
Datawhale分享
最新:AI芯片,编辑:量子位
英伟达老黄,带着新一代GPU芯片H200再次炸场。
官网毫不客气就直说了,“世界最强GPU,专为AI和超算打造”。

听说所有AI公司都抱怨内存不够?
这回直接141GB大内存,与H100的80GB相比直接提升76%。
作为首款搭载HBM3e内存的GPU,内存带宽也从3.35TB/s提升至4.8TB/s,提升43%。

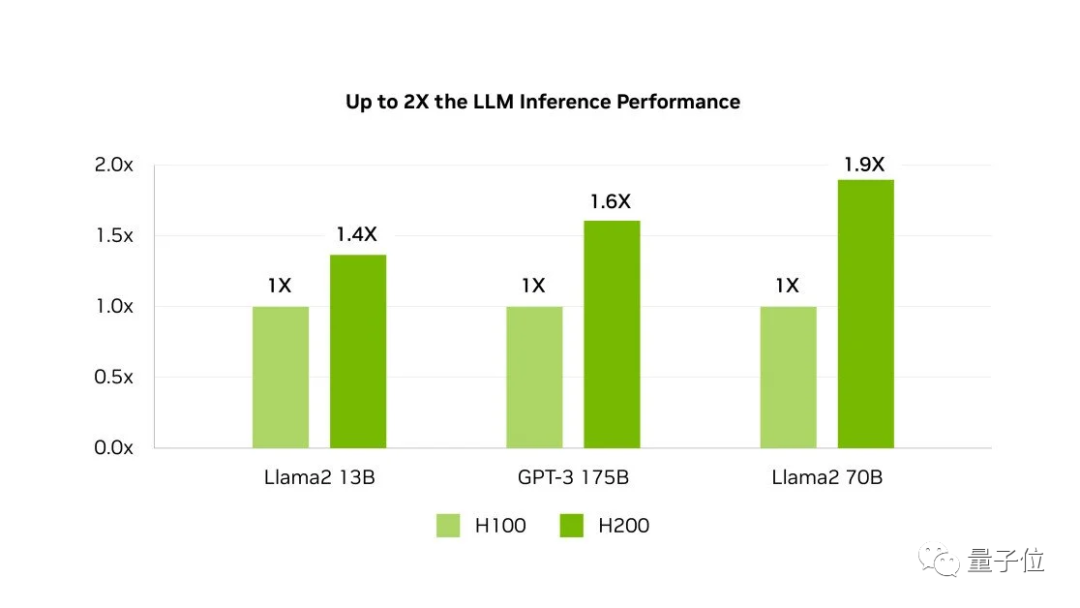
对于AI来说意味着什么?来看测试数据。
在HBM3e加持下,H200让Llama-70B推理性能几乎翻倍,运行GPT3-175B也能提高60%。
对AI公司来说还有一个好消息:
H200与H100完全兼容,意味着将H200添加到已有系统中不需要做任何调整。
最强AI芯片只能当半年
除内存大升级之外,H200与同属Hopper架构的H100相比其他方面基本一致。
台积电4nm工艺,800亿晶体管,NVLink 4每秒900GB的高速互联,都被完整继承下来。
甚至峰值算力也保持不变,数据一眼看过去,还是熟悉的FP64 Vector 33.5TFlops、FP64 Tensor 66.9TFlops。
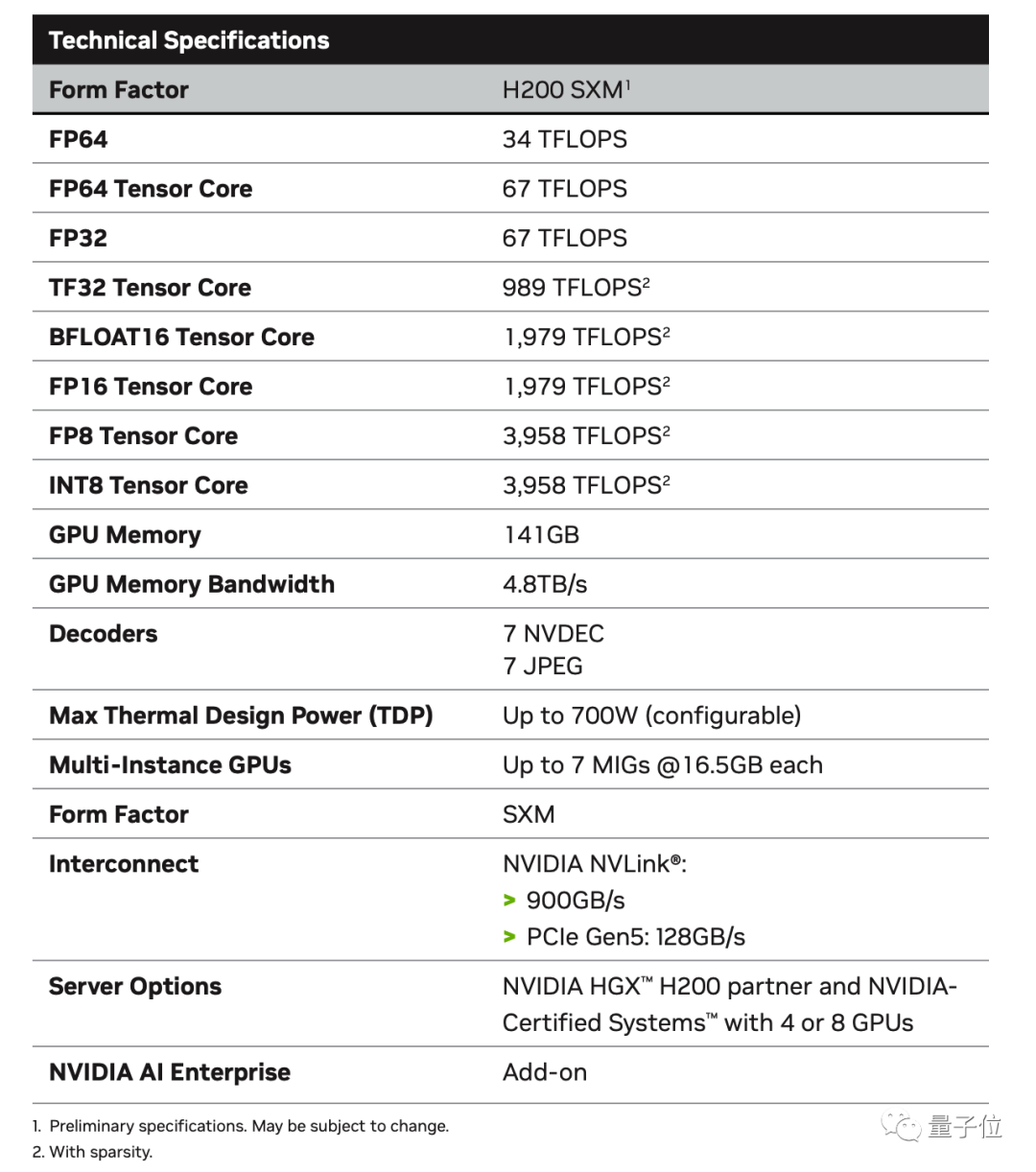
对于内存为何是有零有整的141GB,AnandTech分析HBM3e内存本身的物理容量为144GB,由6个24GB的堆栈组成。
出于量产原因,英伟达保留了一小部分作为冗余,以提高良品率。
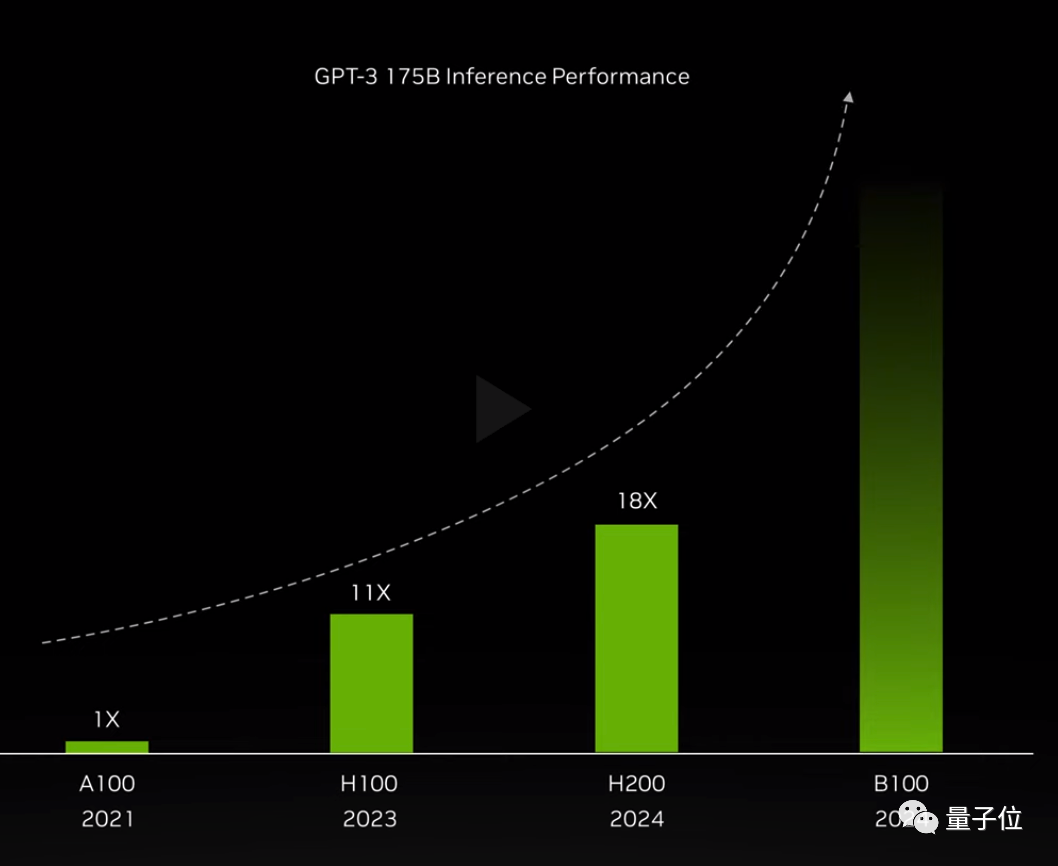
仅靠升级内存,与2020年发布的A100相比,H200就在GPT-3 175B的推理上加速足足18倍。
H200预计在2024年第2季度上市,但最强AI芯片的名号H200只能拥有半年。
同样在2024年的第4季度,基于下一代Blackwell架构的B100也将问世,具体性能还未知,图表暗示了会是指数级增长。
多家超算中心将部署GH200超算节点
除了H200芯片本身,英伟达此次还发布了由其组成的一系列集群产品。
首先是HGX H200平台,它是将8块H200搭载到HGX载板上,总显存达到了1.1TB,8位浮点运算速度超过32P(10^15) FLOPS,与H100数据一致。
HGX使用了英伟达的NVLink和NVSwitch高速互联技术,可以以最高性能运行各种应用负载,包括175B大模型的训练和推理。
HGX板的独立性质使其能够插入合适的主机系统,从而允许使用者定制其高端服务器的非GPU部分。

接下来是Quad GH200超算节点——它由4个GH200组成,而GH200是H200与Grace CPU组合而成的。

Quad GH200节点将提供288 Arm CPU内核和总计2.3TB的高速内存。
通过大量超算节点的组合,H200最终将构成庞大的超级计算机,一些超级计算中心已经宣布正在向其超算设备中集成GH200系统。
据英伟达官宣,德国尤利希超级计算中心将在Jupiter超级计算机使用GH200超级芯片,包含的GH200节点数量达到了24000块,功率为18.2兆瓦,相当于每小时消耗18000多度电。
该系统计划于2024年安装,一旦上线,Jupiter将成为迄今为止宣布的最大的基于Hopper的超级计算机。
Jupiter大约将拥有93(10^18) FLOPS的AI算力、1E FLOPS的FP64运算速率、1.2PB每秒的带宽,以及10.9PB的LPDDR5X和另外2.2PB的HBM3内存。

除了Jupiter,日本先进高性能计算联合中心、德克萨斯高级计算中心、伊利诺伊大学香槟分校国家超级计算应用中心等超算中心也纷纷宣布将使用GH200对其超算设备进行更新升级。
那么,AI从业者都有哪些尝鲜途径可以体验到GH200呢?
上线之后,GH200将可以通过Lambda、Vultr等特定云服务提供商进行抢先体验,Oracle和CoreWeave也宣布了明年提供GH200实例的计划,亚马逊、谷歌云、微软Azure同样也将成为首批部署GH200实例的云服务提供商。
英伟达自身,也会通过其NVIDIA LaunchPad平台提供对GH200的访问。
硬件制造商方面,华硕、技嘉等厂商计划将于今年年底开始销售搭载GH200的服务器设备。
参考链接:
[1]https://www.youtube.com/watch?v=6g0v3tMK2LU
[2]https://www.nvidia.com/en-gb/data-center/h200/
[3]https://www.anandtech.com/show/21136/nvidia-at-sc23-h200-accelerator-with-hbm3e-and-jupiter-supercomputer-for-2024

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢