将预训练目标与蒸馏目标相结合。DLIP的总体目标可以表述如下:
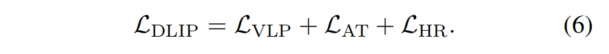
[1].DLIP: Distilling Language-Image Pre-training.
华南理工AI安全团队 联合约翰霍普金斯大学提出抵御联邦学习后门攻击的全新方案
即插即用 Trick | Query-adaptive DETR 提出 Soft Gradient L1 loss,拥挤不是问题

AutoDesk团队提出Segment-Like-Me | SLiME能比SAM分割更丝滑吗?

点击上方卡片,关注「集智书童」公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢