
今天是2023年11月7日,星期二,北京,天气晴。
主题建模是在大量文本文档集合中发现潜在主题结构的常用技术。我们今天来谈谈这个话题。
传统的主题模型,如潜在Dirichlet分配(LDA),将文档表示为主题的混合体,其中每个主题都是单词的分布。主题通常用最可能的单词表示,但这种表示可能包含不连贯或不相关的单词,使用户难以解释主题。
虽然有些模型能让用户根据需求和领域知识交互式地引导主题,但它们的可用性受到词袋主题格式的限制。
为了解决这些局限性,TopicGPT依靠提示大型语言模型来执行上下文话题生成和分配。
为了解决这些问题,《TopicGPT: A Prompt-based Topic Modeling Framework》(https://arxiv.org/abs/2311.01449)引入了TopicGPT,使用LLM来发现所提供文本集合中的潜在主题。与其他方法相比,TopicGPT生成的主题更符合人类的分类。
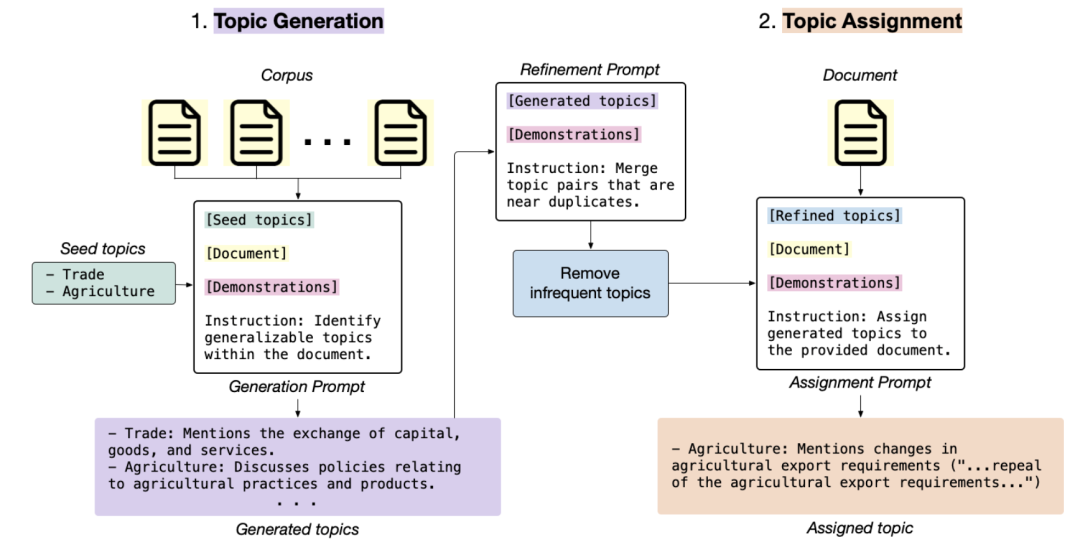
本文对该工作进行介绍,供大家一起参考。
一、实现思路
在具体实现上如下图所示:
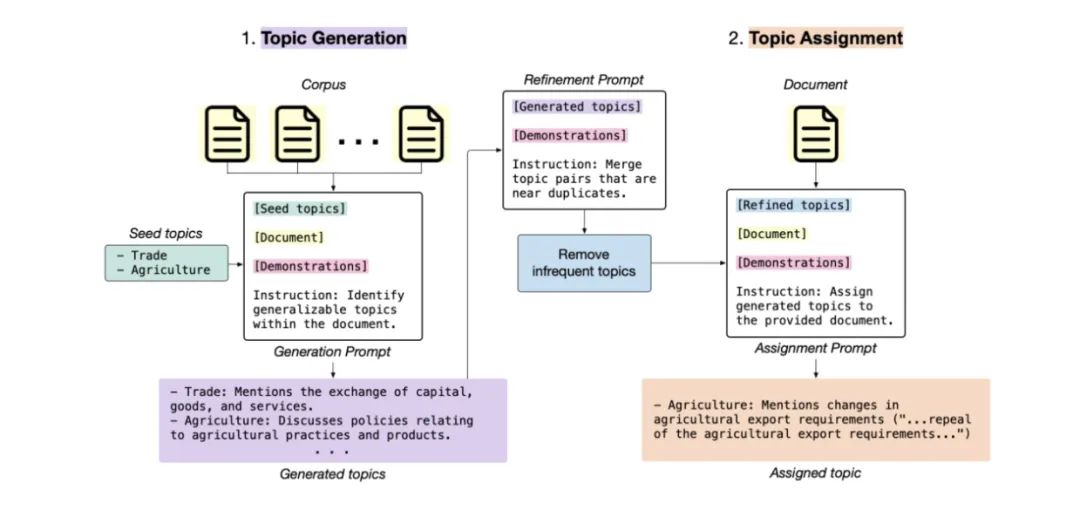
首先,根据输入数据集中的文档样本和之前生成的主题列表,反复提示LLM生成新主题。
然后进一步完善生成的主题集,以整合冗余主题并消除不常见的主题。
最后,给定一个新文档,LLM会将其分配给一个或多个已生成的主题,并提供该文档的引文以支持其分配。 这些引文使该方法易于验证,解决了困扰传统主题模型的一些有效性问题。
与其他方法相比,TopicGPT生成的主题质量更高。在维基百科文章和国会法案两个数据集上,与LDA和BERTopic相比,TopicGPT的主题和赋值与人类标注的基本真实主题的一致性要高得多。
在三个外部聚类指标(单值平均纯度、归一化互信息和调整后的兰德指数)来衡量主题对齐度,发现Top-icGPT比基线有提高;
此外,它的主题与人类标记的主题在语义上更加对齐。进一步的分析表明,TopicGPT的主题质量在各种提示和数据设置下都很稳健。
二、具体实现方案
TopicGPT包括两个主要阶段:主题生成(§3.1)和主题分配。
1、主题生成
主题生成阶段根据输入数据集提示LLM生成一组主题,然后进一步完善这些主题,删除不常用的主题并合并重复的主题。
这一步的输出可以选择性地输入到TopicGPT的分层扩展中,促使模型生成更精细的子主题。
首先,生成新的主题:在第一阶段,反复提示大语言模型(LLM)生成描述性主题。

给定语料库中的一个文档d和一组种子主题S,该模型会被指示要么将d分配给S中的一个现有主题,要么生成一个能更好地描述d的新主题并将其添加到S中。
例如,具体的种子主题示例如下:
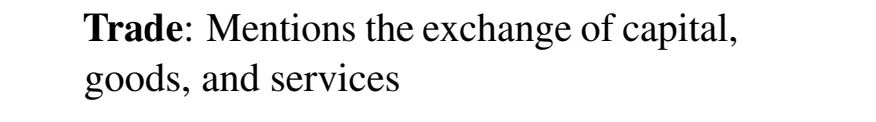
贸易:提及资本、商品和服务的交换 其中"贸易"是主题标签。
最初的种子集由少量人工撰写的主题组成(实验使用了两个种子主题),不需要特定于数据集。
其次,完善生成的主题:首先使用句子嵌入来识别余弦相似度≥0.5的主题对。然后,用五个这样的主题对提示LLM,指示它酌情合并相关或接近重复的主题对。

这一合并步骤可合并多余的主题,并调整各主题之间的特异性,从而返回一个连贯的最终列表。
为了解决上一步可能忽略的次要主题,剔除出现频率较低的主题。为此,跟踪每个主题的生成频率。如果某个话题的出现频率低于"剔除"阈值,就认为该话题是次要的,并将其从最终列表中剔除。

然后,生成话题层次结构:进一步利用TopicGPT来构建多层次的话题层次结构。
具体地,将细化阶段后生成的顶级话题视为顶级话题,并提示LLM在后续级别上生成更具体的子话题。
然后,向模型提供一个包含顶级主题t、种子子主题S′和与顶级主题t相关的文档dt的主题分支。
为了确保子主题是基于文档而不是幻觉,模型还必须返回支持每个子主题的具体文档。
如果文档无法在单个提示中找到,就会将它们划分到不同的提示中,并在随后的提示中包含由较早的提示生成的副标题。
2、主题分配
在分配阶段,目标是在生成的主题列表和数据集中的文档之间建立有效且可解释的关联。

首先,需要向LLM提供了生成的主题列表、2-3个示例和一份文档(有兴趣获取其中的主题)。然后,指示模型为给定的文档分配一个或多个主题。最终输出包括分配的主题标签、特定于文档的主题描述以及从文档中提取的引文,以支持这一分配。
引用文本提高了TopicGPT所做标记的可验证性,而这一直是LDA等传统方法所关注的问题。
主题任务示例如下:

农业:提及农产品出口要求的变化("......农产品出口要求的提高......")。其中"农业"是指定的主题标签,其后是主题描述和括号内的文件引文。
其次,为了解决格式不正确或质量不高的主题分配问题,加入了自我修正步骤。具体地,使用一个解析器来识别幻觉主题分配或无效回复(如"无"/"错误")。随后,向LLM提供被识别的文档和错误类型,打乱主题列表以增加随机性,并提示模型重新分配有效的主题。
三、实验步骤及结论
在实验对比环节,使用两个有标签的英语数据集将TopicGPT与两个流行的话题模型进行了比较。目标是评估TopicGPT的输出是否与人类编码的基本真实主题一致,并测试其在各种设置下的鲁棒性。
1、数据集
使用了两个英文数据集进行评估:Wiki和Bills。对这两个数据集采用了Hoyle等人的处理流程。
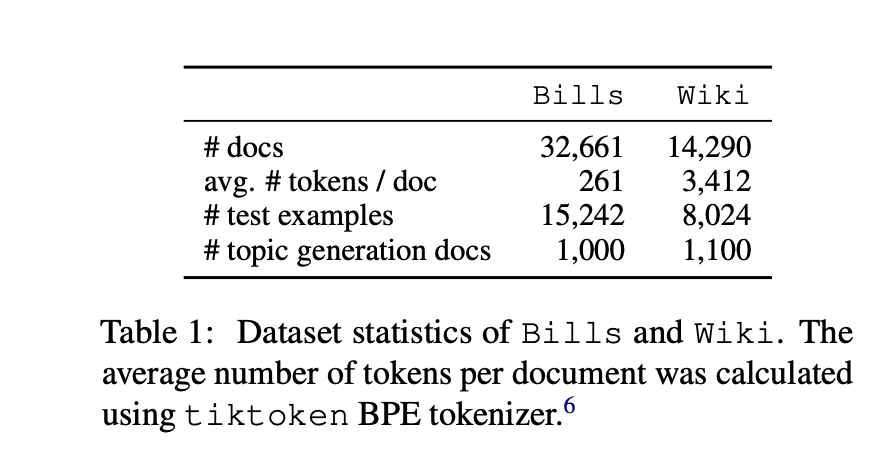
Wiki数据集包含15个高级标签、45个中级标签和279个低级标签,均由人工标注。
Bills包含第110-114届美国国会的32661份法案摘要。该数据集带有21个高级和114个低级人工注释标签。
考虑了两种流行的主题模型,它们遵循不同的范式:LDA和BERTopic。
LDA使用带有Gibbs采样的LDA的MALLET实现。为了公平比较,将主题数k控制为等于TopicGPT生成的主题数。
BERTopic通过对文档的句子转换器嵌入进行聚类来获得主题,主题数k等于TopicGPT生成的主题数。

2、实验结果
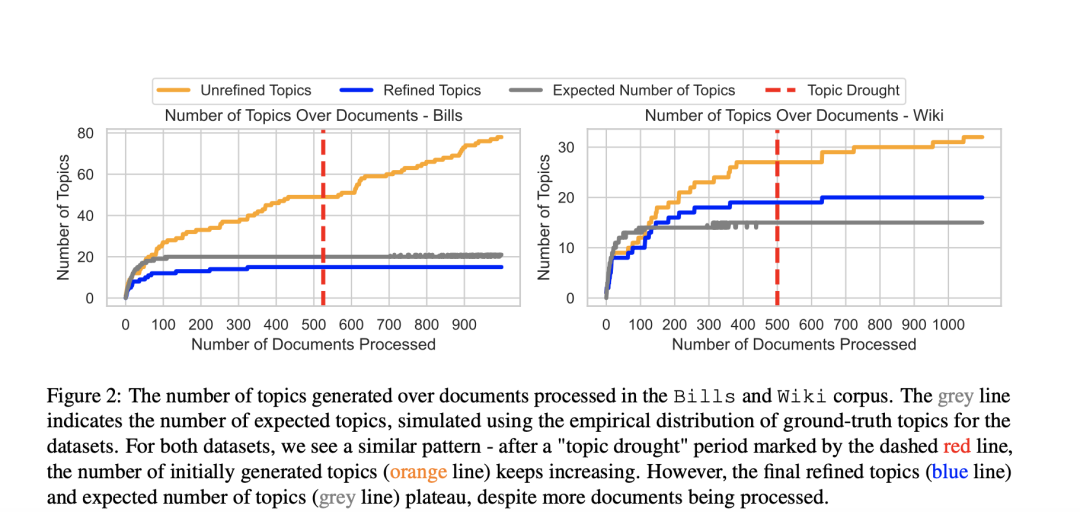
先看主题聚类的情况,在Bills和Wiki语料库中处理的文档所产生的主题数量。灰线表示预期主题数,是根据数据集的真实主题的经验分布模拟得出的。
对于这两个数据集,看到了类似的模式:在红线虚线标示的"话题荒"时期过后,最初生成的话题数量(橙色线)不断增加。尽管处理了更多的文档,最终完善的主题(蓝线)和预期的主题数量(灰线)却趋于平稳。

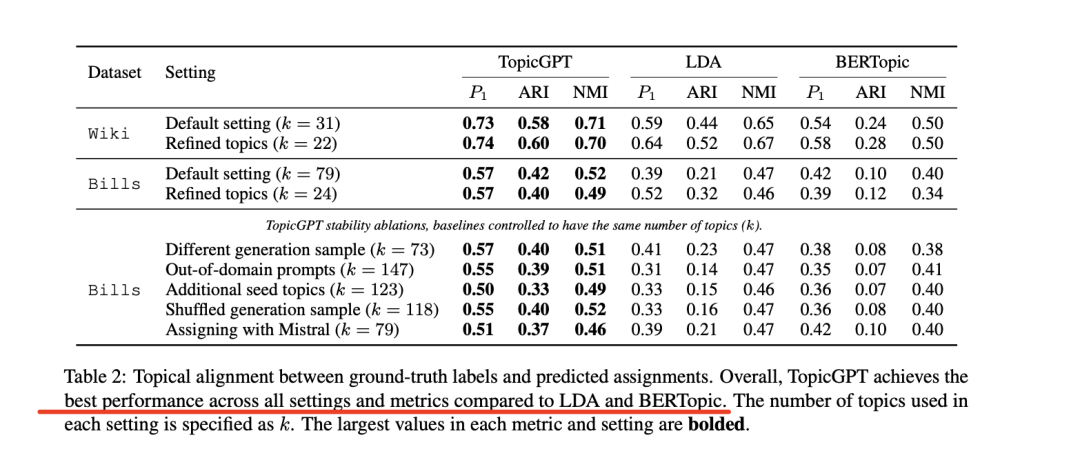
如表2所示,与基线模型相比,Top-icGPT识别的主题与人类标注的标签更加一致,而且这种改进在所有数据集、设置和评估指标中都是成立的。
在两个基线模型中,LDA在所有指标上都普遍优于BERTopic,这表明LDA仍然是一个强大的基线模型。
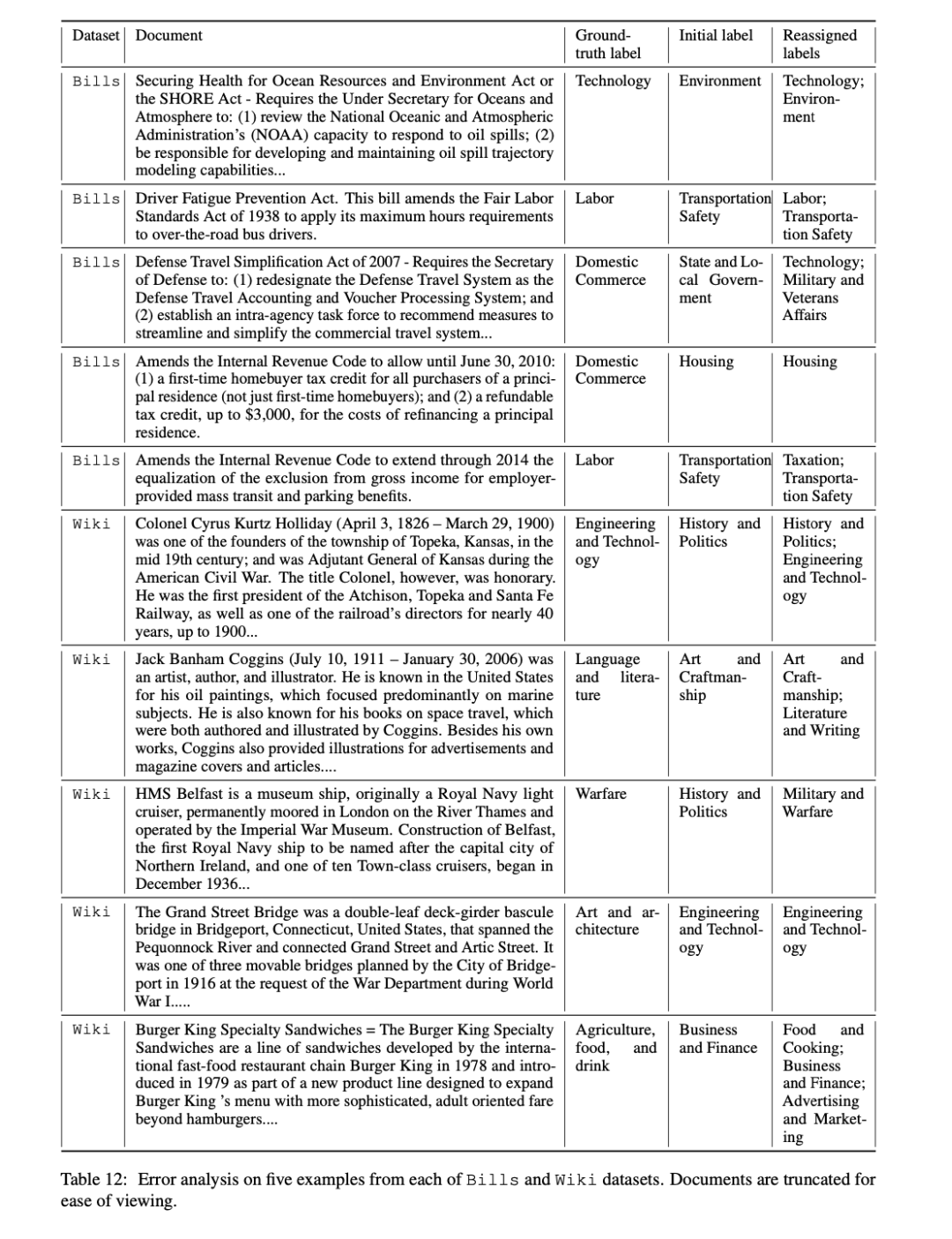
为了充分理解TopicGPT和人类标签之间的分歧,仔细研究了五个默认设置下基本事实主题和TopicGPT不一致的分配,发现每个抽样文档都可以合理地作为多个主题。如下所示:
总结
本文介绍了《TopicGPT: A Prompt-based Topic Modeling Framework》(https://arxiv.org/abs/2311.01449)这一工作,该工作引入了TopicGPT,使用LLM来发现所提供文本集合中的潜在主题。与其他方法相比,TopicGPT生成的主题更符合人类的分类。
不过,该工作也存在不足,例如:
其效果依赖于一个较好的大模型,此外上下文限制。
长文本限制,该方法需要截断文档以适应TopicGPT的上下文长度限制。如果只提供部分文档,就会失去潜在的有价值的上下文,并有可能误导完整文档的内容。虽然在这些初步实验中截断是必要的,但认识到这并不是一个理想的解决方案。
其对非英语种的效果问题。其尚未在非英语数据集上对TopicGPT进行评估。这块需要我们进行实验,具体的,可以参考其项目地址https://github.com/chtmp223/topicGPT。
参考文献
1、https://github.com/chtmp223/topicGPT
2、https://arxiv.org/abs/2311.01449
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢