
点击下方卡片,关注「集智书童」公众号

自动驾驶技术的发展依赖于感知、决策和控制系统的高效集成。传统的数据驱动方法和基于规则的方法在处理复杂驾驶环境和理解其他道路用户的意图时受到限制。这是实现安全和可靠自动驾驶所必需的重要瓶颈,特别是在发展常识推理和细致场景理解方面。
视觉语言模型的出现代表了实现完全自主车辆驾驶的新前沿。本报告对最新最先进的状态与技术进行了详尽的评估,并对GPT-4V(ision)进行了介绍,以及其在自动驾驶场景中的应用。作者探索了模型在理解和推理驾驶场景、做出决策并最终在驾驶者的身份下行动的能力。
作者的全面测试涵盖了从基本场景识别到复杂因果推理和实时决策的各种情况。作者的研究结果表明,GPT-4V在场景理解和因果推理方面,相较于现有的自动驾驶系统,表现出了优越的性能。
它展示了解决非分布式场景、识别意图和做出明智决策在真实驾驶环境中的潜力。然而,仍然存在挑战,特别是在方向识别、交通信号灯识别、视觉地面真实感和空间推理任务中。这些限制强调了需要进一步研究和开发的重要性。
该项目现在已经在GitHub上公开,有兴趣的各方可以访问和使用:https://github.com/PJLab-ADG/GPT4V-AD-Exploration
自动驾驶车辆的完全自主的追求一直以来都受到了依赖感知、决策和规划控制系统的管道限制。无论是基于数据驱动的算法还是基于规则的方法,在许多关键领域都存在不足。
具体来说,它们在准确感知开放词汇对象和解释周围交通参与者行为意图方面存在弱点。这是因为传统方法只能描述有限获取的数据中的抽象特征,或者根据预定的规则来解决问题,而缺乏处理罕见但重要的特殊情况的“常识”,并且无法从数据中概括驾驶相关的知识,以实现对复杂场景的深入理解和有效的因果推理。
大型语言模型的出现,例如 GPT-3.5,GLM,Llama,等等,为作者解决这些问题带来了一线希望。这些语言模型配备了初步的常识推理形式,因此它们在理解复杂的驾驶场景方面有着巨大的潜力。
然而,它们在自动驾驶中的应用主要限制在决策和规划阶段。这一限制是由于它们固有的无法处理和理解视觉数据,这对于准确感知驾驶环境并安全驾驶车辆至关重要。
GPT-4V是一种最近发展的尖端视觉语言模型(VLM),为研究和开发开辟了新的视野。与先前的 GPT-4相比,GPT-4V 在图像理解方面拥有强大的能力,这是实现自动驾驶技术感知差距的重要一步。这一新发现的力量提出了一个问题:GPT-4V 能否成为提高自动驾驶场景理解和因果推理的基石?
在本文中,作者旨在通过全面评估 GPT-4V 的能力来回答这个问题。作者的研究深入挖掘了模型在自动驾驶领域内对场景理解和因果推理的复杂方面所展现的性能。通过全面的测试和深入的分析,作者明确了 GPT-4V 的能力和限制,预计它将为其未来的自动驾驶领域内应用研究提供有价值的支撑。
Figure 1:从一个显示从传统自动驾驶管道到将视觉语言模型(如 GPT-4V)进行整合的插图。这张图片由 DALL-E 3. 生成。

作者已经逐步测试了 GPT-4V 的能力,从场景理解到推理,并最终测试了它在真实驾驶场景中的连续判断和决策能力。作者在大自动驾驶领域对 GPT-4V 的探索主要集中在以下几个方面:
场景理解:这项测试旨在评估 GPT-4V 的基本识别能力。它涉及在行驶过程中识别天气和照明条件,识别不同国家的交通信号灯和标志,评估其他交通参与者照片中的位置和行动,以及探索不同视角的模拟图像和点云图像。此外,作者还出于好奇心探索了不同视角的模拟图像和点云图像。
推理:在这个测试阶段,作者深入评估了 GPT-4V 在自动驾驶环境下的因果推理能力。这项评估涵盖了几个关键方面。首先,作者仔细检查它在处理复杂拐角案例时的性能,这些案例常常挑战数据驱动的感知系统。其次,作者评估它在提供环绕视角方面的能力,这也是自动驾驶应用程序中至关重要的一个特征。
由于 GPT-4V 无法直接处理视频数据,作者利用串联的时间序列图像作为输入来衡量它的时间相关性能力。此外,作者还进行了一些测试来验证它将实际场景与导航图像关联的能力,进一步检查它对自动驾驶场景的整体理解。
模拟驾驶员的角色:为了充分利用 GPT-4V 的潜力,作者让它扮演了一个有经验的驾驶员的角色,让它根据环境在真实驾驶情况下做出决策。作者的方法包括以恒定帧率采样驾驶视频,并逐帧将其输入到 GPT-4V 中。
为了帮助它的决策,作者提供了关键的车辆速度和其他相关信息,并针对每个视频传达了驾驶目标。作者挑战 GPT-4V 产生所需的动作并提供其选择的解释,从而推动了在现实世界驾驶场景中能力的边界。
综上,作者为未来的 GPT-4V 自动驾驶领域研究提供了初步的洞察,为激发未来的研究提供了基础。在上述信息的基础上,作者采用一种独特而引人入胜的图像-文本对齐方法,有系统地结构和展示了作者的调查结果。虽然这种方法可能相对不太严格,但它提供了全面分析的机会。
这篇文章关注自动驾驶领域的测试,采用了一个精选的图像和视频集合,代表各种驾驶场景。测试样本来自不同的来源,包括开源数据集如 nuScenes,Waymo Open dataset,Berkeley Deep Drive-X (eXplanation) Dataset (BDD-X) ,D-city,Car Crash Dataset (CCD),TSD,CODA,ADD,以及 V2X 数据集如 DAIR-V2X 和 CitySim。
此外,一些样本来自 CARLA 模拟环境,而其他样本则是从互联网上获取的。值得一提的是,用于测试的图像数据可能包括截至 2023 年 4 月的图像,这些图像可能会与 GPT-4V 模型的训练数据重叠,而本文中使用的文本查询则完全是新生成的。
本文中所有详细实验均于 2023 年 11 月 5 日之前在使用了的 GPT-4V(version from 2022 年 9 月 25 日) 上进行,使用了在 OpenAI DevDay 之后更新的 GPT-4V(version from November 6th)。作者承认,与作者的测试结果相比,最新版本的 GPT-4V(自 2023 年 11 月 6 日 OpenAI DevDay 之后发布)在处理相同图像时可能会产生不同的响应。
这个测试旨在评估 GPT-4V 的基本场景识别能力。它涉及在行驶过程中识别天气和照明条件,识别不同国家的交通信号灯和标志,评估其他交通参与者照片中的位置和行动,以及探索不同视角的模拟图像和点云图像。此外,作者还进行了模拟图像和点云图像的探索以满足好奇心。
为了实现安全和有效的自动驾驶,一个基本前提是充分理解当前的场景。复杂的交通场景涵盖了许多不同的驾驶条件,每个场景都拥有着各种不同的交通参与者。准确地识别和理解这些元素是自动驾驶车辆做出明智和合适驾驶决策的基本能力。
在这一部分,作者提出了一系列测试,旨在评估 GPT-4V 理解交通场景的能力。作者主要关注两个方面:模型对周围环境的理解以及区分各种交通参与者行为和状态的能力。通过这些评估,作者旨在阐明 GPT-4V 解释动态交通环境的能力。
在这个测试阶段,作者将对 GPT-4V 的环境理解能力进行评估。作者将通过模拟不同的交通场景来检查 GPT-4V 是否能够理解场景中的交通情况,以及是否能够识别并理解场景中的交通标志和信号。此外,作者还将通过模拟不同的天气条件和道路状况来评估 GPT-4V 的环境理解能力。
作者将使用各种类型的摄像头图像和雷达数据作为输入,以评估 GPT-4V 在不同场景下的环境理解能力。此外,作者还将通过模拟不同的交通流量和道路条件来评估 GPT-4V 的环境理解能力。通过这些评估,作者希望揭示 GPT-4V 在理解动态交通环境方面的能力。
在评估 GPT-4V 理解其周围环境的能力时,作者进行了一系列测试,包括以下关键方面:模型区分昼夜的能力、对主导天气状况的理解、以及识别和解释交通信号灯和标志的能力。这些要素对于塑造自动驾驶系统的决策过程至关重要。
例如,显然在夜间或恶劣的天气条件下驾驶需要更加谨慎,而在白天或良好的天气条件下则可以采取更加随意的驾驶策略。
此外,正确解释交通信号灯和道路标志对于自动驾驶系统的有效性至关重要。在本部分中,作者主要使用车辆的前视图像作为视觉输入。所使用的视觉数据来自 nuScenes, D-city, BDD-X 和 TSDD。
接下来是白天和夜间的评估。作者使用白天和夜晚的图像来评估 GPT-4V 理解时间差异的能力。作者向模型提供这些图像,并指示模型描述这些图像中呈现的交通场景,结果在图 2 中展示。结果表明,当呈现白天图像时,GPT-4V 成功地识别了它们为多车道,这意味着 GPT-4V 能够正确理解时间差异。

此外,模型在识别道路上的人行横道方面也非常出色。当面临类似的夜间场景时,GPT-4V 的表现甚至更好。它不仅能识别出路灯的时间为“黄昏或傍晚”,还能检测到远处一辆车上有尾灯,并推断出“它要么是静止的,要么是在远离你的方向上移动”。
天气理解。 天气是影响驾驶行为的一个重要环境因素。作者从 nuScenes 数据集中选择了在相同交叉口拍摄的,在各种天气条件下捕捉的 4 张照片。作者将这些图像呈现给 GPT-4V,并要求模型识别这些图像中的天气条件。结果在图 3 中展示。

结果表明,GPT-4V 在识别每张图像中的天气条件方面表现出显著的准确性,即阴天、晴天、多云和雨天。此外,它为这些结论提供了合理的解释,例如,太阳阴影的存在或街道的潮湿等。
交通信号灯理解。 正确识别交通信号灯对于自动驾驶系统的功能至关重要。错误地识别或错过交通信号灯不仅会导致违反交通规则,而且还会带来严重的交通事故风险。不幸的是,在本测试中,GPT-4V 的表现不够理想,如图 4 和图 5 所示。

在图 4 中,GPT-4V 展示了在夜间条件下区分黄灯和红灯的能力,特别是区分交通信号灯的能力。然而,在图 5 中,当 GPT-4V 面临一个带有倒计时的小型交通信号灯时,它错误地将倒数计时器识别为红灯,并错过了真正的 2 秒红灯倒计时。
模型只有在交通信号灯占据图像的大部分面积时才能提供正确的响应,而在后续的测试中,GPT-4V 出现了误识别交通信号灯的情况,这在成熟的自动驾驶系统中是不可接受的。
交通标志理解。 交通标志包含了各种规则和指令,驾驶员需要遵守。自动驾驶系统可以通过识别交通标志来理解和遵守这些规则,从而减少交通事故的风险并提高驾驶安全性。
因此,作者选择了来自新加坡和中国代表性的图像进行测试。如图 6 中的左侧样本所示,模型可以识别大部分道路标志,包括近处的“SLOW”和远处的“4.5m”,但错误地识别了“Speed Bump”标志。

从右样本的三个标志都被正确识别。这表明 GPT-4V 具有出色地识别交通标志的能力,然而,仍有进一步提高的空间。
在这个部分,作者将测试 GPT-4V 识别和理解不同类型的交通参与者的能力。这些参与者可能包括行人、自行车手、摩托车手和其他车辆的驾驶员。作者将使用图像和视频作为输入来评估 GPT-4V 在这些场景下的表现。例如,作者可以使用行人、自行车手和摩托车手在各种交通场景下的图像来测试 GPT-4V 的能力。作者可以让 GPT-4V 识别这些图像中的参与者,并解释他们的行为。作者还可以使用 GPT-4V 来理解这些场景中的交通规则,例如行人和自行车手是否可以在同一车道行驶,或者摩托车手是否需要遵守相同的交通规则。
通过这些测试,作者可以评估 GPT-4V 在理解不同类型的交通参与者和场景下的能力,并确定其在自动驾驶系统中的潜在用途。准确地理解交通参与者的状态和行为是驾驶的基础。现有的自动驾驶系统通常使用各种摄像头和传感器来感知交通参与者,以便获取更多关于他们的更全面信息。
在这一部分,作者通过各种传感器输入来评估 GPT-4V 理解交通参与者行为的能力,包括 2D 图像、3D 点云可视化图像以及从 V2X 设备和自动驾驶模拟软件中获取的图像。在这里使用的视觉数据来自 nuScenes, ADD, Waymo, DAIR-V2X, CitySim 和 Carla 模拟。
前置相机:为了测试模型的基本识别能力,包括交通参与者识别和车辆计数,作者输入了一系列行驶场景的前视图,并获得了 GPT-4V 的输出结果。如图 7 所示,从左侧的图 7 中可以看出,模型可以完全且准确地描述驾驶场景:它能够识别行人、交通标志、交通信号灯状态以及周围环境。

图 7 的右侧表明模型可以识别车辆类型和车尾灯,并可以猜测其打开车尾灯的意图。然而,模型在无关位置输出了一些错误的说法,例如认为前面的车辆安装了后视摄像头。

图 8 测试了 GPT-4V 的计数能力。利用车辆的前视图白天和夜间的快照,模型可以精确地计算白天拍摄中可识别的车辆数量和状态。然而,在夜间条件下,尽管 GPT-4V 准确地列出了可识别的车辆,但每个车辆的详细描述有时会缺乏准确性。
鱼眼摄像头照片 :鱼眼摄像头是自动驾驶车辆系统中普遍使用的成像设备,也被用来评估 GPT-4V 的感知能力。通过鱼眼镜头捕捉的图像结果记录在图 9 中。
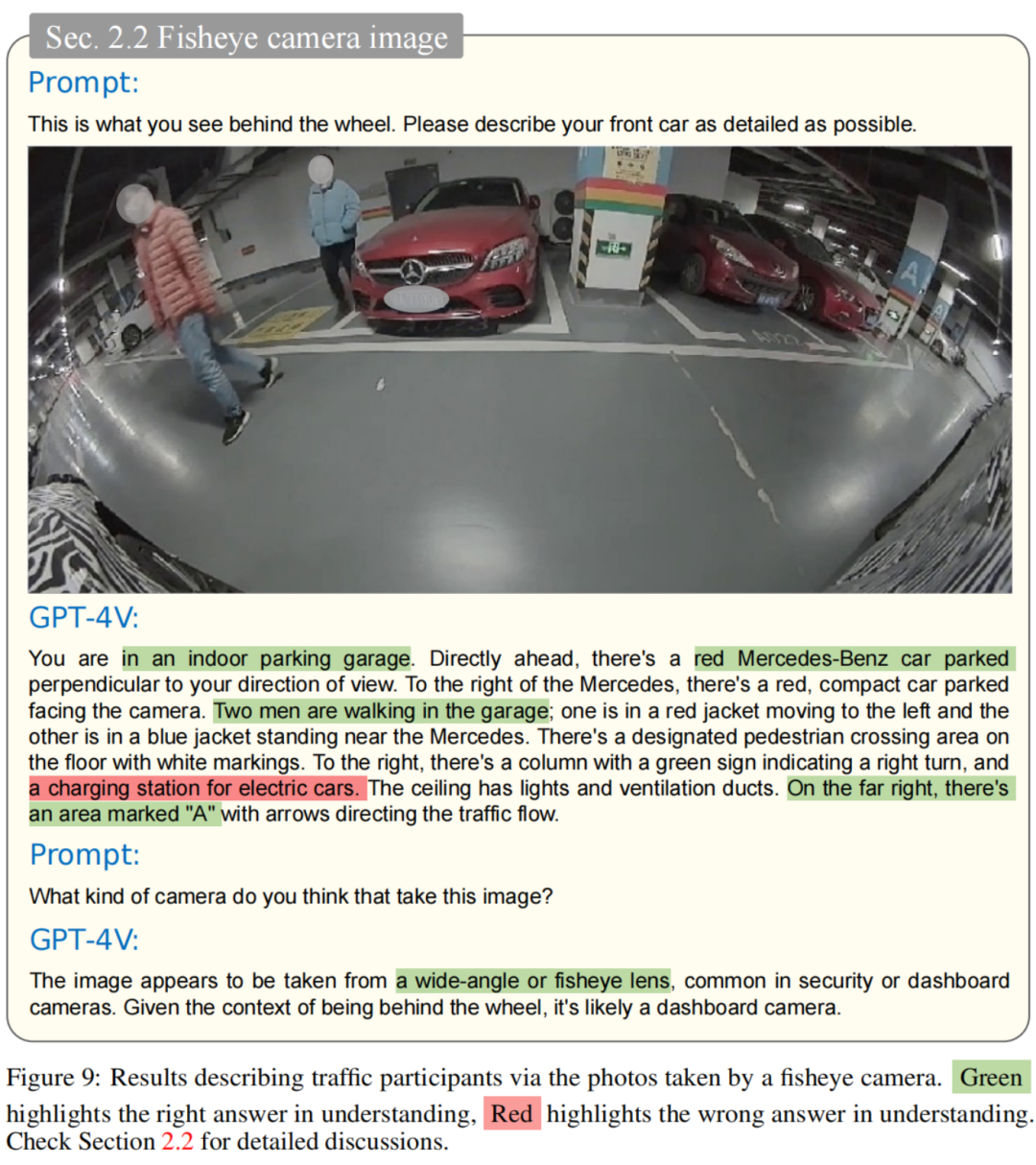
GPT-4V 表现出对鱼眼失真现象具有强大的容忍度,并显示出对室内停车环境的出色理解。它能够可靠地识别出停放的车辆和附近行人的存在,尽管有些错误的描述,如一个不存在的充电站。此外,当被询问照片的潜在设备时,GPT-4V 准确地识别出这是鱼眼摄像机的产物。
点云可视化图像。出于好奇心,作者捕捉了两张 64 线的激光雷达点云图像,一张是从鸟瞰视角获取的,另一张是从前视视角获取的。虽然将点云图像压缩到二维图像上会不可避免地丢失三维几何信息,但仍然可以识别和分类出几个独特的特征。

测试结果如图 10 所示。随后,作者将这两种图像输入到 GPT-4V 中,令作者惊讶的是,该模型展示了在它们内部识别某些道路和建筑模式的能力。由于模型以前很少见到这种类型的数据,因此它不可避免地认为从鸟瞰视角看到的圆形图案是一个环形交叉路口或中央广场。
此外,当任务是识别车辆时,模型在很大程度上成功地估计了场景中的车辆数量。作者也观察到在前视图中存在计数错误,这是由于一些车辆的轮廓不完整且难以辨认所导致的。通过这个测试,展示了模型处理非传统数据的强大能力。
V2X设备照片。 V2X 代表车辆与一切通信,它涵盖了各种技术,使车辆不仅可以互相通信,还可以与基础设施和其他各种实体通信。V2X 摄像头在捕获和处理这个互联生态系统中的视觉信息方面起着重要作用。

在图 11 中,作者展示了 GPT-4V 对于无人机视角照片和两个交叉口摄像头图像生成的响应。在所有三个实例中,GPT-4V 都表现出了可称赞的性能。在无人机视角下,GPT-4V 准确地识别了双向高速公路和照片中右侧的匝道。
并在交叉口 V2X 设备视角中,反應式識別出圖像中的混合車流,包括車、自行車手和行人,以及精確的交通燈識別。
在CARLA模拟器中拍摄的图像。GPT-4V 不仅能够识别这些图像来自于模拟软件,还能够展示出对虚拟车辆和行人之间的高水平意识。此外,在极少数情况下,模拟中的行人闯红灯,GPT-4V 在其响应中适当地承认了这种场景。

然而,值得注意的是,模型在识别模拟中的交通信号灯方面仍然存在一些困难,例如将红色灯光错误地识别为黄色。
推理是正确驾驶行为的重要特征。由于交通环境的动态和不可预测性,驾驶员经常遇到一系列意外事件。熟练的驾驶员在面对这样的意外情况时,需要根据经验和常识作出准确的判断和决策。在本节中,作者进行了一系列测试,以评估 GPT-4V 应对意外事件的能力和在动态环境中导航的能力。
特殊情况下,GPT-4V 表现出了很好的性能。例如,在模拟夜间场景下,模型能够准确地识别出交通信号灯的颜色,并正确地预测车辆的行驶方向。此外,在复杂的道路环境中,GPT-4V 也能够很好地识别出不同类型的交通标志,并正确地估计车辆的数量。然而,在某些特殊情况下,GPT-4V 的表现可能会受到影响。例如,当场景中出现了一些与车辆和行人行为不符的元素时,模型可能会产生错误的预测。此外,当场景中出现了一些不常见或异常的情况时,GPT-4V 可能会表现出一定的泛化不足。总的来说,GPT-4V 展示出了在常见交通场景下进行推理的出色性能,但在特殊和异常情况下,模型可能会表现出一些不足。因此,在将 GPT-4V 应用于实际驾驶任务之前,还需要进一步优化和调整模型,以使其能够更好地适应各种复杂的驾驶场景。
在自动驾驶的持续研究中,增强系统处理意外事件能力的方法通常是不断收集数据。然而,由于驾驶环境的动态、连续和随机性质,收集到的数据只能近似其边界,但永远无法完全涵盖它,也就是说,意外事件是不可避免的。人类驾驶员通常能够通过使用常识和随机应对这些未预料到的状况,安全地通过这些不可预见的情况。这突显了将数据驱动的方法与推理和常识原则相结合对于自动驾驶系统的重要性。在这里使用的视觉数据来自 CODA 和互联网。
在这一部分,作者已经精心挑选出一组感知拐角案例,来评估模型进行常识推理的能力。这些例子故意包括一些在典型分布之外的对象,通常会给传统的感知系统带来挑战,并在决策和规划过程中造成困难。现在,让作者来看看 GPT-4V 在解决这些问题时的表现。

在图 13 的左侧,GPT-4V 能够清晰地描述不常见车辆的外观、地面的交通锥和车辆旁边的员工。在识别出这些条件后,模型意识到 ego 车可以稍微向左移动,保持与右侧工作区域的安全距离,并谨慎地驾驶。
在右边的例子中,GPT-4V 熟练地识别出一个复杂的交通场景,包括橙色的施工车辆、人行道、交通信号灯和自行车手。当被询问其驾驶策略时,它表达了一个意图,即在保持与施工车辆安全距离的同时,在通过时进行平稳的加速,并谨慎地观察行人的存在。

在图 14 的左侧,GPT-4V 能够准确地识别出飞机在道路上紧急着陆,并且附近有相关部门正在处理这种情况。对于传统的感知算法来说,在特定训练之前,很难识别出这种情况。在这些条件下,模型知道它应该减速并打开危险警告灯,等待通过飞机的许可后,再继续进行常规驾驶。
在右边的例子中,GPT-4V 准确地识别出水泥搅拌车和前方红色的交通信号灯。它意识到在保持与前方车辆的安全距离的同时,直到红色的交通信号灯转变为绿色,它将按其旅程继续行驶。

在图 15 的左侧,GPT-4V 描述了一个场景,其中一名行人伴随着两只狗正在穿过人行横道,位于图像的中心右区域。值得注意的是,模型准确地计算了狗的数量。模型得出结论,车辆应该耐心等待行人及狗群通过后再继续行驶,尽管它仍然无法确定交通信号灯的状态。值得一提的是,这种情况并不是 GPT-4V 首次出现。
右边的图片描绘了一个夜间交通场景,被 GPT-4V 准确地识别。在这个实例中,模型巧妙地识别出了前方车辆的照明刹车灯,并注意到行人和自行车手的存在,他们正在耐心等待穿过马路。模型明智地推断出它应该保持静止,直到交通信号灯变成绿色,然后谨慎地开始旅程。
通过使用多视图摄像头,GPT-4V 可以捕获驾驶环境的全面视角。精确地解释这些摄像头之间的空间关系和图像内的重叠区域对于模型有效利用多视图摄像头系统的能力至关重要。在本节中,作者将评估 GPT-4V 在处理多视图图像方面的能力。本节中所有的数据均来自 nuScenes 数据集。

在图 16 中,作者选择了一系列周围的图像并按照正确的顺序输入到模型中。模型能够熟练地识别出图像中的各种元素,如建筑物、车辆、障碍物和停车。它可以从重叠的信息中推断出场景中有两辆汽车,一辆是白色的 SUV 车型,一辆是带有拖车的卡车。虽然模型的一般性能令人印象深刻,但一个微小的错误就是将人行横道错误地识别为了车辆。

在另一个实验中,如图 17 所示,作者同样使用一组组合的周围图像进行测试。虽然模型能够提供对场景的准确描述,但也出现了几次识别错误,特别是在车辆数量和形状方面。值得注意的是,模型产生了一些令人困惑的错觉,例如认为图片上有左转标志。作者推测这些问题可能源于模型的有限空间推理能力。

最后,在图 18 中,作者呈现了正确的正面视图并试图让 GPT-4V 识别和按顺序排列错序的周围图像。尽管模型进行了大量的分析和推理,看起来很合理,但它仍然输出了所有错误答案。这表明模型在将相邻图像之间的联系建立起来时遇到了挑战。作者承认这个任务具有复杂的关联性。
在这一部分,作者将评估 GPT-4V 在理解时间图像方面的能力。作者的方法涉及使用第一人称驾驶视频的多个序列。
从每个视频片段中,作者提取四个关键帧,用顺序号进行标记,并将它们组合成一个单一的图像进行输入。然后,作者让 GPT-4V 描述这个时间段内发生的事件,以及 ego 车辆所采取的行动及其背后的原因。这些示例来自 nuScenes, D-city 和 Carla 模拟。

Figure 19:一张从CARLA地图中的Town 10街道上拍摄的视频截图。GPT-4V清楚地解释了 ego 车辆在人行横道上有行人穿过马路时停车等待的原因,就在交通信号灯变成红色之前。
Figure 20:展示来自 NuScene 数据集的一段视频剪辑。在捕捉关键帧的过程中,作者将领先的大型 SUV 和行人分别标记为 "1" 和 "2"。GPT-4V 不仅准确地回答关于这些标签代表的对象的询问,而且还提供了一个全面的解释,描述了前 SUV 和行人之间的互动。这个互动包括行人穿越街道,而白色 SUV 礼让行人。

图 22 描述的视频序列中,由于下雨,出现了明显的镜头耀斑。然而,GPT-4V 仍然准确地识别了交通信号灯和前端车辆的后方灯。它还推断出在红灯变为绿灯后,前端车辆的语义信息。

然而,需要注意的是,GPT-4V 并不能总是准确地完全分析时间驾驶场景。如图 21 所示,这段视频捕捉到了车辆在超车时从左侧车道变到右侧车道。遗憾的是,GPT-4V 错误地将电动车的行动理解为车辆在车辆前面变道,错误地将车辆的行为理解为车辆减速让行。这再次证明了 GPT-4V 在时间视频背景下的空间推理存在局限性。此外,在图 22 中,GPT-4V 又一次错误地将绿灯识别为红灯。
Visual-Map Navigation,顾名思义,就是让 GPT-4V 能够理解和执行视觉-地图导航任务。具体来说,这个任务的目标是让 GPT-4V 能够理解并执行一系列视觉-地图导航指令,例如:“前方 100 米 直行”,“左转进入商场”等等。通过这些指令,GPT-4V 需要在地图上找到对应的视觉元素,并理解其空间关系,从而确定自己的位置和方向,最终到达目标点。
在实现视觉-地图导航任务的过程中,作者需要使用多种视觉输入,包括摄像头图像,LiDAR 点云,V2X 设备等等。这些输入会提供给 GPT-4V 丰富的视觉信息,帮助它理解和定位自己在地图上的位置。同时,作者还需要为 GPT-4V 设计合适的导航算法,例如 SLAM 算法,来帮助它处理视觉输入,并确定自己的位置和方向。
最后,作者需要在真实环境中测试 GPT-4V 的视觉-地图导航能力。作者可以使用真实世界中的摄像头图像,LiDAR 点云,V2X 设备等等,来模拟导航任务。同时,作者还需要设计一系列测试用例,来评估 GPT-4V 在不同场景下的表现,例如在复杂的城市环境中,在恶劣的天气条件下,在不同的时间等等。通过这些测试,作者可以发现 GPT-4V 的优势和劣势,并进一步优化它的视觉-地图导航能力。
在实际驾驶场景中,驾驶员通常会利用来自外部设备的辅助信息来增强他们的决策能力。例如,一个地图应用程序可以提供有关道路几何形状和路线引导的详细信息,使驾驶员能够做出更明智和合理的驾驶决策。
在这一部分,作者给 GPT-4V 配备了前视摄像头图像和相应的地图软件导航信息。这种设置使 GPT-4V 能够描述场景并做出明智的决策,就像人类驾驶员在类似情况下会做的那样。

如图 23 所示,GPT-4V 准确地使用前视摄像头和地图应用程序信息来确定其位置,然后执行正确的左转动作。通过使用前视摄像头,它对道路状况进行了合理的评估,并与地图应用程序提供的速度信息相结合,提供了适当的驾驶建议。

如图 24 所示,GPT-4V 能够在更复杂的场景中准确地定位自己。然而,在这个特定的情况下,它错误地决定进行左转。尽管如此,GPT-4V 仍能通过前视摄像头正确识别路边停放的车辆和商店的信息,并从地图软件中正确获取速度和距离信息。
自动驾驶算法的最终目标是重现人类驾驶员的决策能力。实现这一目标需要精确的识别、空间意识以及对各种交通元素的时空关系的深入理解。在本节中,作者将通过测试 GPT-4V 在五个不同的实际驾驶场景中的决策能力,来评估其在自主驾驶方面的全部潜力。这些场景涵盖了不同的交通条件、不同的时间段和多个驾驶任务。
在评估过程中,作者会提供 ego-vehicle 的速度和其他相关信息,并要求 GPT-4V 生成观察和驾驶动作。通过这些精心设计的评估,作者的目标是推动 GPT-4V 在现实场景中的能力边界,并揭示其作为未来自主交通领域的驾驶力量的潜力。
在停车场内驾驶时,请将车辆保持在停车位或停车标志内,并始终遵守交通规则,特别是关于行人通过的规则。此外,请确保在离开停车位时,车辆能够安全驶离,并始终与道路边缘保持安全距离。请注意,在某些情况下,自动驾驶车辆可能需要依靠人类驾驶员的决策来避免危险情况。
在这一部分,作者测试 GPT-4V 在封闭区域内的驾驶决策能力。所选场景是向右转以驶出停车场,需要通过一个安全检查。如图 25 所示,在第一帧中,GPT-4V 准确地识别出影响驾驶的关键元素,如行人和车辆灯光。然而,GPT-4V 对行人和远处车辆的状态存在歧义。

因此,它通过保持低速并做好随时停下来的准备,提供了保守的驾驶决策。在第二帧中,GPT-4V 检测到行人已经离开,但却错误地提到斑马线的信息。它仍然遵循谨慎的右转驾驶策略。
在第三帧中,GPT-4V 准确地识别出了如入口门岗、岗亭和围墙等元素,推断车辆即将抵达出口并准备停车接受安全检查。
在第四帧中,GPT-4V 准确地识别出安全检查点现在已经完全开放,因此作者可以安全地驶出停车场。此外,GPT-4V 还定位到出口附近的行人,并建议作者等待他们安全通过后再慢慢驶出。
从这个例子中,作者可以看到 GPT-4V 能够准确地识别出封闭区域内的关键元素,包括栅栏检查站和警卫亭,以及需要等待安全检查并注意行人和车辆驶出停车场的驾驶程序。然而,仍然可能发生一些误判,例如错误地提到斑马线。
在交通路口转弯时,请遵循交通信号灯的指示,并确保在确保安全的情况下进行转弯。此外,在路口转弯时,请确保注意到周围的行人和车辆,并提前开始转弯,以确保安全通过。
在这一部分,作者评估 GPT-4V 在交通路口的转弯能力。如图 26 所示,所选场景是一个交通流量较大的十字路口。在第一帧中,GPT-4V 观察到交通灯是绿色的,并推断出继续向左转的驾驶动作。在第二帧中,由于距离和感知领域的限制,GPT-4V 认为交通灯是看不见的,但观察到前车的刹车灯。

因此,它的驾驶策略是保持当前位置。在第三帧中,GPT-4V 错误地判断了交通信号灯的状态,认为转弯不被允许。在第四帧中,GPT-4V 仍然错误地判断了交通信号灯的状态。最终决定谨慎地执行左转,同时确保安全,避免与其他车辆和行人发生碰撞。
这个例子表明,在路口转弯时,GPT-4V 注意到了各种信息,如交通信号灯和其他车辆的尾灯。然而,GPT-4V 识别远处物体状态的能力较差(如远处交通信号灯),这可能影响其在路口的决策行为。
在高速公路匝道转弯时,请确保车辆能够看到前方道路的情况,并提前开始转弯。此外,在匝道转弯时,请确保车辆能够保持足够的速度,以便能够安全地转弯。此外,请确保车辆在匝道转弯时能够遵循交通规则,并避免与其他车辆发生碰撞。
请注意,匝道转弯可能需要依靠驾驶员的观察和判断来避免危险情况。因此,在匝道转弯时,请确保车辆能够平稳地行驶,并随时准备停车以避免碰撞。最后,请注意在匝道转弯时,请确保车辆能够安全地进入高速公路,并遵守高速公路的交通规则。

在这一部分,作者测试 GPT-4V 在高速公路区域驾驶的能力。如图 27 所示,作者选择了一个具有挑战性的场景,其中车辆需要在夜间执行高速公路匝道转弯。在第一帧中,GPT-4V 准确地识别出了箭头标志和分隔车道线,并从前方车辆的红色尾灯中推断出它正在减速。
因此,自动驾驶车辆应减速并遵循车道线。在第二帧中,尽管 GPT-4V 错误地识别了前面的车辆数量,但它却精确地定位了车道线和路标,表明向左转Figure 25: 自动驾驶车辆在停车场的驾驶能力的说明。
因此,GPT-4V 建议轻轻刹车并使用灯光向左指示其他司机。在第三帧中,由于夜间能见度有限,GPT-4V 只定位了黄色的车道分隔线。因此,它建议使用这些分隔线作为参考,在车道线内缓慢行驶。
在第四帧中,GPT-4V 准确地判断出自动驾驶车辆已经进入了主高速公路道路,并观察到右侧有潜在的并入车辆。因此,它决定调整高速公路驾驶的速度,并在合法范围内偶尔开启远光灯以扩大夜间可视范围。

如图 28 所示,从这个例子作者可以看出,在高速公路区域行驶时,GPT-4V 遵循路标并协助决策,基于周围车辆的状态。然而,它夜间识别物体和定位的局限性仍然存在。在高速公路上,车辆可能会遇到其他车辆并试图合并到车辆车道。在这种情况下,驾驶员需要仔细观察前方的车辆和道路状况,并谨慎地决定是否要并入车辆车道。如果决定并入车辆车道,驾驶员应该确保有足够的空间并避免碰撞。此外,驾驶员应该始终遵守交通规则,并确保在并入车辆车道时不会影响其他车辆的行驶。然而,它错误地检测到一条白色的实线,并错误地认为摩托车在同一车道上。最终给出的建议是注意主路上的摩托车,并根据需要调整速度或改变车道。

如图 29 所示,从这个例子作者可以看出,GPT-4V 通过观察车道变化来评估当前的合并进度,并提供合理的驾驶建议。然而,在夜间,它仍然可能错误地判断路标和车道。总的来说,GPT-4V 在车道合并方面倾向于采用保守的方法。如图 29 所示,作者测试了 GPT-4V 的 U 形转弯能力。作者选择了在夜间交通拥堵的交叉口上执行 U 形转弯的场景。当遇到如 U 形转弯等对道路结构有显著变化的场景时,GPT-4V 往往忽视时间空间上下文关系。然而,总体上提供的驾驶策略相当保守。
通过上述5个测试,作者可以观察到 GPT-4V 已经初步获得了决策能力,类似于人类驾驶员。它可以结合各种交通元素的状态来提供最终的驾驶策略。然而,它在夜间和复杂场景中的表现仍然存在局限性。此外,它容易受到周围环境和车辆行为的影响。尽管如此,GPT-4V 仍然可以提供相当保守的驾驶策略,以确保安全。然而,这些保守的策略可能会影响它在更复杂场景下的表现。因此,需要进一步改进和优化 GPT-4V 的驾驶策略,以使其能够更好地适应各种驾驶场景。
GPT-4V 在自主驾驶方面的能力如下:
能够在夜间和恶劣天气条件下行驶,具有出色的环境感知能力。 能够准确识别交通信号灯、车辆、行人等交通元素。 能够根据周围交通状况和安全因素,智能地调整速度和行驶轨迹。 能够利用导航软件和摄像头图像等信息,自主规划行驶路线。 能够在行驶过程中,对突发事件和紧急情况进行反应和应对。 能够在复杂的城市环境中,准确地完成 U 形转弯、并线等转向操作。 能够在夜间和恶劣天气条件下,安全地驶出高速公路匝道。 能够根据道路标志和导航信息,正确地选择行驶车道。 能够在驾驶员疲劳或紧急情况下,自动接替驾驶员,完成安全行驶。
以上是 GPT-4V 在自主驾驶方面的主要能力。这些能力为未来自动驾驶技术的发展提供了重要的参考和借鉴。
在本文中,作者对 GPT-4V 在各种自主驾驶场景下的能力进行了全面而多方面的评估。结果表明,GPT-4V 在场景理解、意图识别和驾驶决策等方面展现出了有望超越现有自主驾驶系统的能力。
在拐角场景中,GPT-4V 利用其先进的理解能力来处理非标准情况,并可以准确评估周围交通参与者的意图。GPT-4V 利用多视图图像和时间照片来实现对环境的完整感知,准确识别交通参与者之间的动态互动。
此外,它还可以推断出这些行为背后的潜在原因。如第 4 节所示,作者还观察到 GPT-4V 在开放道路上进行连续决策的能力。它甚至可以以类似人类的方式解释导航应用程序的用户界面,帮助和指导驾驶员完成决策过程。
以下是 GPT-4V 在自动驾驶领域中的限制:
夜间和低光条件下,GPT-4V 的表现仍然不够稳定,容易受到环境变化的影响。 对于复杂的交通场景和天气状况,GPT-4V 的表现仍然不够成熟,需要进一步的改进和优化。 GPT-4V 需要更广泛和多样化的数据集和模拟场景,以进一步测试和改进其自动驾驶性能。 GPT-4V 的推理和决策能力仍然需要进一步的改进和优化,以更好地适应复杂的驾驶环境和路况。 GPT-4V 仍然存在一些模型偏见和错误,这可能会影响其在实际自动驾驶中的表现和效果。
然而,在作者进行测试时,作者也发现 GPT-4V 在以下任务上表现不佳:
然而,在图 17、8 和 21 中,作者也观察到模型在识别方向时遇到了困难。这也是自动驾驶的一个关键方面。类似的问题也出现在图 17、8 和 21 中。这些图显示了模型在解释复杂交叉口或做出换车道决定时偶尔会感到困惑。
在图 12、15、22、26 和 29 中,作者也观察到了一些问题。作者认为这个问题可能是由于图像中包含的丰富语义信息导致的,从而导致了交通信号灯的嵌入信息损失。当将图像中的交通信号灯区域裁剪并单独输入时,模型在图 5 中展示了成功识别。
视觉定位任务:如图 7 所示,GPT-4V 发现指定像素级坐标或边界框具有挑战性,它只能表示图像内的大致区域。
空间推理:对自动驾驶车辆的安全操作至关重要,准确的时空推理是必需的。无论是将多视图图像缝合在一起,如图 18 所示,还是估计一辆电动滑板车与自动驾驶汽车之间的相对位置关系,如图 21 所示,GPT-4V 都很难做出精确的判断。
这可能是由于基于二维图像输入理解三维空间固有的复杂性。
此外,模型对非英语交通标志的解读也存在问题,这在多语言标志的地区成为一个挑战。同时,在拥挤的环境中,计数交通参与者的准确性也会降低,因为可能会出现重叠的物体。
这些限制揭示了需要进一步优化的领域,以增强 GPT-4V 在不同驾驶条件和场景下的鲁棒性和适用性。
[1]. On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢