
极市导读
Meta-Transformer 是一个能够编码12种模态的数据的框架,它使用冻结权重的 Encoder,在没有任何配对多模态训练数据的情况下进行多模态感知。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 Meta-Transformer:用一个 Transformer 模型去编码12类模态
(来自 CUHK, Shanghai AI Lab)
1.1 背景和动机:嵌入特征的模态局限性
1.2 Meta-Transformer 主要思想
1.3 数据序列化器
1.4 Meta-Transformer 训练策略
1.5 实验设置
太长不看版
Meta-Transformer 是一个能够编码12种模态的数据的框架,它使用冻结权重的 Encoder,在没有任何配对多模态训练数据的情况下进行多模态感知。在 Meta-Transformer 中,来自不同模态的原始输入数据被映射到共享的 token space 中。然后,一个具有冻结参数的 Transformer Encoder 来提取输入数据的高级语义特征。
Meta-Transformer 由3个主要组件组成:统一的数据 tokenizer、模态共享的 Transformer Encoder 和特定于下游任务的 head,Meta-Transformer 是第一个在具有未配对数据的 12 种模态中执行统一学习的框架。
1 Meta-Transformer:用一个 Transformer 模型去编码12类模态
论文名称:Meta-Transformer: A Unified Framework for Multimodal Learning
论文地址:
http:/arxiv.org/pdf/2307.10802.pdf
项目主页:
http://kxgong.github.io/meta_transformer/
代码地址:
http://github.com/invictus717/MetaTransformer
1.1 背景和动机:处理多种模态的统一的模型
人脑,被视为神经网络模型灵感来源的 "神经网络 ",可以同时处理来自视觉、听觉和触觉等各种感官输入的信息。此外,一个来源的知识可以帮助理解另一个来源的知识。然而,在深度学习中,设计一个能够处理多种数据格式的统一网络并非易事,因为模态之间存在巨大的差距。
每种模态的数据都有独特的数据模式,因此我们在在一个模态上训练的模型也就很难适应于另一种模态。比如图像模态的数据像素比较密集,因此作者认为图片信息有比较多的信息冗余,但是自然语言的信息就不是这样的情况。点云在 3D 空间中具有稀疏分布,这使得它们更容易受到噪声,且难以表征。音频谱图是时变的非平稳数据模式,由频域波的组合组成。视频数据包含一系列图像帧。图数据将实体表示为节点,关系表示为图中的边,建模实体之间的复杂、多对多的关系。
由于各种数据模式固有的实质性差异,通常的做法是利用不同的网络架构分别编码每个模态。因此,设计一个能够利用模态共享参数空间来编码多种数据模态的统一框架仍然是一个重大挑战课题。
有一些多模态的框架比如 VLMO[1],OFA[2],和 BEiT-3[3]通过对配对数据的大规模多模态预训练,使用一个模型理解多模态的输入数据,但是它们更侧重于视觉和语言,无法跨模态共享整个编码器。
由于 Transformer 模型在 NLP,2D 视觉,3D 视觉和音频信息处理中的成功,激励研究人员探索这个多功能模型的通用性,是否可以打造一个能够统一多种模式的基础模型,最终在所有模式中实现人类水平的感知能力。
Meta-Transformer 探索了 Transformer 架构处理12种模态的潜力,包括图像 (images)、自然语言 (natural language)、点云 (point cloud)、音频谱图 (audio spectrogram)、视频 (video)、红外 (infrared)、高光谱 (hyperspectral)、X射线 (X-Ray)、IMU、表格 (tabular)、图 (graph) 和时间序列 (time-series) 数据,如图1所示。
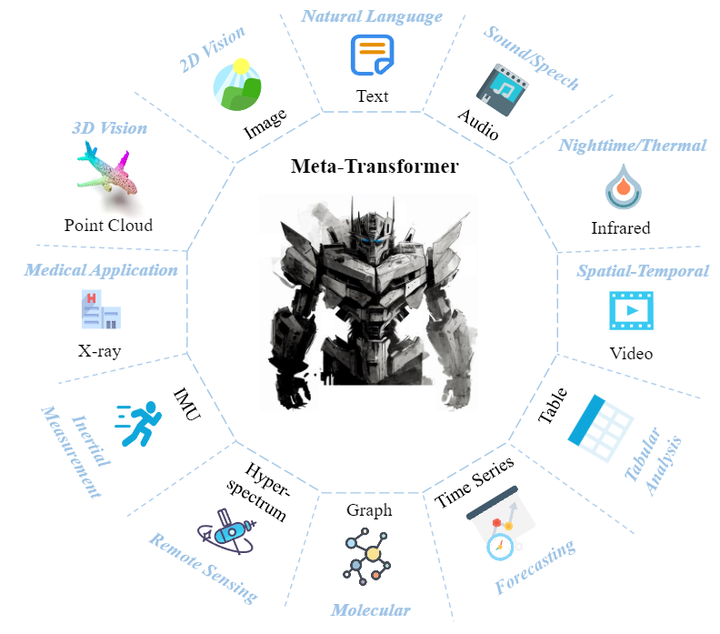
Meta-Transformer 是第一个使用一套参数来同时编码来自12个模态数据的框架。Meta-Transformer 主要由3部分组成:模态专家 (modality-specialist),数据序列化器 (data-to-sequence tokenization),和模态共享的编码器 (modality-shared encoder) 和特定任务的头 (task-specific heads)。Meta-Transformer 的具体做法在下面集结分别介绍。
1.2 Meta-Transformer 主要思想
如下图2所示是 Meta-Transformer 的架构图。
假定 个模态的数据和对应的标签分别是: 和 , 作者假定对于每种模态都有一个参数空间 , 可以用来处理该模态的数据。Meta-Transformer 希望找到一个共享的参数空间 使其满足:
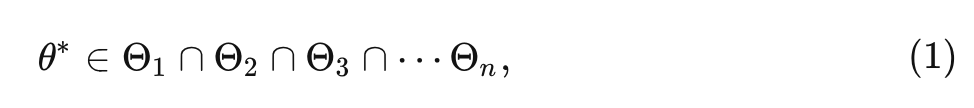
并且假定满足:
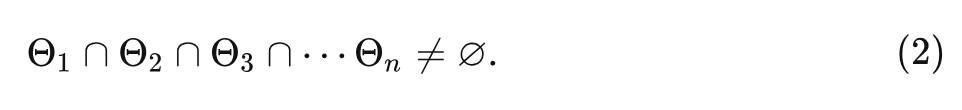
多模态神经网络可以表述为一个统一的映射函数 , 满足:
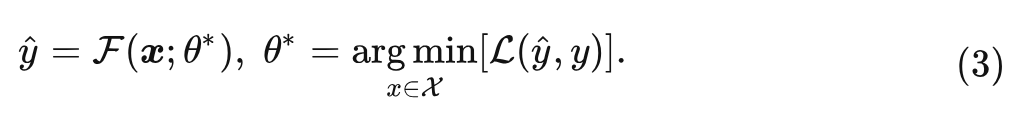
就是对所有模态的数据, 优化模型参数 , 使得模型的预测值和真实值尽量接近。
1.3 数据序列化器
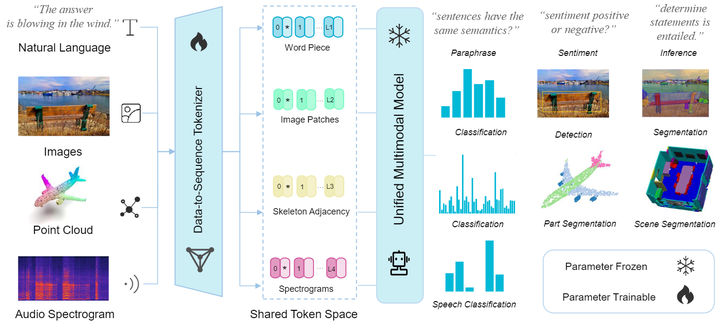
数据序列化器 (data-to-sequence tokenization) 的功能是将各种模态的数据转化成 token Embeddings,如下图3所示。
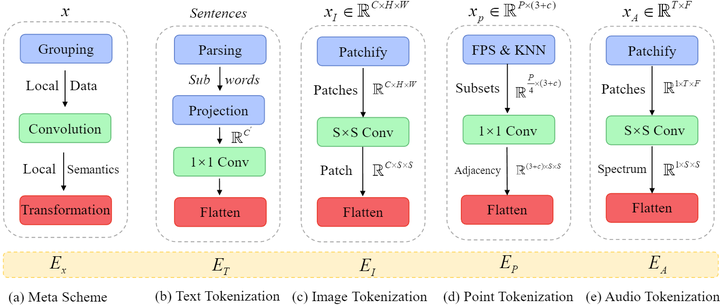
具体而言作者使用 来分别表征 text,image,point cloud,audio spectrogram 模态的数据。
自然语言
作者遵循了 BERT[4] 和 RoBERTa[5]的做法,使用了带有 30,000 token 词汇表的 WordPiece embeddings[6],把原有的单词分成子词,例如原句是 "The supermarket is hosting a sale",处理后的句子是:""_The _super market _is _host ing _a _sale"。每个原始词的第1个字符的前面将与1个特殊的字符“_”堆叠在一起,表示自然词的开头。每个子词对应于词汇表中的唯一标记,然后投影到 word Embedding 的高维特征空间。因此,每个输入文本被转换为一组 token Embedding ,其中 是 token 的数量, 是 Embedding 的维度。
图片
为了适应 图片, 作者把输入图片 reshape 成为 patches 的序列 ,其中 代表原始图片的分辨率, 代表通道数, 代表 Patch Size, 代表 Patch 的数量。然后, 使用投影层将嵌入维度投影到 维:
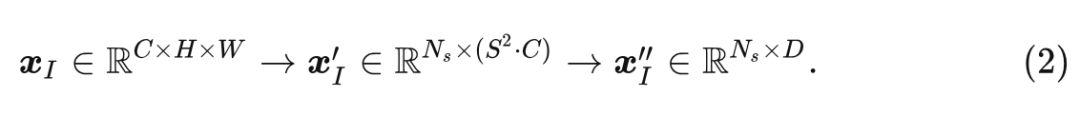
对于视频就把 2D 卷积替换为 3D 卷积。
点云
为了学习 3D 模式, 作者将点云从原始输入空间转换为 token Embedding 空间。表示 个点的点云, 其中 表示 3D 坐标, 是第 个点的特征。通常, 包含颜色、视点、法线等视觉提示。作者使用 Farthest Point Sampling (FPS) 的做法对具有固定采样率 (1/4) 的原始点云的代表性骨架进行采样, 然后使用 -最近邻 (KNN) 对相邻点进行分组。基于包含局部几何先验的 group set, 作者因此构造了具有 group subset 中心点的邻接矩阵, 以便于进一步覆盖 3D 对象的综合结构信息。
最后, 作者从 个子集中聚合结构表征, 得到点嵌入为:
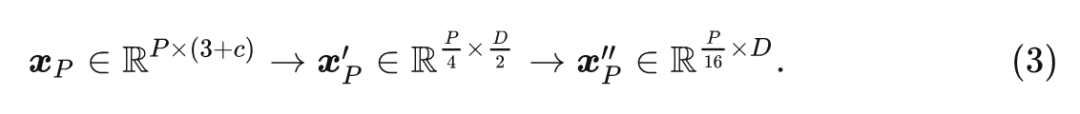
音频频谱图
作者使用 log Mel 滤波器 [7]组对持续时间为 秒的音频波形进行预处理, 然后使用步幅为 的汉明窗口在 的频率上将原始波拆分为 区间, 并将原始波进一步转换为 维滤波器组。
随后, 作者将谱图按时间和频率维度分割成小 Patch, Patch Size 为 。与图像 Patch 不同, 音频补丁在谱图上重叠。在 之后, 作者还选择通过 卷积将整个谱图分割为 个 Patch, 然后将 Patch 扁平化为 token 序列:
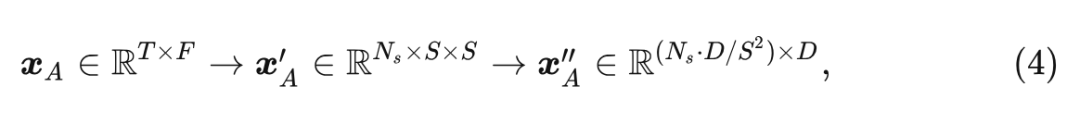
式中, 和 分别代表时间和频率的维度。
1.4 Meta-Transformer 训练策略
Meta-Transformer 编码器
作者利用 ViT 作为 Backbone 网络,并通过对比学习在 LAION-2B 数据集上对其进行预训练,强化了它编码通用 token 的能力。对于文本理解,作者利用 CLIP 的预训练文本 tokenizer 将句子分割成子词并进一步转化为词嵌入。
遵循 ViT 的做法, 作者加了一个可学习的 token , 并通过 Transformer 模型得到其最终的 hidden state 通常用于执行识别任务。为了加强位置信息, 作者将位置编码合并到 token Embedding 中, 输入给 Encoder, 另外使用的是可学习的 1D 位置编码。
Transformer Encoder 的架构遵循 ViT 的设计:
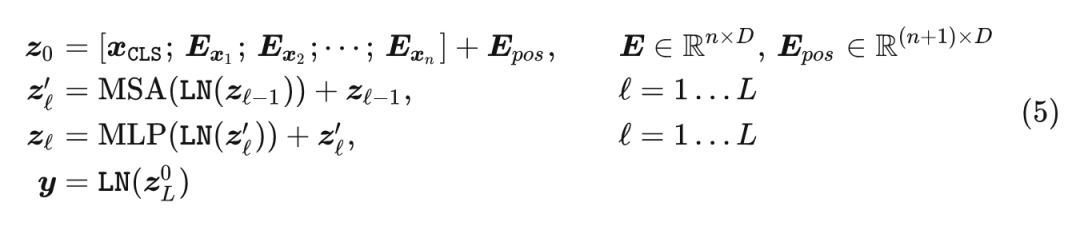
式中, 表示 token Embedding, 表示 token 的数量, 表示位置编码。
特定任务的 head
在通过 Transformer Encoder 得到表征之后,作者进一步把它们送到特定任务的 head 中。它们主要由 MLP 构成,并且因模式和任务而异,Meta-Transformer 的学习目标可以概括表达为:
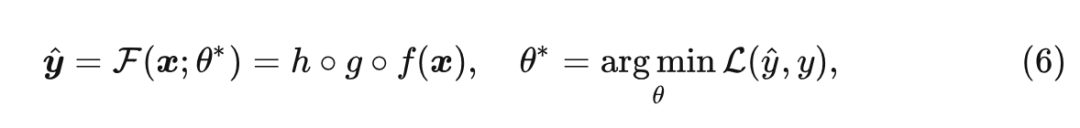
式中, 分别表示 tokenizer, Encoder 和 head。
1.5 实验设置
Text understanding
对于文本理解评估,作者采用通用语言理解评估 (GLUE) 基准,其中包含几个不同的数据集,涵盖了广泛的自然语言理解任务。
Image understanding
1) 分类:作者在 ImageNet-1K 上进行了实验。大模型先在 ImageNet-22K 上做 200 Epochs 的预训练,再在 ImageNet-1K 上进行 20 Epochs 的微调。
2) 目标检测:作者使用 Mask R-CNN 作为检测器对 MS COCO 数据集进行实验,训练每个模型12个 Epochs。
3) 语义分割:作者在 ADE20K 上训练分割头 UperNet 160k 次迭代。
Infrared, X-Ray, and Hyperspectral data understanding
作者分别使用 RegDB、Chest X-Ray 和 Indian Pine 4 数据集对红外图像、X 射线扫描和高光谱数据识别进行了实验。
Point cloud understanding
1) 分类:作者为了评估 Meta-Transformer 在 3D Object Cassification 中的性能,作者使用 ModelNet-40 基准,由 40 个类别中的 CAD 模型组成,有 9,843 个训练样本和 2,468 个验证样本。
2) 语义分割:为了评估三维点云分割的性能,作者评估了 S3DIS 和 ShapeNetPart 数据集上的模型。S3DIS 数据集包含6个大型室内区域和13个语义类,包括271个房间。ShapeNetPart 数据集包括16个形状类别的16,880个对象模型。
Audio recognition
对于音频识别,作者利用 Speech Commands V2 数据集,该数据集由 35 个常见语音命令的 105829 个1秒记录组成。
Video recognition
对于视频理解,作者在 UCF101 数据集上进行了实验,用于动作识别。
Time-series forecasting
对于时间序列预测,作者在 ETTh1、Traffic5、Weather6 和 Exchange 数据集上进行了实验,并使用 Autoformer 的分词器。
Graph understanding
作者在 PCQM4M-LSC 数据集上进行了实验,这是一个大规模数据集,由 4400 万个有机分子组成,具有多达 23 个重原子及其相应的量子力学特性。凭借使用机器学习预测分子特性的目标,它在药物发现和材料科学中有着广泛的应用。
Tabular analysis
作者对 UCI 存储库7的成人和银行营销进行了实验,使用 TabTransformer 的 tokenizer 对原始表格数据进行编码。
IMU recognition
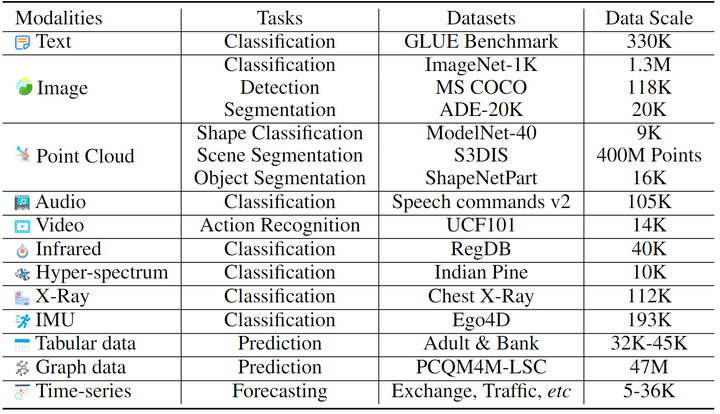
为了评估 Meta-Transformer 理解惯性运动系统的能力,作者在 Ego4D 数据集上进行了实验 IMU 传感器分类。以上实验设置如下图4所示。
1.6 实验结果
自然语言理解任务实验结果
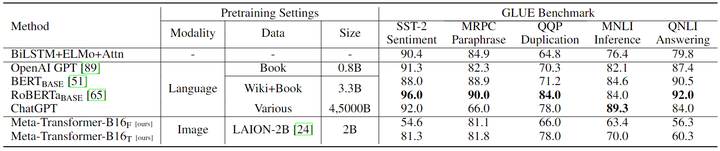
如下图5所示是文本理解任务的 GLUE 基准上的实验结果,作者比较了 BERT 、RoBERTa 和 ChatGPT 等各种最先进的方法。当使用在图像上预训练的冻结参数时,Meta-Transformer-B16F 在 sentiment (SST-2) 得分为 54.6%,在 paraphrase (MRPC) 得分为 81.1%、在 duplication (QQP) 得分为 66.0%、在 inference (MNLI) 得分为 63.4%、在 answering (QNLI) 任务得分为 56.3%。尽管 Meta-Transformer 在 GLUE 基准测试中的表现可能与 BERT、RoBERTa 或 ChatGPT 的性能不如 BERT、RoBERTa 或 ChatGPT 的表现令人印象深刻,但它仍然表现出具有竞争力的性能、适应性和理解自然语言的潜力。
图像理解任务实验结果
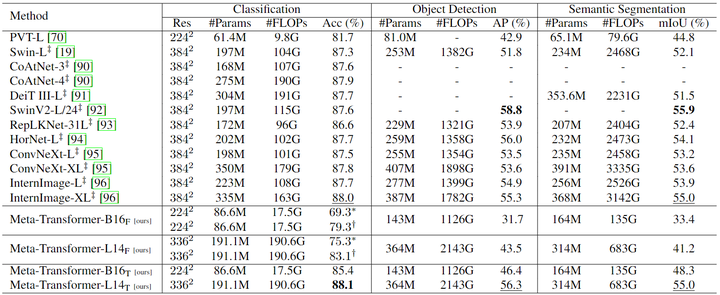
如图6所示,与 Swin Transformer 系列 和 InternImage 相比,Meta-Transformer 在图像理解任务上打造了出色的性能。在图像分类方面,在 CLIP 文本编码器的帮助下,Meta-Transformer 在 Meta-Transformer-B16F 和 Meta-Transformer-L14F 的零样本分类下提供了出色的性能,分别达到 69.3% 和 75.3%。同时,当进一步微调预训练参数时,Meta-Transformer 可以优于现有的先进方法,Meta-Transformer-B16T 和 Meta-Transformer-L14T 分别达到 85.4% 和 88.1% 的准确率。后者在 ImageNet 分类上优于 SwinV2-L/24 的 87.6% 和 InternImage-XL 的 88.0%。
红外、高光谱和 X 射线实验结果

如图7左侧显示了 Meta-Transformer 和其他先进方法在 RegDB 数据集上的性能比较,用于红外图像识别。Meta-Transformer-B16F 展示了具有竞争力的结果,Rank-1 准确率为 73.50%,mAP 为 65.19%。虽然它可能不会优于性能最好的方法,但 Meta-Transformer 被证明是红外图像识别任务的简单可转移方法。这些结果表明 Meta-Transformer 在处理与红外图像相关的挑战方面的潜力,并有助于该领域的进展。
图7右侧显示了 Meta-Transformer 在 Indian Pine 数据集上的性能,用于高光谱图像识别。在完全调整所有参数时,普通 Vision Transformer 也表现良好。Meta-Transformer-B16F 在高光谱图像识别上表现出具有竞争力的结果,总体精度较低。但是与其他方法相比,Meta-Transformer 具有明显更少的可学习的参数 (只有 0.170M)。这揭示了将 Meta-Transformer 应用于遥感、环境监测和矿物勘探的一个有前途的发展方向。
对于 X 射线图像,类似于处理红外图像,我们采用与常见可见图像相同的图像标记器。从图8中可以观察到 Meta-Transformer 可以达到 94.1% 的准确率具有竞争力的性能。
3D 点云理解实验结果
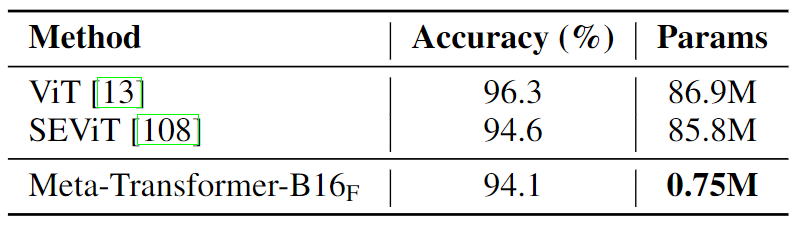
如下图9所示为点云理解任务的实验结果,作者比较了 Meta-Transformer 与其他最先进的方法在 ModelNet-40、S3DIS 和 ShapeNetPart 数据集上的性能。任务包括了 Classification, Semantic Segmentation, 和 Object part Segmentation。在 2D 数据上进行预训练时,Meta-Transformer-B16F 表现出具有竞争力的性能,在 ModelNet-40 上实现了 93.6% 的整体精度 (OA),且只有 0.6M 的可训练参数,这与性能最佳的模型相当。在 S3DIS Area-5 数据集上,Meta-Transformer 使用 2.3M 参数优于其他平均 IoU (mIoU) 为 72.3% 的方法,平均精度 (mAcc) 为 83.5%。此外,Meta-Transformer 在 ShapeNetPart 数据集中表现出色,使用 2.3M 参数,在实例 mIoU (mIoUI ) 和类别 mIoU (mIoUC ) 上实现了最高分,分别为 87.0% 和 85.2%。总之,与其他最先进的方法相比,Meta-Transformer 在点云理解任务方面表现出显着的优势,在可训练参数更少的情况下提供了具有竞争力的性能。
音频识别实验结果
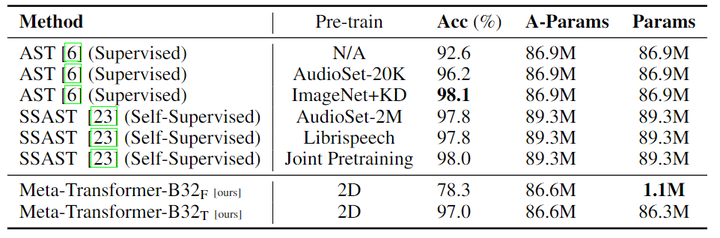
如下图10所示为音频识别任务的实验结果,为了公平地比较 Meta-Transformer 与现有的类似规模的音频 Transformer 模型,作者使用 Meta-Transformer-B32 对音频识别任务进行了实验。使用冻结参数,Meta-Transformer-B32F 达到了 78.3% 的精度,同时只需要对 1.1M 参数进行调整。Meta-Transformer-B32T 模型在调整参数时表现出 97.0% 的精度,而 AST 模型的精度仅为 92.6%。当 AST 在 ImageNet 上进行预训练并辅以额外的知识蒸馏 (KD) 时,它实现了 98.1% 的改进性能,但可训练参数数量较多 86.9M。SAST 模型显示准确度得分从 97.8% 到 98.0%,同时需要 89.3M 参数。这些结果表明,Meta-Transformer 在音频领域具有竞争力,证明了它在不同领域的通用性和有效性。
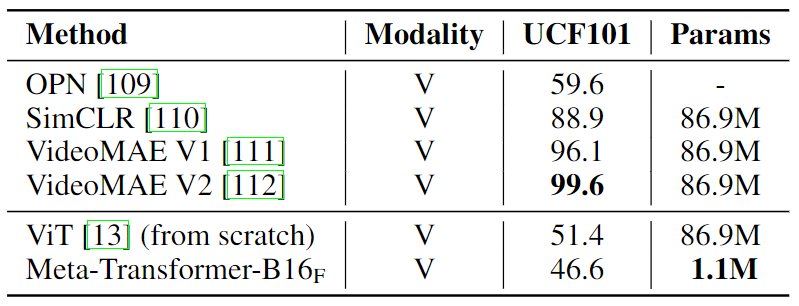
视频识别实验结果
如下图11所示为视频识别任务的实验结果,图11展示了 Meta-Transformer 和现有先进方法在 UCF101 数据集上用于视频理解的性能比较。最先进的为视频识别定制化的方法实现了超过 90% 的精度。Meta-Transformer 仅包含 1100 万个可以忽略不计的可训练参数,同时获得了 46.6% 的精度,而其他方法必须训练大约 86.9 万个参数。尽管 Meta-Transformer 无法击败其他最先进的视频理解模型,但 Meta-Transformer 因其显着降低的可训练参数计数而脱颖而出,这表明统一的多模态学习的潜在好处和更少的架构复杂性。
时间序列预测任务实验结果
如下图12所示为时间序列预测任务实验结果,为了探索 Meta-Transformer 用于时间序列预测的能力,作者对包括 ETTh1、Traffic、Weather 和 Exchange 在内的几个广泛采用的长期预测任务基准进行了实验。
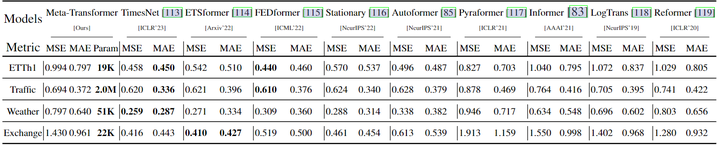
从图12中可以有以下观察结果:
1) 在大多数模型参数固定的情况下,Meta-Transformer 仍然可以在这些数据集上超越现有的方法,包括Pyraformer、Informer、LogTrans 和 Reformer。
2) Meta-Transformer 的可训练参数数量非常少。仅有 19K 可训练参数,Meta-Transformer 仍然可以胜过 Informer。当训练 2M 参数时,Meta-Transformer 可以直接优于 Pyraformer。因此,在感知任务上预训练的 Meta-Transformer 也可以应用于时间序列预测任务,这对该领域的鼓舞人心。
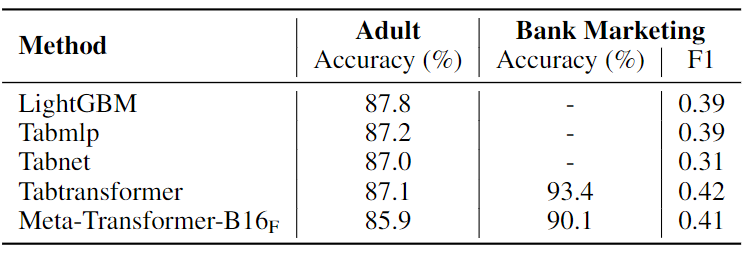
表格数据理解任务实验结果
如下图13所示为表格数据理解任务实验结果,作者提供了不同方法在成人人口普查和银行营销数据集上表格数据理解的性能的比较结果。Meta-Transformer-B16F 在成人人口普查方面的准确率略低于其他方法,但在准确性和 F1 分数方面表现优于 Bank 营销数据集上的所有其他方法。这表明 MetaTransformer 也有利于表格数据理解,尤其是在银行营销等复杂数据集上。
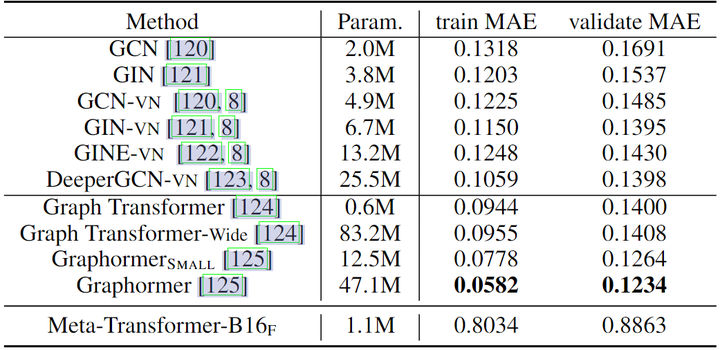
图和 IMU 数据理解任务实验结果
如下图14所示为图和 IMU 数据理解任务实验结果,作者将 Meta-Transformer-B16F 与各种图神经网络模型进行比较,用于 PCQM4M-LSC 数据集上的图数据理解。在所有方法中,Graphormer 表现出最佳性能,训练和验证 MAE 分数分别为 0.0582 和 0.123。相比之下,Meta-Transformer-B16F 提供了 0.8034 和 0.8863 的训练和验证 MAE 分数,揭示了当前 Meta-Transformer 架构在结构数据学习方面的能力有限。
参考
^VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts ^UNIFYING ARCHITECTURES, TASKS, AND MODALITIES THROUGH A SIMPLE SEQUENCE-TO-SEQUENCE LEARNING FRAMEWORK ^Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks ^BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ^RoBERTa: A Robustly Optimized BERT Pretraining Approach ^Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation ^wav2vec: Unsupervised Pre-training for Speech Recognition ^AST: Audio Spectrogram Transformer
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢