
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4V学会自动操纵电脑,这一天终于还是到来了。
只需要给GPT-4V接入鼠标和键盘,它就能根据浏览器界面上网:
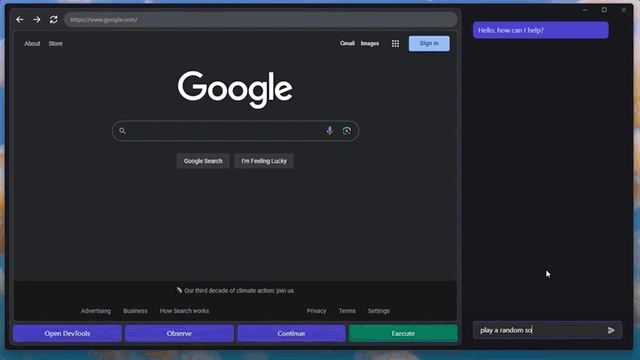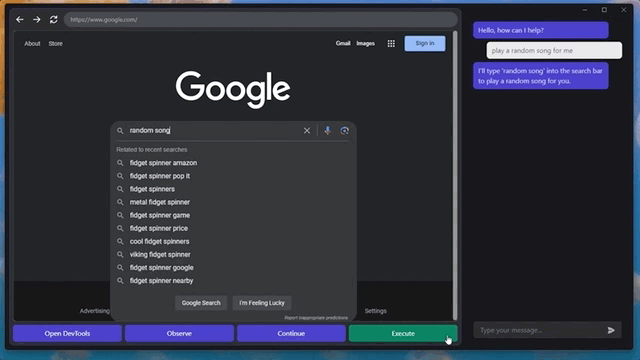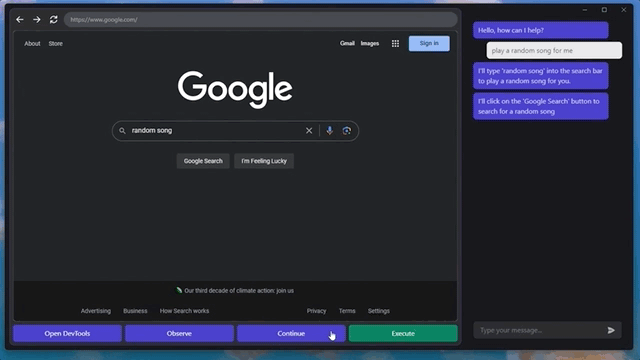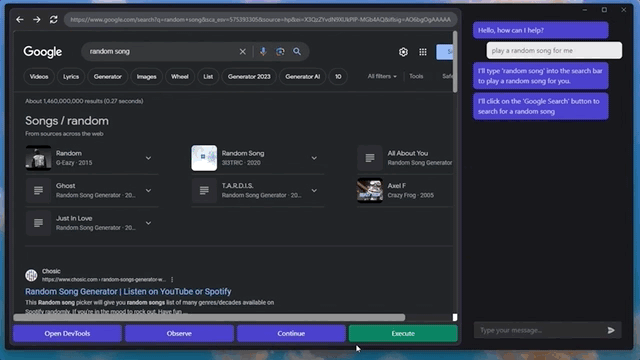
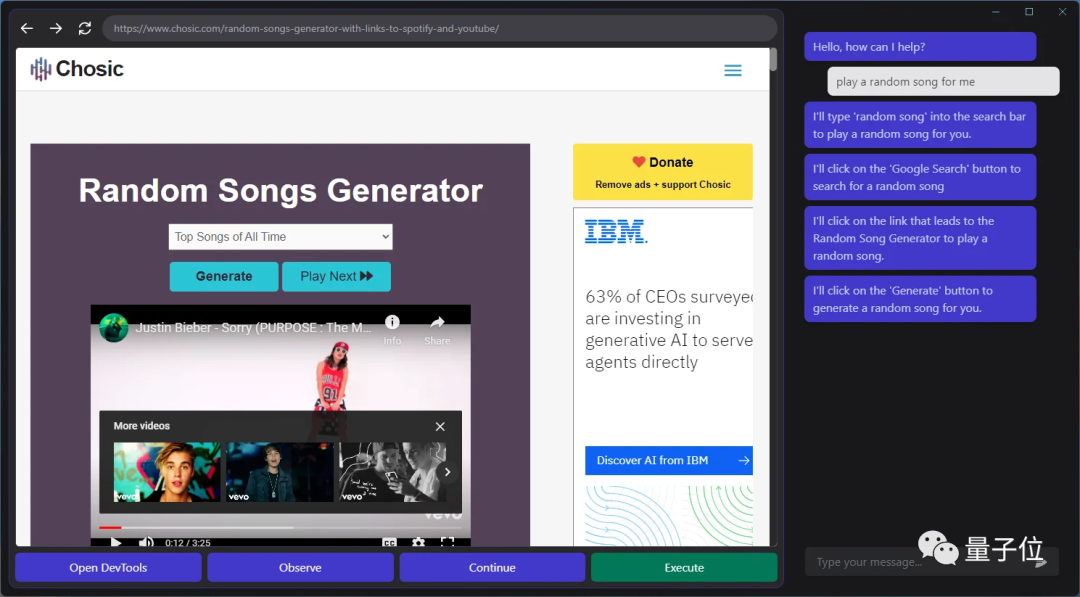
甚至还能快速摸清楚“播放音乐”的播放器网站和按钮,给自己来一段music:
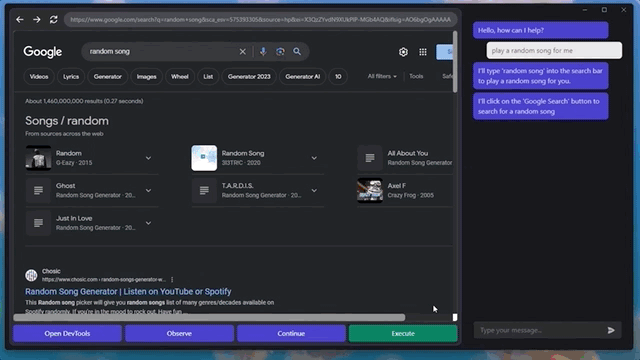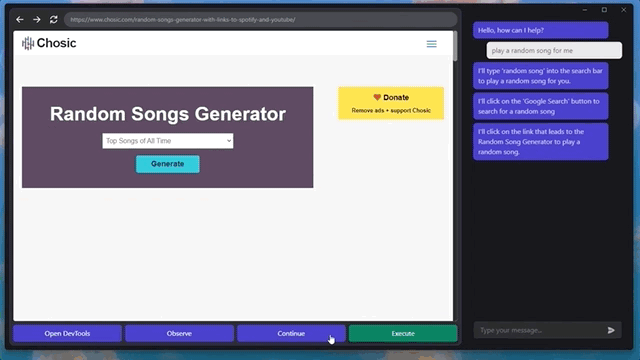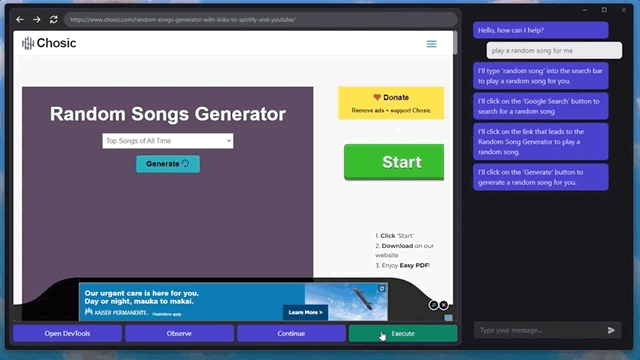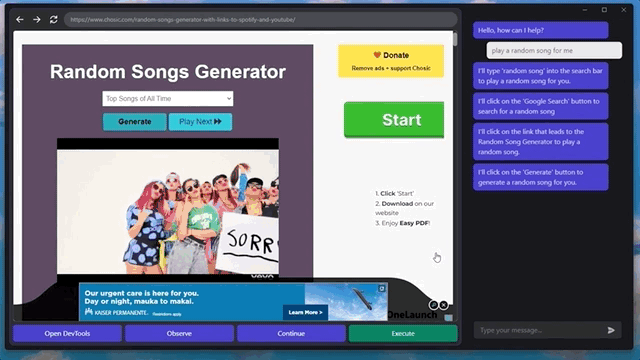
是不是有点细思极恐了?
这是一个MIT本科生小哥整出来的新活,名叫GPT-4V-Act。

只需要几个简单的工具,GPT-4V就能学会控制你的键盘和鼠标,用浏览器上网发帖、买东西甚至是玩游戏。
要是用到的工具出bug了,GPT-4V甚至还能意识到、并试图解决它。

来看看这是怎么做到的。
教GPT-4V“自动上网”
GPT-4V-Act,本质上是一个基于Web浏览器的AI多模态助手(Chromium Copilot)。
它可以像人类一样用鼠标、键盘和屏幕“查看”网页界面,并通过网页中的交互按键进行下一步操作。
要实现这种效果,除了GPT-4V以外,还用到了三个工具。
一个是UI界面,可以让GPT-4V“看见”网页截图,也能让用户与GPT-4V发生交互。
这样,GPT-4V就能将每一步运行思路都通过对话框的形式反映出来,用户来决定是否要继续让它操作。
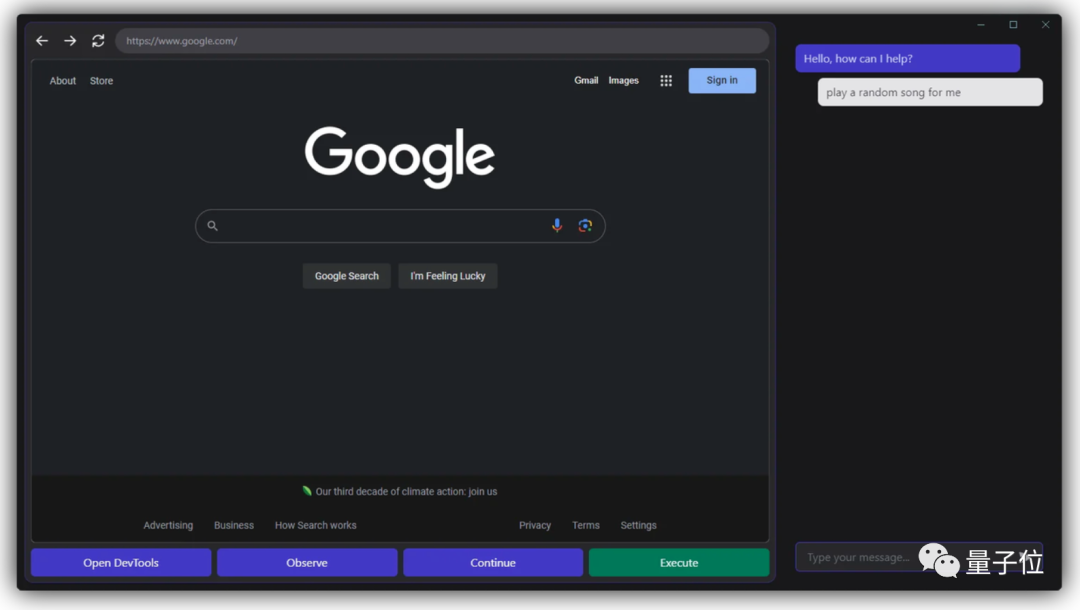
另一个是Set-of-Mark Prompting(SoM)工具,让GPT-4V学会交互的一款工具。

这个工具由微软发明,目的是更好地对GPT-4V进行提示词工程。
相比让GPT-4V直接“看图说话”,这个工具可以将图片关键细节拆分成不同的部分,并进行编号,让GPT-4V有的放矢:

对于网页端也是如此,Set-of-Mark Prompting用类似的方式让GPT-4V知道从网页浏览器的哪个部分找答案,并进行交互。
最后,还需要用到一个自动标注器(JS DOM auto-labeler),可以将网页端所有能交互的按键标注出来,让GPT-4V决定要按哪个。
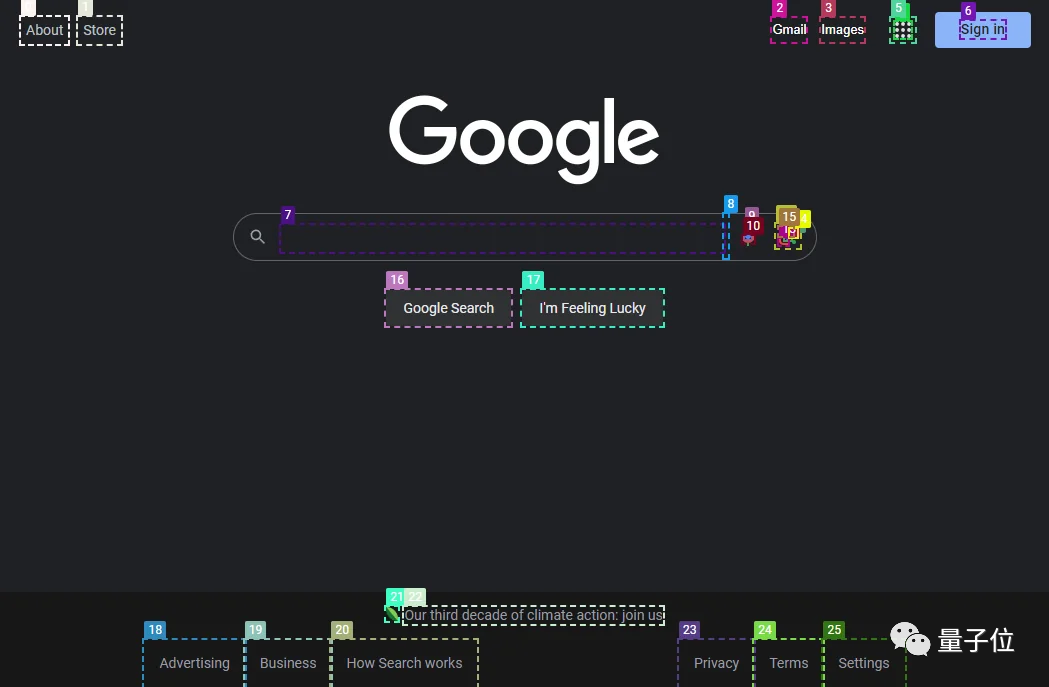
一套流程下来, GPT-4V不仅能准确判断图片上的哪些内容符合需求,还能准确找到交互按键,并学会“自动上网”。
这是个大项目,目前还只实现了部分功能,包括点击、打字交互、自动标注等。
接下来,还有其他的一些功能要实现,例如试试AI打标器(目前网页端的交互还是通过通过JS接口得知哪里能交互,不是AI识别的)、以及提示用户输入详细信息等。

此外,作者也提到,现阶段GPT-4V-Act用法上还有一些需要注意的地方。
例如,GPT-4V-Act可能会被网页打开后铺天盖地的弹窗小广告给“整懵了”,然后出现交互bug。
又例如,目前这种玩法可能会违反OpenAI的产品使用规定:
除非API允许,否则不得使用任何自动化或编程的方法从服务中提取数据并输出,包括抓取、网络收集或网络数据提取。

所以用的时候也要低调一点(doge)
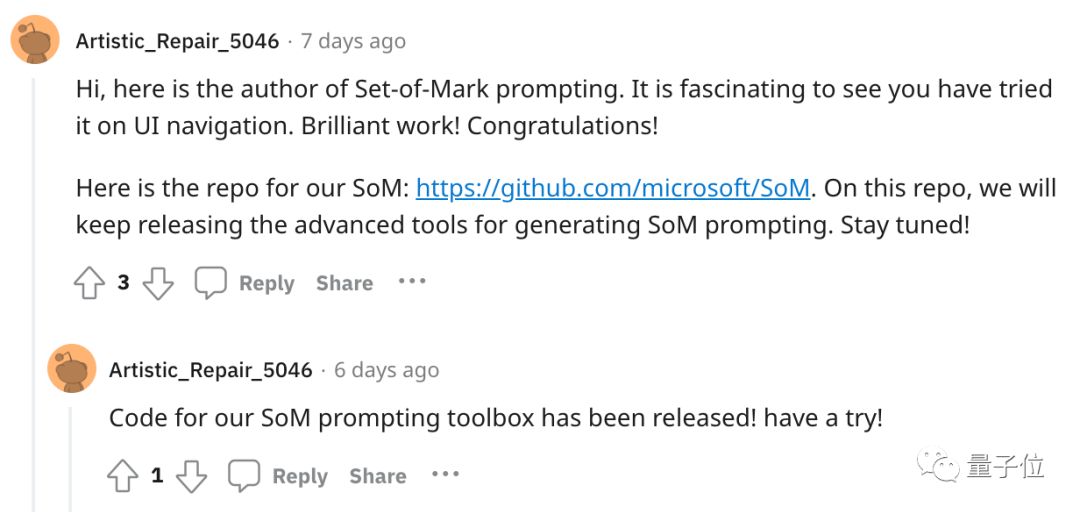
微软SoM作者也来围观
这个项目在网上发出后,吸引了不少人的围观。
像是小哥用到的微软Set-of-Mark Prompting工具的作者,就发现了这个项目:
出色的工作!
还有网友提到,甚至可以用来让AI自己读取验证码。
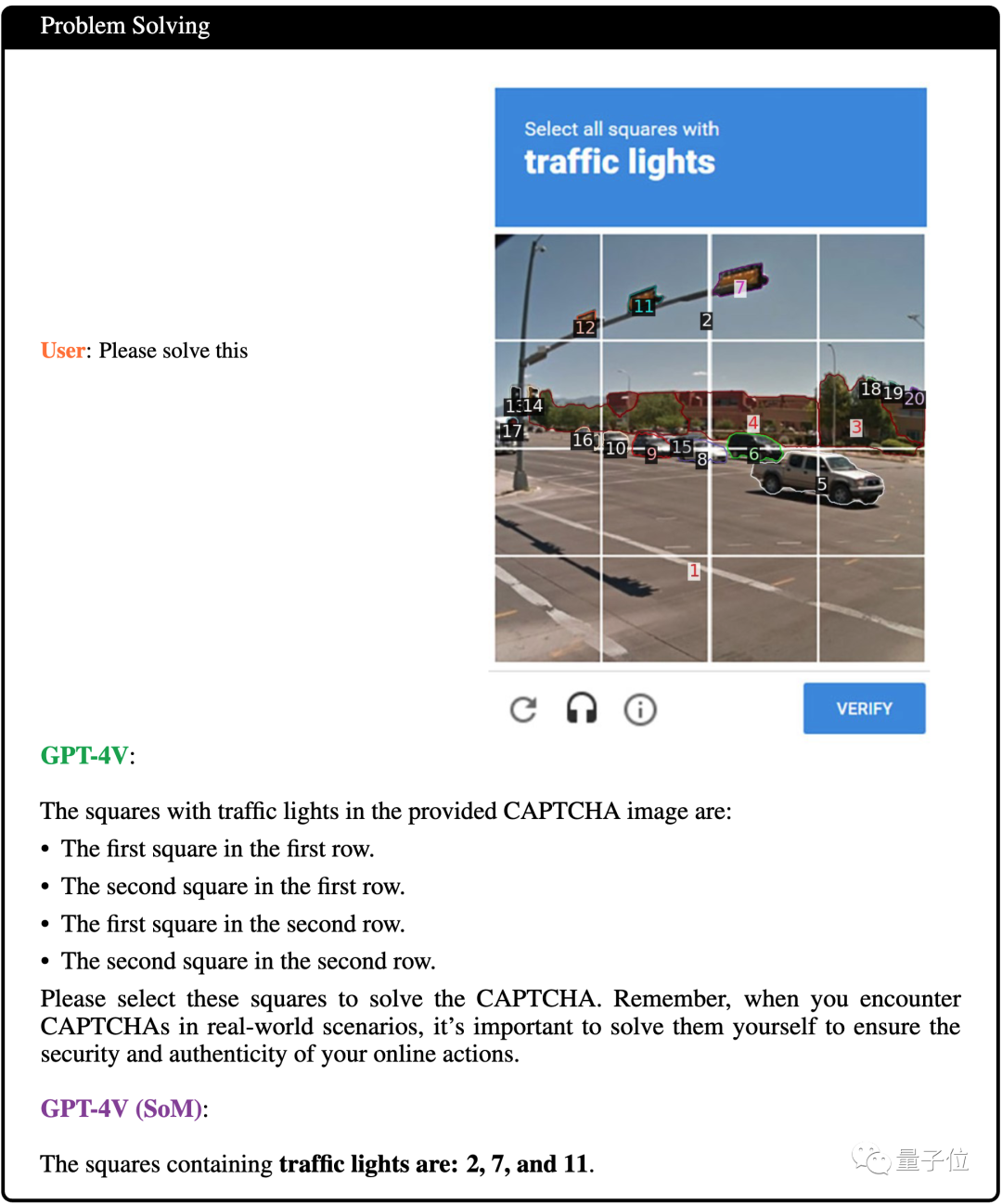
这个在SoM项目中提到过,GPT-4V是能成功解读验证码的(所以以后可能还真不知道是人还是机器在上网 )。
)。
与此同时,也有网友已经在想象桌面流自动化(desktop automation)的操作了。
对此作者回应称:
AI自动标注器应该能实现这个,我也确实在计划制作一个更通用的Copilot。
不过目前GPT-4V还是要收费的,有没有其他的实现方法?
作者也表示,目前还没有,但确实可能会尝试Fuyu-8B或者LLaVAR这样的开源模型。
免费的自动化桌面流AI助手,可以期待一波了。
参考链接:
[1]https://github.com/ddupont808/GPT-4V-Act
[2]https://www.reddit.com/r/MachineLearning/comments/17cy0j7/d_p_web_browsing_uibased_ai_agent_gpt4vact/
— 完 —
《2023年度十大前沿科技报告》案例征集
量子位智库《2023年度十大前沿科技报告》,启动案例征集。诚邀顶级研究机构、一流投资大咖、前沿科技创新公司,参与共创,分享案例。
扫描图片二维码参与前沿科技案例征集。了解更多细节可联系报告负责人:郑钰瑶(微信:CarolineZheng_,请备注企业+姓名)。

点这里👇关注我,记得标星哦~

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢