
编译 | 曾全晨
审稿 | 王建民
今天为大家介绍的是来自Shuigeng Zhou团队的一篇论文。图神经网络(Graph Neural Networks,GNNs)是一种被广泛用于处理图结构数据的方法,在节点分类、链接预测和网络推荐等多种应用中表现出很有前途的性能。然而,现有的方法主要集中在处理相邻节点的加权汇总时,通常是通过关注节点之间的关系来进行的,比如使用两个节点的向量点积。这种方法可能导致在信息传播过程中传播有冲突的噪音。为了解决这个问题,作者提出了一种称为“通用信息传播算法(General Information Propagation Algorithm,GIPA)”的方法,它在信息传播中更细致地融合了信息。该方法在Open Graph Benchmark proteins(OGBNproteins)数据集和阿里巴巴集团的Alipay数据集上对GIPA的性能进行了评估。实验结果显示,GIPA在预测准确性方面表现优异,例如,GIPA的平均ROC-AUC值为0.8917,比Stanford OGBN-proteins排行榜上列出的所有现有方法都要好(截止2023年10月1日的排名详情见图1)。

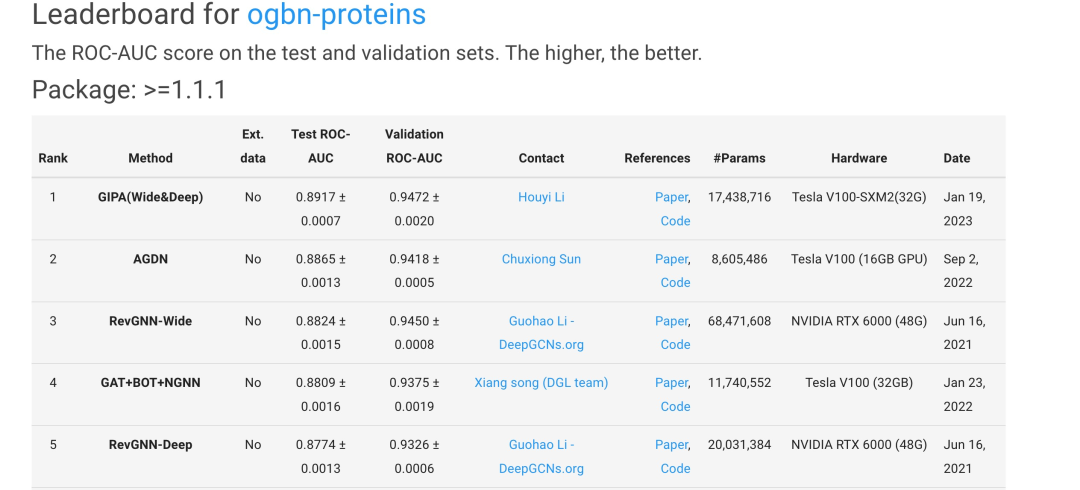
图 1
图神经网络(Graph Neural Networks,GNNs)利用深度神经网络来从相邻节点中聚合特征信息,从而有潜力获得更好的聚合特征。GNNs可以支持归纳学习,并在预测过程中推断未见节点的类标签。然而,GNN面临两个挑战:目标节点的哪些相邻节点参与消息传递?以及每个相邻节点对聚合特征的贡献有多大?对于前一个问题,研究人员提出了针对大型密集或幂律图的邻居采样方法。对于后一个问题,使用邻居重要性估计,以在特征传播过程中为不同的相邻节点附加不同的权重。重要性采样和注意力机制是两种常见的技术。重要性采样是邻居采样的一种特殊情况,其中相邻节点的重要性权重来自节点上的分布。这个分布可以从标准化拉普拉斯矩阵中导出,或者与GNN一起联合学习,在每一步中,从相邻节点中采样一个子集,并使用重要性权重进行聚合。与重要性采样类似,注意力机制也为相邻节点附加重要性权重。然而,注意力与重要性采样不同。注意力表示为神经网络,并始终作为GNN模型的一部分进行学习。相比之下,重要性采样算法使用无可训练参数的统计模型。现有的注意力机制只考虑节点之间的相关性,忽略了传递中的噪音信息抑制以及边缘特征的信息。在现实世界的应用中,只有部分用户授权系统收集他们的个人资料。模型无法学习已知用户和未知用户之间的节点级相关性。因此,现有模型将传播噪音信息,导致不准确的节点表示。
为了解决上述问题,作者提出了一种新的图神经网络注意力模型,即“通用信息传播算法(General Information Propagation Algorithm,GIPA)”。作者设计了一个按位相关性模块和一个特征相关性模块。具体来说,作者认为密集向量的每个维度代表节点的一个特征。因此,按位相关性模块在密集向量进行滤波。此外,作者将节点的每个属性特征表示为one-hot向量。特征相关性模块通过输出相似维度和属性特征的注意权重来执行特征选择。值得一提的是,为了使模型能够提取更好的注意力权重,作者还将度量节点之间相关性的边特征融入在注意力计算中。最后,GIPA将稀疏特征和密集特征分别输入到深度神经网络以进行特定任务的学习。
模型部分
图神经网络考虑了一个带属性的图 G = (V, E),其中 V 是节点集合,E 是边集合。GNNs使用以下相同的模型框架:
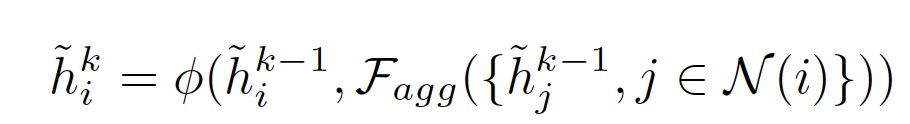
F_agg代表信息聚合函数,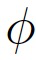 代表更新函数,h代表节点特征。GNN旨在通过考虑节点的邻居和它们之间的关系,来不断更新每个节点的表征。这样,节点的特征会逐渐包含来自整个图的信息,从而使节点能够更好地理解其在图中的上下文和角色。
代表更新函数,h代表节点特征。GNN旨在通过考虑节点的邻居和它们之间的关系,来不断更新每个节点的表征。这样,节点的特征会逐渐包含来自整个图的信息,从而使节点能够更好地理解其在图中的上下文和角色。
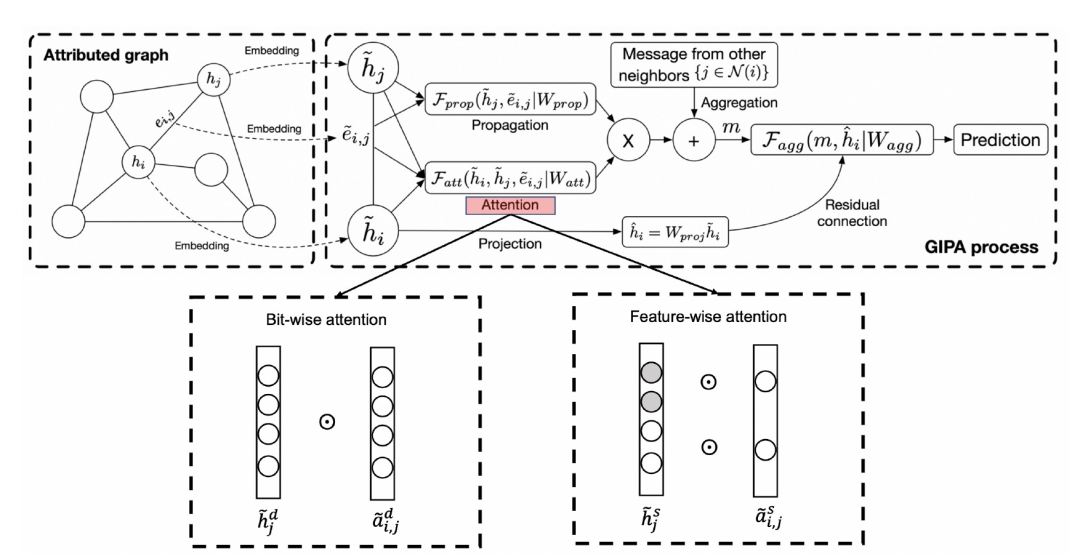
图 2
GIPA的基本架构如图2所示,它以一种更通用的方式提取节点特征和边特征。以特征为h_i的节点i为例子,模型的目标是基于节点自身的特征,节点邻居的特征以及边特征e来学习更好的节点特征。GIPA的工作流程包括三个主要模块:注意力、传播和聚合。GIPA适用于以下情况:在GNN中,每个节点不是由文本或图像组成,而代表对象,例如用户、产品和蛋白质,它们的特征由类别特征和统计特征组成。例如,ogbn-proteins数据集中的类别特征表示蛋白质来自哪个物种。而Alipay数据集中的统计特征类似于用户一年内的总消费额。
对于密集嵌入(dense embedding),每个整数可以表示一个类别,每个浮点数可以表示一个统计值,因此,一个一维嵌入可以表示一个特征。然而,稀疏嵌入(sparse embedding)对于一个特征需要更多维度,对于每个类别特征,需要进行独热编码(one-hot encoding)。例如,某个“类别特征”有K个可能的类别,需要一个K+1维向量来表示该特征。而每个“统计特征”被划分为K个类别(使用等频或等宽切割方法),然后进行K+1维的独热编码。因此,密集嵌入和稀疏嵌入的连接分别成为深度部分和宽度部分的模型输入。
不同于现有的自注意力(self-attention)或缩放点积注意力(scaled dot-product attention)等注意力机制,作者使用多层感知器(MLP)来实现按位(bit-wise)注意力机制和特征级别(feature-wise)注意力机制。GIPA的按位和特征级别注意力过程可以表述如下:
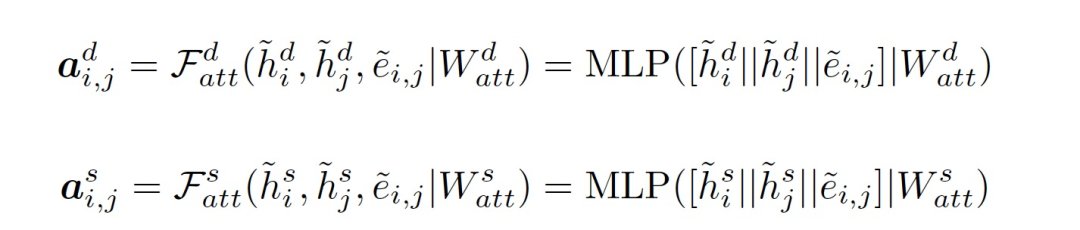
GIPA在传播过程中同时融合了节点嵌入和边嵌入:
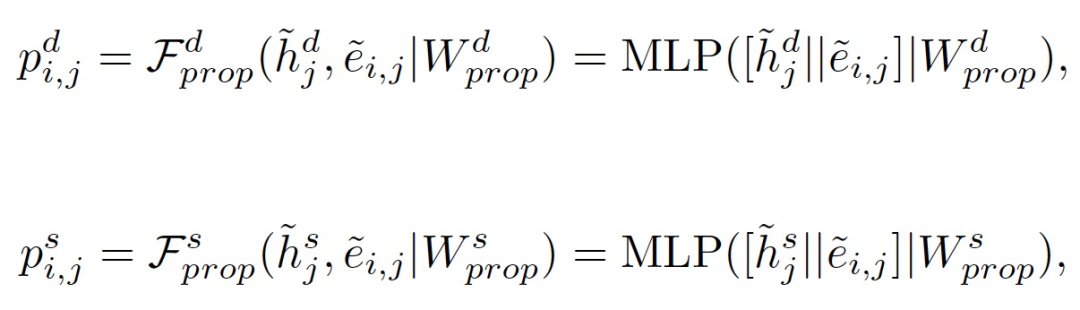
通过按位和特征级别的乘法将注意力和传播的结果结合起来,GIPA获取了节点i从邻居节点传递来的信息:
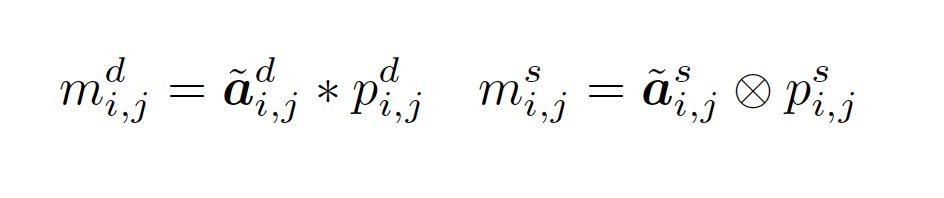
对于每个节点 i,GIPA会重复上述过程,从它的邻居节点那里获取消息:
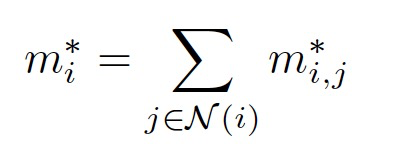
最后信息融合:
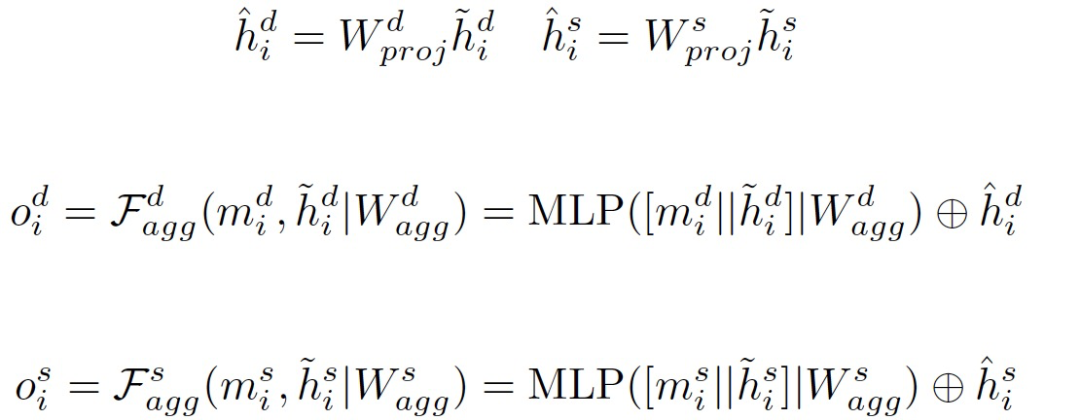
实验部分
在实验中,作者选择了两个具有边属性的数据集:来自OGB的ogbn-proteins数据集和Alipay数据集。ogbn-proteins数据集是一个无向带权图,包含132,534个节点,属于8个不同的物种,具有79,122,504条边,并带有8维特征。任务是一个多标签二分类问题,有112个类别代表不同的蛋白质功能。Alipay数据集是一个带有边属性的图,包含14亿个节点,带有575个特征,以及41.4亿条边,带有57个特征。任务是一个多标签二分类问题。值得注意的是,由于在支付宝数据集上的训练成本较高,作者只对工业数据集中的Fatt和Fprop的输入特征进行了消融实验,如表格1所示。

表 1
表格2显示了ogbn-proteins测试集和验证集的平均ROC-AUC值以及标准差。基线方法的结果来自ogbn-proteins排行榜。GIPA在排行榜中超越了所有以前的方法,首次达到了平均ROC-AUC值高于0.89。仅使用3层的GIPA在ogbn-proteins数据集上达到了最先进的性能。这个结果显示了作者提出的按位和特征级别相关性模块的有效性,它们可以利用边缘特征通过精细的信息融合和噪音抑制来提高性能。
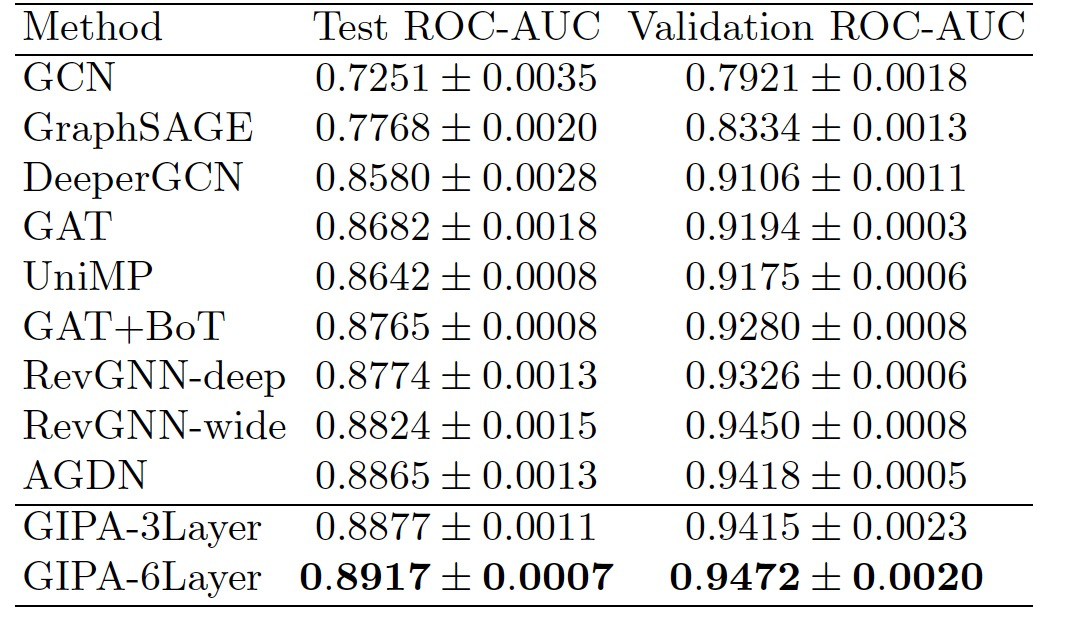
表 2

表 3
为了进一步研究的GIPA中每个组件的影响,作者在ogbn-proteins数据集上进行了消融研究。如表格3所示,与没有按位模块和没有特征模块的GIPA相比,这些组件的组合(即GIPA)产生了最佳性能,这表明了按位和特征级别相关性模块的必要性。在ogbn-proteins数据集上,每个epoch的平均训练时间分别为8.2秒(GIPA)、5.9秒(3层GIPA)和4.9秒(AGDN)。在整个ogbn-proteins图上的平均推理时间分别为11.1秒(GIPA)、9.3秒(3层GIPA)和10.7秒(AGDN)。与AGDN相比,GIPA在训练速度上较慢,但在推理速度上具有优势。
结论
作者提出了GIPA,这是一种用于学习图数据的全新图注意力网络架构。GIPA包括一个按位相关性模块和一个特征相关性模块,实现精细的信息传播和噪音过滤。在ogbn-proteins数据集上的性能评估表明,作者的方法优于目前排行榜上列出的最先进方法,并且已经在规模庞大的工业数据集上进行了测试。
参考资料
Li, H., Chen, Z., Li, Z., Zheng, Q., Zhang, P., Zhou, S. (2023). GIPA: A General Information Propagation Algorithm for Graph Learning. In: Wang, X., et al. Database Systems for Advanced Applications. DASFAA 2023. Lecture Notes in Computer Science, vol 13946. Springer, Cham.
https://doi.org/10.1007/978-3-031-30678-5_34
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢