

01
研究动机
多模态方面级情感分析(简称MABSA)是一项细粒度情感分析任务[1],在过去几年中受到了广泛的研究关注。MABSA派生了许多子任务,它们都围绕着预测几个情感元素,即方面术语(a)、情感极性(p)或它们的组合。如表1所示,给定一对图片和文本,多模态方面术语提取(简称MATE)旨在提取文本中提到的所有方面术语[2],面向方面的多模态情感分类(简称MASC)旨在预测文本中给定方面术语的情感极性[3],而多模态方面-情感联合抽取(简称JMASA)的目标是同时提取所有方面术语及其对应的情感极性[4]。
表1:MABSA所有子任务的定义

这些子任务背后的假设是图片信息可以帮助文本内容识别情感元素。因此,如何利用图片信息是MABSA任务的核心。为此做了很多努力,大致分为三类:(1) 将图片转化为全局特征向量,然后利用注意力机制筛选与文本相关的视觉内容[5,6];(2) 平均将图片划分为多个视觉区域,随后建立文本序列和视觉区域之间的联系[3,4,7];(3) 仅保留图片中的视觉对象区域,然后与文本序列进行动态交互[2,8,9,10,11,12]。
尽管取得了不错的结果,但大多数研究都高估了图片的重要性,因为数据集中包含很多与文本无关的噪声图片,这会对模型学习产生负面影响。在MABSA任务中,部分工作[4,10,13,14,15]设计了跨模态关系检测模块,该模块通过设置阈值来过滤低质量的噪声图片。但是,依赖阈值将不可避免地过滤掉很多有用的图片信息。因此,在这项工作中,我们关注另一个方面:能否可以在不过滤数据的情况下减少噪声图片的负面影响?
为了回答上述问题,我们借鉴了课程学习(简称CL)[16]的思想,因为CL可以通过调整训练数据的顺序实现去噪[17]。换句话说,CL在训练过程中不再完全随机地呈现训练数据,而是鼓励在干净数据上训练更多的时间,在噪声数据上训练较少的时间,通过减少噪声数据的曝光来实现去噪。应用CL的关键是如何定义干净/噪声示例以及如何确定适当的去噪方案。通过分析任务的特点,我们专门设计了一个多粒度多课程去噪框架(M2DF)。M2DF首先从多个粒度评估每个训练实例中包含的噪声图片的程度,然后去噪课程在训练过程中从干净数据开始逐渐向模型展示包含噪声图片的数据。这样,M2DF理论上为干净数据分配了更大的学习权重[18],从而达到了降噪的效果。
02
贡献
我们的贡献总结如下:(1) 我们从一个新的视角出发缓解了MABSA任务中噪声图片带来的负面影响;(2) 我们提出了一个新颖的多粒度多课程去噪框架,该框架与基模型的选择无关;(3) 我们在一些代表性模型上评估了我们的去噪框架。大量实验结果表明,我们的去噪框架在三个子任务上都取得了有竞争力的结果。
03
方案
如图1所示,我们为MABSA任务设计了一个多粒度多课程的去噪框架。它包括两个模块:噪声度量模块和去噪课程模块。
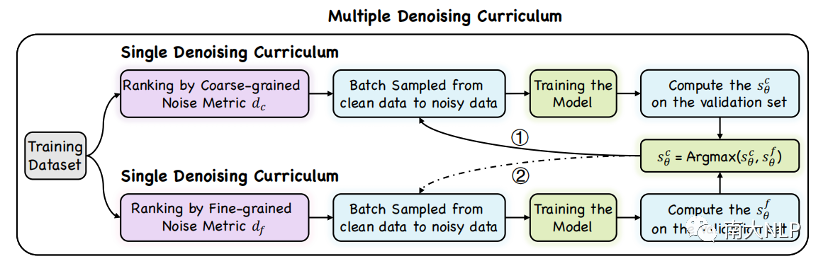 图1:M2DF框架总览
图1:M2DF框架总览
3.1 噪声度量模块
当图像和文本不相关时,图像很可能是噪声。在这种情况下,图像和文本之间的相似性通常较低,并且文本中的方面术语通常不会出现在图像中。基于此,我们分别定义了一个粗粒度(句子级)的噪声度量和一个细粒度(方面级)的噪声度量来衡量每个训练实例中包含的噪声程度。
3.1.1 粗粒度的噪声度量指标
根据上述的直觉,我们通过计算图像和文本之间的相似性来衡量每个训练实例中包含的噪声图像的程度。具体地说,给定训练数据集D中的一个句子-图像对(S_i,I_i), 我们首先将每种模态输入到 CLIP 的不同编码器中[19], 以获得文本特征H和视觉特征V。然后计算它们之间的相似性:
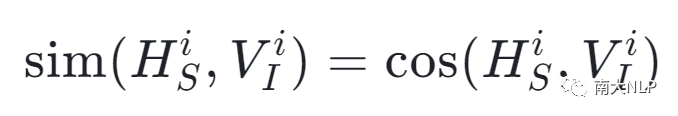
其中cos(·)是一个余弦函数。之后,考虑到图像和文本之间的相似性越低,图像就越可能是噪声,我们定义了一个粗粒度(句子级)的噪声指标,如下所示:

其中d_c被归一化到[0.0, 1.0] 。这里,较低的分数表示句子-图像对(S_i, I_i)是干净的数据。
3.1.2 细粒度的噪声度量指标
除了句子级的噪声度量,我们还从方面术语的角度衡量了噪声水平,因为MABSA的目标是识别方面术语或预测方面术语的情感。具体来说,当图像和文本相关时,句子中的方面术语很可能出现在图像中。相反,当图像和文本不相关时,句子中的方面术语通常不会出现在图像中。因此,我们可以通过计算句子中的方面术语与图像中的视觉对象之间的相似性来判断图像和文本的相关性。相似性越低,图像越有可能是噪声。
我们通过计算句子中的方面术语与图像中的视觉对象之间的相似性来衡量噪声图像的程度。然而,除了MASC任务外,其他子任务的方面术语是未知的。考虑到方面术语主要是名词短语[20],因此我们使用Stanford解析器提取的名词短语作为MATE和JMASA任务中的方面术语。同时,我们使用对象检测模型Mask-RCNN来提取图像中的视觉对象。从句子S和图像I中提取的方面术语和视觉对象的数量如下:
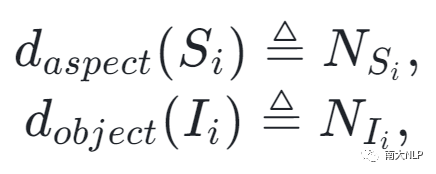
随后,我们将句子S_i中的方面术语和图片I_i中的视觉对象输入到预训练模型CLIP中获得一组aspect特征和object特征。 随后,我们将这些aspect特征和object特征做平均来获得最后的apsect表示和object表示。跨模态相似度计算过程如下:
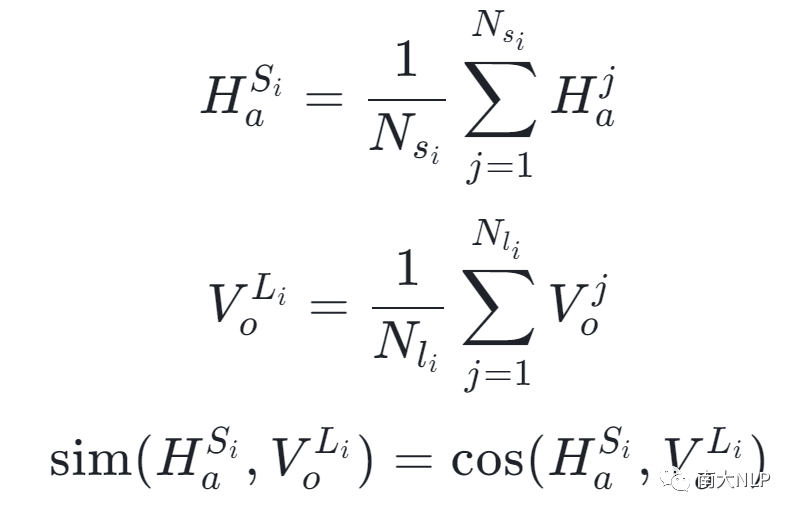
最后,由于方面术语和视觉对象之间相似度越低,图片越有可能是噪声,我们定义了细粒度噪声度量指标:
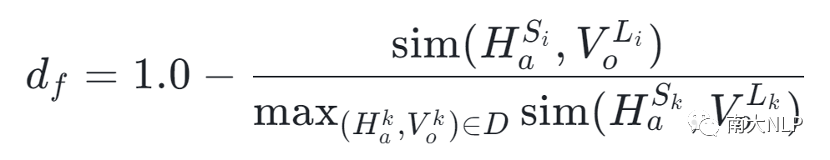
其中d_f被归一化到 [0.0, 1.0] 。这里,较低的分数表示句子-图像对(S_i, I_i)是干净的数据。
3.2 去噪课程模块
我们为每个噪声指标设计了一个去噪课程。考虑到这两种噪声指标从不同的粒度衡量了图像的噪声程度,一个自然的想法是将它们结合在一起以产生更好的去噪效果。为此,我们将单一去噪课程扩展为多重去噪课程。
在这里,我们首先介绍为每个噪声度量指标设计的单去噪课程,然后将其拓展到多去噪课程。
3.2.1 单一去噪课程
在训练过程中,我们首先基于粗粒度噪声度量指标d_c或细粒度噪声度量d_f指标分别对训练集作排序。然后我们定义了一个简单的函数p(t), 用来控制从干净数据到噪声实例的训练进度。具体的函数形式如下:
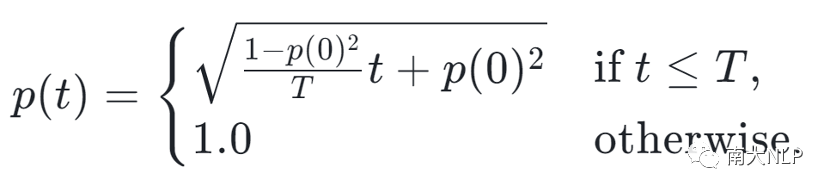 其中p(0)是预定义的初始值,T是去噪课程的持续时间。在每一个时间步t,p(t)代表噪声指标的上限,模型只允许使用噪声指标d_c或d_f不高于p(t)的训练样本进行训练。通过这种方式,训练过程中训练数据不再是完全随机地呈现给模型,而是在干净数据上训练更长时间,在噪声数据上训练更少时间,通过减少噪声数据的曝光来实现降噪。当p(t)变为1.0时,单去噪课程结束,模型可以访问整个数据集。图2给出了这一过程可视化的解释。
其中p(0)是预定义的初始值,T是去噪课程的持续时间。在每一个时间步t,p(t)代表噪声指标的上限,模型只允许使用噪声指标d_c或d_f不高于p(t)的训练样本进行训练。通过这种方式,训练过程中训练数据不再是完全随机地呈现给模型,而是在干净数据上训练更长时间,在噪声数据上训练更少时间,通过减少噪声数据的曝光来实现降噪。当p(t)变为1.0时,单去噪课程结束,模型可以访问整个数据集。图2给出了这一过程可视化的解释。
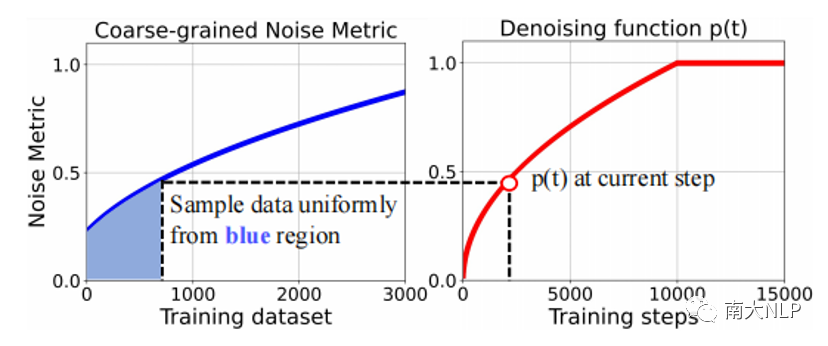 图2:粗粒度噪声度量对应的单去噪课程
图2:粗粒度噪声度量对应的单去噪课程
3.2.2 多重去噪课程
正如之前提到的,考虑到这两种噪声度量从不同的粒度衡量图像的噪声水平,一个很自然的想法是将它们结合在一起以产生更好的去噪效果。为此,我们提出了多重去噪课程。 我们在每个训练步骤中动态地选择最合适的去噪课程。为了达到这个目标,我们使用连续两次在验证集上的性能比值来衡量每个去噪课程的有效性:
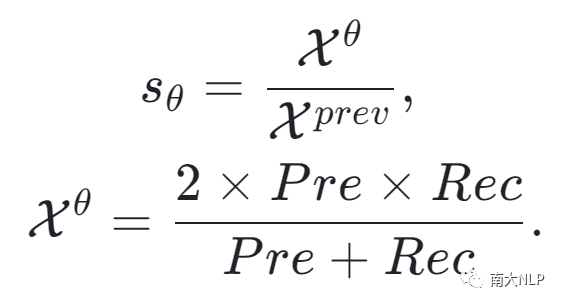
较高的比值的表明当前去噪课程取得了更好的进展,也就应该获得一个更大的采样概率来获得更好的去噪效果。基于此,在每个训练轮次,我们通过比较两个课程比值s来动态选择最合适的去噪课程。
04
实验
4.1 数据集
我们使用了两个公开数据集:Twitter2015和Twitter2017,其详细统计信息见表2:
表2:数据集统计信息
4.2 主实验结果
表3,表4,表5给出了我们的方法在MABSA三个子任务(MATE,MASC,JMASA)上的表现,可以看到我们的方法在不同的基模型上都取得了一致性的性能提升,展现出我们课程学习去噪框架的通用性和泛化能力。
表3:JMASA任务相关实验结果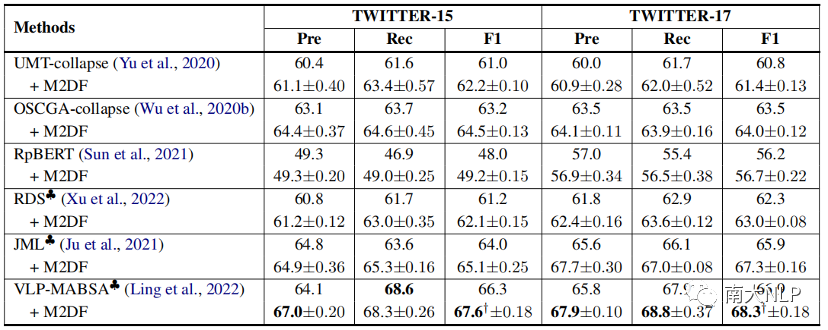
表4:MATE任务相关实验结果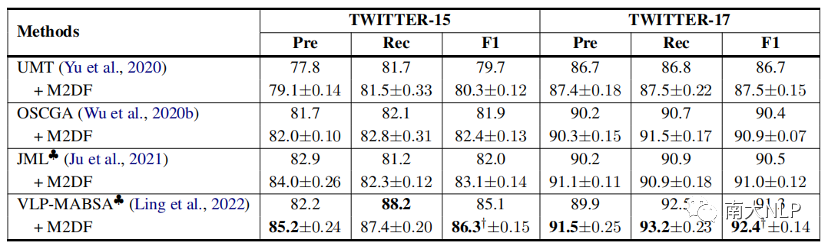
表5: MASC任务相关实验结果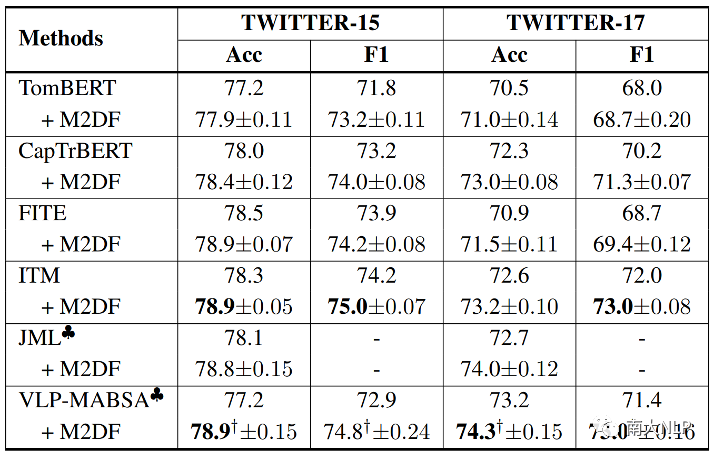
4.3 消融实验结果
我们对两个去噪模块以及它们的组合方式进行了消融实验。如表6所示,设置(a), (b)分别表示对细粒度噪声度量和粗粒度噪声度量模块的消融,设置(c)表示我们最终的方法。基于它们的结果,我们可以发现:(1)两种噪声度量方式都可以提升基模型VLP-MABSA的性能,这验证了我们所设计的噪声度量指标的合理性;(2)相对于粗粒度噪声度量指标,细粒度噪声度量在多数任务上取得了更好的效果,这表明细粒度噪声度量指标能更准确地衡量每个训练样例中是否包含噪声图片;(3)当把两种噪声度量指标结合到一起时,性能进一步提升了(设置c),这表明两种噪声度量指标可以从不同视角提升MABSA任务的性能。
表6:去噪框架的消融实验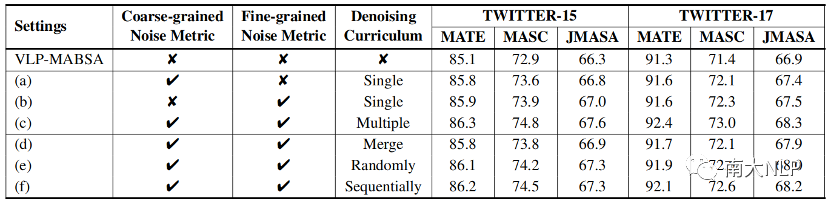
在(d), (e), (f)设置中,我们实现了不同的多课程分配方式,包括Merge(合并两个噪声指标)、Randomly(随机选择一个课程)、Sequentially(序列化分别进行两个课程)。实验结果表明:(1) 所有三种策略在MABSA任务上都实现了稳定的提升,这证明了我们的M2DF框架的有效性和稳健性;(2) Merge策略的结果不如Randomly和Sequentially。一个可能的原因是直接合并两种噪声指标无法充分发挥它们各自的优势;(3) 它们的表现都不如我们的最终方法(设置c),这验证了在每个训练步骤中动态选择策略的优越性。
为了更深入地了解M2DF的作用,我们基于粗粒度噪声指标的大小从低到高将TWITTER-17测试集分成三个大小相等的子集。我们希望衡量M2DF在不同噪声水平上的性能表现。在表7中,我们可以观察到,与VLP-MABSA相比,VLP-MABSA + M2DF在噪声水平较高的子集上实现了更多的性能提升。这表明M2DF确实可以减轻噪声图像的负面影响。
表7 不同噪声级别下TWITTER-17测试集的表现
4.4 案例分析
我们进行案例研究以更好地理解M2DF的优势。图3展示了在JMASA任务上,JML+M2DF和VLP-MABSA+M2DF以及两个代表性基准JML和VLP-MABSA对三个噪声样本的预测结果。
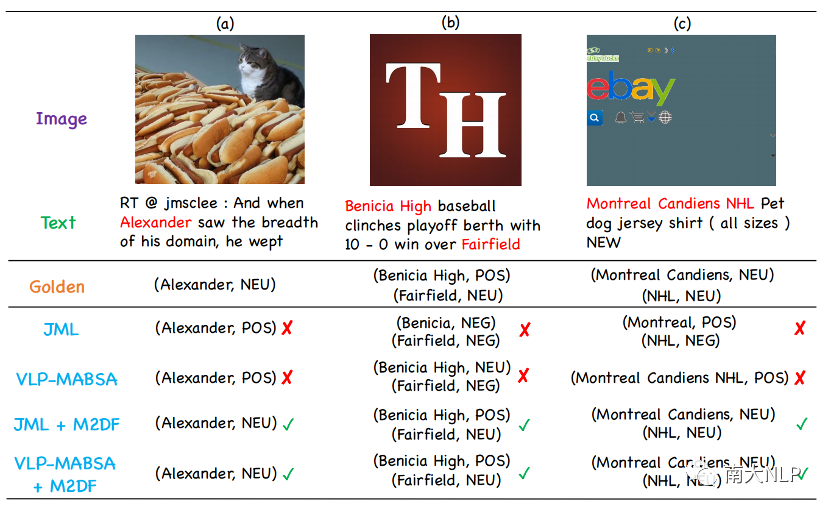 图3:案例分析
图3:案例分析
很明显,JML和VLP-MABSA面对带噪声的图像时给出了错误的预测。这背后的原因可能是:(1)尽管JML开发了一个跨模态关系检测模块来过滤噪声图像,但该模块依赖于阈值,所以使用它来过滤噪声图像并不够可靠;(2)VLP-MABSA对图像一视同仁,忽略了噪声图像的负面影响。相比之下,我们观察到JML+M2DF和VLP-MABSA+M2DF可以在三个噪声样本上获得正确的方面术语和情感极性,这表明我们的框架M2DF可以实现更好的去噪效果。
4.5 错误类型分析
我们在JMASA任务中随机抽取了100个VLP-MABSA + M2DF的错误案例,并将它们分为三个错误类别。图4显示了每个类别的比例和一些代表性示例。最主要的类别是标注偏差。如图4(a)所示,方面术语“Orange Carpet”的情感被标注为“NEU”(中性),但实际上它表达的是“POS”(积极)的情感。这种类型的错误为我们的模型提供准确预测带来了挑战。第二类是缺乏背景知识。在图4(b)中,方面术语“Orange is the New Black”指的是一个著名的喜剧,模型通常只能在没有背景知识的帮助下提取部分方面术语。第三类是信息不足。如图4(c)所示,句子和图像内容都相当简单,无法为我们的模型提供足够的信息来准确识别方面术语及其对应的情感极性。有必要开发更先进的自然语言处理技术来解决上述问题。
 图4:错误分析
图4:错误分析
05
结论
在本文中,我们为MABSA任务提出了一种新颖的多粒度多课程去噪框架(M2DF)。具体来说,我们首先定义了一个粗粒度的噪声指标和一个细粒度的噪声指标来衡量每个训练实例中包含的噪声图像的程度。然后,为了减少噪声图像的负面影响,我们设计了一个单一去噪课程和多重去噪课程。大量实验的结果表明,我们的去噪框架比其他最先进的方法表现得更好。进一步的实验分析也验证了我们去噪框架的优越性。
论文链接:https://arxiv.org/pdf/2310.14605.pdf
代码链接:https://github.com/grandchicken/M2DF
参考文献
[1] Bing Liu. 2012. Sentiment Analysis and Opinion Mining. Synthesis Lectures on Human Language Technologies. Morgan & Claypool Publishers.
[2] Hanqian Wu, Siliang Cheng, Jingjing Wang, Shoushan Li, and Lian Chi. 2020a. Multimodal aspect extraction with region-aware alignment network. In Natural Language Processing and Chinese Computing-9th CCF International Conference, NLPCC 2020, Zhengzhou, China, October 14-18, 2020, Proceedings, Part I, volume 12430 of Lecture Notes in Computer Science, pages 145–156. Springer.
[3] Jianfei Yu and Jing Jiang. 2019. Adapting bert for target-oriented multimodal sentiment classification. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 5408–5414. International Joint Conferences on Artificial Intelligence Organization.
[4] Xincheng Ju, Dong Zhang, Rong Xiao, Junhui Li, Shoushan Li, Min Zhang, and Guodong Zhou. 2021. Joint multi-modal aspect-sentiment analysis with auxiliary cross-modal relation detection. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4395–4405, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
[5] Seungwhan Moon, Leonardo Neves, and Vitor Carvalho. 2018. Multimodal named entity recognition for short social media posts. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1**(Long Papers), pages 852–860. Association for Computational Linguistics.
[6] Nan Xu, Wenji Mao, and Guandan Chen. 2019. Multi interactive memory network for aspect based multimodal sentiment analysis. In Proc. of AAAI, pages 371–378.
[7] Jianfei Yu, Jing Jiang, Li Yang, and Rui Xia. 2020. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL2020, Online, July 5-10, 2020, pages 3342–3352. Association for Computational Linguistics.
[8] Zhiwei Wu, Changmeng Zheng, Yi Cai, Junying Chen, Ho-fung Leung, and Qing Li. 2020b. Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts. In Proceedings of the 28th ACM International Conference on Multimedia, MM ’20, page 1038–1046, New York, NY, USA. Association for Computing Machinery.
[9] Dong Zhang, Suzhong Wei, Shoushan Li, Hanqian Wu, Qiaoming Zhu, and Guodong Zhou. 2021. Multimodal graph fusion for named entity recognition with targeted visual guidance. In AAAI 2021, Virtual Event, February 2-9, 2021, pages 14347–14355.
[10] Jianfei Yu, Jieming Wang, Rui Xia, and Junjie Li. 2022. Targeted multimodal sentiment classification based on coarse-to-fine grained image-target matching. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, pages 4482–4488. International Joint Conferences on Artificial Intelligence Organization. Main Track.
[11] Yan Ling, Jianfei Yu, and Rui Xia. 2022. Vision language pre-training for multimodal aspect-based sentiment analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2149-2159, Dublin, Ireland. Association for Computational Linguistics.
[12] Hao Yang, Yanyan Zhao, and Bing Qin. 2022. Face sensitive image-to-emotional-text cross-modal translation for multimodal aspect-based sentiment analysis. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages3324–3335, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
[13] Lin Sun, Jiquan Wang, Yindu Su, Fangsheng Weng, Yuxuan Sun, Zengwei Zheng, and Yuanyi Chen. 2020. RIVA: A pre-trained tweet multimodal model based on text-image relation for multimodal NER. In Proceedings of the 28th International Conference on Computational Linguistics, pages 1852–1862, Barcelona, Spain (Online). International Committee on Computational Linguistics.
[14] Lin Sun, Jiquan Wang, Kai Zhang, Yindu Su, and Fang sheng Weng. 2021. Rpbert: A text-image relation propagation-based BERT model for multimodal NER. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 13860–13868.
[15] Bo Xu, Shizhou Huang, Ming Du, Hongya Wang, Hui Song, Chaofeng Sha, and Yanghua Xiao. 2022. Different data, different modalities! reinforced data splitting for effective multimodal information extraction from social media posts. In Proceedings of the 29th International Conference on Computational Linguistics, pages 1855–1864. International Committee on Computational Linguistics.
[16] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009, volume 382 of ACM International Conference Proceeding Series, pages 41–48. ACM.
[17] Xin Wang, Yudong Chen, and Wenwu Zhu. 2022. A survey on curriculum learning. IEEE Trans. Pattern Anal. Mach. Intell., 44(9):4555–4576.
[18] Tieliang Gong, Qian Zhao, Deyu Meng, and Zong ben Xu. 2016. Why curriculum learning & self-paced learning work in big/noisy data: A theoretical perspective. Big Data & Information Analytics,1(1):111.
[19] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24July 2021, Virtual Event, volume 139 of Proceedings**of Machine Learning Research, pages 8748–8763.
[20] Minqing Hu and Bing Liu. 2004. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, USA, August 22-25, 2004, pages 168–177. ACM.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢