
点击下方卡片,关注「集智书童」公众号

本文针对transformer模型在预训练过程中面临的一些挑战,提出了一种通用方法GQKVA,该方法可以扩展Query、Key和Value的分组技术。GQKVA旨在加速Transformer的预训练,同时减少模型的大小。
作者在各种GQKVA变体上的实验表明,性能和模型大小的权衡非常明显,可以根据资源和时间的限制进行自定义选择。作者的研究结果还表明,传统的多头自注意力方法并非总是最佳选择,因为有一些更轻更快捷的替代方案。
作者在ViT上测试了本文的方法,在图像分类任务中,它实现了约0.3%的准确性提高,同时将模型大小减少了约4%。
此外,作者的最激进的模型缩减实验结果表明,模型大小减少了约15%,而准确率只降低了约1%。
2023年提出了Transformer模型,在自然语言处理任务中取代了RNNs。尽管CNNs通常被认为是各种计算机视觉任务的主干,但Transformer在许多实例中展示了其竞争能力。这些模型的可扩展性和强大性促使文献中出现了一种趋势,即通过增加模型的参数和层数来提高性能。然而,这些模型的扩展引入了几个挑战,如计算需求重和预训练、微调、推理过程缓慢。
此外,Hoffmann等人(2022年)发现,许多大型语言模型(LLMs)如GPT3 175B过度参数化,训练不足,意味着参数的丰富性并未真正转化为增强性能。因此,需要引入更适度的参数的Transformer模型来解决过度参数化的问题。
针对如何高效地微调大规模的Transformer模型,研究提出了各种技术,如LORA和Prompt-Tuning。文献中在加速Transformer推理方面也相当丰富。然而,加速Transformer模型的预训练则尚未得到充分研究。在这个方向上的一种研究方法是,将多头自注意力计算的时间复杂度从二次降为一次。这是通过引入一个核度量来允许注意力计算顺序的变化实现的。然而,这个方向可能会导致准确性下降。
另一种预训练加速技术的研究方向是减少输入到Transformer中的Token数量。值得注意的是,这两种方向都保持了相同的模型大小,并未解决过度参数化的问题。本文旨在为相对有限的研究中提出的方法之一,即同时加速Transformer的预训练和减少模型大小做出贡献。MQA和GQA最近显示了加速解码器推理速度的潜力。作者提出了一种更通用的方法,称为GQKVA,这是一种预训练加速技术。GQKVA在自注意力机制内对Query、Key和Value进行分区,以减少注意力计算所需的时间。
在作者对视觉Transformer架构的评估中,作者证明了将Query、Key和Value分组的做法可以加速训练并使模型更紧凑。此外,作者还深入分析了将Q、K和Vs分组的做法,揭示了其对模型收敛和参数数量的影响。
作者的贡献包括:
提出了一种高效的通用注意力计算机制GQKVA,该机制涉及将Query、Key和Value分组 在预训练阶段,作者深入探索了各种将Q、K、V矩阵分组的方式,包括MQA、GQA、MKVA、GKVA等 通过在性能与模型大小和TPS之间获得明确的权衡,允许根据资源和时间的限制进行自定义选择。
多头自注意力(MHA)使用一组 个不同的注意力头,每个头理想地专注于学习输入的独有方面。对于每个头,分别创建Query 、Key 和Value 矩阵,通过将输入 通过一个线性层(维度为 )进行处理,该线性层被称为qkv层( 代表嵌入大小)。然后使用公式1计算每个头的点积注意力,从而得到每个头独特的输出。这些输出向量捕捉了输入的多种方面,并在将其与第二个线性层处理之前进行串联。该线性层对组合输出应用变换。
注意力 的计算公式如下:
其中,、 和 分别表示Query向量、Key向量和Value向量, 表示嵌入大小。公式1中的softmax函数计算每个注意力头对应的分值,然后将其与值向量进行点积,得到最终的注意力权重向量。
多Query注意力(MQA)最初是为了提高推理速度而引入的MHA的变体。在这个变体中,作者仍然保持个不同的头,每个头都配备一个单独的Q矩阵。然而,有一个关键的区别:作者使用单个共享的K和V矩阵来处理所有头。
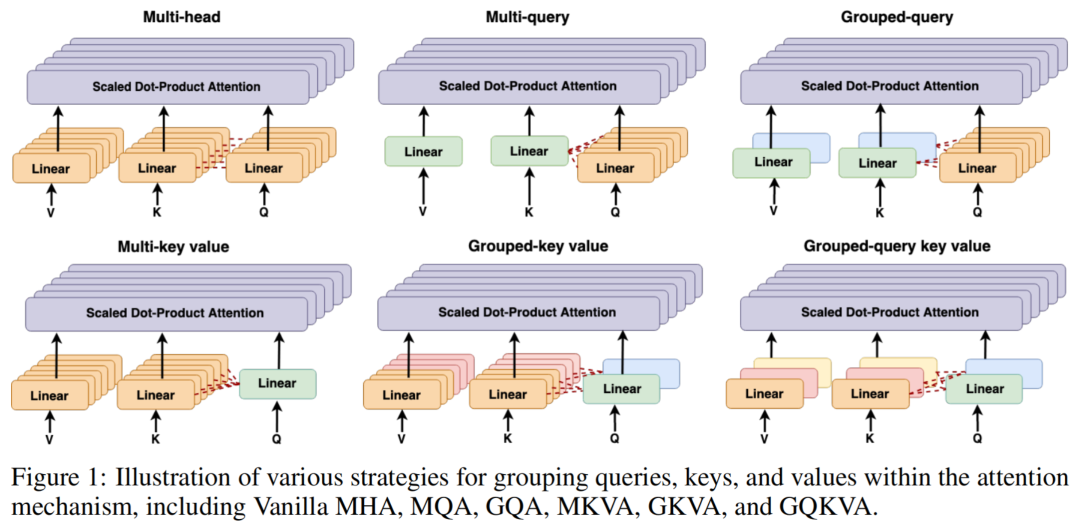
图1:展示在注意力机制内部将Query、Key和Value分组的不同策略,包括原始多头自注意力(MHA)、多Query注意力(MQA)、分组Query注意力(GQA)、分组键值注意力(MKVA)、分组键注意力(GKVA)和分组Query键注意力(GQKVA)。
因此,qkv层的参数数量减少到,其中。
分组Query注意力(GQA)是为了更快的推理速度而引入的。该方法将Query分成个不同的组,每个组共享一个和。因此,在这个方案中,作者有个Q矩阵,以及个共享的和矩阵。
值得注意的是,当等于1时,GQA与MQA等同,而当等于时,GQA与传统的MHA相符。qkv层的参数数量由以下公式确定:。
作者提出MKVA和GKVA作为类似于MQA和GQA的新颖变体。然而,MKVA和GKVA的不同之处在于,它们将Key和Value分组到个不同的组中,而每个组共享一个和;而Query在每个组内共享。
必须强调的是,Key和Value之间存在一对一的映射关系。因此,无论K矩阵如何分组,V矩阵都必须按照相同的分组方式进行分组,以保持这种对应关系。为了澄清,当所有个和共享一个Q矩阵时,作者称该方法为MKVA,而当个Qs共享时,作者称之为GKVA。
为了进一步优化参数数量和计算效率,作者提出了一个全面的方法GQKVA。在GQKVA中,作者将Q矩阵分成组,将K、V矩阵分成组,其中。然后,对每个组合进行点积注意力计算,得到个不同的输出,类似于MHA的行为。
必须注意的是,Qs和K、Vs的使用必须确保没有重复的(Q, KV)对,以保留个有效头。否则,作者将得到点积注意力中的相同输出,降低模型的容量。GQKVA是之前讨论的所有方法的统一泛化。例如,当一个Q矩阵被所有个K、Vs共享时,模型对应于MKVA。如果所有Query中共享个K、Vs,则有GQA-_g_。这种方法在保持多样性的同时优化了参数化和计算效率。
作者在图像分类任务上评估了之前提到的方法在ViT上的性能。作者在ViT-small上训练,它有6个头和2200万参数。训练过程在6个32GB V100 GPU核心上进行,使用数据并行性进行300个周期,批大小为288。作者使用AdamW优化器,并设置初始学习率为0.001。
通过一系列广泛的实验,作者比较了以下方法:MHA、MQA、GQA-2(两个K、V矩阵在所有Query之间共享)、GQA-3、MKVA、GKVA-2(所有Query之间共享两组K、V矩阵)、GKVA-3、GQKVA-2.3(两个Q矩阵和三个K、V矩阵)、以及GQKVA-3.2。总结结果如表1所示。
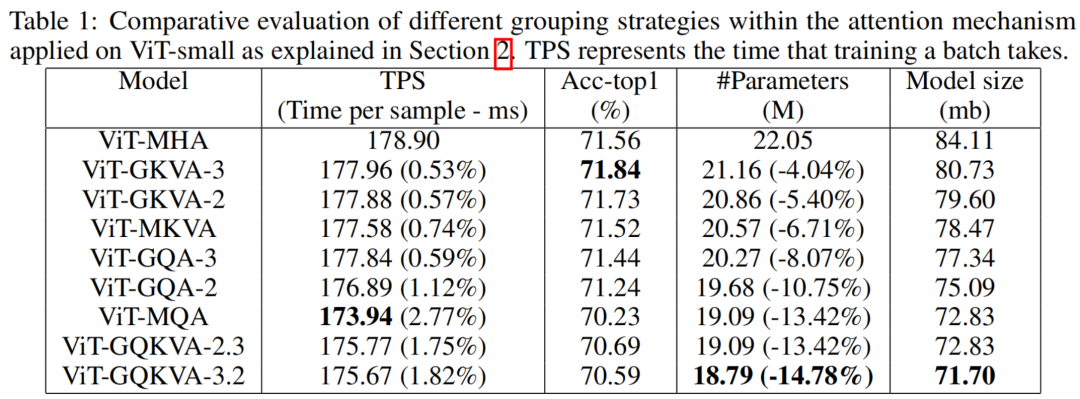
研究结果表明,GKVA-2和GKVA-3在图像分类任务上取得了最高精度,分别为71.73和71.84,分别比多头注意力减少了5.4%和4.04%的模型大小。此外,作者发现GQKVA-2.3和GQKVA-3.2与MQA具有相同或更少的参数数量,但分别通过提高0.46%和0.36%的精度超过了MQA。图2(a)和2(b)分别描绘了模型大小与性能之间的权衡以及时间每样本(TPS)与性能之间的关系。
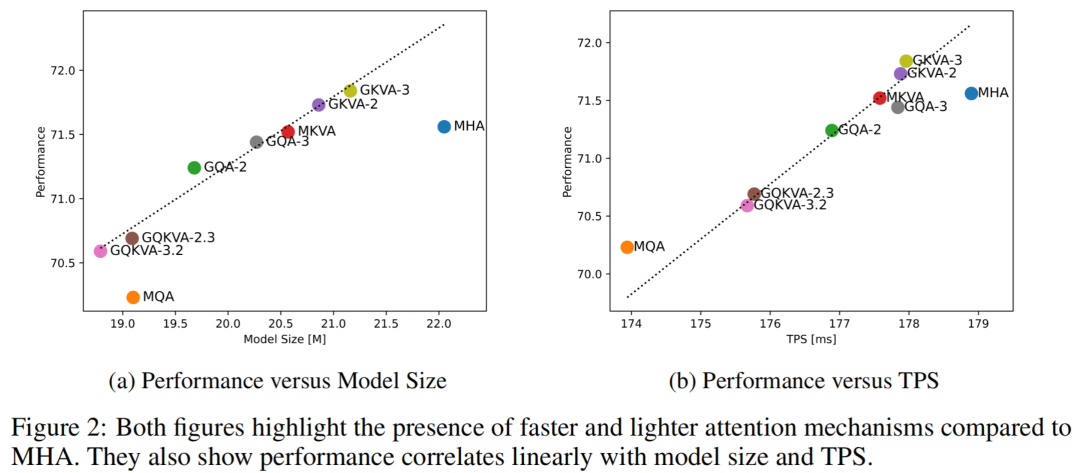
TPS是按照训练一个批次的所需时间测量的。如图2所示,TPS和性能之间呈线性相关。值得注意的是,MHA在两个图中都低于趋势线,表明存在比MHA更快、更轻的替代方案,并且其较大的参数数量并不一定带来好处。
总的来说,除MHA和GQA之外的方法,模型大小增加会导致性能提高,而较大模型通常具有更高的TPS。因此,根据资源和时间的限制,可以选择最适合的方法,以平衡考虑模型大小、训练速度和性能。
Transformer模型通常存在巨大的模型大小和计算密集型的预训练。在这篇论文中,作者引入了一种通用的解决方案GQKVA,旨在加速Transformer的预训练,同时减少模型大小。GQKVA涵盖了像MQA和GQA这样的各种Q、K、V分组技术。作者涉及不同GQKVA变体的实验揭示了模型大小和性能之间明显的权衡。
这种权衡允许实践者根据资源限制和训练时间的限制来定制他们的选择。作者的结果表明,传统的MHA并非总是最佳选择,因为存在更轻便、更快捷的替代方案。
值得注意的是,作者提出的GQKVA方法是通用的,可以应用于任何Transformer架构。然而,由于作者当前的时间和资源限制,作者仅限于探索ViT-small模型。未来的研究应将这些技术扩展到更大的Transformer,以发现更大的速度提升和内存节省的潜力。
[1].GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values.

点击上方卡片,关注「集智书童」公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢